Archive
Reliability via N-version programming?
N-version programming was first proposed in 1978, probably the most known paper on the subject was published in 1986, after which activity was mostly within safety-critical systems circles. Cost was a major issue, it’s expensive to create one version of a program, and producing  independent versions is around times more expensive.
independent versions is around times more expensive.
Now that LLM have significantly reduced the cost of creating programs, people have started to experiment with creating many versions of a specification.
In the past, interest in N-version programming focused on reliability. The idea is that independent implementations of the same specification will contain different coding mistakes, and that when a fault is experienced in one implementation the others will behave as intended, e.g., in a system with  , a two-out-of-three vote is enough to ensure correct behavior.
, a two-out-of-three vote is enough to ensure correct behavior.
The 1986 Knight and Leveson paper found that coding mistakes were correlated, i.e., different implementations, written by different people, sometimes contained the same mistake (so three systems might not be enough to ensure high reliability). The results were replicated, with varying percentages of total and common faults experienced. The possibility that using the same specification for all implementations might be a significant contributor to common mistakes is often raised, but I am not aware of any published studies. There are also implementations issues such as the fuzziness of floating-point arithmetic.
On Monday this week the paper: Do programming languages still matter to your AI coding agent teammate? Evidence at scale from chess engines discussed using LLMs to create 34 chess engines spanning 17 programming languages, and on Thursday the paper N-Version Programming with Coding Agents by Ron, Baudry, and Monperrus (RBM) replicated the Knight/Leveson (KL) paper using programs generated by a variety of LLMs from the specification used by KL (originally used in my top, must-read paper on software fault analysis).
How did the KL and RBM results compare? The KL study involved 27 students each creating an implementation of the same specification in Pascal and had to pass an acceptance test containing 200 tests (randomly generated for each implementation, to prevent filtering of shared faults). The RBM study created 69 implementations (23 in each of Pascal, Python and Rust) of the same KL specification using different coding agents from five vendors. Implementations that failed the acceptance test (10 Pascal, 5 Python, 6 Rust) were not given the opportunity to fix the code.
Each implementation was given the same set of 1-million inputs, and the results compared against those obtained from an Oracle. Based on the number of times each implementation failed (i.e., produced incorrect output), and assuming that each implementation’s failures are independent of other implementations, it’s possible to calculate the expected number of cases where two or more distinct implementations fail on the same input (Kimi steps through the maths). The expected number of multiple failures on the same input is (the actual numbers are in brackets): KL 127 (1,255); RBM Pascal 6 (426), Python 57 (424), Rust 6 (424).
There are a lot more actual instances of two or more implementations failing on the same input, than would be the case if the failures were independent of each other (the statistical analysis shows that the much larger values are extremely unlikely; code+data). The implication is that similar coding mistakes are being made across implementations, leading to correlated failures.
The error rates for the LLM generated programs look a lot lower than those in the KL study. Are the LLM generated programs more reliable than the human written programs? Later studies with human subjects also had a much lower error rate, suggesting that the higher error rate in the KL study was caused by the use of student subjects.
Fans of a particular language will often claim that it has various desirable characteristics, e.g., readability, maintainability and reliability. There is no evidence for any of these claims, and I have always thought that, post-release of the program, programming language is essentially irrelevant. Mistakes and assumptions tend to be language independent. This small sample of programs for one problem don’t show any significant differences between languages (perhaps there is one, but a much larger sample will be needed to see it). In the past, multi-language studies have often used examples from Rosetta Code (also see sections 2.5 and 7.2.9 of my book). Given the perennial interest in comparing programming languages, I am expecting many papers on the subject over the next few years.
A more interesting question is the variability in the source code generated by different LLMs, for the same specification. I am expecting that it will contain some of the patterns in human written code, as well as some patterns of human variation.
Perhaps LLM source code generation does not need to become as reliable as compiler machine code generation, vendors just have to make sure that the mistakes they make are not correlated.
Statistical note: KL uses the Wald interval to estimate the statistical significance (and RBM replicates). There are issues with this approximation when the probability of failure is close to zero (it does not matter here because the difference between theory and practice is so large). These days libraries implementing the complicated, technically correct, approach are available, e.g., binomtest is in Python’s scipy.stats package and binomial.test is included in R’s base system.
Specification based programming
The use of LLM to write software has focused on integrating them within existing practices, i.e., using LLMs as very fancy auto-completers for chunks of code or functionality. This use is programming by conversation, or less politely, programming by stream of thought. The term vibe-coding creates an illusion of trendiness; after all, software engineering is a hedonistic activity.
With vibe-code on top of vibe-code on top of vibe-code, refactoring becomes a complete rewrite, at least in theory. A rewrite assumes that it’s possible to extract a specification that is complete and accurate enough to recreate the software. A lot of software has a short lifetime, so a major rewrite may never be needed. However, for software that is expected to have a long life, management are going to want a more controlled/structured/repeatable approach.
LLMs’ ability to write software is now good enough to support a more controlled/structured/repeatable approach: Programming by specification. That is a specification of the desired behavior is given to one or more LLMs, which use it to generate the appropriate software.
The human input to the program creation process is via the specification.
Features are changed/added/removed by updating the specification. Bugs are fixed by updating the specification. If there are mistakes in the generated code, the specification has to work around them, in the same way that compiler bugs have to be worked around.
Business logic can be expressed as a specification, which is how application domain experts, who are not programmers, are able to create minimal viable products using LLMs.
How might a specification be created?
Agile has taught the lesson that software creation is an iterative process. Requiring a complete specification before coding starts is the stuff of armchair project managers.
One possible specification iteration process starts with a basic outline specification of what is required, and is followed by the following cycle:
- Using the current specification, developer+LLM produces code. Perhaps particular functionality is implemented, or the work continues for some amount of time, or etc,
- the transcript of the LLM conversation is used to create an updated specification of the code that exists when work stopped. Conversations involving code that came and went is not part of the updated specification, although logging it for future reference costs little,
- a new version of all the software covered by the updated specification is generated. This can be tested using existing tests and also by differential testing using multiple implementations created from the same specification (a recent paper generated five implementations in different languages),
- if more functionality is needed, go to step 1.
Specifications share many characteristics with source code. They can be split up and organized into modules/packages/components/phases, as was done for this LLM generated C compiler.
LLM generated code is more verbose than human generated code, just like the machine code generated by early compilers.
Open source projects could soon just be making the specification available. Why ship the source code generated from a specification, projects don’t ship the assembler code generated by compilers, they ship the original source code. However, given the current reliability of LLM source code generation, they are benefits to making the generated source of at least one implementation available (as a kind of checksum).
Reduced implementation costs, using LLMs, make it possible to create programs containing more functionality (Jevrons paradox in action). This in turned leads to specifications becoming larger, complicated and poorly organized, just like source code.
English usage is full of ambiguities. This ambiguity can be reduced by using a controlled language. If specification programming becomes popular, it’s easy to imagine the invention of controlled languages becoming as popular as the invention of programming languages. In 1957, there were compilers for at least 28 programming languages.
Specification based programming is a continuation of the trend of computers handling more of the details involved in program creation, with the program creation process requiring less and less knowledge about computers. Increasing amounts of computer time are spent to reduce or eliminate developer time.
Programming has evolved from physically connecting subsystems by cables to specify the flow of bits in a punch card computer, to a sequence of machine code instructions executed by a stored-program computer, then high-level programming languages reducing the need to know lots of details about the underlying cpu (details that remain include: number of bits in the integer types and type compatibility rules).
Specification based programming requires discipline, and I don’t expect it to be popular. I expect multiple LLM-derived project disasters need to occur before there are any significant changes to the current LLM approaches to software development.
Software task estimation using LLMs is fake research
Developers hate having to provide an estimate for the time needed to implement some functionality. Given the extent to which LLMs have become embedded in the software world, offloading the estimation question to an LLM appears to be an obvious solution.
The problem is that LLMs are very unlikely to give a meaningful answer. However, given that 33% of human estimates are accurate (for tasks of a few hours), 66% within a factor of two (over or under), and 95% within a factor of four (over or under), the accuracy bar for LLMs is low.
Given enough training data, LLMs can do amazing things, e.g., help solve difficult maths problems. LLMs often being good-enough at producing source code is dependent on them having been trained on huge amounts of source code.
The miniscule amount of publicly available software task estimation data is orders of magnitude smaller than the quantity needed to effectively fine-tune a software oriented LLM. Estimation training data needs to contain the following information:
- an appropriately detailed description of the problem,
- the source code of the program being updated, as it existed prior to this or any later features being added (similar descriptions may involve different implementation activities on different projects),
- the actual implementation time,
- a summary of the skill set of the developers who did the work (a developer familiar with the source is likely to complete a task faster than a developer new to the project).
There are datasets (here {10K rows} and here {62K rows}) that contain items (1) and (3).
There are datasets (e.g., here {37K rows} and here {23K rows}) that contain (1) for Open source projects, so (2) could be obtained. These datasets contain estimates (usually in Story Points), and a handful of recorded actuals (and often a status change date-time for each issue, which might/perhaps/maybe used as a proxy for actual work time).
Estimation data (in story points, function points, or time) is much more common than Actual (when available, usually time). Needless to say, there are papers (e.g., here and here) that use human estimation data for training, and then measure LLM performance on close it comes to the human estimates, not the actuals.
My 2024 summary of what is known about task estimation did not discuss the impact of LLMs. What was known is 2024 is that several human factors (e.g., use of round numbers and individual risk profile) play a major role in task estimation. LLMs may reduce the time needed for some tasks, but the human factors remain.
The use of round numbers is deeply embedded in the brain. I suspect the impact of LLM usage will not be to reduce implementation time estimates for tasks, but to increase the amount of functionality included in a task to match the established round number times of 1,2,4 and 7 hours.
Users of story points have the option of leaving everything unchanged. However, there are users of story points who equate one story point to one hour. Will the amount of task functionality be increased to maintain this equating?
Users of function points can continue to count them in the same way. What changes, in an LLM world, is the cost of implementing a function point. Given that the method of calculating the number of function points is specified in various national/international standards, it is not possible to simply increase the amount of functionality to maintain the existing price of a function point.
To summarise: LLMs are being trained on small datasets that don’t contain all the required information to give responses that mimic human estimates made in a pre-LLM world.
One of my most popular blog posts is: Software effort estimation is mostly fake research. The adverb “mostly” can be dropped once LLMs are involved.
Working with an LLM maths assistant to model software processes
This post is a overview of the techniques I use when working with LLMs as a mathematics assistant to derive equations for the aggregate behavior of a collection of software processes. Much of the following could well apply to non-software processes, but my experience is software based.
Any analysis starts with one or more questions/problems and the environment within which any answer is likely to be applicable. Possible questions include:
- Expected number of lines of code, LOC, in the next release of a program,
- number of distinct statement sequences that can be written using
if-statements and
assignmentstatements, - fraction of a program’s functions/methods that have not been modified after fixing all reported faults.
Prompting an LLM with a software related question is likely to result in it giving a software related answer summarising statements made on blogs and perhaps findings from various research papers. These summaries may, or may not, contain the desired answer.
Obtaining a mathematical answer requires that a mathematical question be asked. The software question has to be reframed in mathematical terms. This requires some creativity, lateral thinking, and prior experience is very helpful.
For instance, for question 1, expected lines of code could be reframed as a recurrence relation, such as  , where:
, where:  is the LOC in the
is the LOC in the  ‘th release, and
‘th release, and  ,
,  are constants. An LLM can solve this to relation to give an equation for based on , , and
are constants. An LLM can solve this to relation to give an equation for based on , , and  (the size of the first release).
(the size of the first release).
A more sophisticated set of recurrence relations could include the number of developers working on the project, along the probability distribution of the number of LOC they produce per day/week/month/release, and an equation for the expected time between releases.
Expressing question 2 in mathematical terms requires some lateral thinking. One possibility is to treat each line of code as a step on a 2-D lattice. An assignment statement occupying a line is one step down the page, while an if-statement occupies both a line and is (usually) indented to the right of the previous statement at the start, and indented to the left when it ends. Paths through a lattice are a well studied problem, with lots of existing mathematics for LLMs to have been trained on. This reframing of the question was good enough for me to be able to shepherd ChatGPT towards deriving an answer to the question. My pre-LLM research for answering a related question helped.

Creating a mathematical description of a question requires a lot of hard thinking (at least it does for me), and is an iterative process. If you are lucky, a good enough mapping to a starting formula is found, and the mathematics appears in textbooks, e.g., question 1. For other questions, lateral thinking may produce a mapping to a well researched area within some mathematical niche, e.g., question 2.
Creating a correct mathematical specification of the question is essential. Get this specification wrong, and any final equation will be the answer to a different question than the one intended. Mathematicians are used to describing problems in mathematical terms, while non-mathematicians (like me, and I suspect many readers) are likely to make mistakes and under/over specify the problem.
What can be done to check whether an LLM has interpreted the question in the way intended?
LLM chain-of-thought output provides the required feedback about how it interprets the question given. Some LLMs provide chain-of-thought output of their interpretation of the information contained in the prompt (e.g., Deepseek and Kimi), while others (e.g., until recently both ChatGPT and Grok; both have improved in the last few months) provide none, i.e., they are silent for a long time before giving an answer (which is can be useful for double-checking the output from other LLMs, but is otherwise of little use).
The following discussion is based on the process I used to obtain an answer to question 3.
The number of ways of placing some number of balls in some number of boxes is an established mathematical area of study that can be mapped to question 3. Functions are treated as empty boxes and fault reports as balls that are randomly placed in these boxes.
The initial mathematical question contains the minimum of constraints, and successive questions added constraints to better mimic the characteristics of source code and fault reports.
The following was my starting question:
$m$ identical boxes can each hold a maximum of $L$ balls, and there are $b$ identical balls, balls are uniformly at randomly placed in non-full boxes, where $L < m$ and $m*L > b$ and $b$ can have a similar size as $m$ What is the expected number of boxes that do not contain a ball |
The mathematics is enclosed in $ characters. LLMs support LaTeX input and output mathematics using LaTeX.
The first two lines specify the structure of the system. It’s important to specify that the balls are identical, otherwise the LLM has to decide whether they are, or are not, identical (non-identical has a very different solution).
The third line specifies the process behavior. The phrase “uniformly at randomly” is the mathematical way of saying “the behavior is random with all possibilities being equally likely”. When I first started using LLMs, this phrase is not something I used. However, “uniformly at randomly” often appeared in LLM output, so I switched to using it (LLMs having been trained on a lot more maths than me).
Lines four and five specify relationships between variables. Sometimes constraints such as these reduce the space of possibilities, and lead to a more concise answer. These constraints specify that a function will not contain more reported faults than it has lines of code (which is not always true), and that a program will not have more reported faults than lines of code.
The last line is the question I want answered (Kimi response).
In practice functions don’t all have the same size. Most functions are short, with fewer longer ones. The number of functions containing a given number of lines has (roughly) a power law distribution. Adding this information to the problem gives:
There are $m$ boxes, $B_n$, $1 <= n <= m$ where the
number of boxes that can hold $L$ balls, $1 <= L <= T$,
is proportional to $L^{-b}$,
and there are $F$ identical balls,
balls are uniformly at randomly placed in non-full boxes,
where the number of balls $F$ is much less than
the available places to hold them.
What is the expected number of boxes that do not contain a ball |
Boxes can now have different sizes, so they need to be labelled (i.e., $B_n$), with ball carrying capacity specified as a power law, i.e., $L^{-b}$.
The explicit constraints previously given are replaced by the general statement: “… the number of balls $F$ is much less than the available places to hold them.” This gives the LLM some flexibility about how to interpret the constraint.
LLMs make mistakes. I have seen them make a basic algebra mistake on one output line, followed by output that looks like penetrating insight (if a human had made it).
The chain-of-thought output reads like a derivation that a human would write (at least it does for Kimi, Deepseek, and recently GLM 5.1 from Z.ai). Checking the correctness of this derivation is necessary to gain confidence that the final answer is correct, or not.
This chain-of-thought often makes use a theorem or identity that is new to me. Kimi’s response to the updated prompt above made use of the polylogarithm function, which I had heard of, but knew nothing about.
When new to me maths is generated, Wikipedia is the first place I look. However, some Wikipedia maths articles appear to be written by mathematicians, who assume the reader already understands the topic, and simply summarise the relevant details; which is useless. Of course, one can always ask an LLM (a different one, so there is some cross-checking).
If the chain-of-thought looks correct, is the answer correct?
An LLM once give me an answer that was obviously wrong. It was an equation that could produce negative values, and in practice only positive values were possible. Each step of the chain-of-thought looked correct. It took me a while to spot that two disjoint assumptions in the LLM analysis combined to produce the incorrect answer.
I usually have an expectation of the behavior of any answer. Plotting the value of the equation given in an answer can show whether it follows the pattern of expected behavior.
Another way of gaining confidence in the answer is to give the prompt to multiple LLMs. Sometimes they all agree, and sometimes they disagree. The disagreement may be because the answer has been written in a slightly different form (e.g., summing a series from zero rather than one), or because the LLMs made slightly different assumptions. Comparing chain-of-thought will locate the points where assumptions diverge.
The third major iteration tried to address the observation that some functions are executed more often than others, and so are more likely to be involved in a fault report.
The specification was updated to include a preferential attachment component, with a box containing a ball having a higher probability of receiving a ball than one that did not contain a ball. The added text:
balls are randomly placed in non-full boxes with probability proportional to $L*(1+O)$ where $O$ is the number of ballscurrently in the box,
The equation in the answer was rather complicated (ChatGPT response). I have not checked this equation.
Most of the mathematically oriented questions/problems I have worked on have turned out to have uninteresting answers. Knowing this I can cross them off my list of things to think about. A few might lead to something interesting (e.g., fault prediction is starting to look like a waste of time), but need more work.
The answer checking process increases confidence that a particular answer is a solution to the question asked. It is possible that the specification of the question asked does not have a strong connection to reality.
My current first choice of LLMs for mathematical problems are Deepseek, Kimi, and recently GLM 5.1 (which has compute availability issues). This is primarily because they provide chain-of-thought output. In the last few months both ChatGPT and Grok have started providing more chain-of-thought output.
I usually start with one LLM to refine the question, and depending on progress later involve other LLMs to check and verify output.
Predicting reports of new faults by counting past reports
One of the many difficulties of estimating the probability of a previously unseen fault being reported is lack of information on the amount of time spent using the application; the more time spent, the more likely a previously unseen/seen fault will be experienced. Formal prerelease testing is one of the few situations where running time is likely to be recorded.
Information that is sometimes available is the date/time of fault reports. I say sometimes because a common response to an email asking researchers for their data, is that they did not record information about duplicate faults.
What information might possibly be extracted from a time ordered list of all reported faults, i.e., including reports of previously reported faults?
My starting point for answering this questions is a previous post that analysed time to next previously unreported fault.
The following analysis treats the total number of previously reported faults as a proxy for a unit of time. The LLMs used were Deepseek (which continues to give high quality responses, which are sometimes wrong), Kimi (which is working well again, after 6–9 months of poor performance and low quality chain of thought output), ChatGPT (which now produces good quality chain of thought), Grok (which has become expressive, if not necessarily more accurate), and for the first time GLM 5.1 from the company Z.ai.
After some experimentation, the easiest to interpret formula was obtained by modelling the ‘time’ between occurrences of previously unreported faults. The following is the prompt used (this models each fault as a process that can send a signal, with the Poisson and exponential distribution requirements derived from experimental evidence; here and here):
There are $N$ independent processes. Each process, $P_i$, transmits a signal, and the number of signals transmitted in a fixed time interval, $T$, has a Poisson distribution with mean $L_i$ for $1<= i <= N$. The values $L_i$ are randomly drawn from the same exponential distribution. What is the expected number of signals transmitted by all processes between the $k$ and $k+1$ first signals from the $N$ processes. |
The LLMs responses were either (based on a weekend studying the LLM chain-of-thought response): correct (GLM), very close (ChatGPT made an assumption that was different from the one made by GLM; after some back and forth prompts between the models (via me typing them), ChatGPT agreed that GLM’s assumption was the correct one), wrong but correct when given some hints (Grok without extra help goes down a Polya urn model rabbit hole), and always wrong (Deepseek, and Kimi, which normally do very well).
The expected number of previously reported faults between the  ‘th and
‘th and ") ‘th first occurrence of an unreported fault, is:
‘th first occurrence of an unreported fault, is:
![E[F_{prev}]={k*(2N-k-1)}/{(N-k)(N-k-1)}](https://shape-of-code.com/wp-content/plugins/wpmathpub/phpmathpublisher/img/math_977_e350e5adb969b64ebc06610cb57dd38d.png "E[F_{prev}]={k*(2N-k-1)}/{(N-k)(N-k-1)}") , where is the total number of possible distinct fault reports.
, where is the total number of possible distinct fault reports.
The variance is: (2(N-k)^2+(k-1)(N-k)+2(k-1))}/{(N-k)^2(N-k-1)^2(N-k-2)}")
While is unknown, but there is a distinctive shape to the plot of the change in the expected number of reports against (expressed as a percentage of ), as the plot below shows (see red line; code+data):
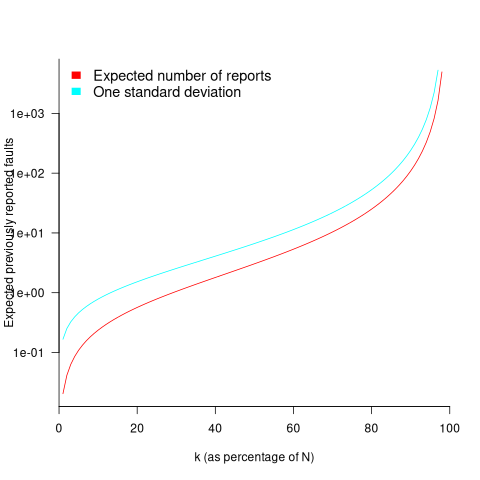
Perhaps, for a particular program, it is possible to estimate as a percentage of by comparing the relative change in the number of previously reported faults that occur between pairs of previously unreported faults.
Unfortunately the variance in the number previously reported faults completely swamps the expected value, ![E[F_{prev}]](https://shape-of-code.com/wp-content/plugins/wpmathpub/phpmathpublisher/img/math_981.5_a5ef61e64e07d16ba49517a817b2a39a.png "E[F_{prev}]") . The blue/green line in the plot above shows the upper bound of one standard deviation, with the lower bound being zero. In other words, any value between zero and the blue/green line is within one standard deviation of the expected value. There is no possibility of reliably narrowing down the bounds for , based on an estimated position of on the red curve above 🙁
. The blue/green line in the plot above shows the upper bound of one standard deviation, with the lower bound being zero. In other words, any value between zero and the blue/green line is within one standard deviation of the expected value. There is no possibility of reliably narrowing down the bounds for , based on an estimated position of on the red curve above 🙁
To quote GLM: “The variance always exceeds the mean because of two layers of randomness: the Poisson shot noise and the uncertainty in the rates themselves.”
That is the theory. Since data is available (i.e., duplicate fault reports in Apache, Eclipse and KDE), allowing the practice to be analysed (code+data).
The above analysis assumes that the software is a closed system (i.e., no code is added/modified/deleted), and that the fault report system does not attempt to reduce duplicate reports (e.g., by showing previously reported problems that appear to be similar, so the person reporting the problem may decide not to report it).
The closed system issue can be handled by analysing individual versions, but there is no solution to duplicate report reduction systems.
Across all KDE projects around 7% of reported problems were duplicates (code+data). For specific fault classes the percentage is often lower, e.g., for the konqueror project 2% of reports deal with program crashing.
Fuzzing is another source of duplicate reports. However, fuzzers are explicitly trying to exercise all parts of the code, i.e., the input is consistently different (or is intended to be).
Summary. This analysis provides another nail in the coffin of estimating the probability of encountering a previously unseen fault and of estimating the number of fault report experiences contained in a program.
70% of new software engineering papers on arXiv are LLM related
Subjectively, it feels like LLMs dominate the software engineering research agenda. Are most researchers essentially studying “Using LLMs to do …”? What does the data on papers published since 2022, when LLMs publicly appeared, have to say?
There is usually a year or two delay between doing the research work and the paper describing the work appearing in a peer reviewed conference/journal. Sometimes the researcher loses interest and no paper appears.
Preprint servers offer a fast track to publication. A researcher uploads a paper, and it appears the next day, with a peer reviewed version appearing sometime later (or not at all). Preprint publication data provides the closest approximation to real-time tracking of research topics. arXiv is the major open-access archive for research papers in computing, physics, mathematics and various engineering fields. The software engineering subcategory is cs.SE; every weekday I read the abstracts of the papers that have been uploaded, looking for a ‘gold dust’ paper.
The python package arxivscraper uses the arXiv api to retrieve metadata associated with papers published on the site. A surprisingly short program extracted the 15,899 papers published in the cs.SE subcategory since 1st January 2022.
A paper’s titles had to capture people’s attention using a handful of words. Putting the name of a new tool/concept in the title is likely to attract attention. The three words in the phrase Large Language Model consume a lot of title space, but during startup the abbreviated form (i.e., LLM) may not be generally recognised. The plot below shows the percentage of papers published each month whose title (case-insensitive) is matched either the regular expression “llm” or “large language model” (code and data):

Peak Large Language Model appears to be at the end of 2024. As time goes by new phrases/abbreviations stop being new and attention is grabbed by other phrases. Did peak LLM in titles occur at the end of 2025?
A paper’s abstract summarises its contents and has space for a lot more words. The plot below shows the percentage of papers published each month whose abstract (case-insensitive) is matched by either the regular expression “llm” or “large language model” (code and data):
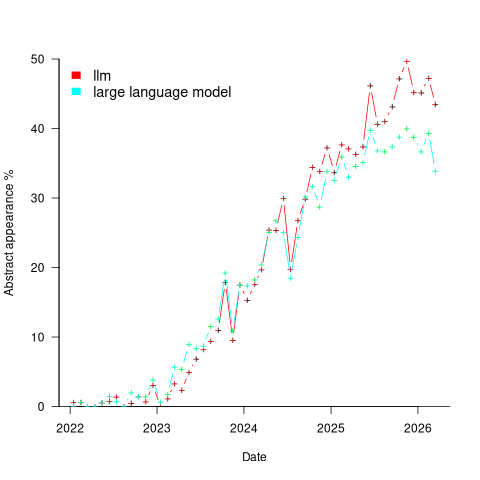
Peak, or plateauing, Large Language Model appears to be towards the end of 2025. Is the end of 2025 a peak of LLM in abstracts, or is it a plateauing with the decline yet to start? We should know by the end of this year.
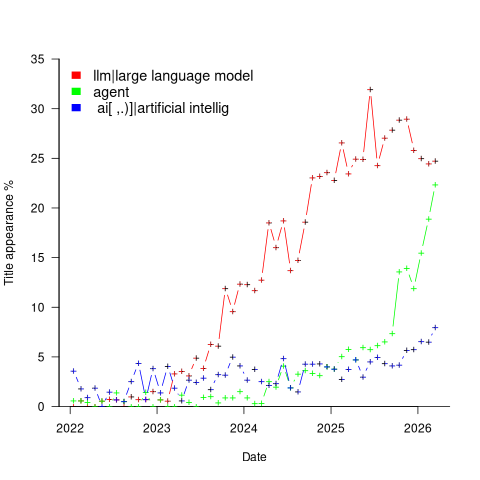
Other phrases associated with LLMs are AI, artificial intelligence and agents. The plot below shows the percentage of papers published each month whose title (case-insensitive) is matched by each of the regular expressions “llm|large language model“, or “ ai[ ,.)]|artificial intellig“, or “agent” (code and data):
Counting the papers containing one or more of these LLM-related phrases gives an estimate of the number of software engineering papers studying this topic. The plot below shows the percentage of papers published each month whose title or abstract (case-insensitive) is matched by one or more of the regular expressions “llm|large language model“, or “ ai[ ,.)]|artificial intellig“, or “agent” (code and data):
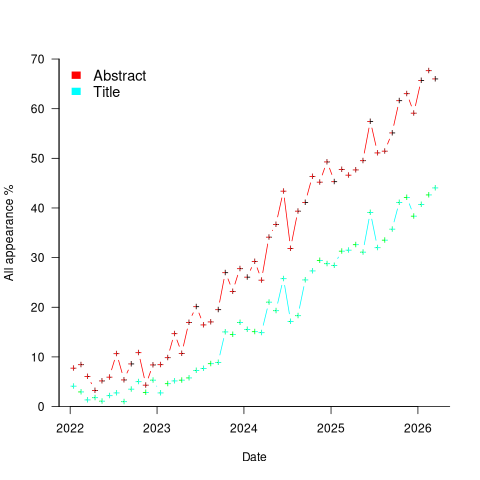
If the rate of growth is unchanged, around 18-month from now 100% of papers published in arXiv’s cs.SE subcategory will be LLM-related.
I expect the rate of growth to slow, and think it will stop before reaching 100% (I was expecting it to be higher than 70% in February). How much higher will it get? No idea, but herd mentality is a powerful force. Perhaps OpenAI going bankrupt will bring researchers to their senses.
Update
Martin Monperrus did an agentic replication of the analysis discussed in this post!
Investigating an LLM generated C compiler
Spending over $20,000 on API calls, a team at Anthropic plus an LLM (Claude Opus version 4.6) wrote a C compiler capable of compiling the Linux kernel and other programs to a variety of cpus. Has Anthropic commercialised monkeys typing on keyboards, or have they created an effective sheep herder?
First of all, does this compiler handle a non-trivial amount of the C language?
Having written a variety of industrial compiler front ends, optimizers, code generators and code analysers (which paid off the mortgage on my house), along with a book that analysed of the C Standard, sentence by sentence (download the pdf), I’m used to finding my way around compilers.
Claude’s C compiler source appears to be surprisingly well written/organised (based on a few hours reading of the code). My immediate thought was that this must be regurgitation of pieces from existing compilers. Searches for a selection of comments in the source failed to find any matches. Stylistically, the code is written by an entity that totally believes in using abstractions; functions call functions that call functions, that call …, eventually arriving at a leaf function that just assigns a value. Not at all like a human C compiler writer (well, apart from this one).
There are some oddities in an implementation of this (small) size. For instance, constant folding includes support for floating-point literals. Use of floating-point is uncommon, and opportunities to fold literals rare. Perhaps this support was included because, well, an LLM did the work. But it increases the amount of code that can be incorrect, for little benefit. When writing a compiler in an implementation language different from the one being compiled, differences between the two languages can have an impact. For instance, Claude C uses Rust’s 128-bit integer type during constant folding, despite this and most other C compilers only supporting at most 64-bit integer types.
A README appears in each of the 32 source directories, giving a detailed overview of the design and implementation of the activities performed by the code. The average length is 560 lines. These READMEs look like edited versions of the prompts used.
To get a sense of how the compiler handled rarely used language features and corner cases, I fed it examples from my book (code). The Complex floating point type is supported, along with Universal Character Names, fiddly scoping rules, and preprocessor oddities. This compiler is certainly non-trivial.
The compiler’s major blind spot is failing to detect many semantic constraints, e.g., performing arithmetic on variables having a struct type, or multiple declarations of functions and variables with the same name in the same scope (the parser README says “No type checking during parsing”; no type checking would be more accurate). The training data is source code that compiles to machine code, i.e., does not contain any semantic errors that a compiler is required to flag. It’s not surprising that Claude C fails to detect many semantic errors. There is a freely available collection of tests for the 80 constraint clauses in the C Standard that can be integrated into the Claude C compiler test suite, including the prompts used to generate the tests.
A compiler is an information conveyor belt. Source is first split into tokens (based on language specific rules), which are parsed to build a tree representation and a symbol table, which is then converted to SSA form so that a sequence of established algorithms can be used to lower the level of abstraction and detect common optimizations patterns, the low-level representation is mapped to machine code, and written to a file in the format for an executable program.
The prompts used to orchestrate the information processing conveyor belt have not been released. I’m guessing that the human team prompted the LLM with a detailed specification of the interfaces between each phase of the compiler.
The compiler is implemented in Rust, the currently fashionable language, and the obvious choice for its PR value. The 106K of source is spread across 351 files (average 531 LOC), and built in 17.5 seconds on my system.
LLMs make mistakes, with coding benchmark success rates being at best around 90%. Based on these numbers, the likelihood of 351 files being correctly generated, at the same time, is  (with 99% probability of correctness we get
(with 99% probability of correctness we get  ). Splitting the compiler into, say, 32 phases each in a directory containing 11 files, and generating and testing each phase independently significantly increases the probability of success (or alternatively, significantly reduces the number of repetitions of the generate code and test process). The success probability of each phase is:
). Splitting the compiler into, say, 32 phases each in a directory containing 11 files, and generating and testing each phase independently significantly increases the probability of success (or alternatively, significantly reduces the number of repetitions of the generate code and test process). The success probability of each phase is:  , and if the same phase is generated 13 times, i.e.,
, and if the same phase is generated 13 times, i.e., }/{log(1-0.90^{11})}") , there is a 99% probability that at least one of them is correct.
, there is a 99% probability that at least one of them is correct.
Some code need not do anything other than pass on the flow of information unchanged. For instance, code to perform the optimization common subexpression elimination does exist, but the optimization is not performed (based on looking at the machine code generated for a few tests; see codegen.c). Detecting non-functional code could require more prompting skill than generating the code. The prompt to implementation this optimization (e.g., write Rust code to perform value numbering) is very different from the prompt to write code containing common subexpressions, compile to machine code and check that the optimization is performed.
There is little commenting in the source for the lexer, parser, and machine code generators, i.e., the immediate front end and final back end. There is a fair amount of detailed commenting in source of the intervening phases.
The phases with little commenting are those which require lots of very specific, detailed information that is not often covered in books and papers. I suspect that the prompts for this code contains lots of detailed templates for tokenizing the source, building a tree, and at the back end how to map SSA nodes to specific instruction sequences.
The intermediate phases have more publicly available information that can be referenced in prompts, such as book chapters and particular papers. These prompts would need to be detailed instructions on how to annotate/transform the tree/SSA conveyed from earlier phases.
Formal methods and LLM generated mathematical proofs
Formal methods have been popping up in the news again, or at least on the technical news sites I follow.
Both mathematics and software share the same pattern of usage of formal methods. The input text is mapped to some output text. Various characteristics of the output text are checked using proof assistant(s). Assuming the mapping from input to output is complete and accurate, and the output has the desired characteristics, various claims can then be made about the input text, e.g., internally consistent. For software systems, some of the claims of correctness made about so-called formally verified systems would make soap powder manufacturers blush.
Mathematicians have been using LLMs to help find proofs of unsolved maths problems. Human written proofs are traditionally checked by other humans reading them to verify that the claimed proof is correct. LLMs generated proofs are sometimes written in what is called a formal language, this proof-as-program can then be independently checked by a proof assistant (the Lean proof assistant is a popular choice; Rocq is popular for proofs about software).
Software developers are well aware that LLM generated code contains bugs, and mathematicians have discovered that LLM generated proof-programs contain bugs. A mathematical proof bug involves Lean reporting that the LLM generated proof is true, when the proof applies to a question that is different from the actual question asked. Developers have probably experienced the case where an LLM generates a working program that does not do what was requested.
An iterative verification-and-refinement pipeline was used for LLMs well publicised solving of International Mathematical Olympiad problems.
A cherished belief of fans of formal methods is that mathematical proofs are correct. Experience with LLMs shows that a sequence of steps in a generated proof may be correct, but the steps may go down a path unrelated to the question posed in the input text. Also, proof assistants are programs, and programs invariably contain coding mistakes, which sometimes makes it possible to prove that false is true (one proof assistant currently has 83 bug reports of false being proved true).
It is well known, at least to mathematicians, that many published proofs contain mistakes, but that these can be fixed (not always easily), and the theorem is true. Unfortunately, journals are not always interested in publishing corrections. A sample of 51 reviews of published proofs finds that around a third contain serious errors, not easily corrected.
Human written proofs contain intentional gaps. For instance, it is assumed that readers can connect two steps without more details being given, or the author does not want to deter reviewers with an overly long proof. If LLM generated proofs are checked by proof assistants, then the gap between steps needs to be of a size supported by the assistant, and deterring reviewers is not an issue. Does this mean that LLM generated proof is likely to be human unfriendly?
Software is often expressed in an imperative language, which means it can be executed and the output checked. Theorems in mathematics are often expressed in a declarative form, which makes it difficult to execute a theorem to check its output.
For software systems, my view is that formal methods are essentially a form of -version programming, with  . Two programs are written, with one nominated to be called the specification; one or more tools are used to analyse both programs, checking that their behavior is consistent, and sometimes other properties. Mistakes may exist in the specification program or the non-specification program.
. Two programs are written, with one nominated to be called the specification; one or more tools are used to analyse both programs, checking that their behavior is consistent, and sometimes other properties. Mistakes may exist in the specification program or the non-specification program.
Using LLMs to help solve mathematical problems is a rapidly evolving field. We will have to wait and see whether end-to-end LLM generated proofs turn out to be trustworthy, or remain as a very useful aid.
My 2025 in software engineering
Unrelenting talk of LLMs now infests all the software ecosystems I frequent.
- Almost all the papers published (week) daily on the Software Engineering arXiv have an LLM themed title. Way back when I read these LLM papers, they seemed to be more concerned with doing interesting things with LLMs than doing software engineering research.
- Predictions of the arrival of AGI are shifting further into the future. Which is not difficult given that a few years ago, people were predicting it would arrive within 6-months. Small percentage improvements in benchmark scores are trumpeted by all and sundry.
- Towards the end of the year, articles explaining AI’s bubble economics, OpenAI’s high rate of loosing money, and the convoluted accounting used to fund some data centers, started appearing.
Coding assistants might be great for developer productivity, but for Cursor/Claude/etc to be profitable, a significant cost increase is needed.
Will coding assistant companies run out of money to lose before their customers become so dependent on them, that they have no choice but to pay much higher prices?
With predictions of AGI receding into the future, a new grandiose idea is needed to fill the void. Near the end of the year, we got to hear people who must know it’s nonsense claiming that data centers in space would be happening real soon now.
I attend one or two, occasionally three, evening meetups per week in London. Women used to be uncommon at technical meetups. This year, groups of 2–4 women have become common in meetings of 20+ people (perhaps 30% of attendees); men usually arrive individually. Almost all women I talked to were (ex) students looking for a job; this was also true of the younger (early 20s) men I spoke to. I don’t know if attending meetups been added to the list of things to do to try and find a job.
Tom Plum passed away at the start of the year. Tom was a softly spoken gentleman whose company, PlumHall, sold a C, and then C++, compiler validation suite. Tom lived on Hawaii, and the C/C++ Standard committees were always happy to accept his invitation to host an ISO meeting. The assets of PlumHall have been acquired by Solid Sands.
Perennial was the other major provider of C/C++ validation suites. It’s owner, Barry Headquist, is now enjoying his retirement in Florida.
The evidence-based software engineering Discord channel continues to tick over (invitation), with sporadic interesting exchanges.
What did I learn/discover about software engineering this year?
Software reliability research is a bigger mess than I had previously thought.
I now regularly use LLMs to find mathematical solutions to my experimental models of software engineering processes. Most go nowhere, but a few look like they have potential (here and here and here).
Analysis/data in the following blog posts, from the last 12-months, belongs in my book Evidence-Based Software Engineering, in some form or other (2025 was a bumper year):
Naming convergence in a network of pairwise interactions
Lifetime of coding mistakes in the Linux kernel
Decline in downloads of once popular packages
Distribution of method chains in Java and Python
Modeling the distribution of method sizes
Distribution of integer literals in text/speech and source code
Percentage of methods containing no reported faults
Half-life of Open source research software projects
Positive and negative descriptions of numeric data
Impact of developer uncertainty on estimating probabilities
After 55.5 years the Fortran Specialist Group has a new home
When task time measurements are not reported by developers
Evolution has selected humans to prefer adding new features
One code path dominates method execution
Software_Engineering_Practices = Morals+Theology
Long term growth of programming language use
Deciding whether a conclusion is possible or necessary
CPU power consumption and bit-similarity of input
Procedure nesting a once common idiom
Functions reduce the need to remember lots of variables
Remotivating data analysed for another purpose
Half-life of Microsoft products is 7 years
How has the price of a computer changed over time?
Deep dive looking for good enough reliability models
Apollo guidance computer software development process
Example of an initial analysis of some new NASA data
Extracting information from duplicate fault reports
I visited Foyles bookshop on Charing cross road during the week (if you’re ever in London, browsing books in Foyles is a great way to spend an afternoon).
Computer books once occupied almost half a floor, but is now down to five book cases (opposite is statistics occupying one book case, and the rest of mathematics in another bookcase):

Around the corner, Gender Studies and LGBTQ+ occupies seven bookcases (the same as last year, as I recall):

Fifth anniversary of Evidence-based Software Engineering book
Yesterday was the 5th anniversary of the publication of my book Evidence-based Software Engineering.
The general research trajectory I was expecting in the 2020s (e.g., more sophisticated statistical analysis and more evidence based studies) has been derailed by the arrival of LLMs three years ago. Almost all software engineering researchers have jumped on the LLM bandwagon, studying whatever LLM use case is likely to result in a published paper. While I have noticed more papers using statistical techniques discovered after the digital computer was invented (perhaps influenced by the second half of the book), there seems to be a lot fewer evidence based papers being published. I don’t expect researches studying software engineering to jump off the LLM bandwagon in the next few years.
The net result of this lack of new research findings is that the book contents are not yet in need of an update.
On a positive note, LLMs’ mathematical problem-solving capabilities have significantly reduced the time needed to analyse models of software engineering processes.
Had today’s LLMs been available while I was writing the book, the text would probably have included many more theoretical models and their analysis. ‘Probably’, because sometimes the analysis finds that a model does not provide meaningfully mimic reality, so it’s possible that only a few more models would have been included.
My plan for the next year is to use LLM’s mathematical problem-solving capabilities to help me analyse models of software engineering processes. A discussion of any interested results found will appear on this blog. I’m hoping that there will be active conversations on the evidence based software engineering Discord channel.
It makes sense to hone my model analysis skills by starting with the subject I am most familiar with, i.e., source code. It also helps that tools are available for obtaining more source measurement data.
I will continue to write about any interesting papers that appear on the arXiv lists cs.se and cs.PL, as well as the major conferences. There won’t be time to track the minor conferences.
Questions raised during model analysis sometimes suggest ideas that, when searched for, lead to new data being discovered. Discovering new data using a previously untried search phrase is always surprising.
Recent Comments