Archive
Modeling the distribution of method sizes
The number of lines of code in a method/function follows the same pattern in the three languages for which I have measurements: C, Java, Pharo (derived from Smalltalk-80).
The number of methods containing a given number of lines is a power law, with an exponent of 2.8 for C, 2.7 for Java and 2.6 for Pharo.
This behavior does not appear to be consistent with a simplistic model of method growth, in lines of code, based on the following three kinds of steps over a 2-D lattice: moving right with probability  , moving up and to the right with probability
, moving up and to the right with probability  , and moving down and to the right with probability
, and moving down and to the right with probability  . The start of an
. The start of an if or for statement are examples of coding constructs that produce a step followed by a step at the end of the statement; steps are any non-compound statement. The image below shows the distinct paths for a method containing four statements:

For this model, if  the probability of returning to the origin after taking
the probability of returning to the origin after taking  is a complicated expression with an exponentially decaying tail, and the case
is a complicated expression with an exponentially decaying tail, and the case  is a well studied problem in 1-D random walks (the probability of returning to the origin after taking steps is
is a well studied problem in 1-D random walks (the probability of returning to the origin after taking steps is  approx n^{-1.5}") ).
).
Possible changes to this model to more closely align its behavior with source statement production include:
- include terms for the correlation between statements, e.g., assigning to a local variable implies a later statement that reads from that variable,
- include context terms in the up/down probabilities, e.g., nesting level.
Measuring statement correlation requires handling lots of special cases, while measurements of up/down steps is easily obtained.
How can / probabilities be written such that step length has a power law with an exponent greater than two?
ChatGPT 5 told me that the Langevin equation and Fokker–Planck equation could be used to derive probabilities that produced a power law exponent greater than two. I had no idea had they might be used, so I asked ChatGPT, Grok, Deepseek and Kimi to suggest possible equations for the / probabilities.
The physics model corresponding to this code related problem involves the trajectories of particles at the bottom of a well, with the steepness of the wall varying with height. This model is widely studied in physics, where it is known as a potential well.
Reaching a possible solution involved refining the questions I asked, following suggestions that turned out to be hallucinations, and trying to work out what a realistic solution might look like.
One ChatGPT suggestion that initially looked promising used a Metropolis–Hastings approach, and a logarithmic potential well. However, it eventually dawned on me that ^a") , where
, where  is nesting level, and
is nesting level, and  some constant, is unlikely to be realistic (I expect the probability of stepping up to decrease with nesting level).
some constant, is unlikely to be realistic (I expect the probability of stepping up to decrease with nesting level).
Kimi proposed a model based on what it called algebraic divergence:
=r/{z(y)},U(y)={u_0y^{1-2/{alpha}}}/{z(y)}, D(y)={d_0y^{1-2/{alpha}}}/{z(y)}")
where: ") normalises the probabilities to equal one,
normalises the probabilities to equal one, =r+u_0y^{1-2/alpha}+d_0y^{1-2/alpha}") ,
,  is the up probability at nesting 0,
is the up probability at nesting 0,  is the down probability at nesting 0, and
is the down probability at nesting 0, and  is the desired power law exponent (e.g., 2.8).
is the desired power law exponent (e.g., 2.8).
For C,  , giving
, giving =r/{z(y)},U(y)={u_0y^{0.29}}/{z(y)}, D(y)={d_0y^{0.29}}/{z(y)}")
The average length of a method, in LOC, is given by:
![E[LOC]={alpha r}/{2(d_0-u_0)}+O(e^{lambda}-1)](https://shape-of-code.com/wp-content/plugins/wpmathpub/phpmathpublisher/img/math_969.5_ffcacf0bb8190096d4d17fb475c0a290.png "E[LOC]={alpha r}/{2(d_0-u_0)}+O(e^{lambda}-1)") , where:
, where: }/{d_0+u_0}")
For C, the mean function length is 26.4 lines, and the values of  , , and need to be chosen subject to the constraint
, , and need to be chosen subject to the constraint  .
.
Combining the normalization factor with the requirement  , shows that as increases,
, shows that as increases, ") slowly decreases and
slowly decreases and ") slowly increases.
slowly increases.
One way to judge how closely a model matches reality is to use it to make predictions about behavior patterns that were not used to create the model. The behavior patterns used to build this model were: function/method length is a power law with exponent greater than 2. The mean length, ![E[LOC]](https://shape-of-code.com/wp-content/plugins/wpmathpub/phpmathpublisher/img/math_981.5_0ac27fa76bd7c6e393f3497c9f30db7e.png "E[LOC]") , is a tuneable parameter.
, is a tuneable parameter.
Ideally a model works across many languages, but to start, given the ease of measuring C source (using Coccinelle), this one language will be the focus.
I need to think of measurable source code patterns that are not an immediate consequence of the power law pattern used to create the model. Suggestions welcome.
It’s possible that the impact of factors not included in this model (e.g., statement correlation) is large enough to hide any nesting related patterns that are there. While different kinds of compound statements (e.g., if vs. for) may have different step probabilities, in C, and I suspect other languages, if-statement use dominates (Table 1713.1: if 16%, for 4.6% while 2.1%, non-compound statements 66%).
C compiler conformance testing: with ChatGPT assistance
How can developers check that a compiler correctly implements all the behavior requirements contained in the corresponding language specification?
An obvious approach is to write lots of test cases for each distinct behavior; such a collection of tests is known as a validation suite, when used by a standard’s organization to test compilers/OS interfaces/etc. The extent to which a compiler’s behavior, when fed these tests, matches that listed in the language specification is a measure of its conformance.
In a world of many compilers with significant differences in behavior (i.e., pre-Open source), it makes economic sense for governments to sponsor the creation of validation suites, and/or companies to offer such suites commercially (mainly for C and C++). The spread of Open source compilers decimated compiler diversity, and compiler validation is fading into history.
New features continue to be added to Cobol, Fortran, C, and C++ by their respective ISO Standard’s committee. If governments are no longer funding updates to validation suites and the cost of commercial suites is too high for non-vendors (my experience is that compiler vendors find them to be cost-effective), how can developers check that a compiler conforms to the behavior specified by the Standard?
How much effort is required to create some minimal set of compiler conformance tests?
C is the language whose requirements I am most familiar with. The C Standard specifies that a conforming compiler issue a diagnostic for a violation of a requirement appearing in a Constraint clause, e.g., “For addition, either both operands shall have arithmetic type, or …”
There are 80 such clauses, containing around 530 non-blank lines, in N3301, the June 2024 draft. Let’s say 300+ distinct requirements, requiring a minimum of one test each. Somebody very familiar with the C Standard might take, say, 10 minutes per test, which is 3,000 minutes, or 50 hours, or 6.7 days; somebody slightly less familiar might take, say, at least an hour, which is 300+ hours, or 40+ days.
Lots of developers are using LLMs to generate source code from a description of what is needed. Given Constraint requirements in the C Standard, can an LLM generate tests that do a good enough job checking a compiler’s conformance to the C Standard?
Simply feeding the 157 pages from the Language chapter of the C Standard into an LLM, and asking it to generate tests for each Constraint requirement does not seem practical with the current state of the art; I’m happy to be proved wrong. A more focused approach might produce the desired tests.
Negative tests are likely to be the most challenging for an LLM to generate, because most publicly available source deals with positive cases, i.e., it is syntactically/semantically correct. The wording of Constraints sometimes specifies what usage is not permitted (e.g., clause 6.4.5.3 “A floating suffix df, dd, dl, DF, DD, or DL shall not be used in a hexadecimal floating literal.”), other times specifies what usage is permitted (e.g., clause 6.5.3.4 “The first operand of the . operator shall have an atomic, qualified, or unqualified structure or union type, and the second operand shall name a member of that type.”), or simply specifies a requirement (e.g., clause 6.7.3.2 “A member declaration that does not declare an anonymous structure or anonymous union shall contain a member declarator list.”).
I took the text from the 80 Constraint clauses, removed footnote numbers and rejoined words split at line-breaks. The plan was to prefix the text of each Constraint with instructions on the code requires. After some experimentation, the instructions I settled on were:
Write a sequence of very short programs which tests that a C compiler correctly flags each violation of the requirements contained in the following excerpt from the latest draft of the C Standard: |
Initially, excerpt was incorrectly spelled as except, but this did not seem to have any effect. Perhaps this misspelling is sufficiently common in the training data, that LLM weights support the intended association.
Experiments using Grok and ChatGPT 4o showed that both generated technically correct tests, but Grok generated code that was intended to be run (and was verbose), while the ChatGPT 4o output was brief and to the point; it did such a good job that I did not try any other LLMs. For this extended test, use of the web interface proved to be an effective approach. Interfacing via the API is probably more practical for larger numbers of requirements.
After some experimentation, I submitted the text from 31 Constraint clauses (I picked the non-trivial ones). The complete text of the questions and ChatGPT 4o responses (text files).
ChatGPT sometimes did not generate tests for all the requirements, when these were presented as they appeared in the Constraint, but did generate tests when the containing sentence was presented in isolation from other requirement sentences. For instance, the following sentence from clause 6.5.5 Cast Operators:
Conversions that involve pointers, other than where permitted by the constraints of 6.5.17.2, shall be specified by means of an explicit cast. |
was ignored when included as part of the complete Constraint, but when presented in isolation, reasonable tests were generated.
The responses never contained more than 10 test cases. I am guessing that this is the result of limits on response cpu time/length. Dividing the text of longer Constraints should solve this issue.
Some assumptions made by ChatGPT 4o about the implementation can be deduced from its responses, e.g., it appears to treat the type short as containing fewer than 32-bits (it assumes that a bit-field defined as a short containing 32-bits will be treated as a Constraint violation). This is not surprising, given the volume of public C source targeting the Intel x86.
I was impressed by the quality of the 242 test cases generated by ChatGPT 4o, which often included multiple tests for the same requirement (text files).
While it sometimes failed to produce a test for a requirement, I did not spot any incorrect tests (as in, not correctly testing for a violation of a listed requirement); the subset of tests feed through behaved as claimed), and I eventually found a prompt that appears to be creating a downloadable zip file of all the tests (most prompts resulted in a zip file containing some collection of 10 tests); the creation process is currently waiting for available cpu time. I now know that downloading a zip file containing one file per test, after each user prompt, is the more reliable option.
Number of statement sequences possible using N if-statements
I recently read a post by Terence Tao describing how he experimented with using ChatGPT to solve a challenging mathematical problem. A few of my posts contain mathematical problems I could not solve; I assumed that solving them was beyond my maths pay grade. Perhaps ChatGPT could help me solve some of them.
To my surprise, a solution was found to the first problem I tried.
I simplified the original problem (involving Motzkin numbers, details below) down to something that was easier for me to explain to ChatGPT. Based on ChatGPT’s response, it appeared lost, so I asked what it knew about Motzkin numbers. I then reframed the question around the concepts in its response, and got a response that, while reasonable, was not a solution. My question was not precise enough, and a couple of question/answer iterations later, ChatGPT broke the problem down into a series of steps that I saw could solve the problem. While the equation it used in its answer was just wrong, I knew what the correct equation was. So while ChatGPT frequently went off in the wrong direction and got its maths wrong, it helped me refine my statement of the problem and ChatGPT eventually gave steps to a solution which were blindingly obvious to me when I read them.
The question I wanted to answer was: How many distinct statement sequences can be created using 
if-statements and  simple-statements (for a total of
simple-statements (for a total of  statements)?
statements)?
A simple-statement might be an assignment or function call, but not any kind of compound statement, such as a loop. Three sequences are possible using one if-statement and two simple-statements. The if-statement occupies two lines, i.e., the condition and termination curly-bracket, }, as follows:
s1; if (c1) { if (c1) { if (c1) { s1; s1; s2; s2; } } } s2; |
In a previous post I showed how a variant of this question, involving any number of if-statements, can be mapped to a combinatorial interpretation of Motzkin numbers and treating matching up/down diagonals along a path as an if-statement.

ChatGPT performed poorly when I phrased the problem in combinatorial terms (or perhaps my phrasing was poor), so I switched to using a lattice path approach. I asked: “How many lattice paths of length S containing exactly N occurrences of the step (1, 1) and N occurrences of the step (1, -1) are possible?”, and after reading the response I replied “Your analysis does not take into account the fact that the path cannot go below the x-axis. Rework your analysis to take this restriction into account.”
The following is my edited version of ChatGPT’s ‘solution’ response (sorry, no link to chat):
“Problem Restated:
We need to count the number of valid Dyck paths of length , where the path consists of:
Exactly upward steps (1,1).
Exactly downward steps (1,−1).
The remaining steps (which must be horizontal steps (1,0)).
These paths must never dip below the x-axis, and they must return to the x-axis at the end.
…
Step 2: Catalan Numbers for Balanced Paths
If we ignore the horizontal steps for the moment, the number of ways to place upward steps and downward steps such that the path does not go below the x-axis is given by the Catalan number  :
:
={(2*N)!}/{(N+1)!N!}")
This Catalan number counts the number of valid ways to arrange the upward steps and downward steps such that the path remains above or on the x-axis.
Step 3: Placing Horizontal Steps
Once the valid upward and downward steps have been arranged in a Catalan structure, we can freely place the horizontal steps (1,0) in the remaining positions of the path. Since there are  steps (upward and downward) and horizontal steps, there are
steps (upward and downward) and horizontal steps, there are  gaps (before, after, or between the upward/downward steps) where the horizontal steps can be placed.
gaps (before, after, or between the upward/downward steps) where the horizontal steps can be placed.
The number of ways to place horizontal steps in these positions is given by a binomial coefficient:”
For some reason, ChatGPT gives the wrong binomial coefficient. Calculating the number of ways of distributing  items into
items into  bins is a well known problem; when a bin can contain zero items, the solution is:
bins is a well known problem; when a bin can contain zero items, the solution is: ={(x+y-1)!}/{(y-1)!x!}") .
.
Combining the equations from the two steps gives the number of distinct statement sequences that can be created using if-statements and simple-statements as:
={(2*N)!}/{(N+1)!N!}{S!}/{(2*N)!(S-2*N)!}={S!}/{{(N+1)!N!}(S-2*N)!}")
The above answer is technically correct, however, it fails to take into account that in practice an if-statement body will always contain either another if-statement or a simple statement, i.e., the innermost if-statement of any nested sequence cannot be empty (the equation used for distributing items into bins assumes a bin can be empty).
Rather than distributing statements into gaps, we first need to insert one simple statement into each of the innermost if-statements. The number of ways of distributing the remaining statements are then counted as previously. How many innermost if-statements can be created using if-statements? I found the answer to this question in a StackExchange question, using traditional search.
The question can be phrased in terms of peaks in Dyck paths, and the answer is contained in the Narayana numbers (which I had never heard of before). The following example, from Wikipedia, shows the number of paths containing a given number of peaks, that can be produced by four if-statements:
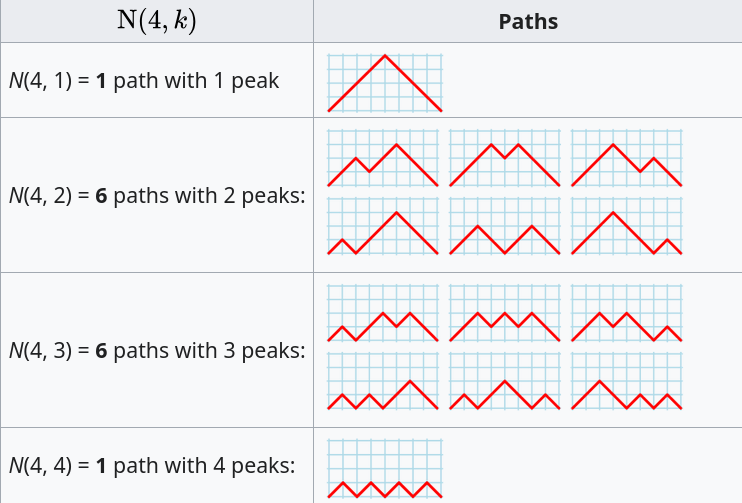
The sum of all these paths is the Catalan number for the given number of if-statements, e.g., using  to denote the Narayana number:
to denote the Narayana number: }=1 + 6 + 6 + 1 = 14=C_4") .
.
Adding at least one simple statement to each innermost if-statement changes the equation for the number of statement sequences from ") , to:
, to:
(matrix{2}{1}{{S-k*P(N, k)} 2*N})}")
The following table shows the number of distinct statement sequences for five-to-twenty statements containing one-to-five if-statements:
N if-statements
1 2 3 4 5
5 6 1
6 10 6
7 15 20 1
8 21 50 7
9 28 105 29 1
10 36 196 91 9
11 45 336 238 45 1
12 55 540 549 166 11
S 13 66 825 1,155 504 66
14 78 1,210 2,262 1,332 286
15 91 1,716 4,179 3,168 1,002
16 105 2,366 7,351 6,930 3,014
17 120 3,185 12,397 14,157 8,074
18 136 4,200 20,153 27,313 19,734
19 153 5,440 31,720 50,193 44,759
20 171 6,936 48,517 88,458 95,381 |
The following is an R implementation of the calculation:
Narayana=function(n, k) choose(n, k)*choose(n, k-1)/n
Catalan=function(n) choose(2*n, n)/(n+1)
if_stmt_possible=function(S, N)
{
return(Catalan(N)*choose(S, 2*N)) # allow empty innermost if-statement
}
if_stmt_cnt=function(S, N)
{
if (S <= 2*N)
return(0)
total=0
for (k in 1:N)
{
P=Narayana(N, k)
if (S-P*k >= 2*N)
total=total+P*choose(S-P*k, 2*N)
}
return(total)
}
isc=matrix(nrow=25, ncol=5)
for (S in 5:20)
for (N in 1:5)
isc[S, N]=if_stmt_cnt(S, N)
print(isc) |
Extracting named entities from a change log using an LLM
The Change log of a long-lived software system contains many details about the system’s evolution. Two years ago I tried to track the evolution of Beeminder by extracting the named entities in its change log (named entities are the names of things, e.g., person, location, tool, organization). This project was pre-LLM, and encountered the usual problem of poor or non-existent appropriately trained models.
Large language models are now available, and these appear to excel at figuring out the syntactic structure of text. How well do LLMs perform, when asked to extract named entities from each entry in a software project’s change log?
For this analysis I’m using the publicly available Beeminder change log. Organizations may be worried about leaking information when sending confidential data to a commercially operated LLM, so I decided to investigate the performance of a couple of LLMs running on my desktop machine (code+data).
The LLMs I used were OpenAI’s ChatGPT plus (the $20 month service), and locally: Google’s Gemma (the ollama 7b model), a llava 7b model (llava-v1.5-7b-q4.llamafile), and a Mistral 7b model (mistral-7b-instruct-v0.2.Q8_0.llamafile). I used 7 billion parameter models locally because this is the size that is generally available for Open sourced models. There are a few models supporting the next step-up, at 13 billion parameters, and a few at 30 billion.
All the local models start a server at localhost:8080, and provide various endpoints. Mozilla’s llamafile based system is compatible with OpenAI’s python package openai. The documentation for the Gemma based system I installed uses the ollama package. In both cases, the coding required is trivial; just add a few statements to create a question based on command line input:
import openai import sys prefix='List the named entities in the following sentences: ' input_str=sys.argv[1] # change log entry from command line client = openai.OpenAI( base_url="http://localhost:8080/v1", # "http://<Your api-server IP>:port" api_key = "sk-no-key-required" ) stream = client.chat.completions.create( model="gpt-4", stream=True, temperature=0, seed=19, messages=[ {"role": "system", "content": "You are ChatGPT, an AI assistant. Your top priority is achieving user fulfilment via helping them with their requests."}, {"role": "user", 'content': prefix+ input_str } ] ) # Print response for chunk in stream: print(chunk.choices[0].delta.content or "", end="") print() |
How well did the models perform?
For rapid iteration, I used the web interface to ChatGPT. The responses started to appear within a few seconds and were displayed at a readable rate.
ChatGPT 3.5
When given a single change log entry, ChatGPT also provides a brief description of the named entity. In the following example, ‘twitter acct‘ and ‘blog posts‘ are not flagged as named entities:
User
print the named entities in the following quoted text "Created
this twitter acct to log user-visible improvements (UVIs) to
Beeminder. (Yes, this is a UVI. Everything counts no matter how
small!) Very first UVI! Back then this counted but nowadays we
don't count things that are too ancillary like making Twitter
accounts or writing blog posts. We did count a few UVIs for
creating this fancy changelog but decided that's too ancillary
now too."
ChatGPT
To identify named entities in the quoted text, we need to look for
proper nouns, which typically include names of specific people,
organizations, locations, and sometimes unique entities. In the
provided text, here are the named entities:
Beeminder - Refers to a specific service or product.
Twitter - Refers to a specific social media platform.
UVI (User-Visible Improvement) - Refers to a specific type of improvement.
changelog - Refers to a specific type of document or record. |
When asked to list the named entities in each of multiple lines, ChatGTP 3.5 performance drops. In the following response, the first line is identical to the example above; the response contains three, not four names entities. The second line contains named entities, but ChatGTP claims there are none. The response to the third line is accurate:
ChatGPT
Here are the named entities in each of the three lines:
"Created this twitter acct" line:
Twitter - Refers to a specific social media platform.
UVIs (User-Visible Improvements) - Refers to a specific
type of improvement.
Beeminder - Refers to a specific service or product.
"Added ridiculous dog-dressed-as-a-bee picture" line:
None
"Now suppressing reminder emails" line:
reminder emails - Refers to a specific type of communication.
bug fixes - Refers to a specific type of improvement aimed
at resolving software issues.
UVIs (User-Visible Improvements) - Refers to a specific
type of improvement. |
ChatGPT 4.0
ChatGPT 4.0 can handle multiple change log entries. The following is the response to the first three entries (the same three entries given the ChatGPT 3.5):
ChatGPT
To thoroughly identify the named entities within each line,
I'll systematically parse each one, focusing on extracting
specific types of entities such as organizations, people,
locations, dates, websites, and any other identifiable proper
nouns.
Beeminder, Twitter, UVI: Organizations or products.
dog-dressed-as-a-bee: Concept, not a proper noun but unique
enough to note.
reminder emails: Concept, referring to a feature. |
While it is possible to input 100 change log entries into the ChatGPT input box, the response contained no more than about 25 of them (there is a maximum limit on the number of input and output tokens).
Running locally
The machine I used locally contains 64G memory and an Intel Core i5-7600K running at 3.80GHz, with four cores. The OS is Linux Mint 21.1, running the kernel 5.15.0-76-generic. I don’t have any GPUs installed.
A GPU would probably significantly improve performance. On Amazon, the price of the NVIDIA Tesla A100 is now just under £7,000, an order of magnitude more than I am interested in paying (let alone the electricity costs). I have not seen any benchmarks comparing GPU performance on running LLMs locally, but then this is still a relatively new activity.
Overall, Gemma produced the best responses and was the fastest model. The llava model performed so poorly that I gave up trying to get it to produce reasonable responses (code+data). Mistral ran at about a third the speed of Gemma, and produced many incorrect named entities.
As a very rough approximation, Gemma might be useful. I look forward to trying out a larger Gemma model.
Gemma
Gemma took around 15 elapsed hours (keeping all four cores busy) to list named entities for 3,749 out of 3,839 change log entries (there were 121 “None” named entities given). Around 3.5 named entities per change log entry were generated. I suspect that many of the nonresponses were due to malformed options caused by input characters I failed to handle, e.g., escaping characters having special meaning to the command shell.
For around about 10% of cases, each named entity output was bracketed by “**”.
The table below shows the number of named entities containing a given number of ‘words’. The instances of more than around three ‘words’ are often clauses within the text, or even complete sentences:
# words 1 2 3 4 5 6 7 8 9 10 11 12 14 Occur 9149 4102 1077 210 69 22 10 9 3 1 3 5 4 |
A total of 14,676 named entities were produced, of which 6,494 were unique (ignoring case and stripping **).
Mistral
Mistral took 20 hours to process just over half of the change log entries (2,027 out of 3,839). It processed input at around 8 tokens per second and output at around 2.5 tokens per second.
When Mistral could not identify a named entity, it reported this using a variety of responses, e.g., “In the given …”, “There are no …”, “In this sentence …”.
Around 5.8 named entities per change log entry were generated. Many of the responses were obviously not named entities, and there were many instances of it listing clauses within the text, or even complete sentences. The table below shows the number of named entities containing a given number of ‘words’:
# words 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Occur 3274 1843 828 361 211 130 132 90 69 90 68 46 49 27 |
A total of 11,720 named entities were produced, of which 4,880 were unique (ignoring case).
Recent Comments