Archive
The aura of software quality
Bad money drives out good money, is a financial adage. The corresponding research adage might be “research hyperbole incentivizes more hyperbole”.
Software quality appears to be the most commonly studied problem in software engineering. The reason for this is that use of the term software quality imbues what is said with an aura of relevance; all that is needed is a willingness to assert that some measured attribute is a metric for software quality.
Using the term “software quality” to appear relevant is not limited to researchers; consultants, tool vendors and marketers are equally willing to attach “software quality” to whatever they are selling.
When reading a research paper, I usually hit the delete button as soon as the authors start talking about software quality. I get very irritated when what looks like an interesting paper starts spewing “software quality” nonsense.
The paper: A Family of Experiments on Test-Driven Development commits the ‘crime’ of framing what looks like an interesting experiment in terms of software quality. Because it looked interesting, and the data was available, I endured 12 pages of software quality marketing nonsense to find out how the authors had defined this term (the percentage of tests passed), and get to the point where I could start learning about the experiments.
While the experiments were interesting, a multi-site effort and just the kind of thing others should be doing, the results were hardly earth-shattering (the experimental setup was dictated by the practicalities of obtaining the data). I understand why the authors felt the need for some hyperbole (but 12-pages). I hope they continue with this work (with less hyperbole).
Anybody skimming the software engineering research literature will be dazed by the number and range of factors appearing to play a major role in software quality. Once they realize that “software quality” is actually a meaningless marketing term, they are back to knowing nothing. Every paper has to be read to figure out what definition is being used for “software quality”; reading a paper’s abstract does not provide the needed information. This is a nightmare for anybody seeking some understanding of what is known about software engineering.
When writing my evidence-based software engineering book I was very careful to stay away from the term “software quality” (one paper on perceptions of software product quality is discussed, and there are around 35 occurrences of the word “quality”).
People in industry are very interested in software quality, and sometimes they have the confusing experience of talking to me about it. My first response, on being asked about software quality, is to ask what the questioner means by software quality. After letting them fumble around for 10 seconds or so, trying to articulate an answer, I offer several possibilities (which they are often not happy with). Then I explain how “software quality” is a meaningless marketing term. This leaves them confused and unhappy. People have a yearning for software quality which makes them easy prey for the snake-oil salesmen.
Software engineering research problems having worthwhile benefits
Which software engineering research problems are likely to yield good-enough solutions that provide worthwhile benefits to professional software developers?
I can think of two (hopefully there are more):
- what is the lifecycle of software? For instance, the expected time-span of the active use of its various components, and the evolution of its dependency ecosystem,
- a model of the main processes involved in a software development project.
Solving problems requires data, and I think it is practical to collect the data needed to solve these two problems; here is some: application lifetime data, and detailed project data (a lot more is needed).
Once a good-enough solution is available, its practical application needs to provide a worthwhile benefit to the customer (when I was in the optimizing compiler business, I found that many customers were not interested in more compact code unless the executable was at least a 10% smaller; this was the era of computer memory often measured in kilobytes).
Investment decisions require information about what is likely to happen in the future, and an understanding of common software lifecycles is needed. The fact that most source code has a brief existence (a few years) and is rarely modified by somebody other than the original author, has obvious implications for investment decisions intended to reduce future maintenance costs.
Running a software development project requires an understanding of the processes involved. This knowledge is currently acquired by working on projects managed by people who have successfully done it before. A good-enough model is not going to replace the need for previous experience, some amount of experience is always going to be needed, but it will provide an effective way of understanding what is going on. There are probably lots of different good-enough ways of running a project, and I’m not expecting there to be a one-true-way of optimally running a project.
Perhaps the defining characteristic of the solution to both of these problems is lots of replication data.
Applications are developed in many ecosystems, and there is likely to be variations between the lifecycles that occur in different ecosystems. Researchers tend to focus on Github because it is easily accessible, which is no good when replications from many ecosystems are needed (an analysis of Github source lifetime has been done).
Projects come in various shapes and sizes, and a good-enough model needs to handle all the combinations that regularly occur. Project level data is not really present on Github, so researchers need to get out from behind their computers and visit real companies.
Given the payback time-frame for software engineering research, there are problems which are not cost-effective to attempt to answer. Suggestions for other software engineering problems likely to be worthwhile trying to solve welcome.
The impact of believability on reasoning performance
What are the processes involved in reasoning? While philosophers have been thinking about this question for several thousand years, psychologists have been running human reasoning experiments for less than a hundred years (things took off in the late 1960s with the Wason selection task).
Reasoning is a crucial ability for software developers, and I thought that there would be lots to learn from the cognitive psychologists research into reasoning. After buying all the books, and reading lots of papers, I realised that the subject was mostly convoluted rabbit holes individually constructed by tiny groups of researchers. The field of decision-making is where those psychologists interested in reasoning, and a connection to reality, hang-out.
Is there anything that can be learned from research into human reasoning (other than that different people appear to use different techniques, and some problems are more likely to involve particular techniques)?
A consistent result from experiments involving syllogistic reasoning is that subjects are more likely to agree that a conclusion they find believable follows from the premise (and are more likely to disagree with a conclusion they find unbelievable). The following is perhaps the most famous syllogism (the first two lines are known as the premise, and the last line is the conclusion):
All men are mortal.
Socrates is a man.
Therefore, Socrates is mortal. |
Would anybody other than a classically trained scholar consider that a form of logic invented by Aristotle provides a reasonable basis for evaluating reasoning performance?
Given the importance of reasoning ability in software development, there ought to be some selection pressure on those who regularly write software, e.g., software developers ought to give a higher percentage of correct answers to reasoning problems than the general population. If the selection pressure for reasoning ability is not that great, at least software developers have had a lot more experience solving this kind of problem, and practice should improve performance.
The subjects in most psychology experiments are psychology undergraduates studying in the department of the researcher running the experiment, i.e., not the general population. Psychology is a numerate discipline, or at least the components I have read up on have a numeric orientation, and I have met a fair few psychology researchers who are decent programmers. Psychology undergraduates must have an above general-population performance on syllogism problems, but better than professional developers? I don’t think so, but then I may be biased.
A study by Winiger, Singmann, and Kellen asked subjects to specify whether the conclusion of a syllogism was valid/invalid/don’t know. The syllogisms used were some combination of valid/invalid and believable/unbelievable; examples below:
Believable Unbelievable
Valid
No oaks are jubs. No trees are punds.
Some trees are jubs. Some Oaks are punds.
Therefore, some trees Therefore, some oaks
are not oaks. are not trees.
Invalid
No tree are brops. No oaks are foins.
Some oaks are brops. Some trees are foins.
Therefore, some trees Therefore, some oaks
are not oaks. are not trees. |
The experiment was run using an online crowdsource site, and 354 data sets were obtained.
The plot below shows the impact of conclusion believability (red)/unbelievability (blue/green) on subject performance, when deciding whether a syllogism was valid (left) or invalid (right), (code+data):
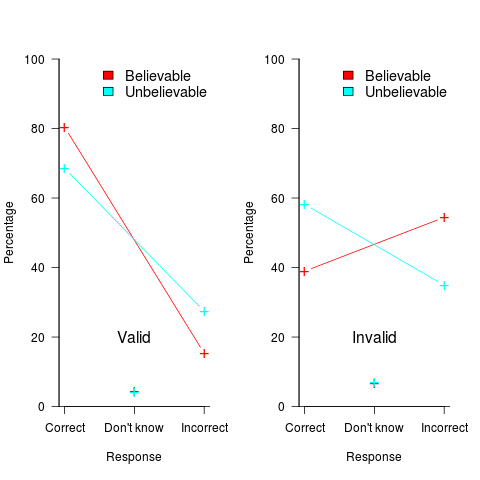
The believability of the conclusion biases the responses away/towards the correct answer (the error bars are tiny, and have not been plotted). Building a regression model puts numbers to the difference, and information on the kind of premise can also be included in the model.
Do professional developers exhibit such a large response bias (I would expect their average performance to be better)?
People tend to write fewer negative tests, than positive tests. Is this behavior related to the believability that certain negative events can occur?
Believability is an underappreciated coding issue.
Hopefully people will start doing experiments to investigate this issue 🙂
Code bureaucracy can reduce the demand for cognitive resources
A few weeks ago I discussed why I thought that research code was likely to remain a tangled mess of spaghetti code.
Everybody’s writing, independent of work-place, starts out as a tangled mess of spaghetti code; some people learn to write code in a less cognitively demanding style, and others stick with stream-of-conscious writing.
Why is writing a tangled mess of spaghetti code (sometimes) not cost-effective, and what are the benefits in making a personal investment in learning to write code in another style?
Perhaps the defining characteristic of a tangled mess of spaghetti code is that everything appears to depend on everything else, consequently: working out the impact of a change to some sequence of code requires an understanding of all the other code (to find out what really does depend on what).
When first starting to learn to program, the people who can hold the necessary information on increasing amounts of code in their head are the ones who manage to create running (of sorts) programs; they have the ‘knack’.
The limiting factor for an individual’s software development is the amount of code they can fit in their head, while going about their daily activities. The metric ‘code that can be fitted in a person’s head’ is an easy concept to grasp, but its definition in terms of the cognitive capacity to store, combine and analyse information in long term memory and the episodic memory of earlier work is difficult to pin down. The reason people live a monks existence when single-handedly writing 30-100 KLOC spaghetti programs (the C preprocessor Richard Stallman wrote for gcc is a good example), is that they have to shut out all other calls on their cognitive resources.
Given time, and the opportunity for some trial and error, a newbie programmer who does not shut their non-coding life down can create, say, a 1,000+ LOC program. Things work well enough, what is the problem?
The problems start when the author stops working on the code for long enough for them to forget important dependencies; making changes to the code now causes things to mysteriously stop working. Our not so newbie programmer now has to go through the frustrating and ego-denting experience of reacquainting themselves with how the code fits together.
There are ways of organizing code such that less cognitive resources are needed to work on it, compared to a tangled mess of spaghetti code. Every professional developer has a view on how best to organize code, what they all have in common is a lack of evidence for their performance relative to other possibilities.
Code bureaucracy does not sound like something that anybody would want to add to their program, but it succinctly describes the underlying principle of all the effective organizational techniques for code.
Bureaucracy compartmentalizes code and arranges the compartments into some form of hierarchy. The hoped-for benefit of this bureaucracy is a reduction in the cognitive resources needed to work on the code. Compartmentalization can significantly reduce the amount of a program’s code that a developer needs to keep in their head, when working on some functionality. It is possible for code to be compartmentalized in a way that requires even more cognitive resources to implement some functionality than without the bureaucracy. Figuring out the appropriate bureaucracy is a skill that comes with practice and knowledge of the application domain.
Once a newbie programmer is up and running (i.e., creating programs that work well enough), they often view the code bureaucracy approach as something that does not apply to them (and if they rarely write code, it might not apply to them). Stream of conscious coding works for them, why change?
I have seen people switch to using code bureaucracy for two reasons:
- peer pressure. They join a group of developers who develop using some form of code bureaucracy, and their boss tells them that this is the way they have to work. In this case there is the added benefit of being able to discuss things with others,
- multiple experiences of the costs of failure. The costs may come from the failure to scale a program beyond some amount of code, or having to keep investing in learning how previously written programs work.
Code bureaucracy has many layers. At the bottom there is splitting code up into functions/methods, then at the next layer related functions are collected together into files/classes, then the layers become less generally agreed upon (different directories are often involved).
One of the benefits of bureaucracy, from the management perspective, is interchangeability of people. Why would somebody make an investment in code bureaucracy if they were not the one likely to reap the benefit?
A claimed benefit of code bureaucracy is ease of wholesale replacement of one compartment by a new one. My experience, along with the little data I have seen, suggests that major replacement is rare, i.e., this is not a commonly accrued benefit.
Another claimed benefit of code bureaucracy is that it makes programs easier to test. What does ‘easier to test’ mean? I have seen reliable programs built from spaghetti code, and unreliable programs packed with code bureaucracy. A more accurate claim is that it can be unexpectedly costly to test programs built from spaghetti code after they have been changed (because of the greater likelihood of the changes having unexpected consequences). A surprising number of programs built from spaghetti code continue to be used in unmodified form for years, because nobody dare risk the cost of checking that they continue to work as expected after a modification
Recent Comments