Archive
Projects are worked on in fits and starts
Companies whose business is designing, developing, and maintaining custom software applications (i.e., a software house) have the difficult job of keeping their expensive employees busy with paying work. Work on an existing project may be held up for various reasons, and the start date of new projects is invariably uncertain.
A solution to the on/off nature of project work is for staff to distribute their time across multiple projects. If one project is held up, there is another project available for them to book their time to.
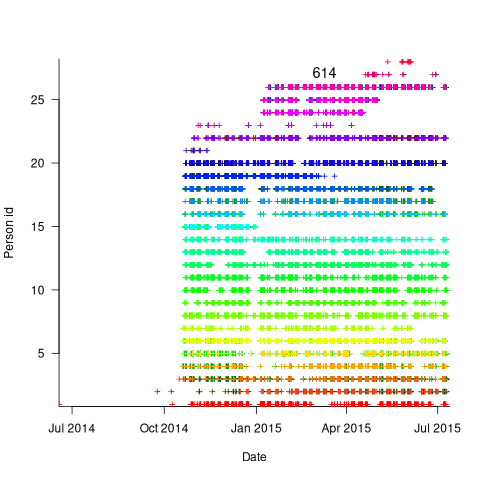
The plot below is for project 614 in the CESAW dataset, and shows the days on which 28 people worked on this project between July 2014 and July (code+data):
The published models of the software development lifecycle are based on perceptions of the workings of large DOD and NASA projects from the 1960s and 1970s. These projects are treated as self-contained entities, with people being available when needed and individually interchangeable. This perception fits with the software physics thinking of the time, along with the early 1960s work of Norden, and the use of differential equations to model the evolution of project manpower. These models fitted the small amount of available data as well as several other models. With some hand waving it is possible to make models such as the Putnam model look good.
With 28 people working on project 614, it’s possible that individual contributions don’t have a big impact on totals, i.e., the total time spent per week (say) does not fluctuate widely. The plot below shows the total hours per week spent on design, coding and test (total project time as roughly three staff years; code+data):
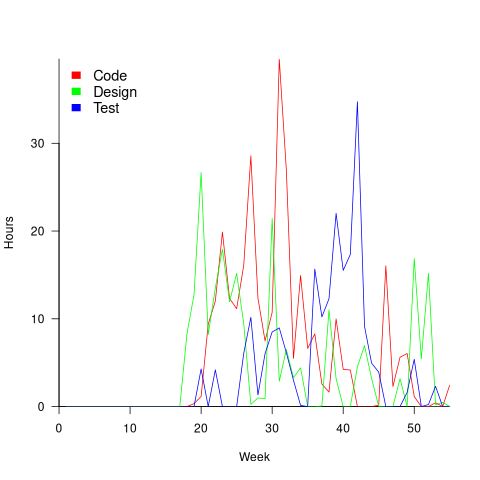
Plenty of wide fluctuations, plus some expected large drops in time spent on the project. For instance, a big drop in all activities around Christmas, and a smaller dip around Thanksgiving.
Having 28 people work on a three-person year project does seem a bit extreme (average of seven-weeks per person). On the other hand, I may be out of date, not having been a team member on a large project in decades.
The total effort required by the projects in the CESAW dataset range from three-person months to three-person years, which I suspect (no data on this question) straddles the range of time spent on the majority of software projects. The projects mostly involve people spending a non-large percentage of time on a project. The data is anonymised on a project basis, and it is not possible to count the number of projects a person is working on at any time.
To summarise: Building a good enough model of software project staffing requires taking into account organization wide staffing priorities. Existing models don’t do this.
Estimating Open source project lifecycle using the Bass model
Is it possible to reliably estimate the elapsed time that a multi-person Open source project spends under major active development, once it has been running for a year or so, and attracted some developers?
The paper Project Life Cycles in Open-Source Software by Das, Ieroshenko, Jain, Qiu, Chin, and Granger fits a Bass diffusion model to the number of monthly developers contributing to a project, and then extrapolates the fitted equation into the future. Is the Bass model a good fit to this kind of data, and how reliable might its prediction be?
What first caught my attention in this paper was the appearance of the sech function (i.e., the hyperbolic secant:  ) in the derived formula. The only other place I have encountered this function in software engineering is the Parr model of project staffing distribution, e.g., effort in hours per week. What’s more, both instances involve
) in the derived formula. The only other place I have encountered this function in software engineering is the Parr model of project staffing distribution, e.g., effort in hours per week. What’s more, both instances involve sech squared, i.e.,  .
.
Is this use of a coincidence, or is there an interesting connection? Let’s look at the paper.
The Bass diffusion model, or just Bass model, assumes that the number of people buying a new product is controlled by two factors: 1) independents who have a constant probability,  , of buying it, and 2) imitators whose probability of purchase depends on
, of buying it, and 2) imitators whose probability of purchase depends on  times the number of existing users of the product (see section 3.6.3 of my book). The Bass model has been extended to handle successive, overlapping generations of a product, e.g., IBM mainframes.
times the number of existing users of the product (see section 3.6.3 of my book). The Bass model has been extended to handle successive, overlapping generations of a product, e.g., IBM mainframes.
I have not seen the Bass model applied to software lifecycles before (a quick search found a 2014 paper using it to model the time-evolution of package dependencies).
The authors of the new paper introduced sech by normalising two variables in the Bass equation: ^2e^{(p+q)t}}/{(pe^{(p+q)t}+q)^2}")
Time,  is normalised by dividing by time of peak development,
is normalised by dividing by time of peak development,  , and number of developers,
, and number of developers,  , is normalised by dividing by peak number of developers,
, is normalised by dividing by peak number of developers,  , giving:
, giving:
)") , where
, where ") , and
, and  . It’s not possible to fit this equation to project data because the peak development values are not known (or might not yet have been reached).
. It’s not possible to fit this equation to project data because the peak development values are not known (or might not yet have been reached).
The equation in the Parr model is: ") , where the values of
, where the values of  and
and  are obtained by fitting a regression model to project data. The derivation of the Parr model assumes that as project implementation progresses, new problems that need to be solved are discovered (e.g., features to be implemented), an existing problem can spawn at most two new subproblems, and the number of new problems discovered at any time is proportional to the number of remaining problems (cannot find an online version of “An alternative to the Rayleigh curve model for software development effort”).
are obtained by fitting a regression model to project data. The derivation of the Parr model assumes that as project implementation progresses, new problems that need to be solved are discovered (e.g., features to be implemented), an existing problem can spawn at most two new subproblems, and the number of new problems discovered at any time is proportional to the number of remaining problems (cannot find an online version of “An alternative to the Rayleigh curve model for software development effort”).
A connection can be made between the Bass and Parr models by equating the number of developers contributing with the number of problems to be solved, with contributors treated as independents or imitators. The opportunities for potential contributors are likely to increase as a project starts up and then, for some projects decrease (projects such as the Linux kernel just keep on going). The problem implemented by a developer could spawn more than two subproblems.
In practice most of the implementation work on an Open source project is done by a small percentage of developers, with some projects dieing after loosing a few core developers. There is also the issue of the same person contributing using multiple identities.
One method for checking how well a model predicts future measurements is to compare the equations fitted using all the monthly data and, say, the first 75% months. The extent to which both fitted equations agree provides an indication of the likely accuracy of currently unknown future values. The Das et al paper fits the Bass model to the monthly contributor data from 23 projects. The plot below shows the number of monthly developers for numpy (since the project started), along with two fitted Bass models, one for all the data and the other for the first 75% of the data (code+data):
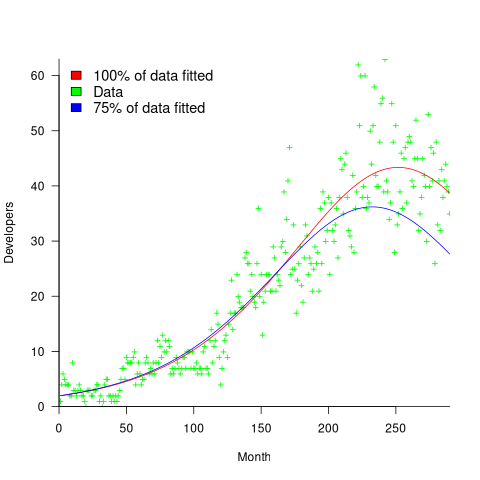
The example project used in the paper has a closer agreement between the two fitted equations, and some of the other projects have much less agreement. The Bass models assumes that monthly contributions are primarily driven by two factors. In practice there could be many other factors driving developer involvement in a project.
Predicting when a project is likely to stop growing is a notoriously difficult problem. Fitting a logistic equation to the growth in lines of code is another example of a model fitting the pattern present in the underlying equation (which flattens off).
It’s possible that weighting developer contribution by the amount of functionality (not lines of code) will produce a closer agreement between theory and practice.
The Putnam project staffing model predates the Parr mode, and later research found that the Putnam model was also a poor predictor of project durations. Both the Parr and Putnam equations can be derived using hazard analysis.
Applying the Bass multi-product generation model to software evolution is now on my to-do list, e.g., use of PHP versions.
Software_Engineering_Practices = Morals+Theology
Including the word science in the term used to describe a research field creates an aura of scientific enterprise. Universities name departments “Computer Science” and creationist have adopted the term “Creation Science”. The word engineering is used when an aura with a practical hue is desired, e.g., “Software Engineering” and “Consciousness Engineering”.
Science and engineering theories/models are founded on the principle of reproducibility. A theory/model achieves its power by making predictions that are close enough to reality.
Computing/software is an amalgam of many fields, some of which do tick the boxes associated with science and/or engineering practices, e.g., the study of algorithms or designing hardware. Activities whose output is primarily derived from human activity (e.g., writing software) are bedevilled by the large performance variability of people. Software engineering is unlikely to ever become a real engineering discipline.
If the activity known as software engineering is not engineering, then what is it?
To me, software engineering appears to be a form of moral theology. My use of this term is derived from the 1988 paper Social Science as Moral Theology by Neil Postman.
Summarising the term moral theology via its two components, i.e., morality+theology, we have:
Morality is a system of rules that enable people to live and work together for mutual benefit. Social groups operate better when its members cooperate with each other based on established moral rules. A group operating with endemic within group lying and cheating is unlikely to survive for very long. People cannot always act selfishly, some level of altruism towards group members is needed to enable a group to flourish.
Development teams will perform better when its members cooperate with each other, as opposed to ignoring or mistreating each other. Failure to successfully work together increases the likelihood that the project the team are working on will failure; however, it is not life or death for those involved.
The requirements of group living, which are similar everywhere, produced similar moral systems around the world.
The requirements of team software development are similar everywhere, and there does appear to be a lot of similarity across recommended practices for team interaction (although I have not studied this is detail and don’t have much data).
Theology is the study of religious beliefs and practices, some of which do not include a god, e.g., Nontheism, Humanism, and Religious Naturalism.
Religious beliefs provide a means for people to make sense of their world, to infer reasons and intentions behind physical events. For instance, why it rains or doesn’t rain, or why there was plenty of animal prey during last week’s hunt but none today. These beliefs also fulfil various psychological and emotional wants or needs. The questions may have been similar in different places, but the answers were essentially invented, and so different societies have ended up with different gods and theologies.
Different religions do have some features in common, such as:
- Creation myths. In software companies, employees tell stories about the beliefs that caused the founders to create the company, and users of a programming language tell stories about the beliefs and aims of the language designer and the early travails of the language implementation.
- Imagined futures, e.g., we all go to heaven/hell: An imagined future of software developers is that source code is likely to be read by other developers, and code lives a long time. In reality, most source code has a brief and lonely existence.
A moral rule sometimes migrates to become a religious rule, which can slow the evolution of the rule when circumstances change. For instance, dietary restrictions (e.g., must not eat pork) are an adaptation to living in some environments.
In software development, the morals of an Agile methodology perfectly fitted the needs of the early Internet, where existing ways of doing things did not exist and nobody knew what customers really wanted. The signatories of the Agile manifesto now have their opinions treated like those of a prophet (these 17 prophets are now preaching various creeds).
Agile is not always the best methodology to use, with a Waterfall methodology being a better match for some environments.
Now that the Agile methodology has migrated to become a ‘religious’ dogma, the reaction to suggestions that an alternative methodology be used are often what one would expect to questioning a religious belief.
For me this is an evolving idea.
Software engineering research problems having worthwhile benefits
Which software engineering research problems are likely to yield good-enough solutions that provide worthwhile benefits to professional software developers?
I can think of two (hopefully there are more):
- what is the lifecycle of software? For instance, the expected time-span of the active use of its various components, and the evolution of its dependency ecosystem,
- a model of the main processes involved in a software development project.
Solving problems requires data, and I think it is practical to collect the data needed to solve these two problems; here is some: application lifetime data, and detailed project data (a lot more is needed).
Once a good-enough solution is available, its practical application needs to provide a worthwhile benefit to the customer (when I was in the optimizing compiler business, I found that many customers were not interested in more compact code unless the executable was at least a 10% smaller; this was the era of computer memory often measured in kilobytes).
Investment decisions require information about what is likely to happen in the future, and an understanding of common software lifecycles is needed. The fact that most source code has a brief existence (a few years) and is rarely modified by somebody other than the original author, has obvious implications for investment decisions intended to reduce future maintenance costs.
Running a software development project requires an understanding of the processes involved. This knowledge is currently acquired by working on projects managed by people who have successfully done it before. A good-enough model is not going to replace the need for previous experience, some amount of experience is always going to be needed, but it will provide an effective way of understanding what is going on. There are probably lots of different good-enough ways of running a project, and I’m not expecting there to be a one-true-way of optimally running a project.
Perhaps the defining characteristic of the solution to both of these problems is lots of replication data.
Applications are developed in many ecosystems, and there is likely to be variations between the lifecycles that occur in different ecosystems. Researchers tend to focus on Github because it is easily accessible, which is no good when replications from many ecosystems are needed (an analysis of Github source lifetime has been done).
Projects come in various shapes and sizes, and a good-enough model needs to handle all the combinations that regularly occur. Project level data is not really present on Github, so researchers need to get out from behind their computers and visit real companies.
Given the payback time-frame for software engineering research, there are problems which are not cost-effective to attempt to answer. Suggestions for other software engineering problems likely to be worthwhile trying to solve welcome.
Research software code is likely to remain a tangled mess
Research software (i.e., software written to support research in engineering or the sciences) is usually a tangled mess of spaghetti code that only the author knows how to use. Very occasionally I encounter well organized research software that can be used without having an email conversation with the author (who has invariably spent years iterating through many versions).
Spaghetti code is not unique to academia, there is plenty to be found in industry.
Structural differences between academia and industry make it likely that research software will always be a tangled mess, only usable by the person who wrote it. These structural differences include:
- writing software is a low status academic activity; it is a low status activity in some companies, but those involved don’t commonly have other higher status tasks available to work on. Why would a researcher want to invest in becoming proficient in a low status activity? Why would the principal investigator spend lots of their grant money hiring a proficient developer to work on a low status activity?
I think the lack of status is rooted in researchers’ lack of appreciation of the effort and skill needed to become a proficient developer of software. Software differs from that other essential tool, mathematics, in that most researchers have spent many years studying mathematics and understand that effort/skill is needed to be able to use it.
Academic performance is often measured using citations, and there is a growing move towards citing software,
- many of those writing software know very little about how to do it, and don’t have daily contact with people who do. Recent graduates are the pool from which many new researchers are drawn. People in industry are intimately familiar with the software development skills of recent graduates, i.e., the majority are essentially beginners; most developers in industry were once recent graduates, and the stream of new employees reminds them of the skill level of such people. Academics see a constant stream of people new to software development, this group forms the norm they have to work within, and many don’t appreciate the skill gulf that exists between a recent graduate and an experienced software developer,
- paid a lot less. The handful of very competent software developers I know working in engineering/scientific research are doing it for their love of the engineering/scientific field in which they are active. Take this love away, and they will find that not only does industry pay better, but it also provides lots of interesting projects for them to work on (academics often have the idea that all work in industry is dull).
I have met people who have taken jobs writing research software to learn about software development, to make themselves more employable outside academia.
Does it matter that the source code of research software is a tangled mess?
The author of a published paper is supposed to provide enough information to enable their work to be reproduced. It is very unlikely that I would be able to reproduce the results in a chemistry or genetics paper, because I don’t know enough about the subject, i.e., I am not skilled in the art. Given a tangled mess of source code, I think I could reproduce the results in the associated paper (assuming the author was shipping the code associated with the paper; I have encountered cases where this was not true). If the code failed to build correctly, I could figure out (eventually) what needed to be fixed. I think people have an unrealistic expectation that research code should just build out of the box. It takes a lot of work by a skilled person to create to build portable software that just builds.
Is it really cost-effective to insist on even a medium-degree of buildability for research software?
I suspect that the lifetime of source code used in research is just as short and lonely as it is in other domains. One study of 214 packages associated with papers published between 2001-2015 found that 73% had not been updated since publication.
I would argue that a more useful investment would be in testing that the software behaves as expected. Many researchers I have spoken to have not appreciated the importance of testing. A common misconception is that because the mathematics is correct, the software must be correct (completely ignoring the possibility of silly coding mistakes, which everybody makes). Commercial software has the benefit of user feedback, for detecting some incorrect failures. Research software may only ever have one user.
Research software engineer is the fancy title now being applied to people who write the software used in research. Originally this struck me as an example of what companies do when they cannot pay people more, they give them a fancy title. Recently the Society of Research Software Engineering was setup. This society could certainly help with training, but I don’t see it making much difference with regard status and salary.
Update
This post generated a lot of discussion on the research software mailing list, and Peter Schmidt invited me to do a podcast with him. Here it is.
Researching programming languages
What useful things might be learned from evidence-based research into programming languages?
A common answer is researching how to design a programming language having a collection of desirable characteristics; with desirable characteristics including one or more of: supporting the creation of reliable, maintainable, readable, code, or being easy to learn, or easy to understand, etc.
Building a theory of, say, code readability is an iterative process. A theory is proposed, experiments are run, results are analysed; rinse and repeat until a theory having a good enough match to human behavior is found. One iteration will take many years: once a theory is proposed, an implementation has to be built, developers have to learn it, and spend lots of time using it to enable longer term readability data to be obtained. This iterative process is likely to take many decades.
Running one iteration will require 100+ developers using the language over several years. Why 100+? Lots of subjects are needed to obtain statistically meaningful results, people differ in their characteristics and previous software experience, and some will drop out of the experiment. Just one iteration is going to cost a lot of money.
If researchers do succeed in being funded and eventually discovering some good enough theories, will there be a mass migration of developers to using languages based on the results of the research findings? The huge investment in existing languages (both in terms of existing code and developer know-how) means that to stand any chance of being widely adopted these new language(s) are going to have to deliver a substantial benefit.
I don’t see a high cost multi-decade research project being funded, and based on the performance improvements seen in studies of programming constructs I don’t see the benefits being that great (benefits in use of particular constructs may be large, but I don’t see an overall factor of two improvement).
I think that creating new programming languages will continue to be a popular activity (it is vanity research), and I’m sure that the creators of these languages will continue to claim that their language has some collection of desirable characteristics without any evidence.
What programming research might be useful and practical to do?
One potentially practical and useful question is the lifecycle of programming languages. Where the components of the lifecycle includes developers who can code in the language, source code written in the language, and companies dependent on programs written in the language (who are therefore interested in hiring people fluent in the language).
Many languages come and go without many people noticing, a few become popular for a few years, and a handful continue to be widely used over decades. What are the stages of life for a programming language, what factors have the largest influence on how widely a language is used, and for how long it continues to be used?
Sixty years worth of data is waiting to be collected and collated; enough to keep researchers busy for many years.
The uses of a lifecycle model, that I can thinkk of, all involve the future of a language, e.g., how much of a future does it have and how might it be extended.
Some recent work looking at the rate of adoption of new language features includes: On the adoption, usage and evolution of Kotlin Features on Android development, and Understanding the use of lambda expressions in Java; also see section 7.3.1 of Evidence-based software engineering.
Recent Comments