Archive
Estimating in round numbers
People tend to use round numbers. When asked the time, the response is often rounded to the nearest 5-minute or 15-minute value, even when using a digital watch; the speaker is using what they consider to be a relevant level of accuracy.
When estimating how long it will take to perform a task, developers tend to use round numbers (based on three datasets). Giving what appears to be an overly precise value could be taken as communicating extra information, e.g., an estimate of 1-hr 3-minutes communicates a high degree of certainty (or incompetence, or making a joke). If the consumer of the estimate is working in round numbers, it makes sense to give a round number estimate.
Three large software related effort estimation datasets are now available: the SiP data contains estimates made by many people, the Renzo Pomodoro data is one person’s estimates, and now we have the Brightsquid data (via the paper “Utilizing product usage data for requirements evaluation” by Hemmati, Didar Al Alam and Carlson; I cannot find an online pdf at the moment).
The plot below shows the total number of tasks (out of the 1,945 tasks in the Brightsquid data) for which a given estimate value was recorded; peak values shown in red (code+data):
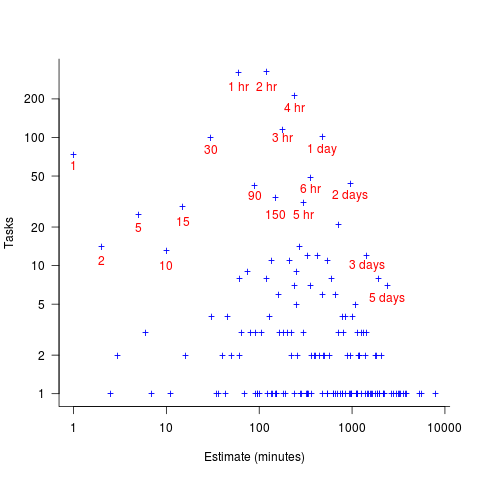
Why are there estimates for tasks taking less than 30 minutes? What are those 1 minute tasks (are they typos, where the second digit was omitted and the person involved simply create a new estimate without deleting the original)? How many of those estimate values appearing once are really typos, e.g., 39 instead of 30? Does the task logging system used require an estimate before anything can be done? Unfortunately I don’t have access to the people involved. It does look like this data needs some cleaning.
There are relatively few 7-hour estimates, but lots for 8-hours. I’m assuming the company works an 8-hour day (the peak at 4-hours, rather than three, adds weight to this assumption).
New users generate more exceptions than existing users (in one dataset)
Application usage data is one of the rarest kinds of public software engineering data.
Even data that might be used to approximate application usage is rare. Server logs might be used as a proxy for browser usage or operating system usage, and number of Debian package downloads as a proxy for usage of packages.
Usage data is an important component of fault prediction models, and the failure to incorporate such data is one reason why existing fault models are almost completely worthless.
The paper Deriving a Usage-Independent Software Quality Metric appeared a few months ago (it’s a bit of a kitchen sink of a paper), and included lots of usage data! As far as I know, this is a first.
The data relates to a mobile based communications App that used Google analytics to log basic usage information, i.e., daily totals of: App usage time, uses by existing users, uses by new users, operating system+version used by the mobile device, and number of exceptions raised by the App.
Working with daily totals means there is likely to be a non-trivial correlation between usage time and number of uses. Given that this is the only public data of its kind, it has to be handled (in my case, ignored for the time being).
I’m expecting to see a relationship between number of exceptions raised and daily usage (the data includes a count of fatal exceptions, which are less common; because lots of data is needed to build a good model, I went with the more common kind). So a’fishing I went.
On most days no exception occurred (zero is the ideal case for the vendor, but I want lots of exception to build a good model). Daily exception counts are likely to be small integers, which suggests a Poisson error model.
It is likely that the same set of exceptions were experienced by many users, rather like the behavior that occurs when fuzzing a program.
Applications often have an initial beta testing period, intended to check that everything works. Lucky for me the beta testing data is included (i.e., more exceptions are likely to occur during beta testing, which get sorted out prior to official release). This is the data I concentrated my modeling.
The model I finally settled on has the form (code+data):

Yes,  had a much bigger impact than
had a much bigger impact than  . This was true for all the models I built using data for all Android/iOS Apps, and the exponent difference was always greater than two.
. This was true for all the models I built using data for all Android/iOS Apps, and the exponent difference was always greater than two.
Why square-root, rather than log? The model fit was much better for square-root; too much better for me to be willing to go with a model which had  as a power-law.
as a power-law.
The impact of  varied by several orders of magnitude (which won’t come as a surprise to developers using earlier versions of Android).
varied by several orders of magnitude (which won’t come as a surprise to developers using earlier versions of Android).
There were not nearly as many exceptions once the App became generally available, and there were a lot fewer exceptions for the iOS version.
The outsized impact of new users on exceptions experienced is easily explained by developers failing to check for users doing nonsensical things (which users new to an App are prone to do). Existing users have a better idea of how to drive an App, and tend to do the kind of things that developers expect them to do.
As always, if you know of any interesting software engineering data, please let me know.
Happy 60th birthday: Algol 60
Report on the Algorithmic Language ALGOL 60 is the title of a 16-page paper appearing in the May 1960 issue of the Communication of the ACM. Probably one of the most influential programming languages, and a language that readers may never have heard of.
During the 1960s there were three well known, widely used, programming languages: Algol 60, Cobol, and Fortran.
When somebody created a new programming languages Algol 60 tended to be their role-model. A few of the authors of the Algol 60 report cited beauty as one of their aims, a romantic notion that captured some users imaginations. Also, the language was full of quirky, out-there, features; plenty of scope for pin-head discussions.
Cobol appears visually clunky, is used by business people and focuses on data formatting (a deadly dull, but very important issue).
Fortran spent 20 years catching up with features supported by Algol 60.
Cobol and Fortran are still with us because they never had any serious competition within their target markets.
Algol 60 had lots of competition and its successor language, Algol 68, was groundbreaking within its academic niche, i.e., not in a developer useful way.
Language family trees ought to have Algol 60 at, or close to their root. But the Algol 60 descendants have been so successful, that the creators of these family trees have rarely heard of it.
In the US the ‘military’ language was Jovial, and in the UK it was Coral 66, both derived from Algol 60 (Coral 66 was the first language I used in industry after graduating). I used to hear people saying that Jovial was derived from Fortran; another example of people citing the language the popular language know.
Algol compiler implementers documented their techniques (probably because they were often academics); ALGOL 60 Implementation is a real gem of a book, and still worth a read today (as an introduction to compiling).
Algol 60 was ahead of its time in supporting undefined behaviors 😉 Such as: “The effect, of a go to statement, outside a for statement, which refers to a label within the for statement, is undefined.”
One feature of Algol 60 rarely adopted by other languages is its parameter passing mechanism, call-by-name (now that lambda expressions are starting to appear in widely used languages, call-by-name has a kind-of comeback). Call-by-name essentially has the same effect as textual substitution. Given the following procedure (it’s not a function because it does not return a value):
procedure swap (a, b); integer a, b, temp; begin temp := a; a := b; b:= temp end; |
the effect of the call: swap(i, x[i]) is:
temp := i; i := x[i]; x[i] := temp |
which might come as a surprise to some.
Needless to say, programmers came up with ‘clever’ ways of exploiting this behavior; the most famous being Jensen’s device.
The follow example of go to usage appears in: International Standard 1538 Programming languages – ALGOL 60 (the first and only edition appeared in 1984, after most people had stopped using the language):
go to if Ab < c then L17 else g[if w < 0 then 2 else n] |
Orthogonality of language use won out over the goto FUD.
The Software Preservation Group is a great resource for Algol 60 books and papers.
Having all the source code in one file
An early, and supposedly influential, analysis of the Coronavirus outbreak was based on results from a model whose 15,000 line C implementation was contained in a single file. There has been lots of tut-tutting from the peanut gallery, about the code all being in one file rather than distributed over many files. The source on Github has been heavily reworked.
Why do programmers work with all the code in one file, rather than split across multiple files? What are the costs and benefits of having the 15K of source in one file, compared to distributing it across multiple files?
There are two kinds of people who work with code all in one file, novices and really capable developers. Richard Stallman is an example of a very capable developer who worked using files containing huge amounts of code, as anybody who looked at the early sources of gcc will be all to familiar.
The benefit of having all the code in one file is that it is easy to find stuff and make global changes. If the source is scattered over multiple files, then working on the code entails knowing which file to look in to find whatever; there is a learning curve (these days screens have lots of pixels, and editors support multiple windows with a different file in each window; I’m sure lots of readers work like this).
Many years ago, when 64K was a lot of memory, I sometimes had to do developer support: people would come to me complaining that the computer was preventing them writing a larger program. What had happened was they had hit the capacity limit of the editor. The source now had to be spread over multiple files to get over this ‘limitation’. In practice people experienced the benefits of using multiple files, e.g., editor loading files faster (because they were a lot smaller) and reduced program build time (because only the code that changed needed to be recompiled).
These days, 15K of source can be loaded or compiled in a blink of an eye (unless a really cheap laptop is being used). Computing power has significantly reduced these benefits that used to exist.
What costs might be associated with keeping all the source in one file?
Monolithic code makes sharing difficult. I don’t know anything about the development environment within which these researched worked. If there were lots of different programs using the same algorithms, or reading/writing the same file formats, then code reuse often provides a benefit that makes it worthwhile splitting off the common functionality. But then the researchers has to learn how to build a program from multiple source files, which a surprising number are unwilling to do (at least it has always been surprising to me).
Within a research group, sharing across researchers might be a possible (assuming they are making some use of the same algorithms and file formats). Involving multiple people in the ongoing evolution of software creates a need for some coordination. At the individual level it may be more cost-efficient for people to have their own private copies of the source, with savings only occurring at the group level. With software development having a low status in academia, I don’t see any of the senior researchers willingly take on a management role, for this code. Perhaps one of the people working on the code is much better than the others (it often happens), but are they going to volunteer themselves as chief dogs body for the code?
In the world of Open Source, where source code is available, cut-and-paste is rampant (along with wholesale copying of files). Working with a copy of somebody else’s source removes a dependency, and if their code works well enough, then go for it.
A cost often claimed by the peanut gallery is that having all the code in a single file is a signal of buggy code. Given that most of the programmers who do this are novices, rather than really capable developers, such code is likely to contain many mistakes. But splitting the code up into multiple files will not reduce the number of mistakes it contains, just distribute them among the files. Correlation is not causation.
For an individual developer, the main benefit of splitting code across multiple files is that it makes developers think about the structure of their code.
For multi-person projects there are the added potential benefits of reusing code, and reducing the time spent reading other people’s code (it’s no fun having to deal with 10K lines when only a few functions are of interest).
I’m not saying that the original code is good, bad, or indifferent. What I am saying is that the having all the source in one file may, or may not, be the most effective way of working. It’s complicated, and I have no problem going with the flow (and limiting the size of the source files I write), but let’s not criticise others for doing what works for them.
Enthusiasm on the Fortran standards committee
The Fortran language standards committee, SC22/WG5, has an unusual situation on its hands. Two people have put themselves forward to chair the committee, when the current chairman’s three year term ends. What is unusual is that it is often difficult to find anybody willing to do the job.
The two candidates are the outgoing chair (the person who invariably does the job, until they decide they have had enough, or can arm wrestle someone else to do it), and a scientist at Los Alamos; I don’t know either person.
SC22 (the ISO committee responsible for language standards), and INCITS (the US Standards body; the US is the Fortran committee secretariate) will work something out.
I had heard that the new guy was ruffling some feathers, and I thought good for him (committees could do with having their feathers ruffled every now and again). Then I read the running for convenor announcement; oh dear. Every committee has a way of working: the objectives listed in this announcement would go down really well with the C++ committee (which already does many of the points listed), but the Fortran committee don’t operate this way.
The language standards world appears to be very similar to the open source world, in that they are both driven by the people who do the work. One person can have a big impact in the open source world, simply by doing the work, but in the language standards world there is voting (people can vote in the open source world by using software or not). One person can write papers and propose lots of additions to a standard, but the agreement of committee members is needed before any wording is added to a draft standard, which eventually goes out for a round of voting by national bodies.
Over the years I have seen several people on a standards committee starting out very enthusiastic, writing proposals and expounding them at meetings; then after a year or two becoming despondent because nothing has happened. If committee members don’t like your proposal (or choose to spend their time on other proposals), they do nothing. A majority doing nothing is enough to stop something happening.
Once a language has become established, many of its users want the committee to move slowly. Compiler vendors don’t want to spend all their time keeping up with language updates (which rarely help sell more product), and commercial users don’t want the hassle of having to spend time working out how a new standard might impact them (having zero impact on existing is a common aim of language committees).
The young, the enthusiastic, and magazines looking to sell clicks are excited by change. An ISO language committee is generally not the place to find it.
Update
INCITS have nominated the current chair for the next three-year term.
Recent Comments