Archive
Grammar checking in 2018
I am a big fan of using tools to find problems quickly. Polishing the draft material for my evidence-based software engineering book, I have been finding an annoying number of grammatical mistakes :-(.
LanguageTool is what I use to check my grammar; it is the best tool of its kind that I know, and supports lots of different languages.
I also have an awk script that looks for new instances of previous mistakes I have made. It rarely flags anything, I seem to be in a continual state of making new grammatical mistakes.
Stung by a recent series is blatant mistakes, I have been searching for a better tool. What did I find:
- The 2014 Conference on Computational Natural Language Learning shared task was grammatical error correction,
- a bibliography of papers on grammatical error correction,
- LMGEC-Lite: the latest research tool (I will download the Billion Word Benchmark dataset, to build the 4G training dataset, from which the 10G language model is created, another day),
- a machine translation approach that automates grammatical error correction, i.e., rewrites what has been written. Perhaps I should use this tool on some of the software engineering papers I read, it could not make them any worse.
So, lots of interesting stuff, but nothing better that is usable.
I keep looking at the interesting things that spaCY can do (if you are looking to integrate language processing in your app, spaCY is currently the best language processing library). Does anybody know of grammar checking work being done using spaCY (LanguageTool is based around a parsing engine that is rather long in the tooth now)?
Anybody interested in organizing a grammar checking tool hack day in London?
Experimental Psychology by Robert S. Woodworth
I have just discovered “Experimental Psychology” by Robert S. Woodworth; first published in 1938, I have a reprinted in Great Britain copy from 1951. The Internet Archive has a copy of the 1954 revised edition; it’s a very useful pdf, but it does not have the atmospheric musty smell of an old book.
The Archives of Psychology was edited by Woodworth and contain reports of what look like ground breaking studies done in the 1930s.
The book is surprisingly modern, in that the topics covered are all of active interest today, in fields related to cognitive psychology. There are lots of experimental results (which always biases me towards really liking a book) and the coverage is extensive.
The history of cognitive psychology, as I understood it until this week, was early researchers asking questions, doing introspection and sometimes running experiments in the late 1800s and early 1900s (e.g., Wundt and Ebbinghaus), behaviorism dominants the field, behaviorism is eviscerated by Chomsky in the 1960s and cognitive psychology as we know it today takes off.
Now I know that lots of interesting and relevant experiments were being done in the 1920s and 1930s.
What is missing from this book? The most obvious omission is equations; lots of data points plotted on graph paper, but no attempt to fit an equation to anything, e.g., an exponential curve to the rate of learning.
A more subtle omission is the world view; digital computers had not been invented yet and Shannon’s information theory was almost 20 years in the future. Researchers tend to be heavily influenced by the tools they use and the zeitgeist. Computers as calculators and information processors could not be used as the basis for models of the human mind; they had not been invented yet.
Impact of team size on planning, when sitting around a table
A recent blog post by Allan Kelly caught my attention; on Monday Allan sent me some comments on the draft of my book and I got to ask for a copy of his data (you don’t need your own software engineering data before sending me comments).
During an Agile training course he gives, Allan runs an exercise based on an extended version of the XP game. The basic points are: people form into teams, a task is announced, teams have to estimate how long it will take them to complete the task and then to plan the task implementation. Allan recorded information on team size, time spent estimating and time spent planning (no information on the tasks, which were straightforward, e.g., fold a paper airplane).
In a recent post I gave a brief analysis of team size on productivity. What does this XP game data have to say about the impact of team size on performance?
We don’t have task information, but we do have two timing measurements for each team. With a bit of suck-it-and-see analysis, I found that the following equation explained 50% of the variance (code+data):

where:  is the number of people on a team,
is the number of people on a team,  is the time in minutes the team spent estimating and
is the time in minutes the team spent estimating and  is time in minutes the team spent planning the task implementation.
is time in minutes the team spent planning the task implementation.
There was some flexibility in the numbers, depending on the method used to build the regression model.
The introduction of each new team member incurs a fixed overhead. Given that everybody is sitting together around a table, this is not surprising; or, perhaps the problem was so simply that nobody felt the need to give a personal response to everything said by everybody else; or, perhaps the exercise was run just before lunch and people were hungry.
I am not aware of any connection between time spent estimating and time spent planning, but then I know almost nothing about this kind of XP game exercise. That square-root looks interesting (an exponent of 0.4 or 0.6 was a slightly less good fit). Thoughts and experiences anybody?
Update: I forgot to mention that including the date of the workshop in the above model increases the variance explained to 90%. The date here is a proxy for the task being solved. A model that uses just the date explains 75% of the variance.
2018 in the programming language standards’ world
I am sitting in the room, at the British Standards Institution, where today’s meeting of IST/5, the committee responsible for programming languages, has just adjourned (it’s close to where I have to be in a few hours).
BSI have downsized us, they no longer provide a committee secretary to take minutes and provide a point of contact. Somebody from a service pool responds (or not) to emails. I did not blink first to our chair’s request for somebody to take the minutes 🙂
What interesting things came up?
It transpires that reports of the death of Cobol standards work may be premature. There are a few people working on ‘new’ features, e.g., support for JSON. This work is happening at the ISO level, rather than the national level in the US (where the real work on the Cobol standard used to be done, before being handed on to the ISO). Is this just a couple of people pushing a few pet ideas or will it turn into something more substantial? We will have to wait and see.
The Unicode consortium (a vendor consortium) are continuing to propose new pile of poo emoji and WG20 (an ISO committee) were doing what they can to stay sane.
Work on the Prolog standard, now seems to be concentrated in Austria. Prolog was the language to be associated with, if you were on the 1980s AI bandwagon (and the Japanese were going to take over the world unless we did something about it, e.g., spend money); this time around, it’s machine learning. With one dominant open source implementation and one commercial vendor (cannot think of any others), standards work is a relic of past glories.
In pre-internet times there was an incentive to kill off committees that were past their sell-by date; it cost money to send out mailings and document storage occupied shelf space. In an electronic world there is no incentive to spend time killing off such committees, might as well wait until those involved retire or die.
WG23 (programming language vulnerabilities) reported lots of interest in their work from people involved in the C++ standard, and for some reason the C++ committee people in the room started glancing at me. I was a good boy, and did not mention bored consultants.
It looks like ISO/IEC 23360-1:2006, the ISO version of the Linux Base Standard is going to be updated to reflect LBS 5.0; something that was not certain few years ago.
Maximum team size before progress begins to stall
On multi-person projects people have to talk to each other, which reduces the amount of time available for directly working on writing software. How many people can be added to a project before the extra communications overhead is such that the total amount of code, per unit time, produced by the team decreases?
A rarely cited paper by Robert Tausworthe provides a simple, but effective analysis.
The plot below shows team productivity rate for a given number of team sizes, based on the examples discussed below.
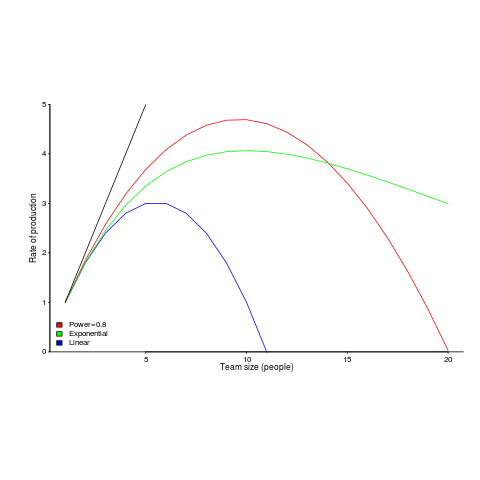
Activities are split between communicating and producing code.
If we assume the communications overhead is give by: ") , where
, where  is the percentage of one person’s time spent communicating in a two-person team,
is the percentage of one person’s time spent communicating in a two-person team,  the number of developers and
the number of developers and  a constant greater than zero (I’m using Tausworthe’s notation).
a constant greater than zero (I’m using Tausworthe’s notation).
The maximum team size, before adding people reduces total output, is given by: t_0})^{1/{alpha}}") .
.
If  (i.e., everybody on the project has the same communications overhead), then
(i.e., everybody on the project has the same communications overhead), then  , which for small is approximately
, which for small is approximately  . For example, if everybody on a team spends 10% of their time communicating with every other team member:
. For example, if everybody on a team spends 10% of their time communicating with every other team member:  .
.
In this team of five, 50% of each persons time will be spent communicating.
If  , then we have
, then we have *0.1})^{1/0.8}approx 10") .
.
What if the percentage of time a person spends communicating with other team members has an exponential distribution? That is, they spend most of their time communicating with a few people and very little with the rest; the (normalised) communications overhead is: t_1}") , where
, where  is a constant found by fitting data from the two-person team (before any more people are added to the team).
is a constant found by fitting data from the two-person team (before any more people are added to the team).
The maximum team size is now given by:  , and if
, and if  , then:
, then:  .
.
In this team of ten, 63% of each persons time will be spent communicating (team size can be bigger, but each member will spend more time communicating compared to the linear overhead case).
Having done this analysis, what is now needed is some data on the distribution of individual communications overhead. Is the distribution linear, square-root, exponential? I am not aware of any such data (there is a chance I have encountered something close and not appreciated its importance).
I have only every worked on relatively small teams, and am inclined towards the distribution of time spent communicating not being constant. Was it exponential or a power-law? I would not like to say.
Could a communications time distribution be reverse engineered from email logs? The cc’ing of people who might have an interest in a topic complicates the data analysis; time spent in meetings are another complication.
Pointers to data most welcome and as is any alternative analysis using data likely to have a higher signal/noise ratio.
StatsModels: the first nail in R’s coffin
In 2012, when I decided to write a book on evidence-based software engineering, R was the obvious system to use for data analysis. At the time, lots of new books had “using R” or “with R” added at the end of their titles; I chose “using R”.
When developers tell me they need to do some statistical analysis, and ask whether they should use Python or R, I tell them to use Python if statistics is a small part of the program, otherwise use R.
If I started work on the book today, I would till choose R. If I were starting five-years from now, I could be choosing Python.
To understand why I think Python will eventually take over the niche currently occupied by R, we need to understand the unique selling points of both systems.
R’s strengths are that it supports a way of thinking that is a good fit for doing data analysis and has an extensive collection of packages that simplify the task of applying a wide variety of analysis techniques to data.
Python also has packages supporting the commonly used data analysis techniques. But nearly all the Python packages provide a developer-mentality interface (i.e., they provide an API like any other package), R provides data-analysis-mentality interfaces. R supports a way of thinking that data analysts can identify with.
Python’s strengths, over R, are a much larger base of developers and language support for writing large programs (R is really a scripting language). Yes, Python has a package ecosystem supporting the full spectrum of application domains, this is not relevant for analysing a successful invasion of R’s niche market (but it is relevant for enticing new developers who are still making up their mind).
StatsModels is a Python package based around R’s data-analysis-mentality interface. When I discovered this package a few months ago, I realised the first nail had been hammered into R’s coffin.
Yes, today R has nearly all the best statistical analysis packages and a large chunk of the leading edge stuff. But packages can be reimplemented (C code can be copy-pasted, the R code mapped to Python); there is no magic involved. Leading edge has a short shelf life, and what proves to be useful can be duplicated; the market for leading edge code in a mature market (e.g., data analysis) is tiny.
A bunch of bright young academics looking to make a name for themselves will see the major trees in the R forest have been felled. The trees in the Python data-analysis-mentality forest are still standing; all it takes is a few people wanting to be known as the person who implemented the Python package that everybody uses for XYZ analysis.
A collection of packages supporting the commonly (and eventually not so commonly) used data analysis techniques, with a data-analysis-mentality interface, removes a major selling point for using R. Python is a bigger developer market with support for many other application domains.
The flow of developers starting out with R will slow down, casual R users will have nothing to lose from trying out another language when the right project comes along (another language on the CV looks good and Python is a bigger market). There will be groups where everybody uses R and will continue to use R because that is what everybody else in the group uses. Ten-Twenty years from now R, developers could be working in a ghost town.
What statistical techniques are useful for software engineering data?
What statistical techniques are of general usefulness for analyzing software engineering data?
The answer depends on the kinds of data likely to be encountered, in software engineering, and the questions likely to be asked.
When I started working on a book, aiming to cover all worthwhile publicly available software engineering data, I was hoping to refer readers to a book (or two) that they ought to read to learn the appropriate techniques. Kabacoff’s “R in Action” comes closest to the book I had in mind as a basic introduction, but there was nothing covering a wider range of topics; so I ended up writing something; I found Crawley’s “The R book”, to be the best book on the subject.
My answer to the kinds of data likely to be available was to work with all the software engineering data I could get obtain (around 600 data sets to date).
What questions should be asked about the data? My selection of questions was driven by whether the data was used in the software engineering half of the book, or the statistical analysis techniques half.
The software engineering material consists of the chapters: Introduction, Human cognitive characteristics, Cognitive capitalism, Ecosystems, Projects, Reliability and Source code. The data appeared in one of these chapters if it could be used to make (what I thought was) a practical point about the topic being discussed.
Data appeared in the statistical analysis techniques chapters, if it could be used to illustrate the technique under discussion.
What happened in practice was the software engineering material was worked on for a year or two, on realizing that bespoke statistical analysis material was needed the existing data was plundered to create the necessary chapters; after this was released, work switched back to the software engineering material (using unplundered and newly acquired data), and of course the earlier chapters plundered data from the yet to be worked on chapters.
This seems to have worked surprisingly well, at least from my perspective of keeping the production line going.
Now most if the data has been analyzed, it’s time to take a global overview and where necessary shuffle things around. I may find that everything is a complete mess; we shall see.
What techniques have I found to be useful?
The number 1, most useful data analysis technique is building a regression model. The one thing I have been consistently able to do, when analyzing other people’s data, is extract more information from it than they did (unless they also built a regression model); at times it has been embarrassing.
At number 2, is bootstrapping. Many widely used techniques only give accurate answers if the data has a normal/gaussian distribution and use of these techniques can involve a lot of arm waving involving claims about the data having a good-enough gaussian-like distribution. This arm waving was necessary before computers became available, because the practical manual techniques required a gaussian distribution. Now we have computers and techniques that don’t require any particular distribution can be used, and which in some cases are more powerful techniques than those designed for manual implementation.
Sitting here, I cannot think of a number 3; there might be one.
What techniques are not generally useful? The various tests containing some combination of the names Wilcoxon, Mann and Whitney are well past their sell-by date. Searching the source of the book I see these names still appear in one or two places; this is a hangover from the early versions from many years ago (when I was following the clueless herd) and will soon be gone.
I thought that extreme value theory might apply to some data, but have only found one data-set to which it might be applied (so not generally useful).
I spent a lot of time watching out for zero-inflated data (data containing more zero values than expected by the common probability distributions). I saw four/five papers containing plots of data that looked zero-inflated and emailed the authors asking for the data (who kindly sent it to me). None of the data turned out to be zero-inflated (I’m not sure what the authors thought about being asked for data that somebody thought was zero-inflated). This does not mean that software engineering data is not zero-inflated, only that it is not common.
My zero-inflated search was motivated by the occasional appearance of zero-truncated data (data with that does not contain zero values). Zero-truncated data occurs when counting starts at one, rather than zero (I have one data-set that is 0/1 truncated; the counting starts at 2).
I was surprised that time-series did not turn out to be widely useful.
Sometimes we are all clueless button pushers, so machine learning gets a few pages. Anybody who knows what they are doing builds regression models.
I will eventually get around to counting how many times each technique is used on the data I have (watch this blog, but don’t hold your breath).
Recent Comments