Archive
Extracting named entities from a change log using an LLM
The Change log of a long-lived software system contains many details about the system’s evolution. Two years ago I tried to track the evolution of Beeminder by extracting the named entities in its change log (named entities are the names of things, e.g., person, location, tool, organization). This project was pre-LLM, and encountered the usual problem of poor or non-existent appropriately trained models.
Large language models are now available, and these appear to excel at figuring out the syntactic structure of text. How well do LLMs perform, when asked to extract named entities from each entry in a software project’s change log?
For this analysis I’m using the publicly available Beeminder change log. Organizations may be worried about leaking information when sending confidential data to a commercially operated LLM, so I decided to investigate the performance of a couple of LLMs running on my desktop machine (code+data).
The LLMs I used were OpenAI’s ChatGPT plus (the $20 month service), and locally: Google’s Gemma (the ollama 7b model), a llava 7b model (llava-v1.5-7b-q4.llamafile), and a Mistral 7b model (mistral-7b-instruct-v0.2.Q8_0.llamafile). I used 7 billion parameter models locally because this is the size that is generally available for Open sourced models. There are a few models supporting the next step-up, at 13 billion parameters, and a few at 30 billion.
All the local models start a server at localhost:8080, and provide various endpoints. Mozilla’s llamafile based system is compatible with OpenAI’s python package openai. The documentation for the Gemma based system I installed uses the ollama package. In both cases, the coding required is trivial; just add a few statements to create a question based on command line input:
import openai import sys prefix='List the named entities in the following sentences: ' input_str=sys.argv[1] # change log entry from command line client = openai.OpenAI( base_url="http://localhost:8080/v1", # "http://<Your api-server IP>:port" api_key = "sk-no-key-required" ) stream = client.chat.completions.create( model="gpt-4", stream=True, temperature=0, seed=19, messages=[ {"role": "system", "content": "You are ChatGPT, an AI assistant. Your top priority is achieving user fulfilment via helping them with their requests."}, {"role": "user", 'content': prefix+ input_str } ] ) # Print response for chunk in stream: print(chunk.choices[0].delta.content or "", end="") print() |
How well did the models perform?
For rapid iteration, I used the web interface to ChatGPT. The responses started to appear within a few seconds and were displayed at a readable rate.
ChatGPT 3.5
When given a single change log entry, ChatGPT also provides a brief description of the named entity. In the following example, ‘twitter acct‘ and ‘blog posts‘ are not flagged as named entities:
User
print the named entities in the following quoted text "Created
this twitter acct to log user-visible improvements (UVIs) to
Beeminder. (Yes, this is a UVI. Everything counts no matter how
small!) Very first UVI! Back then this counted but nowadays we
don't count things that are too ancillary like making Twitter
accounts or writing blog posts. We did count a few UVIs for
creating this fancy changelog but decided that's too ancillary
now too."
ChatGPT
To identify named entities in the quoted text, we need to look for
proper nouns, which typically include names of specific people,
organizations, locations, and sometimes unique entities. In the
provided text, here are the named entities:
Beeminder - Refers to a specific service or product.
Twitter - Refers to a specific social media platform.
UVI (User-Visible Improvement) - Refers to a specific type of improvement.
changelog - Refers to a specific type of document or record. |
When asked to list the named entities in each of multiple lines, ChatGTP 3.5 performance drops. In the following response, the first line is identical to the example above; the response contains three, not four names entities. The second line contains named entities, but ChatGTP claims there are none. The response to the third line is accurate:
ChatGPT
Here are the named entities in each of the three lines:
"Created this twitter acct" line:
Twitter - Refers to a specific social media platform.
UVIs (User-Visible Improvements) - Refers to a specific
type of improvement.
Beeminder - Refers to a specific service or product.
"Added ridiculous dog-dressed-as-a-bee picture" line:
None
"Now suppressing reminder emails" line:
reminder emails - Refers to a specific type of communication.
bug fixes - Refers to a specific type of improvement aimed
at resolving software issues.
UVIs (User-Visible Improvements) - Refers to a specific
type of improvement. |
ChatGPT 4.0
ChatGPT 4.0 can handle multiple change log entries. The following is the response to the first three entries (the same three entries given the ChatGPT 3.5):
ChatGPT
To thoroughly identify the named entities within each line,
I'll systematically parse each one, focusing on extracting
specific types of entities such as organizations, people,
locations, dates, websites, and any other identifiable proper
nouns.
Beeminder, Twitter, UVI: Organizations or products.
dog-dressed-as-a-bee: Concept, not a proper noun but unique
enough to note.
reminder emails: Concept, referring to a feature. |
While it is possible to input 100 change log entries into the ChatGPT input box, the response contained no more than about 25 of them (there is a maximum limit on the number of input and output tokens).
Running locally
The machine I used locally contains 64G memory and an Intel Core i5-7600K running at 3.80GHz, with four cores. The OS is Linux Mint 21.1, running the kernel 5.15.0-76-generic. I don’t have any GPUs installed.
A GPU would probably significantly improve performance. On Amazon, the price of the NVIDIA Tesla A100 is now just under £7,000, an order of magnitude more than I am interested in paying (let alone the electricity costs). I have not seen any benchmarks comparing GPU performance on running LLMs locally, but then this is still a relatively new activity.
Overall, Gemma produced the best responses and was the fastest model. The llava model performed so poorly that I gave up trying to get it to produce reasonable responses (code+data). Mistral ran at about a third the speed of Gemma, and produced many incorrect named entities.
As a very rough approximation, Gemma might be useful. I look forward to trying out a larger Gemma model.
Gemma
Gemma took around 15 elapsed hours (keeping all four cores busy) to list named entities for 3,749 out of 3,839 change log entries (there were 121 “None” named entities given). Around 3.5 named entities per change log entry were generated. I suspect that many of the nonresponses were due to malformed options caused by input characters I failed to handle, e.g., escaping characters having special meaning to the command shell.
For around about 10% of cases, each named entity output was bracketed by “**”.
The table below shows the number of named entities containing a given number of ‘words’. The instances of more than around three ‘words’ are often clauses within the text, or even complete sentences:
# words 1 2 3 4 5 6 7 8 9 10 11 12 14 Occur 9149 4102 1077 210 69 22 10 9 3 1 3 5 4 |
A total of 14,676 named entities were produced, of which 6,494 were unique (ignoring case and stripping **).
Mistral
Mistral took 20 hours to process just over half of the change log entries (2,027 out of 3,839). It processed input at around 8 tokens per second and output at around 2.5 tokens per second.
When Mistral could not identify a named entity, it reported this using a variety of responses, e.g., “In the given …”, “There are no …”, “In this sentence …”.
Around 5.8 named entities per change log entry were generated. Many of the responses were obviously not named entities, and there were many instances of it listing clauses within the text, or even complete sentences. The table below shows the number of named entities containing a given number of ‘words’:
# words 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Occur 3274 1843 828 361 211 130 132 90 69 90 68 46 49 27 |
A total of 11,720 named entities were produced, of which 4,880 were unique (ignoring case).
A distillation of Robert Glass’s lifetime experience
Robert Glass is a software engineering developer, manager, researcher and author who, until six months ago, I had vaguely heard of; somehow I had missed reading any of his 25 books. After seeing citations to some of Glass’s books, I bought half-a-dozen or so, second hand. They are well written, and twenty-five years ago I would have found them very interesting; now I simply agree with the points made.
“software creativity 2.0” is Glass’s penultimate book, published in 2006, and the one that caught my attention. I would recommend his other books to anybody who is new to software engineering, or experienced people looking for an encapsulation in print of what they encounter at work.
Glass was 74 when this book was published, having started working in computing in 1954. He was there and seems to have met many of the major names in software engineering, working with some of them.
The book is a clear-eyed summary of what Glass has learned from being involved with software engineering, and watching method/tool fashions come and go. My favourite section draws parallels between software development cultures and the culture of Rome vs. Greek vs. Barbarian:
Models Roman Greek Barbarians Organization Organize people Organize things Barely Focus Manages projects Writes programs Leap to coding Motivation Group goals Problem to be solved Heroics Working style Organizations Small groups Solo Politics Imperial Democratic Anarchist Tool use People are tools Things are tools Avoid tools Status Function-ocracy Meritocracy Fear-ocracy Activities Plan things Do things Break things Emphasize Form Substance Line of code |
The contents are essentially a collection of short essays, organized under the 19 chapter headings below, which in turn are grouped into four parts. The first nine chapters (part I, and 60% of pages) contain the experience based material, with the subsequent parts/pages having a creativity theme. A thread running through the discussion is idealism/practice:
Discipline vs. Flexibility
Formal methods versus Heuristics
Optimizing versus Satisficing
Quantitative versus Qualitative Reasoning
Process versus Product
Intellect vs. Clerical Tasks
Theory vs. Practice
Industry vs. Academe
Fun versus Getting Serious
Creativity in the Software Organization
Creativity in Software Technology
Creative Milestones in Software History
Organizational Creativity
The Creative Person
Computer Support for Creativity
Creativity Paradoxes#'twas Always Thus
A Synergistic Conclusion
Other Conclusions |
This book deserves to be widely read. I found it best to read a single section per sitting.
Some information on story point estimates for 16 projects
Issues in Jira repositories sometimes include an estimate, in story points, but no information on time to complete (an opening/closing date is usually available; in some projects issues pass through various phases, and enter/exit date/time may be available).
Evidence-based software engineering is a data driven approach to figuring out software development processes. At the practical level, data is usually hard to come by; working with whatever data is available, an analysis may feel like making a prophecy based on examining animal entrails.
Can anything be learned from project issue data that just contains story point estimates? Let’s go on a fishing expedition.
My software data collection includes a paper that collected 23,313 story point estimates from 16 projects (the authors tried to predict an estimate, in story points, for an issue based on its description). If nothing else, this data is a sample of what might be encountered in other projects.
Developers estimating with story points often select values from the Fibonacci sequence, while developers estimating using hours/minutes often use round numbers. The granularity of both the Fibonacci values and round numbers follow the same exponential growth pattern. In terms of granularity, estimating story points in Fibonacci values need not far removed from estimating time in round numbers.
The number of story points per project varied from 352 to 4,667, with a mean of 1,457.
The plots below show the number of issues (y-axis, normalised across projects) estimated to require a given number of story points (x-axis), for 16 projects, with projects clustered by peak story point value (i.e., a project’s most frequently used story point value; code+data):
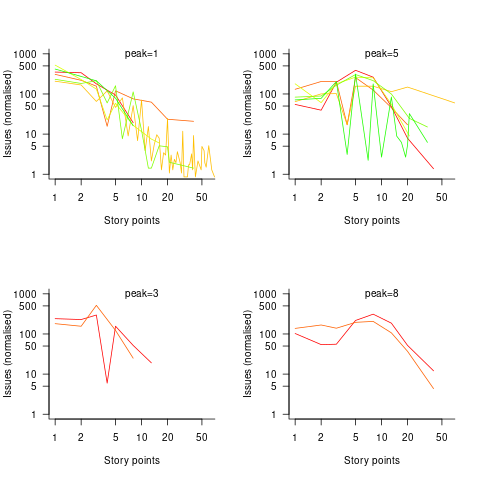
Are the projects with estimate peaks at 3 and 8 story points a quirk of this dataset, or is it to be expected that around 10% of projects will peak at one of these values?
For me, what jumps out of these plots is the number and extent of 4 story point estimates. Perhaps it’s just a visual effect, the actual number is an order of magnitude less than for 3 and 5 story points.
The plot below shows the percentage of estimated story points that are not Fibonacci numbers, sorted by project (the one project not showing has 0%; code+data):
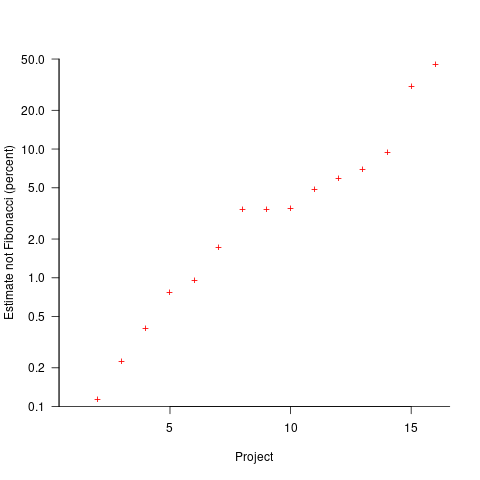
If nothing else, these plots provide a base to start from, and potentially claim to have seen this pattern before.
Why did organizations fund the creation of the first computers?
What were the events that drove organizations to fund the creation of the first computers?
I suspect that many readers do not appreciate how long scientific/engineering calculations took before electronic computers became available, or the huge number of clerical staff employed to process the paperwork associated with running any sizeable business.
If somebody wanted to know the logarithm of some value, or the sine/cosine of an angle, they looked up the answer in a table. Individuals owned small booklets of tables supplying some level of granularity and number of significant digits. My school boy booklet contains 60-pages of tables, all to five digits of output accuracy, with logarithm supporting four-digit input values and the sine/cosine/tangent tables having an input granularity of hundredth of a degree.
The values in these tables were calculated by human computers; with the following being among the most well known (for more details, see Calculation and Tabulation in the Nineteenth Century: Airy versus Babbage by Doron Swade, and The History of Mathematical Tables: from Sumer to Spreadsheets edited by Campbell-Kelly, Croarken, Flood, and Robson):
- In 1624 Henry Briggs published logarithms for the integer ranges 1-20,000 and 90,001-100,000 (to 14 decimal places), followed some years later by tables of sine and logarithm of sine; in 1628 Adriaan Vlacq publishing tables that filled in the missing values (to 10 decimal places). In 1783 Jurij Vega published a bug-fixed and extended version of Vlacq’s tables.
In 1827 Charles Babbage (that Babbage) published Table of Logarithms of the Natural Numbers from 1 to 10800. These tables were based on corrected versions of these tables, a rigorous nine-stage proofreading process was followed to prevent new mistakes creeping in.
Today, one person can publish A reconstruction of the tables of Briggs’ Arithmetica logarithmica (1624), with an appendix containing 300 pages of calculated values,
- between 1794 and 1799, Gaspard de Prony employed sixty to eighty computers to calculate the logarithms of the integers from 1 to 200,000 to fifteen significant digits (rounding issues sometimes required calculating 25 decimal digits; published in eighteen volumes). Around 400 man-years.
Logarithms and trigonometric functions are very widely used, creating incentives for investing in calculating and publishing tables. While it may be financially worthwhile investing in producing tables for some niche markets (e.g. Life tables for insurance companies), there is an unmet demand that will only be filled by a dramatic drop in the cost of computing simple expressions.
Babbage’s Difference engine was designed to evaluate polynomial expressions and print the results; perfect for publishing tables. While Babbage did not build a Difference engine, starting in 1837, engines based on Babbage’s design were built and sold commercially by the Swede Per Georg Scheutz.
Mechanical calculators improve accuracy and speed the process up. Vacuum tubes are invented in 1904 and become widely used to process analogue signals. World War II created an urgent demand for the results of a variety of time-consuming calculations, e.g., accurate ballistic tables, and valve computers were built. The plot below shows the cost per million operations for manual, mechanical and valve computers (code+data):
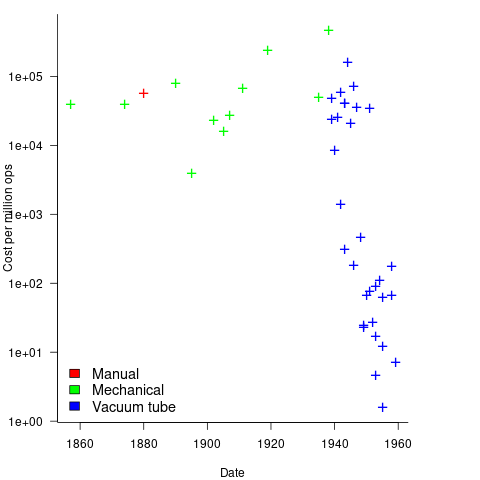
To many observers at the start of the 1950s, the market for electronic computers appeared to be organizations who needed to perform large amounts of scientific/engineering calculation.
Most businesses perform simple calculations on many unrelated values, e.g., banks have to credit/debit the appropriate account when money is deposited/withdrawn. There is no benefit in having a machine that can perform hundreds of calculations per second unless it can be fed data fast enough to keep it busy.
It so happened that, at the start of the 1950s, the US banking system was facing a crisis, the growth in the number of cheques being written meant that it would soon take longer than one day to process all the cheques that arrived in one day. In 1950 Bank of America managed 4.6 million checking accounts, and were opening 23,000 new account per month. Bank of America was then the largest bank in the world, and had a keen interest in continued growth. They funded the development of a bespoke computer system for processing cheques, the ERMA Banking system, which went live in 1959. The plot below shows the number of cheques processed per year by US banks (code+data):
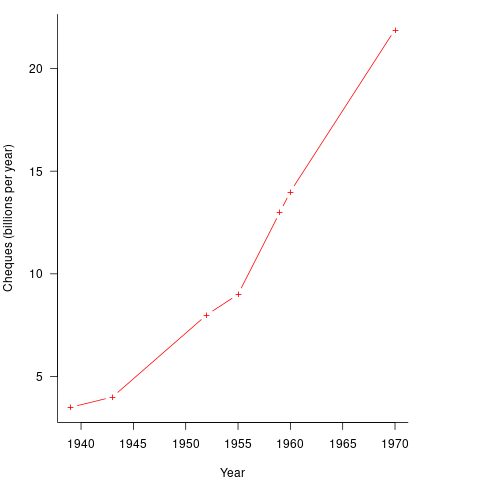
The ERMA system included electronic storage for holding account details, and data entry was speeded up by encoding account details on a magnetic strip included within every cheque.
Businesses are very interested in an integrated combination of input devices plus electronic storage plus compute. There are more commerce oriented businesses than scientific/engineering businesses, and commercial businesses usually have a lot more money to spend, i.e., the real money to be made by selling computers was the business data processing market.
The plot below shows the decreasing cost of hard disc storage (blue, right axis), along with the decreasing computing cost of valve based computers (red, left axis; code+data):
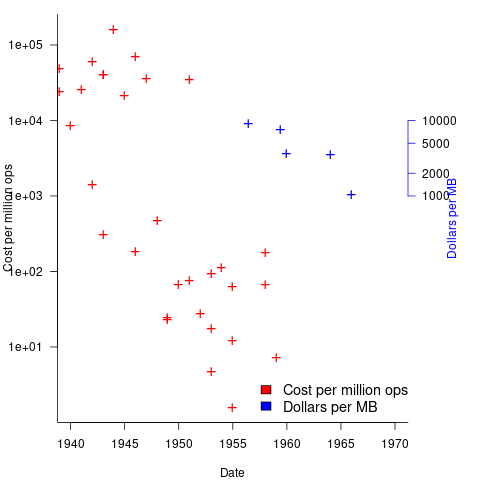
There was a larger business demand to be able to store information electronically, and the hard disc was invented by IBM, roughly 15 years after the first electronic computers.
The very different application demands of data processing and scientific/engineering are reflected in the features supported by the two languages designed in the 1950s, and widely used for the rest of the century: Cobol and Fortran.
Data processing involves simple operations on large quantities of data stored in a potentially huge number of different combinations (the myriad of mechanical point-of-sale terminals stored data in a myriad of different formats, which evolved over time, and the demand for backward compatibility created spaghetti data well before spaghetti code existed). Cobol has extensive functionality supporting the layout and format of input and output data, and simplistic coding constructs.
Scientific/engineering code involves complex calculations on some amount of input. Fortran has extensive functionality supporting program control flow, and relatively basic support for data input/output.
A third major application domain is real-time processing, such as SAGE. However, data on this domain is very hard to find, so it is not discussed.
Recent Comments