Archive
Foundations for Evidence-Based Policymaking Act of 2017
The Foundations for Evidence-Based Policymaking Act of 2017 was enacted by the US Congress on 21st December.
A variety of US Federal agencies are responsible for ensuring the safety of US citizens, in some cases this safety is dependent on the behavior of software. The FDA is responsible for medical device safety and the FAA publishes various software safety handbooks relating to aviation (the Department of transportation has a wider remit).
Where do people go to learn about the evidence for software related issues?
The book: Evidence-based software engineering: based on the publicly available evidence sounds like a good place to start.
Quickly skimming this (currently draft) book shows that no public evidence is available on lots of issues. Oops.
Another issue is the evidence pointing to some suggested practices being at best useless and sometimes fraudulent, e.g., McCabe’s cyclomatic complexity metric.
The initial impact of evidence-based policymaking will be companies pushing back against pointless government requirements, in particular requirements that cost money to implement. In some cases this is a good, e.g., no more charades about software being more testable because its code has a low McCable complexity.
In the slightly longer term, people are going to have to get serious about collecting and analyzing software related evidence.
The Open, Public, Electronic, and Necessary Government Data Act or the OPEN Government Data Act (which is about to become law) will be a big help in obtaining evidence. I think there is a lot of software related data sitting on disks and tapes, waiting to be analysed (NASA appears to have loads to data that they have down almost nothing with, including not making it publicly available).
Interesting times ahead.
Distorting the input profile, to stress test a program
A fault is experienced in software when there is a mistake in the code, and a program is fed the input values needed for this mistake to generate faulty behavior.
There is suggestive evidence that the distribution of coding mistakes and inputs generating fault experiences both have an influence of fault discovery.
How might these coding mistakes be found?
Testing is one technique, it involves feeding inputs into a program and checking the resulting behavior. What are ‘good’ input values, i.e., values most likely to discover problems? There is no shortage of advice for manually writing tests, suggesting how to select input values, but automatic generation of inputs is often somewhat random (relying on quantity over quality).
Probabilistic grammar driven test generators are trivial to implement. The hard part is tuning the rules and the probability of them being applied.
In most situations an important design aim, when creating a grammar, is to have one rule for each construct, e.g., all arithmetic, logical and boolean expressions are handled by a single expression rule. When generating tests, it does not always make sense to follow this rule; for instance, logical and boolean expressions are much more common in conditional expressions (e.g., controlling an if-statement), than other contexts (e.g., assignment). If the intent is to mimic typical user input values, then the probability of generating a particular kind of binary operator needs to be context dependent; this might be done by having context dependent rules or by switching the selection probabilities by context.
Given a grammar for a program’s input (e.g., the language grammar used by a compiler), decisions have to be made about the probability of each rule triggering. One way of obtaining realistic values is to parse existing input, counting the number of times each rule triggers. Manually instrumenting a grammar to do this is a tedious process, but tool support is now available.
Once a grammar has been instrumented with probabilities, it can be used to generate tests.
Probabilities based on existing input will have the characteristics of that input. A recent paper on this topic (which prompted this post) suggests inverting rule probabilities, so that common becomes rare and vice versa; the idea is that this will maximise the likelihood of a fault being experienced (the assumption is that rarely occurring input will exercise rarely executed code, and such code is more likely to contain mistakes than frequently executed code).
I would go along with the assumption about rarely executed code having a greater probability of containing a mistake, but I don’t think this is the best test generation strategy.
Companies are only interested in fixing the coding mistakes that are likely to result of a fault being experienced by a customer. It is a waste of resources to fix a mistake that will never result in a fault experienced by a customer.
What input is likely to interact with coding mistakes to be the root cause of faults experienced by a customer? I have no good answer to this question. But, given there are customer input contains patterns (at least in the world of source code, and I’m told in other application domains), I would generate test cases that are very similar to existing input, but with one sub-characteristic changed.
In the academic world the incentive is to publish papers reporting loads-of-faults-found, the more the merrier. Papers reporting only a few faults are obviously using inferior techniques. I understand this incentive, but fixing problems costs money and companies want a customer oriented rationale before they will invest in fixing problems before they are reported.
The availability of tools that automate the profiling of a program’s existing input, followed by the generation of input having slightly, or very, different characteristics make it easier to answer some very tough questions about program behavior.
Growth of conditional complexity with file size
Conditional statements are a fundamental constituent of programs. Conditions are driven by the requirements of the problem being solved, e.g., if the water level is below the minimum, then add more water. As the problem being solved gets more complicated, dependencies between subproblems grow, requiring an increasing number of situations to be checked.
A condition contains one or more clauses, e.g., a single clause in: if (a==1), and two clauses in: if ((x==y) && (z==3)); a condition also appears as the termination test in a for-loop.
How many conditions containing one clause will a 10,000 line program contain? What will be the distribution of the number of clauses in conditions?
A while back I read a paper studying this problem (“What to expect of predicates: An empirical analysis of predicates in real world programs”; Google currently not finding a copy online, grrr, you will have to hassle the first author: durelli@icmc.usp.br, or perhaps it will get added to a list of favorite publications {be nice, they did publish some very interesting data}) it contained a table of numbers and yesterday my analysis of the data revealed a surprising pattern.
The data consists of SLOC, number of files and number of conditions containing a given number of clauses, for 63 Java programs. The following plot shows percentage of conditionals containing a given number of clauses (code+data):

The fitted equation, for the number of conditionals containing a given number of clauses, is:

where:  (the coefficient for the fitted regression model is 0.56, but square-root is easier to remember),
(the coefficient for the fitted regression model is 0.56, but square-root is easier to remember),  , and
, and  is the number of clauses.
is the number of clauses.
The fitted regression model is not as good when  or
or  is always used.
is always used.
This equation is an emergent property of the code; simply merging files to increase the average length will not change the distribution of clauses in conditionals.
When  , all conditionals contain the same number of clauses, off to infinity. For the 63 Java programs, the mean was 2,625, maximum 11,710, and minimum 172.
, all conditionals contain the same number of clauses, off to infinity. For the 63 Java programs, the mean was 2,625, maximum 11,710, and minimum 172.
I was expecting SLOC to have an impact, but was not expecting number of files to be involved.
What grows with SLOC? Number of global variables and number of dependencies. There are more things available to be checked in larger programs, and an increase in dependencies creates the need to perform more checks. Also, larger programs are likely to contain more special cases, which are likely to involve checking both general and specific values (i.e., more clauses in conditionals); ok, this second sentence is a bit more arm-wavy than the first. The prediction here is that the percentage of global variables appearing in conditions increases with SLOC.
Chopping stuff up into separate files has a moderating effect. Since I did not expect this, I don’t have much else to say.
This model explains 74% of the variance in the data (impressive, if I say so myself). What other factors might be involved? Depth of nesting would be my top candidate.
Removing non-if-statement related conditionals from the count would help clarify things (I don’t expect loop-controlling conditions to be related to amount of code).
Two interesting data-sets in one week, with 10-days still to go until Christmas 🙂
Update: Fitting the same equation to the data from a later paper by the same group, based on mobile applications written in Swift and Objective-C, also produces a well-fitted regression model (apart from the term specifying an interactions between and  ).
).
Update: Thanks to Frank Busse for reminding me of the FAA report An Investigation of Three Forms of the Modified Condition Decision Coverage (MCDC) Criterion, which contains detailed information on the 20,256 conditionals in five Ada programs. The number of conditionals containing a given number of clauses is fitted by a power law (exponent is approximately -3).
Impact of group size and practice on manual performance
How performance varies with group size is an interesting question that is still an unresearched area of software engineering. The impact of learning is also an interesting question and there has been some software engineering research in this area.
I recently read a very interesting study involving both group size and learning, and Jaakko Peltokorpi kindly sent me a copy of the data.
That is the good news; the not so good news is that the experiment was not about software engineering, but the manual assembly of a contraption of the experimenters devising. Still, this experiment is an example of the impact of group size and learning (through repeating the task) on time to complete a task.
Subjects worked in groups of one to four people and repeated the task four times. Time taken to assemble a bespoke, floor standing rack with some odd-looking connections between components was measured (the image in the paper shows something that might function as a floor standing book-case, if shelves were added, apart from some component connections getting in the way).
The following equation is a very good fit to the data (code+data). There is theory explaining why ") applies, but the division by group-size was found by suck-it-and-see (in another post I found that time spent planning increased with teams size).
applies, but the division by group-size was found by suck-it-and-see (in another post I found that time spent planning increased with teams size).
There is a strong repetition/group-size interaction. As the group size increases, repetition has less of an impact on improving performance.
![time = 0.16+ 0.53/{group size} - log(repetitions)*[0.1 + {0.22}/{group size}]](https://shape-of-code.com/wp-content/plugins/wpmathpub/phpmathpublisher/img/math_981.5_b0d171bba046801a68ce5dc8ae1d6115.png "time = 0.16+ 0.53/{group size} - log(repetitions)*[0.1 + {0.22}/{group size}]")
The following plot shows one way of looking at the data (larger groups take less time, but the difference declines with practice), lines are from the fitted regression model:
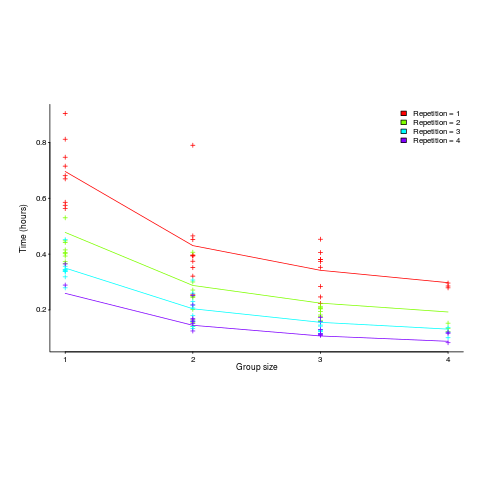
and here is another (a group of two is not twice as fast as a group of one; with practice smaller groups are converging on the performance of larger groups):
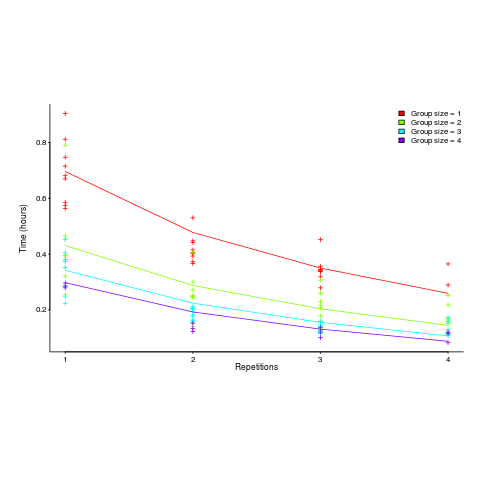
Would the same kind of equation fit the results from solving a software engineering task? Hopefully somebody will run an experiment to find out 🙂
Coding guidelines should specify what constructs can be used
There is a widespread belief that an important component of creating reliable software includes specifying coding constructs that should not be used, i.e., coding guidelines. Given that the number of possible coding constructs is greater than the number of atoms in the universe, this approach is hopelessly impractical.
A more practical approach is to specify the small set of constructs that developers that can only be used. Want a for-loop, then pick one from the top-10 most frequently occurring looping constructs (found by measuring existing usage); the top-10 covers 70% of existing C usage, the top-5 55%.
Specifying the set of coding constructs that can be used, removes the need for developers to learn lots of stuff that hardly ever gets used, allowing them to focus on learning a basic set of techniques. A small set of constructs significantly simplifies the task of automatically checking code for problems; many of the problems currently encountered will not occur; many edge cases disappear.
Developer coding mistakes have two root causes:
- what was written is not what was intended. A common example is the conditional in the if-statement:
if (x = y), where the developer intended to writeif (x == y). This kind of coding typo is the kind of construct flagged by static analysis tools as suspicious.People make mistakes, and developers will continue to make this kind of typographical mistake in whatever language is used,
- what was written does not have the behavior that the developer believes it has, i.e., there is a fault in the developers understanding of the language semantics.
Incorrect beliefs, about a language, can be reduced by reducing the amount of language knowledge developers need to remember.
Developer mistakes are also caused by misunderstandings of the requirements, but this is not language specific.
Why do people invest so much effort on guidelines specifying what constructs not to use (these discussions essentially have the form of literary criticism)? Reasons include:
- providing a way for developers to be part of the conversation, through telling others about their personal experiences,
- tool vendors want a regular revenue stream, and product updates flagging uses of even more constructs (that developers could misunderstand or might find confusing; something that could be claimed for any language construct) is a way of extracting more money from existing customers,
- it avoids discussing the elephant in the room. Many developers see themselves as creative artists, and as such are entitled to write whatever they think necessary. Developers don’t seem to be affronted by the suggestion that their artistic pretensions and entitlements be curtailed, probably because they don’t take the idea seriously.
Recent Comments