Archive
Source code discovery, skipping over the legal complications
The 2020 US elections introduced the issue of source code discovery, in legal cases, to a wider audience. People wanted to (and still do) check that the software used to register and count votes works as intended, but the companies who wrote the software wouldn’t make it available and the courts did not compel them to do so.
I was surprised to see that there is even a section on “Transfer of or access to source code” in the EU-UK trade and cooperation agreement, agreed on Christmas Eve.
I have many years of experience in discovering problems in the source code of programs I did not write. This experience derives from my time as a compiler implementer (e.g., a big customer is being held up by a serious issue in their application, and the compiler is being blamed), and as a static analysis tool vendor (e.g., managers want to know about what serious mistakes may exist in the code of their products). In all cases those involved wanted me there, I could talk to some of those involved in developing the code, and there were known problems with the code. In court cases, the defence does not want the prosecution looking at the code, and I assume that all conversations with the people who wrote the code goes via the lawyers. I have intentionally stayed away from this kind of work, so my practical experience of working on legal discovery is zero.
The most common reason companies give for not wanting to make their source code available is that it contains trade-secrets (they can hardly say that it’s because they don’t want any mistakes in the code to be discovered).
What kind of trade-secrets might source code contain? Most code is very dull, and for some programs the only trade-secret is that if you put in the implementation effort, the obvious way of doing things works, i.e., the secret sauce promoted by the marketing department is all smoke and mirrors (I have had senior management, who have probably never seen the code, tell me about the wondrous properties of their code, which I had seen and knew that nothing special was present).
Comments may detail embarrassing facts, aka trade-secrets. Sometimes the code interfaces to a proprietary interface format that the company wants to keep secret, or uses some formula that required a lot of R&D (management gets very upset when told that ‘secret’ formula can be reverse engineered from the executable code).
Why does a legal team want access to source code?
If the purpose is to check specific functionality, then reading the source code is probably the fastest technique. For instance, checking whether a particular set of input values can cause a specific behavior to occur, or tracing through the logic to understand the circumstances under which a particular behavior occurs, or in software patent litigation checking what algorithms or formula are being used (this is where trade-secret claims appear to be valid).
If the purpose is a fishing expedition looking for possible incorrect behaviors, having the source code is probably not that useful. The quantity of source contained in modern applications can be huge, e.g., tens to hundreds of thousands of lines.
In ancient times (i.e., the 1970s and 1980s) programs were short (because most computers had tiny amounts of memory, compared to post-2000), and it was practical to read the source to understand a program. Customer demand for more features, and the fact that greater storage capacity removed the need to spend time reducing code size, means that source code ballooned. The following plot shows the lines of code contained in the collected algorithms of the Transactions on Mathematical Software, the red line is a fitted regression model of the form:  (code+data):
(code+data):
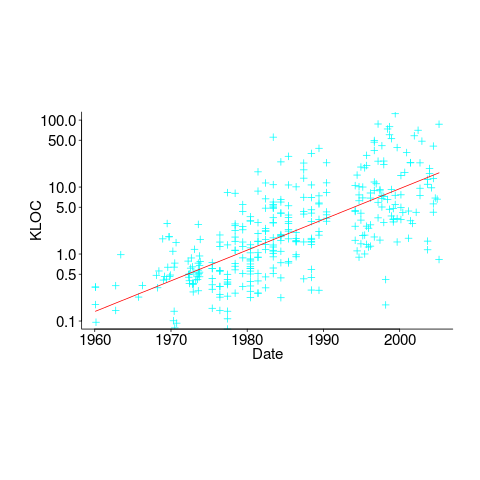
How, by reading the source code, does anybody find mistakes in a 10+ thousand line program? If the program only occasionally misbehaves, finding a coding mistake by reading the source is likely to be very very time-consuming, i.e, months. Work it out yourself: 10K lines of code is around 200 pages. How long would it take you to remember all the details and their interdependencies of a detailed 200-page technical discussion well enough to spot an inconsistency likely to cause a fault experience? And, yes, the source may very well be provided as a printout, or as a pdf on a protected memory stick.
From my limited reading of accounts of software discovery, the time available to study the code may be just days or maybe a week or two.
Reading large quantities of code, to discover possible coding mistakes, are an inefficient use of human time resources. Some form of analysis tool might help. Static analysis tools are one option; these cost money and might not be available for the language or dialect in which the source is written (there are some good tools for C because it has been around so long and is widely used).
Character assassination, or guilt by innuendo is another approach; the code just cannot be trusted to behave in a reasonable manner (this approach is regularly used in the software business). Software metrics are deployed to give the impression that it is likely that mistakes exist, without specifying specific mistakes in the code, e.g., this metric is much higher than is considered reasonable. Where did these reasonable values come from? Someone, somewhere said something, the Moon aligned with Mars and these values became accepted ‘wisdom’ (no, reality is not allowed to intrude; the case is made by arguing from authority). McCabe’s complexity metric is a favorite, and I have written how use of this metric is essentially accounting fraud (I have had emails from several people who are very unhappy about me saying this). Halstead’s metrics are another favorite, and at least Halstead and others at the time did some empirical analysis (the results showed how ineffective the metrics were; the metrics don’t calculate the quantities claimed).
The software development process used to create software is another popular means of character assassination. People seem to take comfort in the idea that software was created using a defined process, and use of ad-hoc methods provides an easy target for ridicule. Some processes work because they include lots of testing, and doing lots of testing will of course improve reliability. I have seen development groups use a process and fail to produce reliable software, and I have seen ad-hoc methods produce reliable software.
From what I can tell, some expert witnesses are chosen for their ability to project an air of authority and having impressive sounding credentials, not for their hands-on ability to dissect code. In other words, just the kind of person needed for a legal strategy based on character assassination, or guilt by innuendo.
What is the most cost-effective way of finding reliability problems in software built from 10k+ lines of code? My money is on fuzz testing, a term that should send shivers down the spine of a defense team. Source code is not required, and the output is a list of real fault experiences. There are a few catches: 1) the software probably to be run in the cloud (perhaps the only cost/time effective way of running the many thousands of tests), and the defense is going to object over licensing issues (they don’t want the code fuzzed), 2) having lots of test harnesses interacting with a central database is likely to be problematic, 3) support for emulating embedded cpus, even commonly used ones like the Z80, is currently poor (this is a rapidly evolving area, so check current status).
Fuzzing can also be used to estimate the numbers of so-far undetected coding mistakes.
Many coding mistakes are not immediately detectable
Earlier this week I was reading a paper discussing one aspect of the legal fallout around the UK Post-Office’s Horizon IT system, and was surprised to read the view that the Law Commission’s Evidence in Criminal Proceedings Hearsay and Related Topics were citing on the subject of computer evidence (page 204): “most computer error is either immediately detectable or results from error in the data entered into the machine”.
What? Do I need to waste any time explaining why this is nonsense? It’s obvious nonsense to anybody working in software development, but this view is being expressed in law related documents; what do lawyers know about software development.
Sometimes fallacies become accepted as fact, and a lot of effort is required to expunge them from cultural folklore. Regular readers of this blog will have seen some of my posts on long-standing fallacies in software engineering. It’s worth collecting together some primary evidence that most software mistakes are not immediately detectable.
A paper by Professor Tapper of Oxford University is cited as the source (yes, Oxford, home of mathematical orgasms in software engineering). Tapper’s job title is Reader in Law, and on page 248 he does say: “This seems quite extraordinarily lax, given that most computer error is either immediately detectable or results from error in the data entered into the machine.” So this is not a case of his words being misinterpreted or taken out of context.
Detecting many computer errors is resource intensive, both in elapsed time, manpower and compute time. The following general summary provides some of the evidence for this assertion.
Two events need to occur for a fault experience to occur when running software:
- a mistake has been made when writing the source code. Mistakes include: a misunderstanding of what the behavior should be, using an algorithm that does not have the desired behavior, or a typo,
- the program processes input values that interact with a coding mistake in a way that produces a fault experience.
That people can make different mistakes is general knowledge. It is my experience that people underestimate the variability of the range of values that are presented as inputs to a program.
A study by Nagel and Skrivan shows how variability of input values results in fault being experienced at different time, and that different people make different coding mistakes. The study had three experienced developers independently implement the same specification. Each of these three implementations was then tested, multiple times. The iteration sequence was: 1) run program until fault experienced, 2) fix fault, 3) if less than five faults experienced, goto step (1). This process was repeated 50 times, always starting with the original (uncorrected) implementation; the replications varied this, along with the number of inputs used.
How many input values needed to be processed, on average, before a particular fault is experienced? The plot below (code+data) shows the numbers of inputs processed, by one of the implementations, before individual faults were experienced, over 50 runs (sorted by number of inputs needed before the fault was experienced):
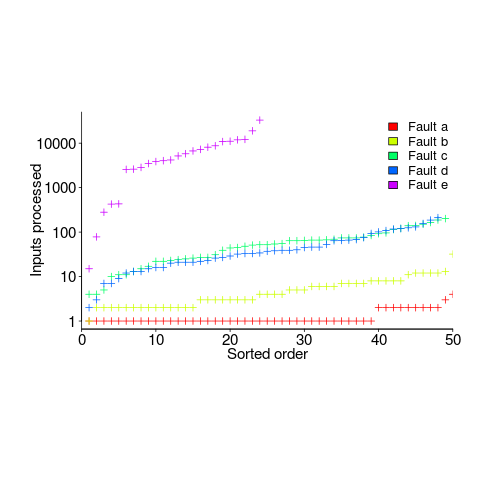
The plot illustrates that some coding mistakes are more likely to produce a fault experience than others (because they are more likely to interact with input values in a way that generates a fault experience), and it also shows how the number of inputs values processed before a particular fault is experienced varies between coding mistakes.
Real-world evidence of the impact of user input on reported faults is provided by the Ultimate Debian Database, which provides information on the number of reported faults and the number of installs for 14,565 packages. The plot below shows how the number of reported faults increases with the number of times a package has been installed; one interpretation is that with more installs there is a wider variety of input values (increasing the likelihood of a fault experience), another is that with more installs there is a larger pool of people available to report a fault experience. Green line is a fitted power law,  , blue line is a fitted loess model.
, blue line is a fitted loess model.
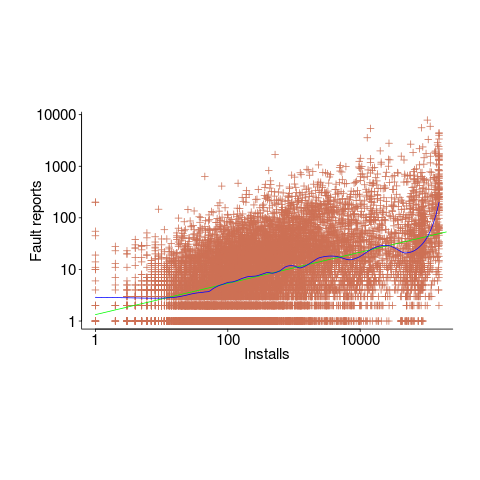
The source containing a mistake may be executed without a fault being experienced; reasons for this include:
- the input values don’t result in the incorrect code behaving differently from the correct code. For instance, given the made-up incorrect code
if (x < 8)(i.e.,8was typed rather than7), the comparison only produces behavior that differs from the correct code whenxhas the value7, - the input values result in the incorrect code behaving differently than the correct code, but the subsequent path through the code produces the intended external behavior.
Some of the studies that have investigated the program behavior after a mistake has deliberately been introduced include:
- checking the later behavior of a program after modifying the value of a variable in various parts of the source; the results found that some parts of a program were more susceptible to behavioral modification (i.e., runtime behavior changed) than others (i.e., runtime behavior not change),
- checking whether a program compiles and if its runtime behavior is unchanged after random changes to its source code (in this study, short programs written in 10 different languages were used),
- 80% of radiation induced bit-flips have been found to have no externally detectable effect on program behavior.
What are the economic costs and benefits of finding and fixing coding mistakes before shipping vs. waiting to fix just those faults reported by customers?
Checking that a software system exhibits the intended behavior takes time and money, and the organization involved may not be receiving any benefit from its investment until the system starts being used.
In some applications the cost of a fault experience is very high (e.g., lowering the landing gear on a commercial aircraft), and it is cost-effective to make a large investment in gaining a high degree of confidence that the software behaves as expected.
In a changing commercial world software systems can become out of date, or superseded by new products. Given the lifetime of a typical system, it is often cost-effective to ship a system expected to contain many coding mistakes, provided the mistakes are unlikely to be executed by typical customer input in a way that produces a fault experience.
Beta testing provides selected customers with an early version of a new release. The benefit to the software vendor is targeted information about remaining coding mistakes that need to be fixed to reduce customer fault experiences, and the benefit to the customer is checking compatibility of their existing work practices with the new release (also, some people enjoy being able to brag about being a beta tester).
- One study found that source containing a coding mistake was less likely to be changed due to fixing the mistake than changed for other reasons (that had the effect of causing the mistake to disappear),
- Software systems don't live forever; systems are replaced or cease being used. The plot below shows the lifetime of 202 Google applications (half-life 2.9 years) and 95 Japanese mainframe applications from the 1990s (half-life 5 years; code+data).
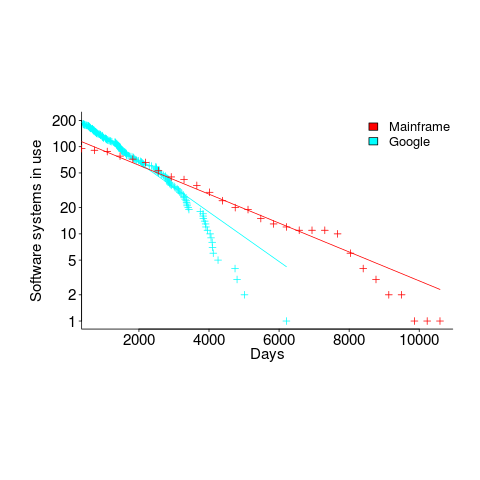
Not only are most coding mistakes not immediately detectable, there may be sound economic reasons for not investing in detecting many of them.
Survival rate of WG21 meeting attendance
WG21, the C++ Standards committee, has a very active membership, with lots of people attending the regular meetings; there are three or four meetings a year, with an average meeting attendance of 67 (between 2004 and 2016).
The minutes of WG21 meetings list those who attend, and a while ago I downloaded these for meetings between 2004 and 2016. Last night I scraped the data and cleaned it up (or at least the attendee names).
WG21 had its first meeting in 1992, and continues to have meetings (eleven physical meetings at the time or writing). This means the data is both left and right censored; known as interval censored. Some people will have attended many meetings before the scraped data starts, and some people listed in the data may not have attended another meeting since.
What can we say about the survival rate of a person being a WG21 attendee in the future, e.g., what is the probability they will attend another meeting?
Most regular attendees are likely to miss a meeting every now and again (six people attended all 30 meetings in the dataset, with 22 attending more than 25), and I assumed that anybody who attended a meeting after 1 January 2015 was still attending. Various techniques are available to estimate the likelihood that known attendees were attending meetings prior to those in the dataset (I’m going with what ever R’s survival package does). The default behavior of R’s Surv function is to handle right censoring, the common case. Extra arguments are needed to handle interval censored data, and I think I got these right (I had to cast a logical argument to numeric for some reason; see code+data).
The survival curves in days since 1 Jan 2004, and meetings based on the first meeting in 2004, with 95% confidence bounds, look like this:
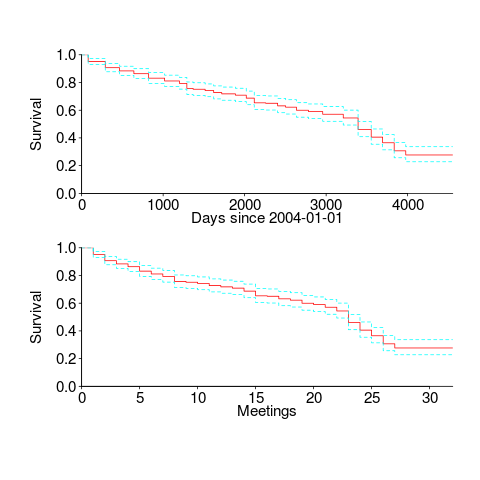
I was expecting a sharper initial reduction, and perhaps wider confidence bounds. Of the 374 people listed as attending a meeting, 177 (47%) only appear once and 36 (10%) appear twice; there is a long tail, with 1.6% appearing at every meeting. But what do I know, my experience of interval censored data is rather limited.
The half-life of attendance is 9 to 10 years, suspiciously close to the interval of the data. Perhaps a reader will scrape the minutes from earlier meetings 🙂
Within the time interval of the data, new revisions of the C++ standard occurred in 20072011 and 2014; there had also been a new release in 2003, and one was being worked on for 2017. I know some people stop attending meetings after a major milestone, such as a new standard being published. A fancier analysis would investigate the impact of standards being published on meeting attendance.
People also change jobs. Do WG21 attendees change jobs to ones that also require/allow them to attend WG21 meetings? The attendee’s company is often listed in the minutes (and is in the data). Something for intrepid readers to investigate.
Christmas books for 2020
A very late post on the interesting books I read this year (only one of which was actually published in 2020). As always the list is short because I did not read many books and/or there is lots of nonsense out there, but this year I have the new excuses of not being able to spend much time on trains and having my own book to finally complete.
I have already reviewed The Weirdest People in the World: How the West Became Psychologically Peculiar and Particularly Prosperous, and it is the must-read of 2020 (after my book, of course :-).
The True Believer by Eric Hoffer. This small, short book provides lots of interesting insights into the motivational factors involved in joining/following/leaving mass movements. Possible connections to software engineering might appear somewhat tenuous, but bits and pieces keep bouncing around my head. There are clearer connections to movements going mainstream this year.
The following two books came from asking what-if questions about the future of software engineering. The books I read suggesting utopian futures did not ring true.
“Money and Motivation: Analysis of Incentives in Industry” by William Whyte provides lots of first-hand experience of worker motivation on the shop floor, along with worker response to management incentives (from the pre-automation 1940s and 1950s). Developer productivity is a common theme in discussions I have around evidence-based software engineering, and this book illustrates the tangled mess that occurs when management and worker aims are not aligned. It is easy to imagine the factory-floor events described playing out in web design companies, with some web-page metric used by management as a proxy for developer productivity.
Labor and Monopoly Capital: The Degradation of Work in the Twentieth Century by Harry Braverman, to quote from Wikipedia, is an “… examination the nature of ‘skill’ and the finding that there was a decline in the use of skilled labor as a result of managerial strategies of workplace control.” It may also have discussed management assault of blue-collar labor under capitalism, but I skipped the obviously political stuff. Management do want to deskill software development, if only because it makes it easier to find staff, with the added benefit that the larger pool of less skilled staff increases management control, e.g., low skilled developers knowing they can be easily replaced.
Recent Comments