Distribution of number of statements in functions
The source code of individual functions is written a particular way by individuals to solve particular problems. When source code use of programming constructs are counted, in a sufficiently large quantity of source code, various patterns emerge. The most common patterns involve power laws and exponentials. The plot below shows the number of functions containing a given number of lines of code, expression-statements (e.g., assignments, calls whose return value is not used), function calls (which includes calls within an expression), and return-statements for 176,172 C functions, along with fitted power laws (data obtained using GitHub’s CodeQL variant analysis; code+data):
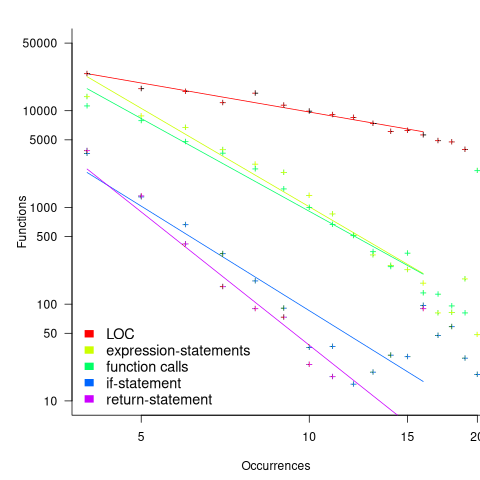
The power law exponents are: LOC 1, expression-statements 3.4, calls 3.2, if-statements 3.6, and return-statements 4.6.
This plot counts uses across all functions, to provide a global perspective. Given the quantity of data available, it’s possible to focus on the characteristics of functions containing a given number of lines of code (LOC), to study patterns of behavior that emerge as functions get longer (it was once thought that there was an optimal function length that minimised the likelihood of fault reports).
Given a function containing  LOC, what is the probability that it will contain
LOC, what is the probability that it will contain 
if-statements, or for-statements, or expression-statements, etc? The plots below show the number of if-statements that occur in 176,172 C functions containing each of 4, 5, …, 19 LOC, along with fitted regression lines (code+data):

The fitted model is the probability mass function of the negative binomial distribution. The blue/green lines are individual fits to the data in each plot.
The negative binomial distribution is usually described in terms of the probability of  events occurring (or not occurring) in a sequence of
events occurring (or not occurring) in a sequence of  tries, e.g., rolling two 6’s in five attempts. In a function context, this can be interpreted as the probability that there will be occurrences of a particular statement in the LOC of the function’s code.
tries, e.g., rolling two 6’s in five attempts. In a function context, this can be interpreted as the probability that there will be occurrences of a particular statement in the LOC of the function’s code.
There are various ways of specifying a negative binomial distribution. The data was fitted using R’s gamlss package, which uses the two parameters: mean ( ) and dispersion (
) and dispersion ( ).
).
As functions get longer (i.e., LOC increases), they are more likely to contain more of each kind of statement (i.e., the mean will increase), and the variability is also likely to increase. In other words, the parameters and will increase with LOC. The red line in each plot are derived from a fitted negative binomial distribution with: ") and
and ") , where the values
, where the values  ,
,  ,
,  , and
, and  are returned by the fitting process (this equation was found by inspired guessing/some trial and error; another possibility is:
are returned by the fitting process (this equation was found by inspired guessing/some trial and error; another possibility is: , and
, and  ). This LOC dependent fits (in red) closely follow the bespoke fits (in blue/green), and for larger LOC are not affected by noisy data points.
). This LOC dependent fits (in red) closely follow the bespoke fits (in blue/green), and for larger LOC are not affected by noisy data points.
Being able to fit a single model to the data over a range of LOCs shows that a consistent pattern of behavior exists. Similar models can be built for number of calls, while-statements, expression-statements and number of local variables. The model of for-statements suffered from high variability counts, and return-statements counts grew too slowly over the range of LOC analysed.
If the number of if-statements, say, within functions of a given size has a negative binomial distribution, then adding together all these distributions, weighted by the number of functions at a given size, should produce a power law whose exponent matches that found in the first plot (i.e., 3.6).
I asked ChatGPT: “If $y(k, x)=a*x^{-b}*NB(k; mu=log(x), sigma=log(x))$ where: $NB$ is the probability mass of the negative binomial distribution, $mu$ is its mean and $x$ takes positive integer values, $a$ is a positive constant, and $1 < b < 3$. Show that the series $sum_{x=3}^14 y(k, x)$i for $0 < k < 10$ is approximately a power law." and obtained the response that the exponent was approximately  (i.e., about 2), which is not close.
(i.e., about 2), which is not close.
The responses from other LLMs were not any better. The calculation requires various simplifying assumptions (all the models resorted to numerical simulation at some point), and these need to be checked.
Call graph neighbourhood and fault prediction
Fault reports are generated by a program’s users, and the extreme difficulty of obtaining any information about how users use a program and number of users makes it almost impossible to do reliable fault prediction.
Source code is often available. Are there any source code characteristics that could be used to make fault predictions?
A significant number of published software fault prediction papers are based on the idea that the code contained in the functions modified to fix reported faults have ‘woo‘ characteristics that is not present in the code of other functions. Discovering these woo characteristics would make it possible to reliably predict faults. Countless hours of machine learning have been invested on the search for woo.
Faults are reported in the code that users execute, and the more often the code is executed, the more opportunities there are for fault triggering input values to occur.
Functions that have been modified to fix faults tell us something about the code that is executed by users. If a function in file A calls a function in file B which in turn calls a function in file C, and file B has be modified to fix a fault, then we know that a function in A has been called, and perhaps also in C (yes, call-chains are usually links between functions, not links between the files that contain them; most files contain only a few functions). Are files in the call-chain neighbourhood of a fault-fixed file more likely, in the future, to be modified because of a reported fault, than files that are not in such a call-chain neighbourhood?
The paper Do Bugs Propagate? An Empirical Analysis of Temporal Correlations Among Software Bugs by Gu, Han, Kim and Zhang extracted data on files/functions from multiple releases of the four systems: HTTPClient, Jackrabbit, Lucene, and Rhino, including LOC, call-graph, number of changes/authors, and number of fixed faults.
For a particular system, data on each file/function and its neighbourhood in release was then used to build a regression model that predicts the likelihood of each file needing to be changed to fix a reported fault in the next release,  .
.
The technical details of the regression fitting process for this data are more complicated than usual, and are discussed at the end of the post. The important question is whether information on call-chain neighbourhood fault reports have a worthwhile impact on the performance of a fault prediction model.
Yes, call-chain neighbourhood information does make a worthwhile improvement to fault prediction in the next release (as expected, LOC has a big impact).
The authors also built a co-change graph (i.e., files modified in the same commit), and a type hierarchy graph (i.e., is a class in file X extends a class in file B, an edge from A to B is created). Information on these neighbourhoods made a worthwhile improvement to fault prediction in the next release.
The authors of the paper give a purely code focused explanation of the behavior, i.e., the coding mistake propagate within a neighbourhood. Perhaps code does move between functions in the same file. To distinguish between mistake propagation and user usage the call-graph analysis needs to be function-based, rather than file-based.
This data longitudinal because it follows the same subject (i.e., each file) through time (i.e., each release), and the response variable is to be fitted to a logistic equation. The statistical technique used to fit this kind of data the generalized estimating equation, a form of generalized linear model (the regression technique used in many of these blog posts) that handles correlation between observations, i.e., the same file is measured multiple times.
The analysis code that comes with the data is written in Matlab (Octave is an Open source mostly compatible program). To understand the analysis (in correlation_analysis.m), I implemented it in R (code and data). The coefficients of the fitted models are different from those given in the paper, but directionally the same. Octave had issues with the statistical library used for the analysis, so it was not possible to replicate the regression model coefficients.
Classification of code updates
Version control systems usually include support for classifying each check-in as being a particular instance of some category, e.g., Adaptive, Corrective, Perfective, or Other (this software maintenance category has a long history).
Categories have been studied for over 2,000 years. Categories is the first subject of Aristotle’s six works on logical analysis and dialectic.
Categorization is used to perform inductive reasoning (i.e., the derivation of generalized knowledge from specific instances), and also acts as a memory aid (about the members of a category). Categories provide a framework from which small amounts of information can be used to infer, seemingly unconnected (to an outsider), useful conclusions.
Experimental work on human classification has produced a variety of theories. See “Classification and Cognition” by W. K. Estes for an evidence-based analysis.
The evidence clearly shows that the boundaries between different members of a category are fuzzy. How consistent are developers in assigning software activities to the same instance of a category?
The study Determining the Distribution of Maintenance Categories: Survey versus Measurement by Schach, Jin, Yu, Heller, and Offutt, asked two people to categorise 215 maintenance changes involving the first 20 versions of Linux. The rows/columns in the table below show the number of changes assigned to each category by each person:
Adaptive Corrective Perfective Other Total Adaptive 2 0 0 0 2 Corrective 0 82 16 0 98 Perfective 0 5 99 2 106 Other 0 0 0 9 9 Total 2 87 115 11 215 |
The terminology used in the statistics analysis of agreement uses the term “raters” to refer to the people who classify items into categories. Cohen’s Kappa,  , is a measure of agreement between two raters (not more), which varies from zero (i.e., raters chose at random) to one (perfect agreement). For this data (code+data):
, is a measure of agreement between two raters (not more), which varies from zero (i.e., raters chose at random) to one (perfect agreement). For this data (code+data):  , which is very good agreement between the two raters.
, which is very good agreement between the two raters.
Another classification dataset is described in the paper Two datasets of defect reports labelled by a crowd of annotators of unknown reliability by Hernández-González, Rodriguez, Inza, Harrison, and Lozano, where five unspecified people classified two defect datasets (the paper had five authors, hmm; the associated paper does not use any established statistical technique to measure rater agreement {the paper’s really about something else}), one containing 962 defects from the Compendium project, and the other 675 defects from the Mozilla project.
The study used the Orthogonal defect classification (ODC) defect impact classification (ODC involves eight different classifications, some easier to assign than others), which contains 13 impacts, i.e., Bug, Capability, Documentation, Feature, Installability, Integrity/Security, Migration, Performance, Reliability, Requirements, Standards, Support, Usability. The Mozilla data does not contain instances of three defect impacts: Serviceability, Standards, and Accessibility.
Conger’s kappa is an extension of Cohen’s kappa to handle more than two raters, and is applicable when all raters classify all items (which they do here). Fleiss’s kappa is the brand-name technique for this kind of data, and does not require that all raters classified all items. This experimental design matches the assumptions made in the derivation of Conger’s kappa, and do not match those made for Fleiss’s kappa.
The 95% confidence intervals for the two sets of agreements between five-raters are (code+data): 0.26 to 0.29 (962 items) and 0.28 to 0.33 (675 items). Both have fair to poor agreement.
I was not surprised by the poor inter-rater agreement for these two datasets. There is a lot of domain specific knowledge is needed to assign some of the members of the ODC defect impact classification, e.g., Installability and Migration. As outsiders (I assume), the raters in this study only had the text associated with the defect report to make their decision.
Does ODC only achieve the claimed benefits if the people using it have been trained so that their agreement rate is higher? I am not aware of any other studies comparing ODC defect classification consistency. But then, studies like this rarely get done anyway.
Detailed management data on 1,211 software projects
Until April this year there were only two non-trivial publicly available software project datasets (i.e., Sip and CESAW) containing software project data relating to human effort, e.g., people time, elapsed time, and tasks performed. The SiP data contains 10-years of software development tasks by one company, and the CESAW data contains the tasks involved in implementing 45 software projects.
Two months ago the Software Excellence Alliance released the SEA Data Warehouse (the CESAW data is roughly a 10% subset of SEA). This post compares software project size from the perspective of various management related features.
An analysis of pre-LLM project development is still relevant because many project behavior patterns are driven by interactions with the outside world. Also, time spent writing code is often small part of project development.
The headline summary is that there is development-phase/estimates/actuals/start-time/end-time/person/team/etc information for the 679,904 tasks involved in implementing 1,211 software projects.
The projects were developed using the Team Software Process (TSP). This is an iterative development process that uses development phases similar to the Waterfall process, with weekly meeting that monitor progress using earned-value management. Given that the work-breakdown structure (WBS) is used to break down a project into a hierarchy of smaller and smaller components, these projects are US Department of Defense related.
The plot below shows, for each of the 1,211 projects (sorted by number of plans, in black), the number of tasks (blue), WBS (green), and deleted plans (red) ( ; code+data):
; code+data):
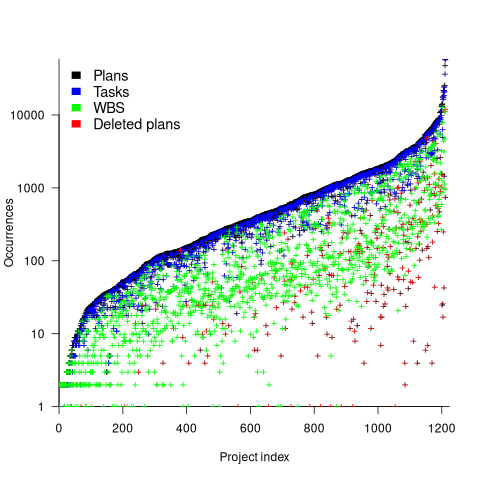
The average ratio of  is 8.4 (standard deviation 23). An exponential or power law (not Weibull) can be fitted to portions of the distribution of project sizes, measured in number of plans or tasks. If project size really does follow a single common distribution, a much larger sample size will be needed to reliably fit it.
is 8.4 (standard deviation 23). An exponential or power law (not Weibull) can be fitted to portions of the distribution of project sizes, measured in number of plans or tasks. If project size really does follow a single common distribution, a much larger sample size will be needed to reliably fit it.
The plot below shows, for each project (sorted by total person hours, in red), the number of elapsed days from start of first to end of last task (green), and number of people who worked on at least one task (blue) (projects implemented by a single person do not have consistent time data; code+data):
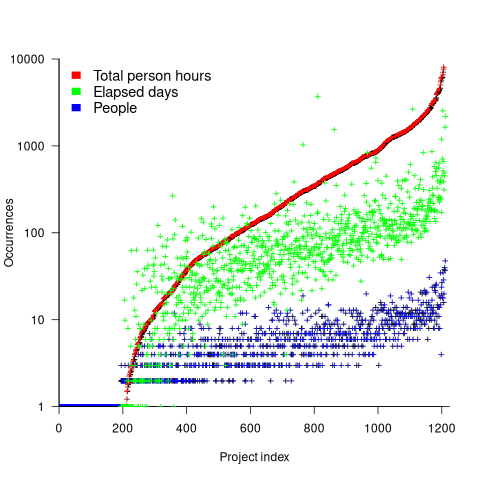
For a given number of person hours worked on a project, there is an order of magnitude variation in elapsed days and number of people who worked on at least one task.
This dataset contains a huge amount of detail, and I’m sure there are lots of patterns to be found. But, what are the important questions to ask, that would be useful to project managers. When I ask managers what project questions they would like answers, the response is often one of quizzical uncertainty. There are plenty of people promoting their opinions, and it’s very rare to encounter anybody asking meaningful questions.
A model of fault experiences for a single functionality program
Some programs perform one basic task, e.g., analyse input to calculate some quantity. These programs often take a set of input values and produce some output.
If a program contains a single coding mistake  and the probability of producing incorrect output, for one set of inputs, is
and the probability of producing incorrect output, for one set of inputs, is  , the probability of the ‘th output being incorrect is:
, the probability of the ‘th output being incorrect is: ^(d-1)") . This is a geometric distribution (an exponential distribution is a good enough approximation). The value can be thought of as the distance between incorrect outputs, measured in the number of distinct inputs correctly processed.
. This is a geometric distribution (an exponential distribution is a good enough approximation). The value can be thought of as the distance between incorrect outputs, measured in the number of distinct inputs correctly processed.
If the program contains a second, different, coding mistake,  whose probability of producing incorrect output, for a given input, is
whose probability of producing incorrect output, for a given input, is  , the probability of incorrect output after inputs is now:
, the probability of incorrect output after inputs is now: ![(p_1+p_2)*[(1-p_1)*(1-p_2)]^(d-1)](https://shape-of-code.com/wp-content/plugins/wpmathpub/phpmathpublisher/img/math_982_853913cb24fec2f10818b3919fd640c5.png "(p_1+p_2)*[(1-p_1)*(1-p_2)]^(d-1)") . And so on for each distinct coding mistake.
. And so on for each distinct coding mistake.
The value of is driven by the likelihood that the input values cause the program’s flow of control to reach the code containing the coding mistake, and then for the execution of the coding mistake to produce a value that percolates through the executed code to produce an incorrect output value. It might be said that users cause faults by providing the necessary input values.
Each  in the expression
in the expression ![(p_1+p_2+...+p_n)*[(1-p_1)*(1-p_2)*(...)*(1-p_n)]^(d-1)](https://shape-of-code.com/wp-content/plugins/wpmathpub/phpmathpublisher/img/math_982_86feb9ecd2aee2f767263419ffc8aca4.png "(p_1+p_2+...+p_n)*[(1-p_1)*(1-p_2)*(...)*(1-p_n)]^(d-1)") is created by the distinct coding mistakes,
is created by the distinct coding mistakes,  .
.
In practice the number of distinct coding mistakes, , is unknown, and a single probability is assigned to incorrect output:  , giving:
, giving: ^(d-1)") (the substitution
(the substitution =(1-p_1)*(1-p_2)*(...)*(1-p_n)") is a good enough approximation because the are very small).
is a good enough approximation because the are very small).
How accurate is this model in practice?
The analysis below uses data from my top, must read, paper on software fault analysis and a recent study of LLM driven N-version programming.
The N-Version Programming with Coding Agents tested 1-million inputs/outputs, and 14 of the programs in the published results contained 421 incorrect outputs (data kindly provided by Javier Ron). Before discussing the same incorrect counts, does the ‘distance’ between incorrect outputs have an exponential distribution?
This question can be answered using an exponential Q-Q plot (values predicted by theory on the x-axis, actual values on the y-axis). The plot below shows the actual values (blue/green) and a fitted regression line (data from running the claude_code__m_claude-haiku-4.5__l_rust__run000 generated code; code+data):
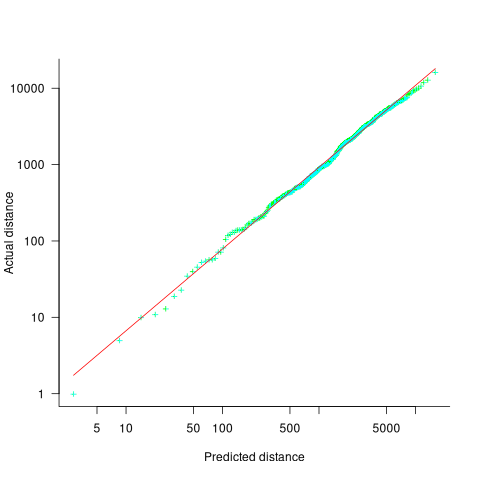
If the data had an exponential distribution the exponent of a fitted power law would be exactly 1. However, the fitted exponent is 1.07, and is statistically significant (for the sample size and standard error of the fit).
The above analysis assumes that the probability of incorrect output,  , is constant. In practice varies across different input values, but over very many inputs is assumed to be clustered around an unchanging average value. It is possible that the input values are divided into two clusters whose incorrect output probabilities are
, is constant. In practice varies across different input values, but over very many inputs is assumed to be clustered around an unchanging average value. It is possible that the input values are divided into two clusters whose incorrect output probabilities are  and
and  , i.e., a mixture of two exponentials. The worst case scenario is a mixture of umpteen exponentials.
, i.e., a mixture of two exponentials. The worst case scenario is a mixture of umpteen exponentials.
Fitting the distance data to a mixture of two exponentials gives: e^{-0.00037}") (code+data). This corresponds to 10% of the input having an average distance between incorrect output of 482, and 90% having a distance of 2,735 (average 2,482), i.e., one cluster of input values is a lot more likely to produce incorrect output than the other cluster. In the published data the average distance is 2,385.
(code+data). This corresponds to 10% of the input having an average distance between incorrect output of 482, and 90% having a distance of 2,735 (average 2,482), i.e., one cluster of input values is a lot more likely to produce incorrect output than the other cluster. In the published data the average distance is 2,385.
The specification used for the N-version studies came from a study by Nagel and Skrivan who tracked down each of the coding mistakes in the programs tested. They found that around 80% of incorrect outputs were caused by the same coding mistake, and 16% by a second coding mistake (see figure 4.3.7.1-1; an analysis of the Knight & Leveson coding mistakes). Once these two coding mistakes were fixed, other coding mistakes caused incorrect output.
For the LLM generated code, 14 out of the 59 programs had 421 incorrect outputs. Did the LLMs all generate code containing the same coding mistake? I have yet to track down any of the coding mistakes, or get an LLM to do it for me. Once a few coding mistakes have been fixed, ‘allowing’ other coding mistakes to produce incorrect output, will partially correct LLM generated programs stop having correlated failures?
How much does the number of incorrect output change when a different set of random inputs are used?
The random seed used in the published results is: 42. I replicated this output for all 56 programs (it takes around 8.5 hours on my system), and then ran the 1-million inputs on just four programs using the seeds: 101, 20101, 321, 789, and 6000 (which each took around 1-hour). The table below shows the number of incorrect outputs for the various seeds (each numeric column corresponds to a different seed):
Generation information Number of incorrect outputs claude_code__m_claude-haiku-4.5__l_rust 421 432 374 404 424 452 codex__m_gpt-5.1-codex__l_pascal 421 431 372 402 424 451 claude_code__m_claude-sonnet-4.6__l_pascal 1222 1224 1214 1237 1207 1282 codex__m_gpt-5.4-mini__l_python 10052 10063 10181 9944 9963 10122 |
Two (claude_code__m_claude-haiku-4.5__l_rust and codex__m_gpt-5.1-codex__l_pascal) of the 14 programs that had the same number of incorrect outputs with seed 42, had slightly different number of incorrect outputs with other seeds. This suggests that their coding mistakes are slightly different.
All the generated programs had some deviation from the pure single exponential model discussed above.
This simple model for ‘distance’ between incorrect outputs is a good fit to reality because the program performs one basic function and is relatively short (around 500 lines). Larger programs supporting a selection of functionality are going to require much more complicated models.
Reliability via N-version programming?
N-version programming was first proposed in 1978, probably the most known paper on the subject was published in 1986, after which activity was mostly within safety-critical systems circles. Cost was a major issue, it’s expensive to create one version of a program, and producing independent versions is around times more expensive.
Now that LLM have significantly reduced the cost of creating programs, people have started to experiment with creating many versions of a specification.
In the past, interest in N-version programming focused on reliability. The idea is that independent implementations of the same specification will contain different coding mistakes, and that when a fault is experienced in one implementation the others will behave as intended, e.g., in a system with  , a two-out-of-three vote is enough to ensure correct behavior.
, a two-out-of-three vote is enough to ensure correct behavior.
The 1986 Knight and Leveson paper found that coding mistakes were correlated, i.e., different implementations, written by different people, sometimes contained the same mistake (so three systems might not be enough to ensure high reliability). The results were replicated, with varying percentages of total and common faults experienced. The possibility that using the same specification for all implementations might be a significant contributor to common mistakes is often raised, but I am not aware of any published studies. There are also implementations issues such as the fuzziness of floating-point arithmetic.
On Monday this week the paper: Do programming languages still matter to your AI coding agent teammate? Evidence at scale from chess engines discussed using LLMs to create 34 chess engines spanning 17 programming languages, and on Thursday the paper N-Version Programming with Coding Agents by Ron, Baudry, and Monperrus (RBM) replicated the Knight/Leveson (KL) paper using programs generated by a variety of LLMs from the specification used by KL (originally used in my top, must-read paper on software fault analysis).
How did the KL and RBM results compare? The KL study involved 27 students each creating an implementation of the same specification in Pascal and had to pass an acceptance test containing 200 tests (randomly generated for each implementation, to prevent filtering of shared faults). The RBM study created 69 implementations (23 in each of Pascal, Python and Rust) of the same KL specification using different coding agents from five vendors. Implementations that failed the acceptance test (10 Pascal, 5 Python, 6 Rust) were not given the opportunity to fix the code.
Each implementation was given the same set of 1-million inputs, and the results compared against those obtained from an Oracle. Based on the number of times each implementation failed (i.e., produced incorrect output), and assuming that each implementation’s failures are independent of other implementations, it’s possible to calculate the expected number of cases where two or more distinct implementations fail on the same input (Kimi steps through the maths). The expected number of multiple failures on the same input is (the actual numbers are in brackets): KL 127 (1,255); RBM Pascal 6 (426), Python 57 (424), Rust 6 (424).
There are a lot more actual instances of two or more implementations failing on the same input, than would be the case if the failures were independent of each other (the statistical analysis shows that the much larger values are extremely unlikely; code+data). The implication is that similar coding mistakes are being made across implementations, leading to correlated failures.
The error rates for the LLM generated programs look a lot lower than those in the KL study. Are the LLM generated programs more reliable than the human written programs? Later studies with human subjects also had a much lower error rate, suggesting that the higher error rate in the KL study was caused by the use of student subjects.
Fans of a particular language will often claim that it has various desirable characteristics, e.g., readability, maintainability and reliability. There is no evidence for any of these claims, and I have always thought that, post-release of the program, programming language is essentially irrelevant. Mistakes and assumptions tend to be language independent. This small sample of programs for one problem don’t show any significant differences between languages (perhaps there is one, but a much larger sample will be needed to see it). In the past, multi-language studies have often used examples from Rosetta Code (also see sections 2.5 and 7.2.9 of my book). Given the perennial interest in comparing programming languages, I am expecting many papers on the subject over the next few years.
A more interesting question is the variability in the source code generated by different LLMs, for the same specification. I am expecting that it will contain some of the patterns in human written code, as well as some patterns of human variation.
Perhaps LLM source code generation does not need to become as reliable as compiler machine code generation, vendors just have to make sure that the mistakes they make are not correlated.
Statistical note: KL uses the Wald interval to estimate the statistical significance (and RBM replicates). There are issues with this approximation when the probability of failure is close to zero (it does not matter here because the difference between theory and practice is so large). These days libraries implementing the complicated, technically correct, approach are available, e.g., binomtest is in Python’s scipy.stats package and binomial.test is included in R’s base system.
Specification based programming
The use of LLM to write software has focused on integrating them within existing practices, i.e., using LLMs as very fancy auto-completers for chunks of code or functionality. This use is programming by conversation, or less politely, programming by stream of thought. The term vibe-coding creates an illusion of trendiness; after all, software engineering is a hedonistic activity.
With vibe-code on top of vibe-code on top of vibe-code, refactoring becomes a complete rewrite, at least in theory. A rewrite assumes that it’s possible to extract a specification that is complete and accurate enough to recreate the software. A lot of software has a short lifetime, so a major rewrite may never be needed. However, for software that is expected to have a long life, management are going to want a more controlled/structured/repeatable approach.
LLMs’ ability to write software is now good enough to support a more controlled/structured/repeatable approach: Programming by specification. That is a specification of the desired behavior is given to one or more LLMs, which use it to generate the appropriate software.
The human input to the program creation process is via the specification.
Features are changed/added/removed by updating the specification. Bugs are fixed by updating the specification. If there are mistakes in the generated code, the specification has to work around them, in the same way that compiler bugs have to be worked around.
Business logic can be expressed as a specification, which is how application domain experts, who are not programmers, are able to create minimal viable products using LLMs.
How might a specification be created?
Agile has taught the lesson that software creation is an iterative process. Requiring a complete specification before coding starts is the stuff of armchair project managers.
One possible specification iteration process starts with a basic outline specification of what is required, and is followed by the following cycle:
- Using the current specification, developer+LLM produces code. Perhaps particular functionality is implemented, or the work continues for some amount of time, or etc,
- the transcript of the LLM conversation is used to create an updated specification of the code that exists when work stopped. Conversations involving code that came and went is not part of the updated specification, although logging it for future reference costs little,
- a new version of all the software covered by the updated specification is generated. This can be tested using existing tests and also by differential testing using multiple implementations created from the same specification (a recent paper generated five implementations in different languages),
- if more functionality is needed, go to step 1.
Specifications share many characteristics with source code. They can be split up and organized into modules/packages/components/phases, as was done for this LLM generated C compiler.
LLM generated code is more verbose than human generated code, just like the machine code generated by early compilers.
Open source projects could soon just be making the specification available. Why ship the source code generated from a specification, projects don’t ship the assembler code generated by compilers, they ship the original source code. However, given the current reliability of LLM source code generation, they are benefits to making the generated source of at least one implementation available (as a kind of checksum).
Reduced implementation costs, using LLMs, make it possible to create programs containing more functionality (Jevrons paradox in action). This in turned leads to specifications becoming larger, complicated and poorly organized, just like source code.
English usage is full of ambiguities. This ambiguity can be reduced by using a controlled language. If specification programming becomes popular, it’s easy to imagine the invention of controlled languages becoming as popular as the invention of programming languages. In 1957, there were compilers for at least 28 programming languages.
Specification based programming is a continuation of the trend of computers handling more of the details involved in program creation, with the program creation process requiring less and less knowledge about computers. Increasing amounts of computer time are spent to reduce or eliminate developer time.
Programming has evolved from physically connecting subsystems by cables to specify the flow of bits in a punch card computer, to a sequence of machine code instructions executed by a stored-program computer, then high-level programming languages reducing the need to know lots of details about the underlying cpu (details that remain include: number of bits in the integer types and type compatibility rules).
Specification based programming requires discipline, and I don’t expect it to be popular. I expect multiple LLM-derived project disasters need to occur before there are any significant changes to the current LLM approaches to software development.
Waiting times and the task selection process
When working on a project, what process do developers use to select the next task to implement?
One way to answer this question is to ask the developers/managers working on the project. However, these people are not always available, and sometimes the actual process used is not what management say it is.
Analysis of the amount of time a task spends in the queue finds various patterns. A previous post discussed some of the theory and data on the distribution of queue task waiting times.
What can be deduced about the task selection process from data on the time they spend in the queue?
From the theoretical perspective there are three task selection processes:
- select the task with the highest priority. The priority of a task might be set by its age (e.g., FIFO, a first, in first out queue), its value to the business, dependency of other tasks, etc.
The distribution of the number of tasks having a given waiting time on some priority queues is a power law (in a FIFO queue the waiting time distribution depends on the distribution of arrival times of new tasks), i.e.,
 , where
, where  is some constant
is some constant - select a task at random. Random selection comes in various guises including: developers picking what looks to be the most interesting task on the day, or managers deciding that particular functionality would look good during a marketing/sales pitch in a few days.
The distribution of the number of tasks having a given waiting when tasks are selected at random from the queue is an exponential, i.e.,
 , where is some constant,
, where is some constant, - select a fraction,
 , of tasks by highest priority, and select the other fraction,
, of tasks by highest priority, and select the other fraction,  , of tasks at random.
, of tasks at random.
The distribution of the number of tasks having a given waiting when tasks in this process are a combination of power law and exponential, i.e.,
 , where and are constants.
, where and are constants.
The average amount of time a task spends in a queue is given by Little’s law, and is independent of the selection process (high priority tasks have a shorter waiting time than low priority tasks, but the overall average is unchanged), i.e., assuming that the averages, and variance, do not change over time, then: (waiting time) equals (average number of tasks in the queue) divided by (average number of tasks implemented per unit of time).
If analysis of the data finds just a power law, then the selection process involves a power law, just an exponential, then some random process(es), and if a combination distributions then a combination of selection processes.
Can anything be learned from knowing the value of or ?
The analysis of various priority+random models finds that, given enough running time, converges to specific values between 1 and 2. Is waiting time data on, say, 1,000 tasks (with an average of 4-hours per task, this is 2-person years) sufficient running time to converge to a good enough approximation of ?
This question can be answered by simulating task queue waiting times. The plot below shows, for 100 projects, the values of fitted to the power law component of the waiting time distribution of projects each having 1,000 tasks (the queue length was fixed at 10 tasks, five task priorities, with  fraction of tasks selected by priority, and the rest randomly; code):
fraction of tasks selected by priority, and the rest randomly; code):
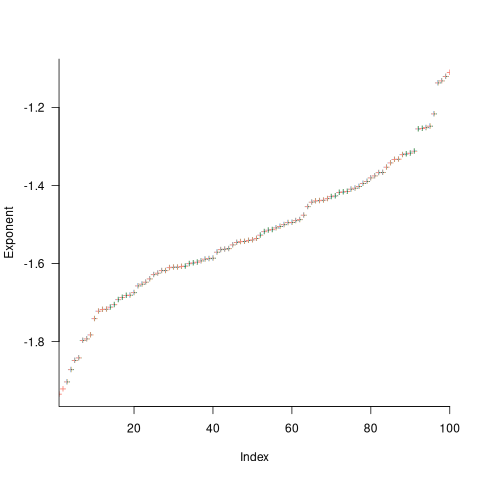
The wide range of fitted exponent values for clearly shows that 1,000 tasks is not sufficient for convergence to a good enough approximation. In fact over 100,000 tasks are needed before exponent values converge within one decimal place.
Similar results are obtained for queue lengths between 5 and 20 tasks, and priority ranges between 3 and 10. Reducing the value of down to 0.7 had a large impact on the tail of the distribution. I have not tried variable length queues.
Sometimes task priorities are changed. One study found that around 8% of bug priorities were changed before the bug was fixed. Simulation found that, when task priorities are changed (at the rate ), rather than randomly selecting a task, the waiting time distribution was a power law (also the long wait time distribution was power law like; code).
Tasks that have spent a long time in the queue are likely to have their priority increased, or be removed from the queue.
If the amount of time spent in the queue contributes some amount of priority to the original task, then the waiting time distribution is exponential (technically it is geometric, the discrete form of exponential; code). The LLM maths assistants did not find any viable equations.
To summarise: The distribution of tasks having a given waiting time has a high variance, which significantly reduces its usefulness for deducing information about the task selection process.
Projects are worked on in fits and starts
Companies whose business is designing, developing, and maintaining custom software applications (i.e., a software house) have the difficult job of keeping their expensive employees busy with paying work. Work on an existing project may be held up for various reasons, and the start date of new projects is invariably uncertain.
A solution to the on/off nature of project work is for staff to distribute their time across multiple projects. If one project is held up, there is another project available for them to book their time to.
The plot below is for project 614 in the CESAW dataset, and shows the days on which 28 people worked on this project between July 2014 and July (code+data):
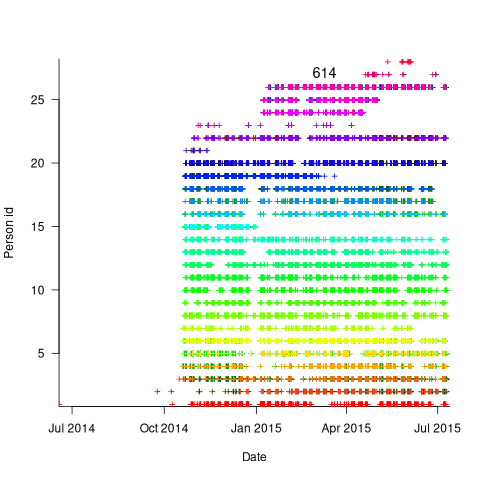
The published models of the software development lifecycle are based on perceptions of the workings of large DOD and NASA projects from the 1960s and 1970s. These projects are treated as self-contained entities, with people being available when needed and individually interchangeable. This perception fits with the software physics thinking of the time, along with the early 1960s work of Norden, and the use of differential equations to model the evolution of project manpower. These models fitted the small amount of available data as well as several other models. With some hand waving it is possible to make models such as the Putnam model look good.
With 28 people working on project 614, it’s possible that individual contributions don’t have a big impact on totals, i.e., the total time spent per week (say) does not fluctuate widely. The plot below shows the total hours per week spent on design, coding and test (total project time as roughly three staff years; code+data):
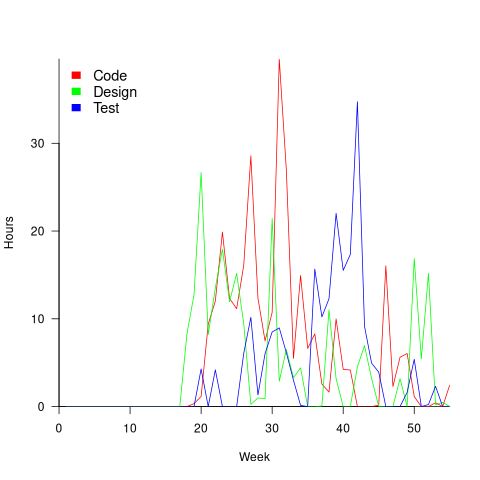
Plenty of wide fluctuations, plus some expected large drops in time spent on the project. For instance, a big drop in all activities around Christmas, and a smaller dip around Thanksgiving.
Having 28 people work on a three-person year project does seem a bit extreme (average of seven-weeks per person). On the other hand, I may be out of date, not having been a team member on a large project in decades.
The total effort required by the projects in the CESAW dataset range from three-person months to three-person years, which I suspect (no data on this question) straddles the range of time spent on the majority of software projects. The projects mostly involve people spending a non-large percentage of time on a project. The data is anonymised on a project basis, and it is not possible to count the number of projects a person is working on at any time.
To summarise: Building a good enough model of software project staffing requires taking into account organization wide staffing priorities. Existing models don’t do this.
Answering via a scale to improve estimation accuracy
The human brain differs from the brain of other animals in having two number processing systems: 1) the approximate number system (present in other animals), and 2) language.
Round numbers are often given in answers when using language, to questions having a numeric answer. While use of round numbers may be conversationally appropriate, they decrease the accuracy of the answer.
Numeric values can be specified without using language. For instance, by pointing at a position on a scale representing a sequence of increasing/decreasing values, such as a ruler. Are answers given by pointing at a scale less likely to be round numbers, and more importantly are they likely to be more accurate than answers given using language?
Various studies by psychologists have investigated response differences between answering using language and scales. The analysis below is based on data from the paper: On the round number bias and wisdom of crowds in different response formats for numerical estimation by Honda, Kagawa and Shirasuna. This study asked 1,805 subjects to estimate the number of dots in an image, like the one below, with images containing: 183, 287, 360, 453, 554, 633, 719, 807, or 986 dots (randomly selected):

Subjects responded using a randomly selected one of six different scales or using language (i.e., typing a number). The scales differed in axis labeling and some were zero based (subjects had to slide the blue colored circle from zero to a position, rather than clicking on a position); see image below:

The plot below shows the normalised occurrences of estimate values (rounded to the nearest value divisible by five) made using language (red) and one of the scales (blue/green), with grey line showing actual number of dots. There was little difference between the various kinds of scales, and all the scale answers have been aggregated (code+data):
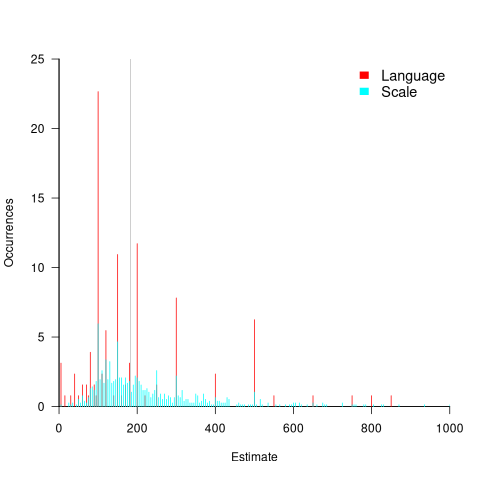
The red spikes clearly show many language given answers are at round numbers. The answers given using a scale are much less likely to be round numbers, with the blue/green lines showing the use of a wider selection of estimates.
Are answers given using language likely to be more or less accurate than answer given using a scale?
The plot above shows that few responses are close to the actual value, which means that no fitted model is going to explain much of the variability in the data. All the regression models I fitted to the difference between answers and actuals found that languages responses were less accurate, on average (code+data). Combining the explanatory variables in a variety of different ways did not significantly affect the quality of the fitted model.
In hand-wavy terms, the average error in the language responses was at most 10% larger than the scale responses.
To summaries, scale responses are likely to be more accurate, but a lot less likely to be a round number.
People are willing to tradeoff accuracy for being able to communicate using a round number. For instance, I once pointed out to a manager that changing all 1-hour estimates to 1.25 hours would significantly improve accuracy; he was unwilling to give up the greater uncertainty implied by the 1-hour estimate.
Will this behavior replicate for software task estimates? Is it possible to shift a scale answer to the closest round number without losing the accuracy advantage?
We will have to wait until somebody does the appropriate study.
Recent Comments