Archive
Dimensional analysis of the Halstead metrics
One of the driving forces behind the Halstead complexity metrics was physics envy; the early reports by Halstead use the terms software physics and software science.
One very simple, and effective technique used by scientists and engineers to check whether an equation makes sense, is dimensional analysis. The basic idea is that when performing an operation between two variables, their measurement units must be consistent; for instance, two lengths can be added, but a length and a time cannot be added (a length can be divided by time, returning distance traveled per unit time, i.e., velocity).
Let’s run a dimensional analysis check on the Halstead equations.
The input variables to the Halstead metrics are:  , the number of distinct operators,
, the number of distinct operators,  , the number of distinct operands,
, the number of distinct operands,  , the total number of operators, and
, the total number of operators, and  , the total number of operands. These quantities can be interpreted as units of measurement in tokens.
, the total number of operands. These quantities can be interpreted as units of measurement in tokens.
The formula are:
- Program length:

There is a consistent interpretation of this equation: operators and operands are both kinds of tokens, and number of tokens can be interpreted as a length. - Calculated program length:

There is a consistent interpretation of this equation: the operand of a logarithm has to be dimensionless, and the convention is to treat the operand as a ratio (if no denominator is specified, the value 1 having the same dimensions as the numerator is taken, giving a dimensionless result), the value returned is dimensionless, which can be multiplied by a variable having any kind of dimension; so again two (token) lengths are being added. - Volume:

A volume has units of (i.e., it is created by multiplying three lengths). There is only one length in this equation; the equation is misnamed, it is a length.
(i.e., it is created by multiplying three lengths). There is only one length in this equation; the equation is misnamed, it is a length. - Difficulty:

Here the dimensions of and cancel, leaving the dimensions of (a length); now Halstead is interpreting length as a difficulty unit (whatever that might be). - Effort:

This equation multiplies two variables, both having a length dimension; the result should be interpreted as an area. In physics work is force times distance, and power is work per unit time; the term effort is not defined.
Halstead is claiming that a single dimension, program length, contains so much unique information that it can be used as a measure of a variety of disparate quantities.
Halstead’s colleagues at Purdue were rather damming in their analysis of these metrics. Their report Software Science Revisited: A Critical Analysis of the Theory and Its Empirical Support points out the lack of any theoretical foundation for some of the equations, that the analysis of the data was weak and that a more thorough analysis suggests theory and data don’t agree.
I pointed out in an earlier post, that people use Halstead’s metrics because everybody else does. This post is unlikely to change existing herd behavior, but it gives me another page to point people at, when people ask why I laugh at their use of these metrics.
C2X and undefined behavior
The ISO C Standard is currently being revised by WG14, to create C2X.
There is a rather nebulous clustering of people who want to stop compilers using undefined behaviors to generate what these people (and probably most other developers) consider to be very surprising code. For instance, always printing p is truep is false, when executing the code: bool p; if ( p ) printf("p is true"); if ( !p ) printf("p is false"); (possible because p is uninitialized, and accessing an uninitialized value is undefined behavior).
This sounds like a good thing; nobody wants compilers generating surprising code.
All the proposals I have seen, so far, involve doing away with constructs that can produce undefined behavior. Again, this sounds like a good thing; nobody likes undefined behaviors.
The problem is, there is a reason for labeling certain constructs as producing undefined behavior; the behavior is who-knows-what.
Now the C Standard could specify the who-knows-what behavior; for instance, it could specify that the result of dividing by zero is 42. Standard’s conforming compilers would then have to generate code to check whether the denominator was zero, and return 42 for this case (until Intel, ARM and other processor vendors ‘updated’ the behavior of their divide instructions). Way-back-when a design decision was made, the behavior of divide by zero is undefined, not 42 or any other value; this was a design decision, code efficiency and compactness was considered to be more important.
I have not seen anybody arguing that the behavior of divide by zero should be specified. But I have seen people arguing that once C’s integer representation is specified as being twos-compliment (currently it can also be ones-compliment or signed-magnitude), then arithmetic overflow becomes defined. Wrong.
Twos-compliment is a specification of a representation, not a specification of behavior. What is the behavior when the result of adding two integers cannot be represented? The result might be to wrap (the behavior expected by many developers), to saturate at the maximum value (frequently needed in image and signal processing), to raise a signal (overflow is not usually supposed to happen), or something else.
WG14 could define the behavior, for when the result of an arithmetic operation is not representable in the number of bits available. Standard’s conforming compilers targeting processors whose arithmetic instructions did not behave as required would have to generate code, for any operation that could overflow, to do what was necessary. The embedded market are heavy users of C; in this market memory is limited, and processor performance is never fast enough, the overhead of supporting a defined behavior could just be too high (a more attractive solution is to code review, to make sure the undefined behavior cannot occur).
Is there another way of addressing the issue of compiler writers’ use/misuse of undefined behavior? Yes, offer them money. Compiler writing is a business, at least at the level at which gcc and llvm operate. If people really are keen to influence the code generated by gcc and llvm, money is the solution. Wot, no money? Then stop complaining.
OSI licenses: number and survival
There is a lot of source code available which is said to be open source. One definition of open source is software that has an associated open source license. Along with promoting open source, the Open Source Initiative (OSI) has a rigorous review process for open source licenses (so they say, I have no expertise in this area), and have become the major licensing brand in this area.
Analyzing the use of licenses in source files and packages has become a niche research topic. The majority of source files don’t contain any license information, and, depending on language, many packages don’t include a license either (see Understanding the Usage, Impact, and Adoption of Non-OSI Approved Licenses). There is some evolution in license usage, i.e., changes of license terms.
I knew that a fair-few open source licenses had been created, but how many, and how long have they been in use?
I don’t know of any other work in this area, and the fastest way to get lots of information on open source licenses was to scrape the brand leader’s licensing page, using the Wayback Machine to obtain historical data. Starting in mid-2007, the OSI licensing page kept to a fixed format, making automatic extraction possible (via an awk script); there were few pages archived for 2000, 2001, and 2002, and no pages available for 2003, 2004, or 2005 (if you have any OSI license lists for these years, please send me a copy).
What do I now know?
Over the years OSI have listed 110107 different open source licenses, and currently lists 81. The actual number of license names listed, since 2000, is 205; the ‘extra’ licenses are the result of naming differences, such as the use of dashes, inclusion of a bracketed acronym (or not), license vs License, etc.
Below is the Kaplan-Meier survival curve (with 95% confidence intervals) of licenses listed on the OSI licensing page (code+data):
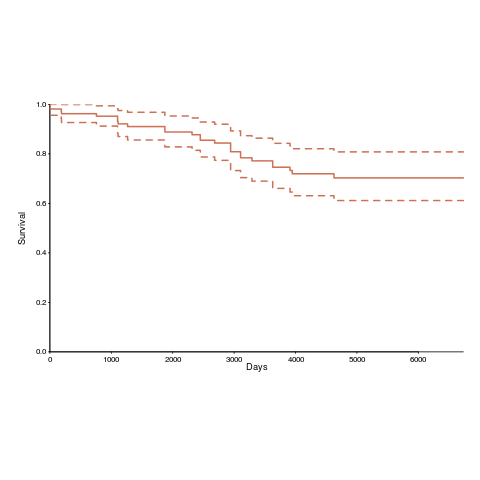
How many license proposals have been submitted for review, but not been approved by OSI?
Patrick Masson, from the OSI, kindly replied to my query on number of license submissions. OSI doesn’t maintain a count, and what counts as a submission might be difficult to determine (OSI recently changed the review process to give a definitive rejection; they have also started providing a monthly review status). If any reader is keen, there is an archive of mailing list discussions on license submissions; trawling these would make a good thesis project 🙂
The Algorithmic Accountability Act of 2019
The Algorithmic Accountability Act of 2019 has been introduced to the US congress for consideration.
The Act applies to “person, partnership, or corporation” with “greater than $50,000,000 … annual gross receipts”, or “possesses or controls personal information on more than— 1,000,000 consumers; or 1,000,000 consumer devices;”.
What does this Act have to say?
(1) AUTOMATED DECISION SYSTEM.—The term ‘‘automated decision system’’ means a computational process, including one derived from machine learning, statistics, or other data processing or artificial intelligence techniques, that makes a decision or facilitates human decision making, that impacts consumers.
That is all encompassing.
The following is what the Act is really all about, i.e., impact assessment.
(2) AUTOMATED DECISION SYSTEM IMPACT ASSESSMENT.—The term ‘‘automated decision system impact assessment’’ means a study evaluating an automated decision system and the automated decision system’s development process, including the design and training data of the automated decision system, for impacts on accuracy, fairness, bias, discrimination, privacy, and security that includes, at a minimum—
I think there is a typo in the following: “training, data” -> “training data”
(A) a detailed description of the automated decision system, its design, its training, data, and its purpose;
How many words are there in a “detailed description of the automated decision system”, and I’m guessing the wording has to be something a consumer might be expected to understand. It would take a book to describe most systems, but I suspect that a page or two is what the Act’s proposers have in mind.
(B) an assessment of the relative benefits and costs of the automated decision system in light of its purpose, taking into account relevant factors, including—
Whose “benefits and costs”? Is the Act requiring that companies do a cost benefit analysis of their own projects? What are the benefits to the customer, compared to a company not using such a computerized approach? The main one I can think of is that the customer gets offered a service that would probably be too expensive to offer if the analysis was done manually.
The potential costs to the customer are listed next:
(i) data minimization practices;
(ii) the duration for which personal information and the results of the automated decision system are stored;
(iii) what information about the automated decision system is available to consumers;
This act seems to be more about issues around data retention, privacy, and customers having the right to find out what data companies have about them
(iv) the extent to which consumers have access to the results of the automated decision system and may correct or object to its results; and
(v) the recipients of the results of the automated decision system;
What might the results be? Yes/No, on a load/job application decision, product recommendations are a few.
Some more potential costs to the customer:
(C) an assessment of the risks posed by the automated decision system to the privacy or security of personal information of consumers and the risks that the automated decision system may result in or contribute to inaccurate, unfair, biased, or discriminatory decisions impacting consumers; and
What is an “unfair” or “biased” decision? Machine learning finds patterns in data; when is a pattern in data considered to be unfair or biased?
In the UK, the sex discrimination act has resulted in car insurance companies not being able to offer women cheaper insurance than men (because women have less costly accidents). So the application form does not contain a gender question. But the applicants first name often provides a big clue, as to their gender. So a similar Act in the UK would require that computer-based insurance quote generation systems did not make use of information on the applicant’s first name. There is other, less reliable, information that could be used to estimate gender, e.g., height, plays sport, etc.
Lots of very hard questions to be answered here.
MI5 agent caught selling Huawei exploits on Russian hacker forums
An MI5 agent has been caught selling exploits in Huawei products, on an underground Russian hacker forum (a paper analyzing the operation of these forums; perhaps the researchers were hired as advisors). How did this news become public? A reporter heard Mr Wang Kit, a senior Huawei manager, complaining about not receiving a percentage of the exploit sale, to add to his quarterly sales report. A fair point, given that Huawei are funding a UK centre to search for vulnerabilities.
The ostensive purpose of the Huawei cyber security evaluation centre (funded by Huawei, but run by GCHQ; the UK’s signals intelligence agency), is to allay UK fears that Huawei have added back-doors to their products, that enable the Chinese government to listen in on customer communications.
If this cyber centre finds a vulnerability in a Huawei product, they may or may not tell Huawei about it. Obviously, if it’s an exploitable vulnerability, and they think that Huawei don’t know about it, they could pass the exploit along to the relevant UK government department.
If the centre decides to tell Huawei about the vulnerability, there are two good reasons to first try selling it, to shady characters of interest to the security services:
- having an exploit to sell gives the person selling it credibility (of the shady technical kind), in ecosystems the security services are trying to penetrate,
- it increases Huawei’s perception of the quality of the centre’s work; by increasing the number of exploits found by the centre, before they appear in the wild (the centre has to be careful not to sell too many exploits; assuming they manage to find more than a few). Being seen in the wild adds credibility to claims the centre makes about the importance of an exploit it discovered.
How might the centre go about calculating whether to hang onto an exploit, for UK government use, or to reveal it?
The centre’s staff could organized as two independent groups; if the same exploit is found by both groups, it is more likely to be found by other hackers, than an exploit found by just one group.
Perhaps GCHQ knows of other groups looking for Huawei exploits (e.g., the NSA in the US). Sharing information about exploits found, provides the information needed to more accurately estimate the likelihood of others discovering known exploits.
How might Huawei estimate the number of exploits MI5 are ‘selling’, before officially reporting them? Huawei probably have enough information to make a good estimate of the total number of exploits likely to exist in their products, but they also need to know the likelihood of discovering an exploit, per man-hour of effort. If Huawei have an internal team searching for exploits, they might have the data needed to estimate exploit discovery rate.
Another approach would be for Huawei to add a few exploits to the code, and then wait to see if they are used by GCHQ. In fact, if GCHQ accuse Huawei of adding a back-door to enable the Chinese government to spy on people, Huawei could claim that the code was added to check whether GCHQ was faithfully reporting all the exploits it found, and not keeping some for its own use.
Recent Comments