Archive
Software engineering experiments: sell the idea, not the results
A new paper investigates “… the feasibility of stealthily introducing vulnerabilities in OSS via hypocrite commits (i.e., seemingly beneficial commits that in fact introduce other critical issues).” Their chosen Open source project was the Linux kernel, and they submitted three patches to the kernel review process.
This interesting idea blew up in their faces, when the kernel developers deduced that they were being experimented on (they obviously don’t have a friend on the inside). The authors have come out dodging and weaving.
What can be learned by reading the paper?
Firstly, three ‘hypocrite commits’ is not enough submissions to do any meaningful statistical analysis. I suspect it’s a convenience sample, a common occurrence in software engineering research. The authors sell three as a proof-of-concept.
How many of the submitted patches passed the kernel review process?
The paper does not say. The first eight pages provide an introduction to the Open source development model, the threat model for introducing vulnerabilities, and the characteristics of vulnerabilities that have been introduced (presumably by accident). This is followed by 2.5 pages of background and setup of the experiment (labelled as a proof-of-concept).
The paper then switches (section VII) to discussing a different, but related, topic: the lifetime of (unintended) vulnerabilities in patches that had been accepted (which I think should have been the topic of the paper. This interesting discussion is 1.5 pages; also see The life and death of statically detected vulnerabilities: An empirical study, covered in figure 6.9 in my book.
The last two pages discuss mitigation, related work, and conclusion (“…a proof-of-concept to safely demonstrate the practicality of hypocrite commits, and measured and quantified the risks.”; three submissions is not hard to measure and quantify, but the results are not to be found in the paper).
Having the paper provide the results (i.e., all three commits spotted, and a very negative response by those being experimented on) would have increased the chances of negative reviewer comments.
Over the past few years I have started noticing this kind of structure in software engineering papers, i.e., extended discussion of an interesting idea, setup of experiment, and cursory or no discussion of results. Many researchers are willing to spend lots of time discussing their ideas, but are unwilling to invest much time in the practicalities of testing them. Some reviewers (who decide whether a paper is accepted to publication) don’t see anything wrong with this approach, e.g., they accept these kinds of papers.
Software engineering research remains a culture of interesting ideas, with evidence being an optional add-on.
Another nail for the coffin of past effort estimation research
Programs are built from lines of code written by programmers. Lines of code played a starring role in many early effort estimation techniques (section 5.3.1 of my book). Why would anybody think that it was even possible to accurately estimate the number of lines of code needed to implement a library/program, let alone use it for estimating effort?
Until recently, say up to the early 1990s, there were lots of different computer systems, some with multiple (incompatible’ish) operating systems, almost non-existent selection of non-vendor supplied libraries/packages, and programs providing more-or-less the same functionality were written more-or-less from scratch by different people/teams. People knew people who had done it before, or even done it before themselves, so information on lines of code was available.
The numeric values for the parameters appearing in models were obtained by fitting data on recorded effort and lines needed to implement various programs (63 sets of values, one for each of the 63 programs in the case of COCOMO).
How accurate is estimated lines of code likely to be (this estimate will be plugged into a model fitted using actual lines of code)?
I’m not asking about the accuracy of effort estimates calculated using techniques based on lines of code; studies repeatedly show very poor accuracy.
There is data showing that different people implement the same functionality with programs containing a wide range of number of lines of code, e.g., the 3n+1 problem.
I recently discovered, tucked away in a dataset I had previously analyzed, developer estimates of the number of lines of code they expected to add/modify/delete to implement some functionality, along with the actuals.
The following plot shows estimated added+modified lines of code against actual, for 2,692 tasks. The fitted regression line, in red, is:  (the standard error on the exponent is
(the standard error on the exponent is  ), the green line shows
), the green line shows  (code+data):
(code+data):
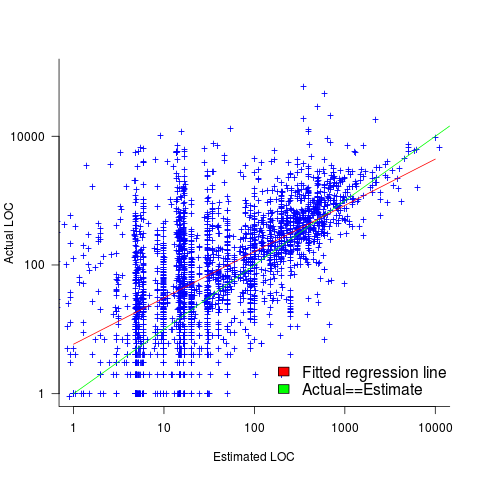
The fitted red line, for lines of code, shows the pattern commonly seen with effort estimation, i.e., underestimating small values and over estimating large values; but there is a much wider spread of actuals, and the cross-over point is much further up (if estimates below 50-lines are excluded, the exponent increases to 0.92, and the intercept decreases to 2, and the line shifts a bit.). The vertical river of actuals either side of the 10-LOC estimate looks very odd (estimating such small values happen when people estimate everything).
My article pointing out that software effort estimation is mostly fake research has been widely read (it appears in the first three results returned by a Google search on software fake research). The early researchers did some real research to build these models, but later researchers have been blindly following the early ‘prophets’ (i.e., later research is fake).
Lines of code probably does have an impact on effort, but estimating lines of code is a fool’s errand, and plugging estimates into models built from actuals is just crazy.
Pricing by quantity of source code
Software tool vendors have traditionally licensed their software on a per-seat basis, e.g., the cost increases with the number of concurrent users. Per-seat licensing works well when there is substantial user interaction, because the usage time is long enough for concurrent usage to build up. When a tool can be run non-interactively in the cloud, its use is effectively instantaneous. For instance, a tool that checks source code for suspicious constructs. Charging by lines of code processed is a pricing model used by some tool vendors.
Charging by lines of code processed creates an incentive to reduce the number of lines. This incentive was once very common, when screens supporting 24 lines of 80 characters were considered a luxury, or the BASIC interpreter limited programs to 1023 lines, or a hobby computer used a TV for its screen (a ‘tiny’ CRT screen, not a big flat one).
It’s easy enough to splice adjacent lines together, and halve the cost. Well, ease of splicing depends on programming language; various edge cases have to be handled (somebody is bound to write a tool that does a good job).
How does the tool vendor respond to a (potential) halving of their revenue?
Blindly splicing pairs of lines creates some easily detectable patterns in the generated source. In fact, some of these patterns are likely to be flagged as suspicious, e.g., if (x) a=1;b=2; (did the developer forget to bracket the two statements with { }).
The plot below shows the number of lines in gcc 2.95 containing a given number of characters (left, including indentation), and the same count after even-numbered lines (with leading whitespace removed) have been appended to odd-numbered lines (code+data, this version of gcc was using in my C book):
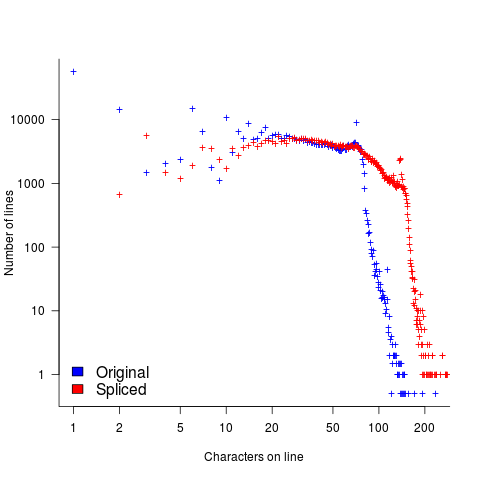
The obvious change is the introduction of a third straight’ish line segment (the increase in the offset of the sharp decline might be explained away as a consequence of developers using wider windows). By only slicing the ‘right’ pairs of lines together, the obvious patterns won’t be present.
Using lines of codes for pricing has the advantage of being easy to explain to management, the people who sign off the expense, who might not know much about source code. There are other metrics that are much harder for developers to game. Counting tokens is the obvious one, but has developer perception issues: Brackets, both round and curly. In the grand scheme of things, the use/non-use of brackets where they are optional has a minor impact on the token count, but brackets have an oversized presence in developer’s psyche.
Counting identifiers avoids the brackets issue, along with other developer perceptions associated with punctuation tokens, e.g., a null statement in an else arm.
If the amount charged is low enough, social pressure comes into play. Would you want to work for a company that penny pinches to save such a small amount of money?
As a former tool vendor, I’m strongly in favour of tool vendors making a healthy profit.
Creating an effective static analysis requires paying lots of attention to lots of details, which is very time-consuming. There are lots of not particularly good Open source tools out there; the implementers did all the interesting stuff, and then moved on. I know of several groups who got together to build tools for Java when it started to take-off in the mid-90s. When they went to market, they quickly found out that Java developers expected their tools to be free, and would not pay for claimed better versions. By making good enough Java tools freely available, Sun killed the commercial market for sales of Java tools (some companies used their own tools as a unique component of their consulting or service offerings).
Could vendors charge by the number of problems found in the code? This would create an incentive for them to report trivial issues, or be overly pessimistic about flagging issues that could occur (rather than will occur).
Why try selling a tool, why not offer a service selling issues found in code?
Back in the day a living could be made by offering a go-faster service, i.e., turn up at a company and reduce the usage cost of a company’s applications, or reducing the turn-around time (e.g., getting the daily management numbers to appear in less than 24-hours). This was back when mainframes ruled the computing world, and usage costs could be eye-watering.
Some companies offer bug-bounties to the first person reporting a serious vulnerability. These public offers are only viable when the source is publicly available.
There are companies who offer a code review service. Having people review code is very expensive; tools are good at finding certain kinds of problem, and investing in tools makes sense for companies looking to reduce review turn-around time, along with checking for more issues.
The first computer I owned
The first computer I owned was a North Star Horizon. I bought it in kit form, which meant bags of capacitors, resistors, transistors, chips, printed circuit boards, etc, along with the circuit diagrams for each board. These all had to be soldered in the right holes, the chips socketed (no surface mount soldering for such a low volume system), and wires connected. I was amazed when the system booted the first time I powered it up; debugging with the very basic equipment I had would have been a nightmare. The only missing component was the power supply transformer, and a trip to the London-based supplier sorted that out. I saved a months’ salary by building the kit (which cost me 4-months salary, and I was one of the highest paid people in my circle).

The few individuals who bought a computer in the late 1970s bought either a Horizon or a Commodore Pet (which was more expensive, but came with an integrated monitor and keyboard). Computer ownership really started to take off when the BBC micro came along at the end of 1981, and could be bought for less than a months’ salary (at least for a white-collar worker).
My Horizon contained a Z80A clocking at 4MHz, 32K of RAM, and two 5 1/4-inch floppy drives (each holding 360K; the Wikipedia article says the drives held 90K, mine {according to the labels on the floppies, MD 525-10} are 40-track, 10-sector, double density). I later bought another 32K of memory; the system ROM was at 56K, and contained 4K of code, various tricks allowed the 4K above 60K to be used (the consistent quality of the soldering on one of the boards below identifies the non-hand built board).

The OS that came with the system was CP/M, renamed to CP/M-80 when the Intel 8086 came along, and will be familiar to anybody used to working with early versions of MS-DOS.
As a fan of Pascal, my development environment of choice was UCSD Pascal. The C compiler of choice was BDS C.
Horizon owners are total computer people 🙂 An emulator, running under Linux and capable of running Horizon disk images, is available for those wanting a taste of being a Horizon owner. I didn’t see any mention of audio emulation in the documentation; clicks and whirls from the floppy drive were a good way of monitoring compile progress without needing to look at the screen (not content with using our Horizon’s at home, another Horizon owner and I implemented a Horizon emulator in Fortran, running on the University’s Prime computers). I wonder how many Nobel-prize winners did their calculations on a Horizon?
The Horizon spec needs to be appreciated in the context of its time. When I worked in application support at the University of Surrey, users had a default file allocation of around 100K’ish (memory is foggy). So being able to store stuff on a 360K floppy, which could be purchased in boxes of 10, was a big deal. The mainframe/minicomputers of the day were available with single-digit megabytes, but many previous generation systems had under 100K of RAM. There were lots of programs out there still running in 64K. In terms of cpu power, nearly all existing systems were multi-user, and a less powerful, single-user, cpu beats sharing a more powerful cpu with 10-100 people.
In terms of sheer weight, visual appearance and electrical clout, the Horizon power supply far exceeds those seen in today’s computers, which look tame by comparison (two of those capacitors are 4-inches tall):

My Horizon has been sitting in the garage for 32-years, and tucked away in unused rooms for years before that. The main problem with finding out whether it still works is finding a device to connect to the 25-pin serial port. I have an old PC with a 9-pin serial port, but I have spent enough of my life fiddling around with serial-port cables and Kermit to be content trying a simpler approach. I connect the power supply and switched it on. There was a loud crack and a flash on the disk-controller board; probably a tantalum capacitor giving up the ghost (easy enough to replace). The primary floppy drive did spin up and shutdown after some seconds (as expected), but the internal floppy engagement arm (probably not its real name) does not swing free when I open the bay door (so I cannot insert a floppy).
I am hoping to find a home for it in a computer museum, and have emailed the two closest museums. If these museums are not interested, the first person to knock on my door can take it away, along with manuals and floppies.
Update: This North Star can now be seen at the Retro Computer Museum.
Linux has a sleeper agent working as a core developer
The latest news from Wikileaks, that GCHQ, the UK’s signal intelligence agency, has a sleeper agent working as a trusted member of the Linux kernel core development team should not come as a surprise to anybody.
The Linux kernel is embedded as a core component inside many critical systems; the kind of systems that intelligence agencies and other organizations would like full access.
The open nature of Linux kernel development makes it very difficult to surreptitiously introduce a hidden vulnerability. A friendly gatekeeper on the core developer team is needed.
In the Open source world, trust is built up through years of dedicated work. Funding the right developer to spend many years doing solid work on the Linux kernel is a worthwhile investment. Such a person eventually reaches a position where the updates they claim to have scrutinized are accepted into the codebase without a second look.
The need for the agent to maintain plausible deniability requires an arm’s length approach, and the GCHQ team made a wise choice in targeting device drivers as cost-effective propagators of hidden weaknesses.
Writing a device driver requires the kinds of specific know-how that is not widely available. A device driver written by somebody new to the kernel world is not suspicious. The sleeper agent has deniability in that they did not write the code, they simply ‘failed’ to spot a well hidden vulnerability.
Lack of know-how means that the software for a new device is often created by cutting-and-pasting code from an existing driver for a similar chip set, i.e., once a vulnerability has been inserted it is likely to propagate.
Perhaps it’s my lack of knowledge of clandestine control of third-party computers, but the leak reveals the GCHQ team having an obsession with state machines controlled by pseudo random inputs.
With their background in code breaking, I appreciate that GCHQ have lots of expertise to throw at doing clever things with pseudo random numbers (other than introducing subtle flaws in public key encryption).
What about the possibility of introducing non-random patterns in randomised storage layout algorithms (he says, waving his clueless arms around)?
Which of the core developers is most likely to be the sleeper agent? His codename, Basil Brush, suggests somebody from the boomer generation, or perhaps reflects some personal characteristic; it might also be intended to distract.
What steps need to be taken to prevent more sleeper agents joining the Linux kernel development team?
Requiring developers to provide a record of their financial history (say, 10-years worth), before being accepted as a core developer, will rule out many capable people. Also, this approach does not filter out ideologically motivated developers.
The world may have to accept that intelligence agencies are the future of major funding for widely used Open source projects.
Update
Turns out the sleeper agent was working on xz.
Recent Comments