Archive
Software task estimation using LLMs is fake research
Developers hate having to provide an estimate for the time needed to implement some functionality. Given the extent to which LLMs have become embedded in the software world, offloading the estimation question to an LLM appears to be an obvious solution.
The problem is that LLMs are very unlikely to give a meaningful answer. However, given that 33% of human estimates are accurate (for tasks of a few hours), 66% within a factor of two (over or under), and 95% within a factor of four (over or under), the accuracy bar for LLMs is low.
Given enough training data, LLMs can do amazing things, e.g., help solve difficult maths problems. LLMs often being good-enough at producing source code is dependent on them having been trained on huge amounts of source code.
The miniscule amount of publicly available software task estimation data is orders of magnitude smaller than the quantity needed to effectively fine-tune a software oriented LLM. Estimation training data needs to contain the following information:
- an appropriately detailed description of the problem,
- the source code of the program being updated, as it existed prior to this or any later features being added (similar descriptions may involve different implementation activities on different projects),
- the actual implementation time,
- a summary of the skill set of the developers who did the work (a developer familiar with the source is likely to complete a task faster than a developer new to the project).
There are datasets (here {10K rows} and here {62K rows}) that contain items (1) and (3).
There are datasets (e.g., here {37K rows} and here {23K rows}) that contain (1) for Open source projects, so (2) could be obtained. These datasets contain estimates (usually in Story Points), and a handful of recorded actuals (and often a status change date-time for each issue, which might/perhaps/maybe used as a proxy for actual work time).
Estimation data (in story points, function points, or time) is much more common than Actual (when available, usually time). Needless to say, there are papers (e.g., here and here) that use human estimation data for training, and then measure LLM performance on close it comes to the human estimates, not the actuals.
My 2024 summary of what is known about task estimation did not discuss the impact of LLMs. What was known is 2024 is that several human factors (e.g., use of round numbers and individual risk profile) play a major role in task estimation. LLMs may reduce the time needed for some tasks, but the human factors remain.
The use of round numbers is deeply embedded in the brain. I suspect the impact of LLM usage will not be to reduce implementation time estimates for tasks, but to increase the amount of functionality included in a task to match the established round number times of 1,2,4 and 7 hours.
Users of story points have the option of leaving everything unchanged. However, there are users of story points who equate one story point to one hour. Will the amount of task functionality be increased to maintain this equating?
Users of function points can continue to count them in the same way. What changes, in an LLM world, is the cost of implementing a function point. Given that the method of calculating the number of function points is specified in various national/international standards, it is not possible to simply increase the amount of functionality to maintain the existing price of a function point.
To summarise: LLMs are being trained on small datasets that don’t contain all the required information to give responses that mimic human estimates made in a pre-LLM world.
One of my most popular blog posts is: Software effort estimation is mostly fake research. The adverb “mostly” can be dropped once LLMs are involved.
Another nail for the coffin of past effort estimation research
Programs are built from lines of code written by programmers. Lines of code played a starring role in many early effort estimation techniques (section 5.3.1 of my book). Why would anybody think that it was even possible to accurately estimate the number of lines of code needed to implement a library/program, let alone use it for estimating effort?
Until recently, say up to the early 1990s, there were lots of different computer systems, some with multiple (incompatible’ish) operating systems, almost non-existent selection of non-vendor supplied libraries/packages, and programs providing more-or-less the same functionality were written more-or-less from scratch by different people/teams. People knew people who had done it before, or even done it before themselves, so information on lines of code was available.
The numeric values for the parameters appearing in models were obtained by fitting data on recorded effort and lines needed to implement various programs (63 sets of values, one for each of the 63 programs in the case of COCOMO).
How accurate is estimated lines of code likely to be (this estimate will be plugged into a model fitted using actual lines of code)?
I’m not asking about the accuracy of effort estimates calculated using techniques based on lines of code; studies repeatedly show very poor accuracy.
There is data showing that different people implement the same functionality with programs containing a wide range of number of lines of code, e.g., the 3n+1 problem.
I recently discovered, tucked away in a dataset I had previously analyzed, developer estimates of the number of lines of code they expected to add/modify/delete to implement some functionality, along with the actuals.
The following plot shows estimated added+modified lines of code against actual, for 2,692 tasks. The fitted regression line, in red, is:  (the standard error on the exponent is
(the standard error on the exponent is  ), the green line shows
), the green line shows  (code+data):
(code+data):
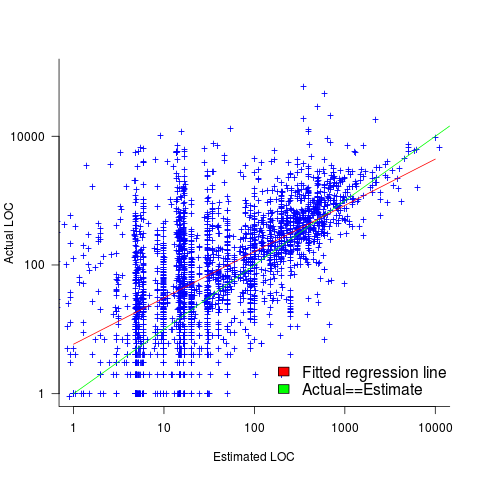
The fitted red line, for lines of code, shows the pattern commonly seen with effort estimation, i.e., underestimating small values and over estimating large values; but there is a much wider spread of actuals, and the cross-over point is much further up (if estimates below 50-lines are excluded, the exponent increases to 0.92, and the intercept decreases to 2, and the line shifts a bit.). The vertical river of actuals either side of the 10-LOC estimate looks very odd (estimating such small values happen when people estimate everything).
My article pointing out that software effort estimation is mostly fake research has been widely read (it appears in the first three results returned by a Google search on software fake research). The early researchers did some real research to build these models, but later researchers have been blindly following the early ‘prophets’ (i.e., later research is fake).
Lines of code probably does have an impact on effort, but estimating lines of code is a fool’s errand, and plugging estimates into models built from actuals is just crazy.
Software effort estimation is mostly fake research
Effort estimation is an important component of any project, software or otherwise. While effort estimation is something that everybody in industry is involved with on a regular basis, it is a niche topic in software engineering research. The problem is researcher attitude (e.g., they are unwilling to venture into the wilds of industry), which has stopped them acquiring the estimation data needed to build realistic models. A few intrepid people have risked an assault on their ego and talked to people in industry, the outcome has been, until very recently, a small collection of tiny estimation datasets.
In a research context, the term effort estimation is actually a hang over from the 1970s; effort correction more accurately describes the behavior of most models since the 1990s. In the 1970s, models took various quantities (e.g., estimated lines of code) and calculated an effort estimate. Later models have included an estimate as input to the model, producing a corrected estimate as output. For the sake of appearances, I will use existing terminology.
Which effort estimation datasets do researchers tend to use?
A 2012 review of datasets used for effort estimation using machine learning between 1991-2010, found that the top three were: Desharnias with 24 papers (29%), COCOMO with 19 papers (23%) and ISBSG with 17. A 2019 review of datasets used for effort estimation using machine learning between 1991 and 2017, found the top three to be NASA with 17 papers (23%), the COCOMO data and ISBSG were joint second with 16 papers (21%), and Desharnais was third with 14. The 2012 review included more sources in its search than the 2019 review, and subjectively your author has noticed a greater use of the NASA dataset over the last five years or so.
How large are these datasets that have attracted so many research papers?
The NASA dataset contains 93 rows (that is not a typo, there is no power-of-ten missing), COCOMO 63 rows, Desharnais 81 rows, and ISBSG is licensed by the International Software Benchmarking Standards Group (academics can apply for a limited time use for research purposes, i.e., not pay the $3,000 annual subscription). The China dataset contains 499 rows, and is sometimes used (there is no mention of a supercomputer being required for this amount of data ;-).
Why are researchers involved in software effort estimation feeding tiny datasets from the 1980s-1990s into machine learning algorithms?
Grant money. Research projects are more likely to be funded if they use a trendy technique, and for the last decade machine learning has been the trendiest technique in software engineering research. What data is available to learn from? Those estimation datasets that were flogged to death in the 1990s using non-machine learning techniques, e.g., regression.
Use of machine learning also has the advantage of not needing to know anything about the details of estimating software effort. Everything can be reduced to a discussion of the machine learning algorithms, with performance judged by a chosen error metric. Nobody actually looks at the predicted estimates to discover that the models are essentially producing the same answer, e.g., one learner predicts 43 months, 2 weeks, 4 days, 6 hours, 47 minutes and 11 seconds, while a ‘better’ fitting one predicts 43 months, 2 weeks, 2 days, 6 hours, 27 minutes and 51 seconds.
How many ways are there to do machine learning on datasets containing less than 100 rows?
A paper from 2012 evaluated the possibilities using 9-learners times 10 data-preprocessing options (e.g., log transform or discretization) times 7-error estimation metrics giving 630 possible final models; they picked the top 10 performers.
This 2012 study has not stopped researchers continuing to twiddle away on the option’s nobs available to them; anything to keep the paper mills running.
To quote the authors of one review paper: “Unfortunately, we found that very few papers (including most of our own) paid any attention at all to properties of the data set.”
Agile techniques are widely used these days, and datasets from the 1990s are not applicable. What datasets do researchers use to build Agile effort estimation models?
A 2020 review of Agile development effort estimation found 73 papers. The most popular data set, containing 21 rows, was used by nine papers. Three papers used simulated data! At least some authors were going out and finding data, even if it contains fewer rows than the NASA dataset.
As researchers in business schools have shown, large datasets can be obtained from industry; ISBSG actively solicits data from industry and now has data on 9,500+ projects (as far as I can tell a small amount for each project, but that is still a lot of projects).
Are there any estimates on GitHub? Some Open source projects use JIRA, which includes support for making estimates. Some story point estimates can be found on GitHub, but the actuals are missing.
A handful of researchers have obtained and released estimation datasets containing thousands of rows, e.g., the SiP dataset contains 10,100 rows and the CESAW dataset contains over 40,000 rows. These datasets are generally ignored, perhaps because when presented with lots of real data, researchers have no idea what to do with it.
Surveys are fake research
For some time now, my default position has been that software engineering surveys, of the questionnaire kind, are fake research (surveys of a particular research field used to be worth reading, but not so often these days; that issues is for another post). Every now and again a non-fake survey paper pops up, but I don’t consider the cost of scanning all the fake stuff to be worth the benefit of finding the rare non-fake survey.
In theory, surveys could be interesting and worth reading about. Some of the things that often go wrong in practice include:
- poorly thought out questions. Questions need to be specific and applicable to the target audience. General questions are good for starting a conversation, but analysis of the answers is a nightmare. Perhaps the questions are non-specific because the researcher is looking for direction: well please don’t inflict your search for direction on the rest of us (a pointless plea in the fling it at the wall to see if it sticks world of academic publishing).
Questions that demonstrate how little the researcher knows about the topic serve no purpose. The purpose of a survey is to provide information of interest to those in the field, not as a means of educating a researcher about what they should already know,
- little effort is invested in contacting a representative sample. Questionnaires tend to be sent to the people that the researcher has easy access to, i.e., a convenience sample. The quality of answers depends on the quality and quantity of those who replied. People who run surveys for a living put a lot of effort into targeting as many of the right people as possible,
- sloppy and unimaginative analysis of the replies. I am so fed up with seeing an extensive analysis of the demographics of those who replied. Tables containing response break-down by age, sex, type of degree (who outside of academia cares about this) create a scientific veneer hiding the lack of any meaningful analysis of the issues that motivated the survey.
Although I have taken part in surveys in the past, these days I recommend that people ignore requests to take part in surveys. Your replies only encourage more fake research.
The aim of this post is to warn readers about the growing use of this form of fake research. I don’t expect anything I say to have any impact on the number of survey papers published.
Recent Comments