Archive
beta: Evidence-based Software Engineering – book
My book, Evidence-based software engineering: based on the publicly available data is now out on beta final release (pdf, and code+data). The plan is for a three-month review, with the final version available in the shops in time for Christmas (I plan to get a few hundred printed, and made available on Amazon).
The next few months will be spent responding to reader comments, and adding material from the remaining 20 odd datasets I have waiting to be analysed.
You can either email me with any comments, or add an issue to the book’s Github page.
While the content is very different from my original thoughts, 10-years ago, the original aim of discussing all the publicly available software engineering data has been carried through (in some cases more detailed data, in greater quantity, has supplanted earlier less detailed/smaller datasets).
The aim of only discussing a topic if public data is available, has been slightly bent in places (because I thought data would turn up, and it didn’t, or I wanted to connect two datasets, or I have not yet deleted what has been written).
The outcome of these two aims is that the flow of discussion is very disjoint, even disconnected. Another reason might be that I have not yet figured out how to connect the material in a sensible way. I’m the first person to go through this exercise, so I have no idea where it’s going.
The roughly 620+ datasets is three to four times larger than I thought was publicly available. More data is good news, but required more time to analyse and discuss.
Depending on the quantity of issues raised, updates of the beta release will happen.
As always, if you know of any interesting software engineering data, please tell me.
How should involved if-statement conditionals be structured?
Which of the following two if-statements do you think will be processed by readers in less time, and with fewer errors, when given the value of x, and asked to specify the output?
// First - sequence of subexpressions if (x > 0 && x < 10 || x > 20 && x < 30) print("a"); else print "b"); // Second - nested ifs if (x > 0 && x < 10) print("c"); else if (x > 20 && x < 30) print("d"); else print("e"); |
Ok, the behavior is not identical, in that the else if-arm produces different output than the preceding if-arm.
The paper Syntax, Predicates, Idioms — What Really Affects Code Complexity? analyses the results of an experiment that asked this question, including more deeply nested if-statements, the use of negation, and some for-statement questions (this post only considers the number of conditions/depth of nesting components). A total of 1,583 questions were answered by 220 professional developers, with 415 incorrect answers.
Based on the coefficients of regression models fitted to the results, subjects processed the nested form both faster and with fewer incorrect answers (code+data). As expected performance got slower, and more incorrect answers given, as the number of intervals in the if-condition increased (up to four in this experiment).
I think short-term memory is involved in this difference in performance; or at least I can concoct a theory that involves a capacity limited memory. Comprehending an expression (such as the conditional in an if-statement) requires maintaining information about the various components of the expression in working memory. When the first subexpression of x > 0 && x < 10 || x > 20 && x < 30 is false, and the subexpression after the || is processed, there is no now forget-what-went-before point like there is for the nested if-statements. I think that the single expression form is consuming more working memory than the nested form.
Does the result of this experiment (assuming it is replicated) mean that developers should be recommended to write sequences of conditions (e.g., the first if-statement example) about as:
if (x > 0 && x < 10) print("a"); else if (x > 20 && x < 30) print("a"); else print("b"); |
Duplicating code is not good, because both arms have to be kept in sync; ok, a function could be created, but this is extra effort. As other factors are taken into account, the costs of the nested form start to build up, is the benefit really worth the cost?
Answering this question is likely to need a lot of work, and it would be a more efficient use of resources to address questions about more commonly occurring conditions first.
A commonly occurring use is testing a single range; some of the ways of writing the range test include:
if (x > 0 && x < 10) ... if (0 < x && x < 10) ... if (10 > x && x > 0) ... if (x > 0 && 10 > x) ... |
Does one way of testing the range require less effort for readers to comprehend, and be more likely to be interpreted correctly?
There have been some experiments showing that people are more likely to give correct answers to questions involving information expressed as linear syllogisms, if the extremes are at the start/end of the sequence, such as in the following:
A is better than B
B is better than C |
and not the following (which got the lowest percentage of correct answers):
B is better than C
B is worse than A |
Your author ran an experiment to find out whether developers were more likely to give correct answers for particular forms of range tests in if-conditions.
Out of a total of 844 answers, 40 were answered incorrectly (roughly one per subject; it was a paper and pencil experiment, so no timings). It's good to see that the subjects were so competent, but with so few mistakes made the error bars are very wide, i.e., too few mistakes were made to be able to say that one representation was less mistake-prone than another.
I hope this post has got other researchers interested in understanding developer performance, when processing if-statements, and that they will be running more experiments help shed light on the processes involved.
An experiment involving matching regular expressions
Recommendations for/against particular programming constructs have one thing in common: there is no evidence backing up any of the recommendations. Running experiments to measure the impact of particular language features on developer performance is not something that researchers do (there have been a handful of experiments looking at the impact of strong typing on developer performance; the effect measured was tiny).
In February I discovered two groups researching regular expressions. In the first post on duplicate regexs, I promised to say something about the second group. This post discusses an experiment comparing developer comprehension of various regular expressions; the paper is: Exploring Regular Expression Comprehension.
The experiment involved 180 workers on Mechanical Turk (to be accepted, workers had to correctly answer four or five questions about regular expressions). Workers/subjects performed two different tasks, matching and composition.
- In the matching task workers saw a regex and a list of five strings, and had to specify whether the regex matched (or not) each string (there was also an unsure response).
- In the composition task workers saw a regular expression, and had to create a string matched by this regex. Each worker saw 10 different regexs, which were randomly drawn from a set of 60 regexs (which had been created to be representative of various regex characteristics). I have not analysed this data yet.
What were the results?
For the matching task: given each of the pairs of regexs below, which one (of each pair) would you say workers were most likely to get correct?
R1 R2 1. tri[a-f]3 tri[abcdef]3 2. no[w-z]5 no[wxyz]5 3. no[w-z]5 no(w|x|y|z)5 4. [ˆ0-9] [\D] |
The percentages correct for (1) were essentially the same, at 94.0 and 93.2 respectively. The percentages for (2) were 93.3 and 87.2, which is odd given that the regex is essentially the same as (1). Is this amount of variability in subject response to be expected? Is the difference caused by letters being much less common in text, so people have had less practice using them (sounds a bit far-fetched, but its all I could think of). The percentages for (3) are virtually identical, at 93.3 and 93.7.
The percentages for (4) were 58 and 73.3, which surprised me. But then I have been using regexs since before \D support was generally available. The MTurk generation have it easy not having to use the ‘hard stuff’ 😉
See Table III in the paper for more results.
This matching data might be analysed using Item Response theory, which can take into account differences in question difficulty and worker/subject ability. The plot below looks complicated, but only because there are so many lines. Each numbered colored line is a different regex, worker ability is on the x-axis (greater ability on the right), and the y-axis is the probability of giving a correct answer (code+data; thanks to Peipei Wang for fixing the bugs in my code):
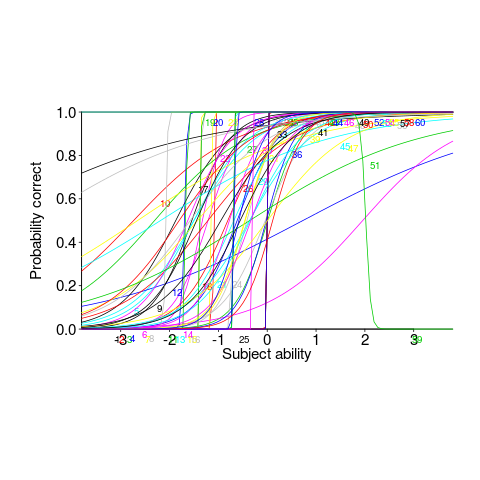
Yes, for question 51 the probability of a correct answer decreases with worker ability. Heads are being scratched about this.
There might be some patterns buried in amongst all those lines, e.g., particular kinds of patterns require a given level of ability to handle, or correct response to some patterns varying over the whole range of abilities. These are research questions, and this is a blog article: answers in the comments 🙂
This is the first experiment of its kind, so it is bound to throw up more questions than answers. Are more incorrect responses given for longer regexs, particularly if they cannot be completely held in short-term memory? It is convenient for the author to use a short-hand for a range of characters (e.g., a-f), and I was expecting a difference in performance when all the letters were enumerated (e.g., abcdef); I had theories for either one being less error-prone (I obviously need to get out more).
C++ template usage
Generics are a programming construct that allow an algorithm to be coded without specifying the types of some variables, which are supplied later when a specific instance (for some type(s)) is instantiated. Generics sound like a great idea; who hasn’t had to write the same function twice, with the only difference being the types of the parameters.
All of today’s major programming languages support some form of generic construct, and developers have had the opportunity to use them for many years. So, how often generics are used in practice?
In C++, templates are the language feature supporting generics.
The paper: How C++ Templates Are Used for Generic Programming: An Empirical Study on 50 Open Source Systems contains lots of interesting data 🙂 The following analysis applies to the five largest projects analysed: Chromium, Haiku, Blender, LibreOffice and Monero.
As its name suggests, the Standard Template Library (STL) is a collection of templates implementing commonly used algorithms+other stuff (some algorithms were commonly used before the STL was created, and perhaps some are now commonly used because they are in the STL).
It is to be expected that most uses of templates will involve those defined in the STL, because these implement commonly used functionality, are documented and generally known about (code can only be reused when its existence is known about, and it has been written with reuse in mind).
The template instantiation measurements show a 17:1 ratio for STL vs. developer-defined templates (i.e., 149,591 vs. 8,887).
What are the usage characteristics of developer defined templates?
Around 25% of developer defined function templates are only instantiated once, while 15% of class templates are instantiated once.
Most templates are defined by a small number of developers. This is not surprising given that most of the code on a project is written by a small number of developers.
The plot below shows the percentage instantiations (of all developer defined function templates) of each developer defined function template, in rank order (code+data):
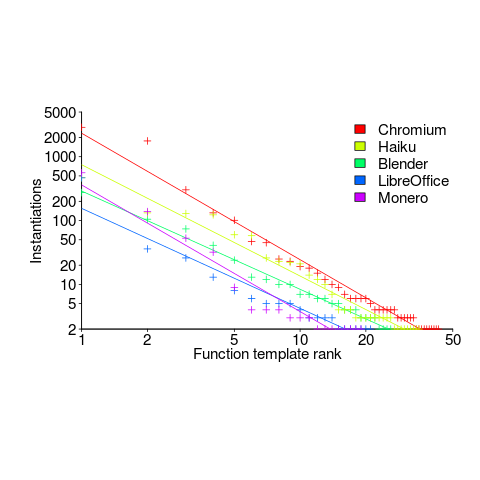
Lines are each a fitted power law, whose exponents vary between -1.5 and -2. Is it just me, or are these exponents surprising close?
The following is for developer defined class templates. Lines are fitted power law, whose exponents vary between -1.3 and -2.6. Not so close here.
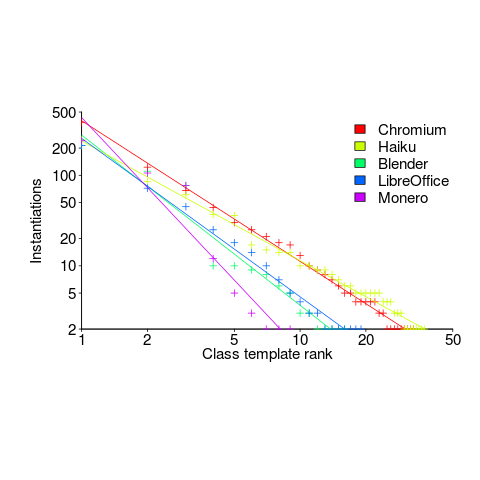
What processes are driving use of developer defined templates?
Every project has its own specific few templates that get used everywhere, by all developers. I imagine these are tailored to the project, and are widely advertised to developers who work on the project.
Perhaps some developers don’t define templates, because that’s not what they do. Is this because they work on stuff where templates don’t offer much benefit, or is it because these developers are stuck in their ways (if so, is it really worth trying to change them?)
Recent Comments