Archive
Small team estimating in story points; a project dataset
Just before the end of last year a regular reader, Mr A., emailed to ask if I would be interested in analysing the software project data for the company he worked for. The wishing to be anonymous company sold physical products, and bespoke software that supported the business was written by a team of three.
Two factors made this dataset interesting, 1) it was for a small team, 2) story points were used for estimating tasks and actual time was recorded (I had not seen such data before).
There are probably hundreds of thousands of small software teams working in companies whose main line of business is far removed from software (a significant percentage of developers work within a small team supporting the activities of non-software companies; I cannot find the bls page listing developer employment across industry codes). These small teams are rarely studied. Software engineering research usually focuses on the practices of software based companies, or large software development projects, i.e., groups likely to be easily visible to external researchers.
To be widely applicable, evidence-based software engineering has to be of practical use to small development teams, not just large development groups.
The wide variety of opinions on the accuracy of story point estimates are unsupported by data; at least I have not yet been able to find any. Here was an opportunity to analyse story point estimates against actual hours.
The reason for analysing task implementation data is to help those involved understand what is going on, with the intent of improving processes. A small team presents two major challenges:
- relatively high levels of variability in the data. When there are only a few people working on a project, the impact of individual events can have a dramatic impact on project metrics, e.g., somebody going on holiday results in a big drop in work performed. Statistical analysis looks for general patterns in data, and small sample sizes have a higher variance than large sample sizes. With a large team, the impact of individual events tends to be smoothed out by the activities of many other events,
- the project lead of a small team is likely to have a good understanding of what is going on. Mr A. was always able to give me detailed explanations behind the patterns I found in the data. There is a lot more going on in a large team, and the team lead is unlikely to have a detailed understanding of everything.
The dataset contained some of the usual patterns found in other datasets (code+data):
- Round numbers. Actual task time finishing on 15/10/30/20 minute boundaries. With stories estimated at between one and five story points, there was little scope for round number use here.
- Consistent under/over estimation. A small sample size limited the chances of seeing both under and over estimation, and only under estimation was seen.
- Estimation accuracy. The factor of two/four accuracy pattern seen is close to that seen in data from other companies.
What did I learn from the analysis of this dataset?
I was pleased to see that the multiplication factors around estimation accuracy were similar to those seen with time-based estimates. I had no feel for how estimation accuracy might compare. We will have to wait and see whether the same pattern is found in other projects using story point estimates.
The analysis conversation for other project datasets had involved exchange of emails. Updating a Markdown formatted project analysis file has proved to be a more usable approach for the conversation between me and the domain expert. I used Visual Studio Code to edit this file and generate a pdf.
I asked Mr A. what would he thought was the most useful part of the analysis, for him.
Mr A. “The most useful part of the analysis? I think it was great to get an outsider’s perspective on the data.”
I hope that this dataset is the first of many from small team projects. With enough experience, it ought to be possible to create a template spreadsheet/markdown file that is generally usable for non-experts.
Human reasoning is generally not logic based
From around 350 BC until the 1960s, the students were taught that people reasoned using logic, and teachers believed this to be true. In the 1960s psychologists started running experiments that asked subjects to solve reasoning problems, the results showed that people often failed to give the answers dictated by logic.
Some recurring patterns were present in the answers given, and small changes in the wording of the question asked were found to produce different answer patterns. Very few researchers were willing to give up the idea that subjects were reasoning using logic, there must be another explanation, e.g., subjects must be interpreting the experimental questions asked in a way that differed from that assumed by the researchers. The social context of reasoning was one of the early drivers of evolutionary psychology; reasoning must provide some survival benefit by solving problems that regularly occur in natural human environments.
After a myriad of detailed theories did little more than predict small subsets of subject responses, mainstream reasoning research finally gave up the belief that logic is the default technique used by people to solve reasoning problems. Theories of reasoning behavior are now based around people estimating probabilities and picking the answer with the highest probability; this approach does a much better job of predicting common patterns in subject answers.
Experimental studies of reasoning often use psychology undergraduates as subjects (the historical norm, with Mechanical Turk workers becoming more common). While researchers may be concerned about how well undergraduate behavior mimics the general population, my concern is the extent to which these results apply to software developers. Is a necessary condition for being a professional software developer that a person, by default, uses logic to solve reasoning problems?
Of course, software developers claim that their reasoning is logic based, but then so do people in the general population (or at least the non-developers I interact with do). The dual-process theory of reasoning contains two reasoning systems, one unconscious/intuitive and the second a conscious/deliberate system; it has been said that the purpose of the second system is to come up with reasons to justify the answers produced by the first system.
Until reasoning experiments are run with professional developer subjects, we won’t know the extent to which existing results in reasoning research apply to this specialist subset of the population.
The Wason selection task is to studies of reasoning, like the fruit fly is to studies of genetics. What pattern of behavior do you show on this task (code)?
The plot below shows a set of four cards, of which you can see only the exposed face but not the hidden back. On each card, there is a number on one side and a letter on the other.
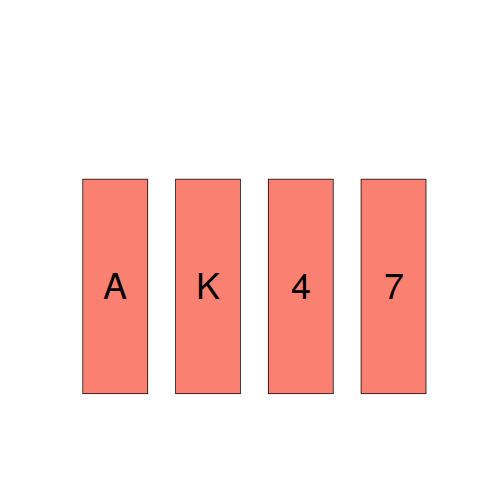
- Given the statement: “If there is a vowel on one side, then there is an even number on the other side.”
Your task is to decide, which, if any, of these four cards must be turned over to decide whether this statement is true. - Specify the cards you would turn over. Don’t turn unnecessary cards.
————————————
Most people correct specify that the card showing a vowel must be turned over to verify that an even number appears on the other side. A common mistake is to specify that the card showing an even number also has to be turned over. However, there is no requirement on the letter appearing on the other side of a card showing an even number. A second necessary condition involves a negative test (something that developers are known to overlook); for the statement to hold, a vowel must not appear on the other side of the card showing an odd number, this is the second card that must be turned over.
Software engineering as a hedonistic activity
My discussions with both managers and developers on software development processes invariably end up on the topic of developer happiness. Managers want to keep their development teams happy, and there is a longstanding developer culture of entitlement to work that they find interesting.
Companies in general want to keep their employees happy, irrespective of the kind of work they do. What makes developers different, from management’s perspective, is that demand for good software developers far outstrips supply.
Many developers approach software engineering as a hedonistic activity; yes, there are those who only do it for the money.
The huge quantity of open source software, much of it written out of personal interest rather than paid employment, provides evidence for there being many people willing to create software because of the pleasure they get from doing it.
Software developers only get to indulge in hedonistic development activities (e.g., choosing which tools to use, how to structure their code, and not having to provide estimates) because of the relative ease with which competent developers can obtain another job. Replacing developers is time-consuming and expensive, which gives existing employees a lot of bargaining power with management.
Some of the consequences of managements’ desire to keep developers happy, or at least not unhappy include:
- Not pushing too hard for an estimate of the likely time needed to complete a task,
- giving developers a lot of say in which languages/tools/packages they use. This creates a downstream need to support a wider variety of development ecosystems than might otherwise have been necessary, and further siloing development teams,
- allowing developers to spend time beautifying their code to meet personal opinions about the visual appearance of source.
The balance of power that facilitates hedonism driven development is determined by the relative size of the employment market in the supply and demand for software developers. Once demand falls below the available supply, finding a new job becomes more difficult, shifting the balance of power away from developers to managers.
I am not expecting supply to exceed demand any time soon. While International computer companies have been laying off lots of staff, demand from small companies appears to be strong (based on the ever-present ‘We’re hiring’ slides I regularly see at London meetups), but things may change. Tools such as ChatGPT are far from good enough to replace developers in the near term.
Many Butterfly collections are worthless
Github based Butterfly collecting continues to dominate research in evidence-based software engineering.
The term Butterfly collecting was first applied to Zoology researchers who spent their time amassing huge collections of various kinds of insects, with Butterfly collections being widely displayed (Butterfly collecting was once a common hobby). Theoretically oriented researchers, in many disciplines, often disparage what they consider to be pointless experimental work as Butterfly collecting.
While some of the data from software engineering Butterfly collections may turn out to be very useful in validating theories of software processes, I suspect that many of the data collections are intrinsically worthless. My two main reasons for suspecting they are worthless are:
- the collection is the publishable output from a series of data analysis fishing expeditions, i.e., researchers iterate over: 1) create a hypothesis, 2) look for data that validates it, 3) rinse and repeat until something is found that looks interesting enough to be accepted for publication.
The problem is the focus of the fishing expedition (as a regular fisher of data, I am not anti-fishing). Simply looking for something that can be published strips off the research aspect of the work. The aim of software engineering research (from the funders’ perspective) is to build a body of knowledge that makes practical connections to industrial practices.
Researchers running a medical trial are required to preregister their research aims, i.e., specify what data they plan to collect and how they are going to analyse it, before they collect any data. Preregistration does not prevent fishing expeditions, but it does make them very visible; providing extra information for readers to evaluate the significance of any findings.
Conference organizers could ask the authors of submitted papers to provide some evidence that the paper is not the product of a fishing expedition. Some form of light-weight preregistration is one source of evidence (some data repositories offer preregistration functionality, e.g., Figshare).
- the use of simplistic statistical analysis techniques, whose results are then used to justify claims that something of note has been discovered.
The simplistic analysis usually tests the hypothesis: “Is there a difference?” A more sophisticated analysis would ask about the size of any difference. My experience from analysing data from these studies is that while a difference exists, it is often so small that it is of little practical interest.
The non-trivial number of papers containing effectively null results could easily be reduced by conferences and Journals requiring the authors of submitted papers to estimate the size of any claimed difference, i.e., use non-simplistic analysis techniques.
Github is an obvious place to mine for software engineering data; it offers a huge volume of code, along with many support tools and processes to mine it. When I tell people that I’m looking for software engineering data, Github is invariably their first suggestion. Jira repos are occasionally analysed, it’s a question of finding a selection that make their data public.
Github contains so much code, it’s hard to argue that it is not representative of a decent amount of industrial code. There’s lots of software data that is rarely publicly available on Github (e.g., schedules and estimates), but this is a separate issue.
I see Github being the primary site for mining software engineering related data for many years to come.
Recent Comments