Archive
The first commercially available (claimed) verified compiler
Yesterday, I read a paper containing a new claim by some of those involved with CompCert (yes, they of soap powder advertising fame): “CompCert is the first commercially available optimizing compiler that is formally verified, using machine assisted mathematical proofs, to be exempt from miscompilation”.
First commercially available; really? Surely there are earlier claims of verified compilers being commercial availability. Note, I’m saying claims; bits of the CompCert compiler have involved mathematical proofs (i.e., code generation), so I’m considering earlier claims having at least the level of intellectual honesty used in some CompCert papers (a very low bar).
What does commercially available mean? The CompCert system is open source (but is not free software), so I guess it’s commercially available via free downloading licensing from AbsInt (the paper does not define the term).
Computational Logic, Inc is the name that springs to mind, when thinking of commercial and formal verification. They were active from 1983 to 1997, and published some very interesting technical reports about their work (sadly there are gaps in the archive). One project was A Mechanically Verified Code Generator (in 1989) and their Gypsy system (a Pascal-like language+IDE) provided an environment for doing proofs of programs (I cannot find any reports online). Piton was a high-level assembler and there was a mechanically verified implementation (in 1988).
There is the Danish work on the formal specification of the code generators for their Ada compiler (while there was a formal specification of the Ada semantics in VDM, code generators tend to be much simpler beasts, i.e., a lot less work is needed in formal verification). The paper I have is: “Retargeting and rehosting the DDC Ada compiler system: A case study – the Honeywell DPS 6” by Clemmensen, from 1986 (cannot find an online copy). This Ada compiler was used by various hardware manufacturers, so it was definitely commercially available for (lots of) money.
Are then there any earlier verified compilers with a commercial connection? There is A PRACTICAL FORMAL SEMANTIC DEFINITION AND VERIFICATION SYSTEM FOR TYPED LISP, from 1976, which has “… has proved a number of interesting, non-trivial theorems including the total correctness of an algorithm which sorts by successive merging, the total correctness of the McCarthy-Painter compiler for expressions, …” (which sounds like a code generator, or part of one, to me).
Francis Morris’s thesis, from 1972, proves the correctness of compilers for three languages (each language contained a single feature) and discusses how these features may be combined into a more “realistic” language. No mention of commercial availability, but I cannot see the demand being that great.
The definition of PL/1 was written in VDM, a formal language. PL/1 is a huge language and there were lots of subsets. Were there any claims of formal verification of a subset compiler for PL/1? I have had little contact with the PL/1 world, so am not in a good position to know. Anybody?
Over to you dear reader. Are there any earlier claims of verified compilers and commercial availability?
Publishing information on project progress: will it impact delivery?
Numbers for delivery date and cost estimates, for a software project, depend on who you ask (the same is probably true for other kinds of projects). The people actually doing the work are likely to have the most accurate information, but their estimates can still be wildly optimistic. The managers of the people doing the work have to plan (i.e., make worst/best case estimates) and deal with people outside the team (i.e., sell the project to those paying for it); planning requires knowledge of where things are and where they need to be, while selling requires being flexible with numbers.
A few weeks ago I was at a hackathon organized by the people behind the Project Data and Analytics meetup. The organizers (Martin Paver & co.) had obtained some very interesting project related data sets. I worked on the Australian ICT dashboard data.
The Australian ICT dashboard data was courtesy of the Queensland state government, which has a publicly available dashboard listing digital project expenditure; the Victorian state government also has a dashboard listing ICT expenditure. James Smith has been collecting this data on a monthly basis.
What information might meaningfully be extracted from monthly estimates of project delivery dates and costs?
If you were running one of these projects, and had to provide monthly figures, what strategy would you use to select the numbers? Obviously keep quiet about internal changes for as long as possible (today’s reduction can be used to offset a later increase, or vice versa). If the client requests changes which impact date/cost, then obviously update the numbers immediately; the answer to the question about why the numbers changed is that, “we are responding to client requests” (i.e., we would otherwise still be on track to meet the original end-points).
What is the intended purpose of publishing this information? Is it simply a case of the public getting fed up with overruns, with publishing monthly numbers is seen as a solution?
What impact could monthly publication have? Will clients think twice before requesting an enhancement, fearing public push back? Will companies doing the work make more reliable estimates, or work harder?
Project delivery dates/costs change because new functionality/work-to-do is discovered, because the appropriate staff could not be hired and other assorted unknown knowns and unknowns.
Who is looking at this data (apart from half a dozen people at a hackathon on the other side of the world)?
Data on specific projects can only be interpreted in the context of that project. There is some interesting research to be done on the impact of public availability on client and vendor reporting behavior.
Will publication have an impact on performance? One way to get some idea is to run an A/B experiment. Some projects have their data made public, others don’t. Wait a few years, and compare project performance for the two publication regimes.
Statistical techniques not needed to analyze software engineering data
One of the methods I used to try to work out what statistical techniques were likely to be useful to software developers, was to try to apply techniques that were useful in other areas. Of course, applying techniques requires the appropriate data to apply them to.
Extreme value statistics are used to spot patterns in rare events, e.g., frequency of rivers over spilling their banks and causing extensive flooding. I have tried and failed to find any data where Extreme value theory might be applicable. There probably is some such data, somewhere.
The fact that I have spent a lot of time looking for data and failed to find particular kinds of data, suggests that occurrences are rare. If data needing a particular kind of analysis technique is rare, there is no point including a discussion of the technique in a book aimed at providing general coverage of material.
I have spent some time looking for data drawn from a zero-inflated Poisson distribution. Readers are unlikely to have ever heard of this and might well ask why I would be interested in such an obscure distribution. Well, zero-truncated Poisson distributions crop up regularly (the Poisson distribution applies to count data that starts at zero, when count data starts at one the zeroes are said to be truncated and the Poisson distribution has to be offset to adjust for this). There is a certain symmetry to zero-truncated/inflated (although the mathematics involved is completely different), plus there is probably a sunk cost effect (i.e., I have spent time learning about them, I am going to find the data).
I spotted a plot in a paper investigating record data structure usage in Racket, that looked like it might be well fitted by a zero-inflated Poisson distribution. Tobias Pape kindly sent me the data (number of record data structures having a given size), which I then failed miserably to fit to any kind of Poisson related distribution; see plot below; data points along red line through the plus symbols (code+data):
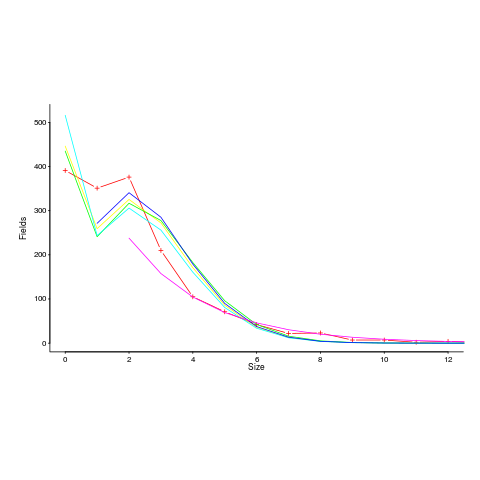
I can only imagine what the authors thought of my reason for wanting the data (I made data requests to a few other researchers for similar reasons; and again I failed to fit the desired distribution).
I had expected to make more use of time series analysis; but, it has just not been that applicable.
Machine learning is useful for publishing papers, but understanding what is going on is the subject of my book, not building black boxes to make predictions.
It is possible that researchers are not publishing work relating to data that requires statistical techniques I have not used, because they don’t know how to analyze the data or the data is too hard to collect. Inability to use the correct techniques to analyze data is rarely a reason for not publishing a paper. Data being too hard to collect is very believable, as-is the data rarely occurring in software engineering related work.
There are statistical tests I have intentionally ignored, the Mann–Whitney U test (aka, the Wilcoxon rank-sum test) and the t-test probably being the most well-known. These tests became obsolete once computers became generally available. If you are ever stuck on a desert island without a computer, these are the statistical tests you will have to use.
Students vs. professionals in software engineering experiments
Experiments are an essential component of any engineering discipline. When the experiments involve people, as subjects in the experiment, it is crucial that the subjects are representative of the population of interest.
Academic researchers have easy access to students, but find it difficult to recruit professional developers, as subjects.
If the intent is to generalize the results of an experiment to the population of students, then using student as subjects sounds reasonable.
If the intent is to generalize the results of an experiment to the population of professional software developers, then using student as subjects is questionable.
What it is about students that makes them likely to be very poor subjects, to use in experiments designed to learn about the behavior and performance of professional software developers?
The difference between students and professionals is practice and experience. Professionals have spent many thousands of hours writing code, attending meetings discussing the development of software; they have many more experiences of the activities that occur during software development.
The hours of practice reading and writing code gives professional developers a fluency that enables them to concentrate on the problem being solved, not on technical coding details. Yes, there are students who have this level of fluency, but most have not spent the many hours of practice needed to achieve it.
Experience gives professional developers insight into what is unlikely to work and what may work. Without experience students have no way of evaluating the first idea that pops into their head, or a situation presented to them in an experiment.
People working in industry are well aware of the difference between students and professional developers. Every year a fresh batch of graduates start work in industry. The difference between a new graduate and one with a few years experience is apparent for all to see. And no, Masters and PhD students are often not much better and in some cases worse (their prolonged sojourn in academia means that have had more opportunity to pick up impractical habits).
It’s no wonder that people in industry laugh when they hear about the results from experiments based on student subjects.
Just because somebody has “software development” in their job title does not automatically make they an appropriate subject for an experiment targeting professional developers. There are plenty of managers with people skills and minimal technical skills (sub-student level in some cases)
In the software related experiments I have run, subjects were asked how many lines of code they had read/written. The low values started at 25,000 lines. The intent was for the results of the experiments to be generalized to the population of people who regularly wrote code.
Psychology journals are filled with experimental papers that used students as subjects. The intent is to generalize the results to the general population. It has been argued that students are not representative of the general population in that they have spent more time reading, writing and reasoning than most people. These subjects have been labeled as WEIRD.
I spend a lot of time reading software engineering papers. If a paper involves human subjects, the first thing I do is find out whether the subjects were students (usual) or professional developers (not common). Authors sometimes put effort into dressing up their student subjects as having professional experience (perhaps some of them have spent a year or two in industry, but talking to the authors often reveals that the professional experience was tutoring other students), others say almost nothing about the identity of the subjects. Papers describing experiments using professional developers, trumpet this fact in the abstract and throughout the paper.
I usually delete any paper using student subjects, some of the better ones are kept in a subdirectory called students.
Software engineering researchers are currently going through another bout of hand wringing over the use of student subjects. One paper makes the point that a student based experiment is a good way of validating an experiment that will later involve professional developers. This is a good point, but ignored the problem that researchers rarely move on to using professional subjects; many researchers only ever intend to run student-based experiments. Also, they publish the results from the student based experiment, which are at best misleading (but academics get credit for publishing papers, not for the content of the papers).
Researchers are complaining that reviews are rejecting their papers on student based experiments. I’m pleased to hear that reviewers are rejecting these papers.
The best or most compiler writers born in February?
Some years ago, now, I ran a poll asking about readers’ month of birth and whether they had worked on a compiler. One hypothesis was that the best compiler writers are born in February, an alternative hypothesis is that most compiler writers are born in February.
I have finally gotten around to analyzing the data and below is the Rose diagram for the 82, out of 132 responses, compiler writers (the green arrow shows the direction and magnitude of the mean; code+data):
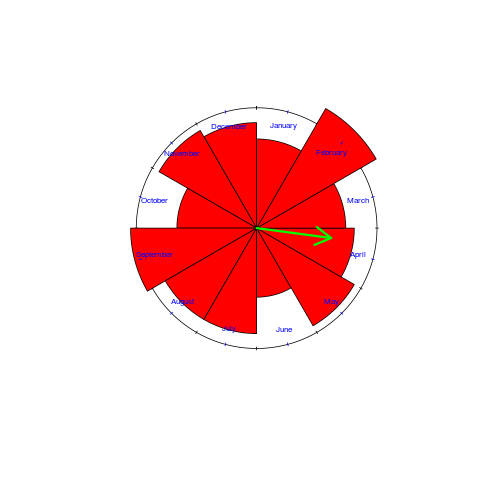
At 15% of responses, February is the most common month for compiler writer birthdays. The percentage increases to 16%, if weighted by the number of births in each month.
So there you have it, the hypothesis that most compiler writers are born in February is rejected, leaving the hypothesis that the best compiler writers are born in February. How could this not be true 🙂
What about the birth month of readers who are not compiler writers? While the mean direction and length are more-or-less the same, for the two populations, the Rose diagram shows that the shape of the distributions are different:
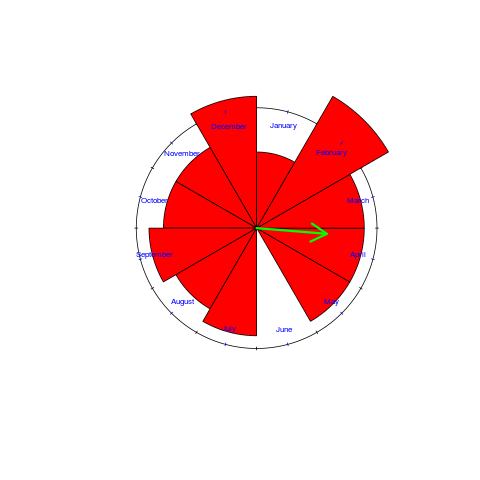
Facebook’s Big Code Summit
I was at Facebook’s first Big Code Summit on Monday and Tuesday (I say the first, because I hope there is another one next year).
The talks all involved machine learning (to be expected, given the Big Code in the event’s title). Normally I ignore papers on machine learning in software engineering, but understanding code is hard and we don’t know much about it. As I keep telling anyone who will listen, machine learning is the tool to use when you don’t know what you are doing (provided you have enough data).
People have been learning code patterns for some time now, suggesting applications in code completion in the IDE and finding suspicious API sequences (e.g., a missing call). This is one area where machine learning is a natural solution: nobody has the time to write down all the common patterns, for all the common languages, and APIs are constantly changing. It makes no sense to solve this problem manually.
So what was new and/or interesting?
We got new and very interesting in the first talk, when Eran Yahav presented his group’s work on cod2vec, the paper was interesting, but the demo had the wow factor.
I have not made up my mind about Michael Pradel‘s proposal for learning new coding rule checks. These rules are often created by people, but people with the necessary skill are thin on the ground. Machine learning requires something to learn from, how could coding rules be created this way. Michael’s group is working on a system where developers create the positive and negative cases and a machine learner figures out rules from these examples. Would the creation of these positive/negative examples prove to be just as hard as writing rules? I was not convinced that such an approach was practical, but if somebody wants to try it out, why not.
I found Xinyun Chen‘s talk interesting, but then I’ve written lots of parsers, and automatically figuring out how to parse a language from examples will always get my attention. A few people in the audience thought that a better solution was typing in a grammar and parsing the ‘usual’ way. This approach assumes a grammar exists, can be strong-armed into a form that is practical to embed in a parser (requiring somebody skilled in the necessary black arts), to produce a system that will only process complete translation units (or whatever the language calls a unit of translation).
Adding a new scalar type to C
I think the time has arrived for a new scalar type in C, which for want of a better name I shall call the compendium type.
On today’s processors a compendium type behaves a lot like an integer type, except that nobody really wants to include it in the list of supported integer types, e.g., 128-bit scalars.
Why is a new scalar type needed? The Standard supports extended integer types, why not treat a scalar object that supports integer arithmetic as an integer type?
The C Standard says (section 6.2.5 Types):
“There are five standard signed integer types, designated as signed char, short int, int, long int, and long long int. (These and other types may be designated in several additional ways, as described in 6.7.2.) There may also be implementation-defined extended signed integer types.38) The standard and extended signed integer types are collectively called signed integer types.39)”
There is corresponding wording for unsigned integer types.
The standard header
“The typedef name intN_t designates a signed integer type with width N, no padding bits, and a two’s complement representation. Thus, int8_t denotes such a signed integer type with a width of exactly 8 bits.”
This all sounds very feasible, but there is a catch. The Standard defines a greatest-width integer type, section 7.20.1.5 Greatest-width integer types
“The following type designates a signed integer type capable of representing any value of any signed integer type:
intmax_t”
and various library functions have an argument type intmax_t (there is also an uintmax_t).
An ‘extra-large’ integer type is not something that can just sit there, in the list of available integer types, waiting to be used. Preprocessor arithmetic and a variety of library are based around the type intmax_t. An extra-large integer type would have a very visible impact on all developers, many of whom would want to ignore it.
GCC supports 128-bit integers, e.g., __int128. But some magic pixie dust is involved, this type has no connection with intmax_t.
What do developers do with these 128- and 256-bit scalar objects? Evaluating graphics algorithms, hashes and cryptographic calculations are obvious candidates; yes, perhaps even calculations involving integers that require this many bits. I have not seen any analysis of the uses of this kind of wide-integer-like type.
Extra-wide scalar types have a variety of uses and the term compendium type, captures this. Hardware support for such extra-width types is growing, with vendors looking to fill major niches.
Contorting existing wording, in the Standard, so accommodate these extra-wide types within the existing integer type machinery is a short term solution. Work on the upcoming revision of the C Standard should either do nothing and allow vendors to take the approach currently used by GCC, or create a new scalar type (perhaps using a TR).
The Nostradamus argument in software engineering research
The Nostradamus argument in software engineering research goes something like: This idea was proposed in a paper by XX, some years ago.
I regularly encounter the Nostradamus argument when discussing what people in industry are doing, with one or more academics. The same argument is probably made in other fields.
The rules of academic research pretty much guarantee that somebody, at sometime, has published a paper containing an idea related to something being discussed today.
The first researcher(s) to publish an idea gets the credit for the idea, and ‘uses it up’ the idea, that is somebody else cannot subsequently publish a paper claiming that idea (it does happen, either through plagiarism or slip-ups during review).
The job of researchers is to find new ideas (well, actually these days it is to quickly find an idea that will get published; researchers are on a publication treadmill). Sometimes a paper will explicitly point out the novel idea they are claiming (usually a sign of a very poor paper; the author(s) obviously don’t feel confident that the reader will see anything of merit). Researchers also talk of gaps in the literature, i.e., some topic where little, if anything, has been published.
Before starting work in an area, researchers are supposed to read all relevant prior publications; this can be an awful lot of work and take a lot of time. In practice people tend to read the papers in the top 10, or so, journals published in the last few years; maybe looking at more journals and going further back in time if the initial search fails to return many results. I have had many conversations with researchers about a paper, or thesis, they are just completing and been told “I’m just finishing off the literature search”, i.e., they are doing the background checks after completing their research, not before (yes, sometimes rather similar work has already been published and some quick footwork is needed).
So the work of prior researchers is venerated in theory, but rarely in practice.
Recent Comments