Archive
Projects are worked on in fits and starts
Companies whose business is designing, developing, and maintaining custom software applications (i.e., a software house) have the difficult job of keeping their expensive employees busy with paying work. Work on an existing project may be held up for various reasons, and the start date of new projects is invariably uncertain.
A solution to the on/off nature of project work is for staff to distribute their time across multiple projects. If one project is held up, there is another project available for them to book their time to.
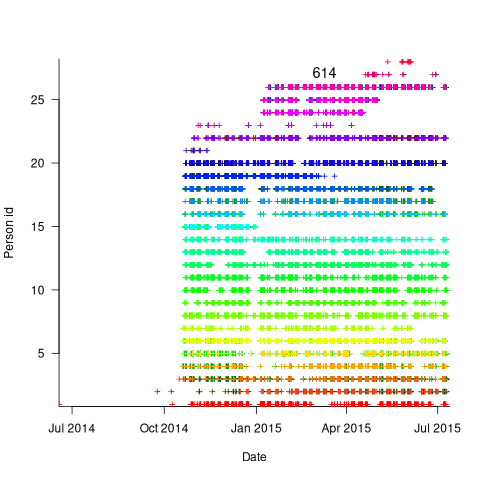
The plot below is for project 614 in the CESAW dataset, and shows the days on which 28 people worked on this project between July 2014 and July (code+data):
The published models of the software development lifecycle are based on perceptions of the workings of large DOD and NASA projects from the 1960s and 1970s. These projects are treated as self-contained entities, with people being available when needed and individually interchangeable. This perception fits with the software physics thinking of the time, along with the early 1960s work of Norden, and the use of differential equations to model the evolution of project manpower. These models fitted the small amount of available data as well as several other models. With some hand waving it is possible to make models such as the Putnam model look good.
With 28 people working on project 614, it’s possible that individual contributions don’t have a big impact on totals, i.e., the total time spent per week (say) does not fluctuate widely. The plot below shows the total hours per week spent on design, coding and test (total project time as roughly three staff years; code+data):
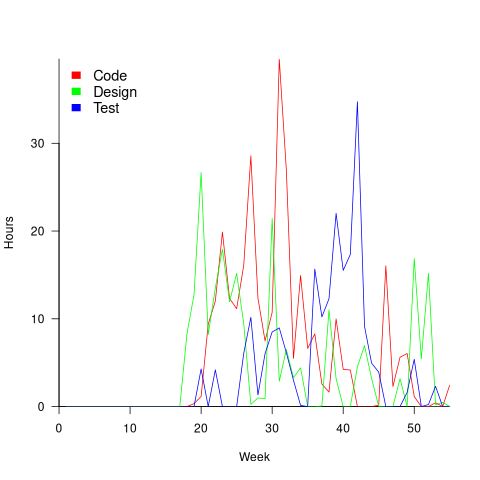
Plenty of wide fluctuations, plus some expected large drops in time spent on the project. For instance, a big drop in all activities around Christmas, and a smaller dip around Thanksgiving.
Having 28 people work on a three-person year project does seem a bit extreme (average of seven-weeks per person). On the other hand, I may be out of date, not having been a team member on a large project in decades.
The total effort required by the projects in the CESAW dataset range from three-person months to three-person years, which I suspect (no data on this question) straddles the range of time spent on the majority of software projects. The projects mostly involve people spending a non-large percentage of time on a project. The data is anonymised on a project basis, and it is not possible to count the number of projects a person is working on at any time.
To summarise: Building a good enough model of software project staffing requires taking into account organization wide staffing priorities. Existing models don’t do this.
Answering via a scale to improve estimation accuracy
The human brain differs from the brain of other animals in having two number processing systems: 1) the approximate number system (present in other animals), and 2) language.
Round numbers are often given in answers when using language, to questions having a numeric answer. While use of round numbers may be conversationally appropriate, they decrease the accuracy of the answer.
Numeric values can be specified without using language. For instance, by pointing at a position on a scale representing a sequence of increasing/decreasing values, such as a ruler. Are answers given by pointing at a scale less likely to be round numbers, and more importantly are they likely to be more accurate than answers given using language?
Various studies by psychologists have investigated response differences between answering using language and scales. The analysis below is based on data from the paper: On the round number bias and wisdom of crowds in different response formats for numerical estimation by Honda, Kagawa and Shirasuna. This study asked 1,805 subjects to estimate the number of dots in an image, like the one below, with images containing: 183, 287, 360, 453, 554, 633, 719, 807, or 986 dots (randomly selected):

Subjects responded using a randomly selected one of six different scales or using language (i.e., typing a number). The scales differed in axis labeling and some were zero based (subjects had to slide the blue colored circle from zero to a position, rather than clicking on a position); see image below:

The plot below shows the normalised occurrences of estimate values (rounded to the nearest value divisible by five) made using language (red) and one of the scales (blue/green), with grey line showing actual number of dots. There was little difference between the various kinds of scales, and all the scale answers have been aggregated (code+data):
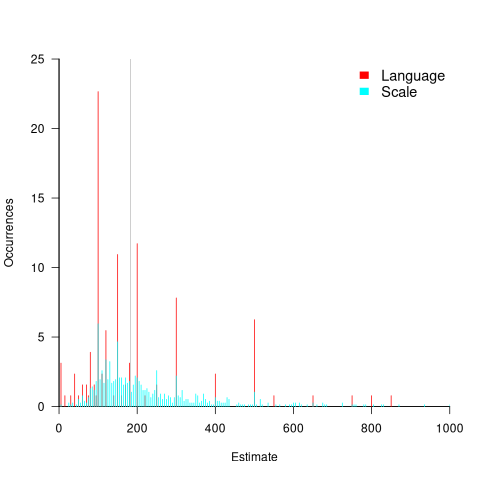
The red spikes clearly show many language given answers are at round numbers. The answers given using a scale are much less likely to be round numbers, with the blue/green lines showing the use of a wider selection of estimates.
Are answers given using language likely to be more or less accurate than answer given using a scale?
The plot above shows that few responses are close to the actual value, which means that no fitted model is going to explain much of the variability in the data. All the regression models I fitted to the difference between answers and actuals found that languages responses were less accurate, on average (code+data). Combining the explanatory variables in a variety of different ways did not significantly affect the quality of the fitted model.
In hand-wavy terms, the average error in the language responses was at most 10% larger than the scale responses.
To summaries, scale responses are likely to be more accurate, but a lot less likely to be a round number.
People are willing to tradeoff accuracy for being able to communicate using a round number. For instance, I once pointed out to a manager that changing all 1-hour estimates to 1.25 hours would significantly improve accuracy; he was unwilling to give up the greater uncertainty implied by the 1-hour estimate.
Will this behavior replicate for software task estimates? Is it possible to shift a scale answer to the closest round number without losing the accuracy advantage?
We will have to wait until somebody does the appropriate study.
Estimating Open source project lifecycle using the Bass model
Is it possible to reliably estimate the elapsed time that a multi-person Open source project spends under major active development, once it has been running for a year or so, and attracted some developers?
The paper Project Life Cycles in Open-Source Software by Das, Ieroshenko, Jain, Qiu, Chin, and Granger fits a Bass diffusion model to the number of monthly developers contributing to a project, and then extrapolates the fitted equation into the future. Is the Bass model a good fit to this kind of data, and how reliable might its prediction be?
What first caught my attention in this paper was the appearance of the sech function (i.e., the hyperbolic secant:  ) in the derived formula. The only other place I have encountered this function in software engineering is the Parr model of project staffing distribution, e.g., effort in hours per week. What’s more, both instances involve
) in the derived formula. The only other place I have encountered this function in software engineering is the Parr model of project staffing distribution, e.g., effort in hours per week. What’s more, both instances involve sech squared, i.e.,  .
.
Is this use of a coincidence, or is there an interesting connection? Let’s look at the paper.
The Bass diffusion model, or just Bass model, assumes that the number of people buying a new product is controlled by two factors: 1) independents who have a constant probability,  , of buying it, and 2) imitators whose probability of purchase depends on
, of buying it, and 2) imitators whose probability of purchase depends on  times the number of existing users of the product (see section 3.6.3 of my book). The Bass model has been extended to handle successive, overlapping generations of a product, e.g., IBM mainframes.
times the number of existing users of the product (see section 3.6.3 of my book). The Bass model has been extended to handle successive, overlapping generations of a product, e.g., IBM mainframes.
I have not seen the Bass model applied to software lifecycles before (a quick search found a 2014 paper using it to model the time-evolution of package dependencies).
The authors of the new paper introduced sech by normalising two variables in the Bass equation: ^2e^{(p+q)t}}/{(pe^{(p+q)t}+q)^2}")
Time,  is normalised by dividing by time of peak development,
is normalised by dividing by time of peak development,  , and number of developers,
, and number of developers,  , is normalised by dividing by peak number of developers,
, is normalised by dividing by peak number of developers,  , giving:
, giving:
)") , where
, where ") , and
, and  . It’s not possible to fit this equation to project data because the peak development values are not known (or might not yet have been reached).
. It’s not possible to fit this equation to project data because the peak development values are not known (or might not yet have been reached).
The equation in the Parr model is: ") , where the values of
, where the values of  and
and  are obtained by fitting a regression model to project data. The derivation of the Parr model assumes that as project implementation progresses, new problems that need to be solved are discovered (e.g., features to be implemented), an existing problem can spawn at most two new subproblems, and the number of new problems discovered at any time is proportional to the number of remaining problems (cannot find an online version of “An alternative to the Rayleigh curve model for software development effort”).
are obtained by fitting a regression model to project data. The derivation of the Parr model assumes that as project implementation progresses, new problems that need to be solved are discovered (e.g., features to be implemented), an existing problem can spawn at most two new subproblems, and the number of new problems discovered at any time is proportional to the number of remaining problems (cannot find an online version of “An alternative to the Rayleigh curve model for software development effort”).
A connection can be made between the Bass and Parr models by equating the number of developers contributing with the number of problems to be solved, with contributors treated as independents or imitators. The opportunities for potential contributors are likely to increase as a project starts up and then, for some projects decrease (projects such as the Linux kernel just keep on going). The problem implemented by a developer could spawn more than two subproblems.
In practice most of the implementation work on an Open source project is done by a small percentage of developers, with some projects dieing after loosing a few core developers. There is also the issue of the same person contributing using multiple identities.
One method for checking how well a model predicts future measurements is to compare the equations fitted using all the monthly data and, say, the first 75% months. The extent to which both fitted equations agree provides an indication of the likely accuracy of currently unknown future values. The Das et al paper fits the Bass model to the monthly contributor data from 23 projects. The plot below shows the number of monthly developers for numpy (since the project started), along with two fitted Bass models, one for all the data and the other for the first 75% of the data (code+data):
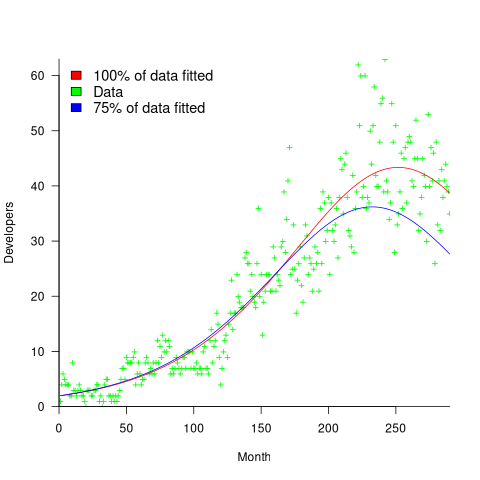
The example project used in the paper has a closer agreement between the two fitted equations, and some of the other projects have much less agreement. The Bass models assumes that monthly contributions are primarily driven by two factors. In practice there could be many other factors driving developer involvement in a project.
Predicting when a project is likely to stop growing is a notoriously difficult problem. Fitting a logistic equation to the growth in lines of code is another example of a model fitting the pattern present in the underlying equation (which flattens off).
It’s possible that weighting developer contribution by the amount of functionality (not lines of code) will produce a closer agreement between theory and practice.
The Putnam project staffing model predates the Parr mode, and later research found that the Putnam model was also a poor predictor of project durations. Both the Parr and Putnam equations can be derived using hazard analysis.
Applying the Bass multi-product generation model to software evolution is now on my to-do list, e.g., use of PHP versions.
Software task estimation using LLMs is fake research
Developers hate having to provide an estimate for the time needed to implement some functionality. Given the extent to which LLMs have become embedded in the software world, offloading the estimation question to an LLM appears to be an obvious solution.
The problem is that LLMs are very unlikely to give a meaningful answer. However, given that 33% of human estimates are accurate (for tasks of a few hours), 66% within a factor of two (over or under), and 95% within a factor of four (over or under), the accuracy bar for LLMs is low.
Given enough training data, LLMs can do amazing things, e.g., help solve difficult maths problems. LLMs often being good-enough at producing source code is dependent on them having been trained on huge amounts of source code.
The miniscule amount of publicly available software task estimation data is orders of magnitude smaller than the quantity needed to effectively fine-tune a software oriented LLM. Estimation training data needs to contain the following information:
- an appropriately detailed description of the problem,
- the source code of the program being updated, as it existed prior to this or any later features being added (similar descriptions may involve different implementation activities on different projects),
- the actual implementation time,
- a summary of the skill set of the developers who did the work (a developer familiar with the source is likely to complete a task faster than a developer new to the project).
There are datasets (here {10K rows} and here {62K rows}) that contain items (1) and (3).
There are datasets (e.g., here {37K rows} and here {23K rows}) that contain (1) for Open source projects, so (2) could be obtained. These datasets contain estimates (usually in Story Points), and a handful of recorded actuals (and often a status change date-time for each issue, which might/perhaps/maybe used as a proxy for actual work time).
Estimation data (in story points, function points, or time) is much more common than Actual (when available, usually time). Needless to say, there are papers (e.g., here and here) that use human estimation data for training, and then measure LLM performance on close it comes to the human estimates, not the actuals.
My 2024 summary of what is known about task estimation did not discuss the impact of LLMs. What was known is 2024 is that several human factors (e.g., use of round numbers and individual risk profile) play a major role in task estimation. LLMs may reduce the time needed for some tasks, but the human factors remain.
The use of round numbers is deeply embedded in the brain. I suspect the impact of LLM usage will not be to reduce implementation time estimates for tasks, but to increase the amount of functionality included in a task to match the established round number times of 1,2,4 and 7 hours.
Users of story points have the option of leaving everything unchanged. However, there are users of story points who equate one story point to one hour. Will the amount of task functionality be increased to maintain this equating?
Users of function points can continue to count them in the same way. What changes, in an LLM world, is the cost of implementing a function point. Given that the method of calculating the number of function points is specified in various national/international standards, it is not possible to simply increase the amount of functionality to maintain the existing price of a function point.
To summarise: LLMs are being trained on small datasets that don’t contain all the required information to give responses that mimic human estimates made in a pre-LLM world.
One of my most popular blog posts is: Software effort estimation is mostly fake research. The adverb “mostly” can be dropped once LLMs are involved.
Taking a new GLR parser generator for a spin
It’s been 10 years since I last wrote about parsing tools, and the C parser, pycparser, I took for a test drive is still actively maintained. This week I read a post on Gecko, a new parser generator. Its author, Vladimir Makarov, implemented his first parser generator in 1985.
Gecko generates GLR parsers (Generalized Left-to-Right). In 2009, I predicted that GLR parsing was the future. It might still be the future, but since I made that prediction handwritten parsers, using some form of recursive descent, are what the major compilers (e.g., gcc and llvm) have been updated to use. Bison, the almost invisible market leader for parser generation, has supported GLR parsers for almost 20 years. The other ‘generalized’ technique, Earley parsing, produces parsers that are much slower and are memory hogs.
GLR parsers support Type-1 languages in the Chomsky hierarchy. The LR parsers supported by yacc compatible tools (e.g., the Bison default mode), and LL by ANTLR, can handle Type-2 languages, and regular expressions are Type-3 languages.
Programming language grammars are often context-sensitive (ambiguous is the common developer terminology), i.e., there is more than one way of parsing a sequence of input tokens. The classic example is the C statement: T *p;, which could be a declaration of p, or a redundant multiplication. This ambiguity can be resolved by maintaining a list of identifiers currently defined as typedefs, and have the lexer/parser lookup the status of identifiers in the contexts where a typedef could occur. This is not a big deal for compilers, which have to build a symbol table anyway. However, it’s very inconvenient when only syntax analysis is needed, i.e., no semantic analysis of the source.
An alternative approach is to parse all possibilities, and hope that eventually only one parse is syntactically possible. The following example could work, because there is a subsequent use of T in a non-typedef context (I’m not aware of any tools that do this):
T *p; // Is this a declaration of p as a pointer to T? T++; // No! It's a multiplication of T by p |
Another approach is to choose the most likely parse. Redundant multiplications are rare, and a declaration is the most likely usage. The token sequence f(x); is most likely to be a function call with one argument, rather than redundant parenthesis around a declaration of x to have type f.
Taking Gecko for a test drive requires a lexer and a grammar. Fortunately, one of the Gecko test cases includes a C lexer/grammar, and I adapted this to try out some C syntax test cases (code). My comparison point for these tests my memory of testing out Bison with GLR enabled.
Developers make coding mistakes, and I made mistakes when adapting the existing Gecko C grammar. Perhaps because I’m new to it, but Gecko’s minimalist error reporting was not helpful. Lots of debug information is available, but this is oriented towards somebody developing the innards of a parser generator. Hopefully, now Gecko is up and working, the focus will shift to improving developer diagnostics.
When Bison fails to merge multiple parses into a single parse, it failed. Gecko appears not to fail (it’s difficult to tell), it returns a parse tree.
Coding mistakes are sometime syntax errors, and without some form of error recovery, syntax errors often cascade to produce lots of spurious errors. Recovering from syntax errors is hard, but skipping to the next semicolon works remarkably well as a catch-all.
In Bison, syntax error recovery has to be hand-coded into the grammar and parser. Gecko supports an automatic syntax error recovery process. Based on a small sample, this automatic process failed to handle the common syntax errors (e.g., missing identifier or missing operator in an expression) I tried it on (code). It did handle the example in the documentation. Perhaps this is a work in progress.
The Gecko source built and passed all of its own tests. My tests are intended to check for handling of ambiguous constructs and error handling. As such, they are not pass/fail.
The main functional difference between Gecko and Bison is that Gecko is compiled into the program and can then be used to read and process a grammar at program runtime. Bison processes the grammar to produce tables that are included as part of the build process of a program.
This difference enables Gecko to handle grammars that are created or updated at application runtime. This approach also simplifies the process of handling multiple grammars.
While on the subject of parser generators, I have been following the progress of Marpa, but not tried it yet. The author has some interesting things to say about parsing.
Recent Comments