Archive
My 2025 in software engineering
Unrelenting talk of LLMs now infests all the software ecosystems I frequent.
- Almost all the papers published (week) daily on the Software Engineering arXiv have an LLM themed title. Way back when I read these LLM papers, they seemed to be more concerned with doing interesting things with LLMs than doing software engineering research.
- Predictions of the arrival of AGI are shifting further into the future. Which is not difficult given that a few years ago, people were predicting it would arrive within 6-months. Small percentage improvements in benchmark scores are trumpeted by all and sundry.
- Towards the end of the year, articles explaining AI’s bubble economics, OpenAI’s high rate of loosing money, and the convoluted accounting used to fund some data centers, started appearing.
Coding assistants might be great for developer productivity, but for Cursor/Claude/etc to be profitable, a significant cost increase is needed.
Will coding assistant companies run out of money to lose before their customers become so dependent on them, that they have no choice but to pay much higher prices?
With predictions of AGI receding into the future, a new grandiose idea is needed to fill the void. Near the end of the year, we got to hear people who must know it’s nonsense claiming that data centers in space would be happening real soon now.
I attend one or two, occasionally three, evening meetups per week in London. Women used to be uncommon at technical meetups. This year, groups of 2–4 women have become common in meetings of 20+ people (perhaps 30% of attendees); men usually arrive individually. Almost all women I talked to were (ex) students looking for a job; this was also true of the younger (early 20s) men I spoke to. I don’t know if attending meetups been added to the list of things to do to try and find a job.
Tom Plum passed away at the start of the year. Tom was a softly spoken gentleman whose company, PlumHall, sold a C, and then C++, compiler validation suite. Tom lived on Hawaii, and the C/C++ Standard committees were always happy to accept his invitation to host an ISO meeting. The assets of PlumHall have been acquired by Solid Sands.
Perennial was the other major provider of C/C++ validation suites. It’s owner, Barry Headquist, is now enjoying his retirement in Florida.
The evidence-based software engineering Discord channel continues to tick over (invitation), with sporadic interesting exchanges.
What did I learn/discover about software engineering this year?
Software reliability research is a bigger mess than I had previously thought.
I now regularly use LLMs to find mathematical solutions to my experimental models of software engineering processes. Most go nowhere, but a few look like they have potential (here and here and here).
Analysis/data in the following blog posts, from the last 12-months, belongs in my book Evidence-Based Software Engineering, in some form or other (2025 was a bumper year):
Naming convergence in a network of pairwise interactions
Lifetime of coding mistakes in the Linux kernel
Decline in downloads of once popular packages
Distribution of method chains in Java and Python
Modeling the distribution of method sizes
Distribution of integer literals in text/speech and source code
Percentage of methods containing no reported faults
Half-life of Open source research software projects
Positive and negative descriptions of numeric data
Impact of developer uncertainty on estimating probabilities
After 55.5 years the Fortran Specialist Group has a new home
When task time measurements are not reported by developers
Evolution has selected humans to prefer adding new features
One code path dominates method execution
Software_Engineering_Practices = Morals+Theology
Long term growth of programming language use
Deciding whether a conclusion is possible or necessary
CPU power consumption and bit-similarity of input
Procedure nesting a once common idiom
Functions reduce the need to remember lots of variables
Remotivating data analysed for another purpose
Half-life of Microsoft products is 7 years
How has the price of a computer changed over time?
Deep dive looking for good enough reliability models
Apollo guidance computer software development process
Example of an initial analysis of some new NASA data
Extracting information from duplicate fault reports
I visited Foyles bookshop on Charing cross road during the week (if you’re ever in London, browsing books in Foyles is a great way to spend an afternoon).
Computer books once occupied almost half a floor, but is now down to five book cases (opposite is statistics occupying one book case, and the rest of mathematics in another bookcase):

Around the corner, Gender Studies and LGBTQ+ occupies seven bookcases (the same as last year, as I recall):

Fifth anniversary of Evidence-based Software Engineering book
Yesterday was the 5th anniversary of the publication of my book Evidence-based Software Engineering.
The general research trajectory I was expecting in the 2020s (e.g., more sophisticated statistical analysis and more evidence based studies) has been derailed by the arrival of LLMs three years ago. Almost all software engineering researchers have jumped on the LLM bandwagon, studying whatever LLM use case is likely to result in a published paper. While I have noticed more papers using statistical techniques discovered after the digital computer was invented (perhaps influenced by the second half of the book), there seems to be a lot fewer evidence based papers being published. I don’t expect researches studying software engineering to jump off the LLM bandwagon in the next few years.
The net result of this lack of new research findings is that the book contents are not yet in need of an update.
On a positive note, LLMs’ mathematical problem-solving capabilities have significantly reduced the time needed to analyse models of software engineering processes.
Had today’s LLMs been available while I was writing the book, the text would probably have included many more theoretical models and their analysis. ‘Probably’, because sometimes the analysis finds that a model does not provide meaningfully mimic reality, so it’s possible that only a few more models would have been included.
My plan for the next year is to use LLM’s mathematical problem-solving capabilities to help me analyse models of software engineering processes. A discussion of any interested results found will appear on this blog. I’m hoping that there will be active conversations on the evidence based software engineering Discord channel.
It makes sense to hone my model analysis skills by starting with the subject I am most familiar with, i.e., source code. It also helps that tools are available for obtaining more source measurement data.
I will continue to write about any interesting papers that appear on the arXiv lists cs.se and cs.PL, as well as the major conferences. There won’t be time to track the minor conferences.
Questions raised during model analysis sometimes suggest ideas that, when searched for, lead to new data being discovered. Discovering new data using a previously untried search phrase is always surprising.
My 2024 in software engineering
Readers are unlikely to have noticed something that has not been happening during the last few years. The plot below shows, by year of publication, the number of papers cited (green) and datasets used (red) in my 2020 book Evidence-Based Software Engineering. The fitted red regression lines suggest that the 20s were going to be a period of abundant software engineering data; this has not (yet?) happened (the blue line is a local regression fit, i.e., loess). In 2020 COVID struck, and towards the end of 2022 Large Language Models appeared and sucked up all the attention in the software research ecosystem, and there is lots of funding; data gathering now looks worse than boring (code+data):
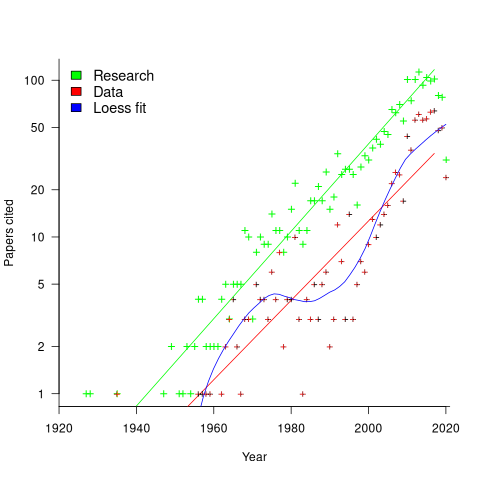
LLMs are showing great potential as research tools, but researchers are still playing with them in the sandpit.
How many AI startups are there in London? I thought maybe one/two hundred. A recruiter specializing in AI staffing told me that he would estimate around four hundred; this was around the middle of the year.
What did I learn/discover about software engineering this year?
Regular readers may have noticed a more than usual number of posts discussing papers/reports from the 1960s, 1970s and early 1980s. There is a night and day difference between software engineering papers from this start-up period and post mid-1980s papers. The start-up period papers address industry problems using sophisticated mathematical techniques, while post mid-1980s papers pay lip service to industrial interests, decorating papers with marketing speak, such as maintainability, readability, etc. Mathematical orgasms via the study of algorithms could be said to be the focus of post mid-1980s researchers. So-called software engineering departments ought to be renamed as Algorithms department.
Greg Wilson thinks that the shift happened in the 1980s because this was the decade during which the first generation of ‘trained in software’ people (i.e., emphasis on mathematics and abstract ideas) became influential academics. Prior generations had received a practical training in physics/engineering, and been taught the skills and problem-solving skills that those disciplines had refined over centuries.
My research is a continuation of the search for answers to the same industrial problems addressed by the start-up researchers.
In the second half of the year I discovered the mathematical abilities of LLMs, and started using them to work through the equations for various models I had in mind. Sometimes the final model turned out to be trivial, but at least going through the process cleared away the complications in my mind. According to reports, OpenAI’s next, as yet unreleased, model has super-power maths abilities. It will still need a human to specify the equations to solve, so I am not expecting to have nothing to blog about.
Analysis/data in the following blog posts, from the last 12-months, belongs in my book Evidence-Based Software Engineering, in some form or other:
Small business programs: A dataset in the research void
Putnam’s software equation debunked (the book is non-committal).
if statement conditions, some basic measurements
Number of statement sequences possible using N if-statements; perhaps.
A new NASA software dataset from the 1970s
A surprising retrospective task estimation dataset
Average lines added/deleted by commits across languages
Census of general purpose computers installed in the 1960s
Some information on story point estimates for 16 projects
Agile and Waterfall as community norms
Median system cpu clock frequency over last 15 years
The evidence-based software engineering Discord channel continues to tick over (invitation), with sporadic interesting exchanges.
Good enough reliability models: still an unknown
Estimating the likelihood that a software system will operate as intended, for some period of time, is one of the big problems within the field of software reliability research. When software does not operate as intended, a fault, or bug, or hallucination is said to have occurred.
Three events need to occur for a user of a software system to experience a fault:
- a developer writes code that does not always behave as intended, i.e., a coding mistake,
- the user of the software feeds it input that causes the coding mistake to produce unintended behavior,
- the unintended behavior percolates through the system to produce a visible fault (sometimes an unintended behavior does not percolate very far, and does not produce any change of visible behavior).
Modelling each kind of event and their interaction is a huge undertaking. Researchers in one of the major subfields of software reliability take a global approach, e.g., they model time to next fault experience, using data on the number of faults experienced per given amount of cpu/elapsed time (often obtained during testing). Modelling the fault data obtained during testing results in a model of the likelihood of the next fault experienced using that particular test process. This is useful for doing a return-on-investment calculation to decide whether to do more testing. If the distribution of inputs used during testing is similar to the distribution of customer inputs, then the model can be of use in estimating the rate of customer fault experiences.
Is it possible to use a model whose design was driven by data from testing one or more software systems to estimate the rate of fault experiences likely when testing other software systems?
The number of coding mistakes will differ between systems (because they have different sizes, and/or different developer abilities), and the testers’ ability will be different, and the extent to which mistaken behavior percolates through code will differ. However, it is possible for there to be a general model for rate of fault experiences that contains various parameters that need to be fitted for each situation.
Since that start of the 1970s, researchers have been searching for this general model (the first software reliability model is thought to be: “Program errors as a birth-and-death process” by G. R. Hudson, Report SP-3011, System Development Corp., 1967 Dec 4; please send me a copy, if you have one).
The image below shows the 18 models discussed in the 1987 book “Software Reliability: Measurement, Prediction, Application” by Musa, Iannino, and Okumoto (later editions have seriously watered down the technical contents, and lack most of the tables/plots). It’s to be expected that during the early years of a new field, many different models will be proposed and discussed.
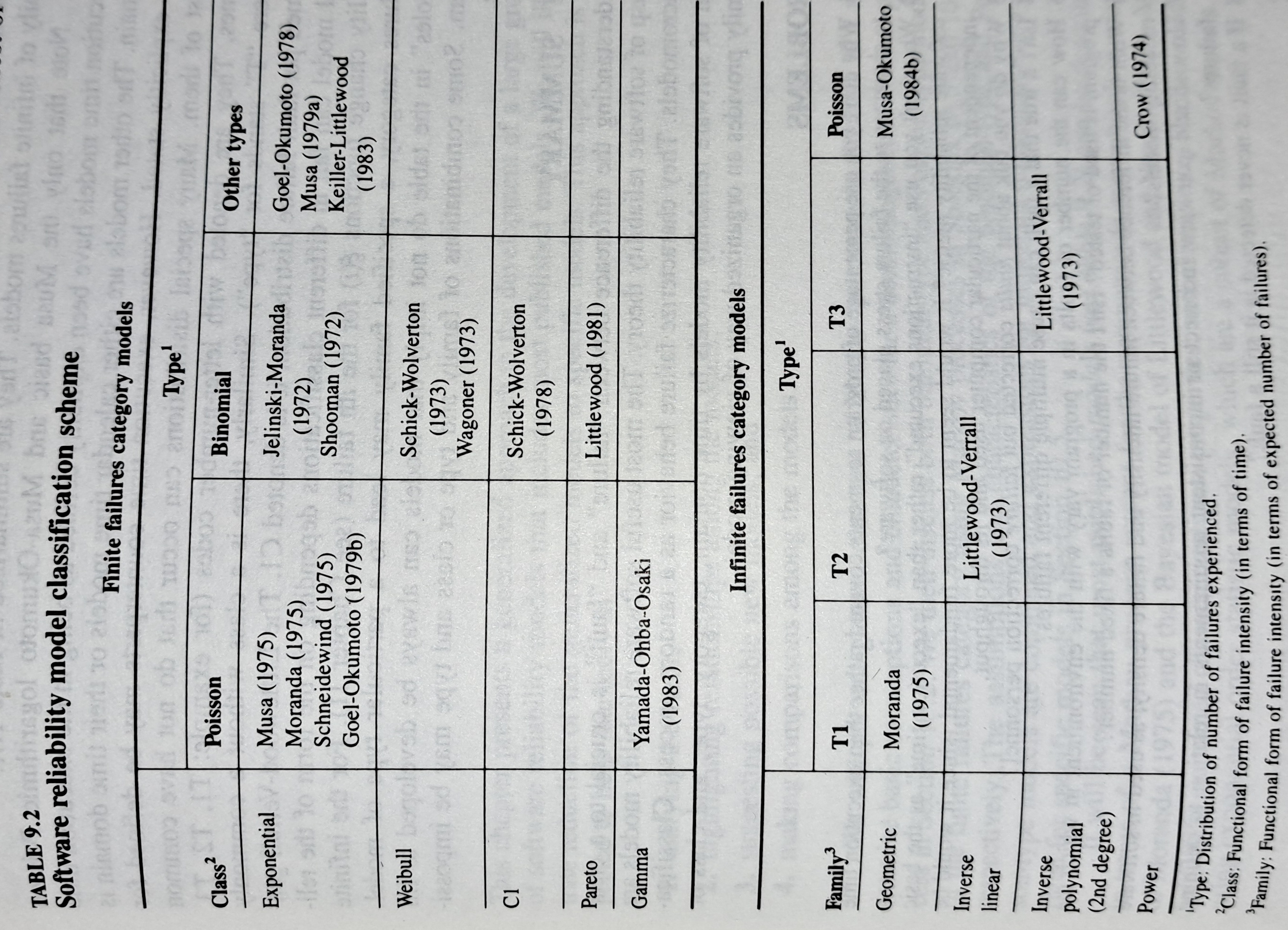
Did researchers discover a good-enough general model for rate of fault experiences?
It’s hard to say. There is not enough reliability data to be confident that any of the umpteen proposed models is consistently better at predicting than any other. I believe that the evidence-based state of the art has not yet progressed beyond the 1982 report Software Reliability: Repetitive Run Experimentation and Modeling by Nagel and Skrivan.
Fitting slightly modified versions of existing models to a small number of tiny datasets has become standard practice in this corner of software engineering research (the same pattern of behavior has occurred in software effort estimation). The image below shows 16 models from a 2021 paper.
Nearly all the reliability data used to create these models is from systems built in the 1960s and 1970s. During these decades, software systems were paid for organizations that appreciated the benefits of collecting data to build models, and funding the necessary research. My experience is that few academics make an effort to talk to people in industry, which means they are unlikely to acquire new datasets. But then researchers are judged by papers published, and the ecosystem they work within is willing to publish papers extolling the virtues of another variant of an existing model.

The various software fault datasets used to create reliability models tends to be scattered in sometimes hard to find papers (yes, it is small enough to be printed in papers). I have finally gotten around to organizing all the public data that I have in one place, a Reliability data repo on GitHub.
If you have a public fault dataset that does not appear in this repo, please send me a copy.
1970s: the founding decade of software reliability research
Reliability research is a worthwhile investment for very large organizations that fund the development of many major mission-critical software systems, where reliability is essential. In the 1970s, the US Air Force’s Rome Air Development Center probably funded most of the evidence-based software research carried out in the previous century. In the 1980s, Rome fell, and the dark ages lasted for many decades (student subjects, formal methods, and mutation testing).
Organizations sponsor research into software reliability because they want to find ways of reducing the number of coding mistakes, and/or the impact of these mistakes, and/or reduce the cost of achieving a given level of reliability.
Control requires understanding, and understanding reliability first requires figuring out the factors that are the primarily drivers of program reliability.
How did researchers go about finding these primary factors? When researching a new field (e.g., software reliability in the 1970s), people can simply collect the data that is right in front of them that is easy to measure.
For industrial researchers, data was collected from completed projects, and for academic researchers, the data came from student exercises.
For a completed project, the available data are the reported errors and the source code. This data be able to answer questions such as: what kinds of error occur, how much effort is needed to fix them, and how common is each kind of error?
Various classification schemes have been devised, including: functional units of an application (e.g., computation, data management, user interface), and coding construct (e.g., control structures, arithmetic expressions, function calls). As a research topic, kinds-of-error has not attracted much attention; probably because error classification requires a lot of manual work (perhaps the availability of LLMs will revive it). It’s a plausible idea, but nobody knows how large an effect it might be.
Looking at the data, it is very obvious that the number of faults increases with program size, measured in lines of code. These are two quantities that are easily measured and researchers have published extensively on the relationship between faults (however these are counted) and LOC (counted by function/class/file/program and with/without comments/blank lines). The problem with LOC is that measuring it appears to be too easy, and researchers keep concocting more obfuscated ways of counting lines.
What do we now know about the relationship between reported faults and LOC? Err, … The idea that there is an optimal number of LOC per function for minimizing faults has been debunked.
People don’t appear to be any nearer understanding the factors behind software reliability than at the end of the 1970s. Yes, tool support has improved enormously, and there are effective techniques and tools for finding and tracking coding mistakes.
Mistakes in programs are put there by the people who create the programs, and they are experienced by the people who use the programs. The two factors rarely researched in software reliability are the people building the systems and the people using them.
Fifty years later, what software reliability books/reports from the 1970s have yet to be improved on?
The 1987 edition (ISBN 0-07-044093-X) of “Software Reliability: Measurement, Prediction, Application” by Musa, Iannino, and Okumoto is based on research done in the 1970s (the 1990 professional edition is not nearly as good). Full of technical details, but unfortunately based on small datasets.
The 1978 book Software Reliability by Thayer, Lipow and Nelson, remains a go-to source for industrial reliability research data.
A good example of the industrial research funded by the Air Force is the 1979 report Software Data Baseline Analysis by D. L. Fish and T. Matsumoto. This is worth looking at just to learn how few rows of data later researchers have been relying on.
Survey papers: LLMs will restore some level of usefulness
Scientific papers are like soap operas, in that understanding them requires readers to have some degree of familiarity with the ongoing plot.
How can people new to an opera quickly get up to speed with the ongoing story lines, without reading hundreds of papers?
The survey paper is intended to be the answer to this question. Traditionally written by an established researcher in the field, the 100+ pages aim to be an authoritative overview of the progress and setbacks of research on a particular topic within the last 5/10/15 years (depending on the rate/lack of progress since the last major survey paper).
These days research papers are often written by PhD students, with the professor doing the supervising, and getting their name tacked on to the end of the list of authors (professors can spend more time writing grant applications than writing research papers). Writing a single 100+ page survey paper is not a cost-effective use of an experienced person’s time, given the pressure to pump out papers, even when the ACM Computing Surveys is one of the highest ranked journals in computing. The short lifecycle of fields driven by the next fashionable topic is another disincentive.
Given the incentives, why are survey papers still being published?
In software engineering there are now two kinds of survey papers: 1) the traditional kind, written by people who see it as a service, or are not on the publish/perish treadmill, or early stage researchers surveying a niche topic, 2) PhD students using what we now call a Large language model summary approach, soon to be replaced by real LLMs.
So-called survey papers (at least in software engineering) are now regularly being written by members of the intended audience of traditional survey papers, i.e., PhD students who are new to the field and want a map of the territory showing the routes to the frontiers.
How does a person who knows almost nothing about a field write a (20-40 page, rarely 100+) survey paper about it?
A survey is based on the list of all the appropriate papers. In theory, appropriate papers have to meet some quality criteria, e.g., be published in a reputable journal/conference/blog. In practice, the list is created by searching various academic publication search engines (e.g., web of science, or the ACM digital library) using a targeted regular expression; for instance:
(agile OR waterfall OR software OR "story points" OR "story point" OR "user stories" OR "function points" OR "planning poker" OR "pomodoros" OR "use case" OR "source code" OR "DORA metrics" OR scrum) (predict OR prediction OR quantify OR dataset OR schedule OR lifecycle OR "life cycle" OR estimate OR estimates OR estimating OR estimation OR estimated OR #noestimates OR "evidence" OR empirical OR evolution OR ecosystems OR cognitive OR economics OR reliability OR metrics OR experiment) |
The list of papers returned may be filtered further, depending on how many there are (a hundred or two does not look too lightweight, and does not require an excessive amount of work).
Next, what to say about these papers, and how many of them actually need to be read?
The bottom of the barrel, vacant ideas, survey paper tabulates easily calculated metrics (e.g., number of papers per year, number of authors per paper, clusters of keywords), and babble on about paper selection criteria, keyword growth and diversity, and more research is needed.
For a survey paper to appear in a layer above the vacant ideas level, the authors have to process some amount of the paper contents. The paper A Systematic Literature Review on Reasons and Approaches for Accurate Effort Estimations in Agile by Pasuksmit, Thongtanunam, and Karunasekera is a recent example of one such survey. The search criteria returned 519 papers, of which 82 were selected for inclusion, i.e., cited. The first 10, of the 42 pages, covered the selection process and the process used to answer the two research questions; RQ1: What are the discovered reasons for inaccurate estimations in Agile iterative development? and RQ2: What are the approaches proposed to improve effort estimation in Agile iterative development?
The main answers to the research questions appeared in: 1) tables which listed attributes relating to the question and the papers that had something to say about that attribute, and 2) sections containing a few paragraphs highlighting various points made by papers about some attribute.
My primary interest was Table 11, which listed the papers/dataset used. A few were new to me, but unfortunately all confidential.
A survey can only be as good as the papers it is based on. The regular expression approach can miss important papers and include unimportant papers. The Pasuksmit et al paper only included one paper by the leading researcher in Agile effort estimation, and included papers that I wouldn’t waste disk space on a pdf file.
I would not recommend these ‘LLM’ style surveys to newcomers to a field. They don’t connect the lines of research, call out the successes/failures, and they don’t provide a map of the territory.
The readership of these survey papers are the experienced researchers, who will scan the list of cited papers looking for anything they might have missed.
I’m not expecting LLMs to be capable of producing experienced professor level survey papers any time soon. In a year or two, LLMs will surely be doing a better job than PhD students.
Many Butterfly collections are worthless
Github based Butterfly collecting continues to dominate research in evidence-based software engineering.
The term Butterfly collecting was first applied to Zoology researchers who spent their time amassing huge collections of various kinds of insects, with Butterfly collections being widely displayed (Butterfly collecting was once a common hobby). Theoretically oriented researchers, in many disciplines, often disparage what they consider to be pointless experimental work as Butterfly collecting.
While some of the data from software engineering Butterfly collections may turn out to be very useful in validating theories of software processes, I suspect that many of the data collections are intrinsically worthless. My two main reasons for suspecting they are worthless are:
- the collection is the publishable output from a series of data analysis fishing expeditions, i.e., researchers iterate over: 1) create a hypothesis, 2) look for data that validates it, 3) rinse and repeat until something is found that looks interesting enough to be accepted for publication.
The problem is the focus of the fishing expedition (as a regular fisher of data, I am not anti-fishing). Simply looking for something that can be published strips off the research aspect of the work. The aim of software engineering research (from the funders’ perspective) is to build a body of knowledge that makes practical connections to industrial practices.
Researchers running a medical trial are required to preregister their research aims, i.e., specify what data they plan to collect and how they are going to analyse it, before they collect any data. Preregistration does not prevent fishing expeditions, but it does make them very visible; providing extra information for readers to evaluate the significance of any findings.
Conference organizers could ask the authors of submitted papers to provide some evidence that the paper is not the product of a fishing expedition. Some form of light-weight preregistration is one source of evidence (some data repositories offer preregistration functionality, e.g., Figshare).
- the use of simplistic statistical analysis techniques, whose results are then used to justify claims that something of note has been discovered.
The simplistic analysis usually tests the hypothesis: “Is there a difference?” A more sophisticated analysis would ask about the size of any difference. My experience from analysing data from these studies is that while a difference exists, it is often so small that it is of little practical interest.
The non-trivial number of papers containing effectively null results could easily be reduced by conferences and Journals requiring the authors of submitted papers to estimate the size of any claimed difference, i.e., use non-simplistic analysis techniques.
Github is an obvious place to mine for software engineering data; it offers a huge volume of code, along with many support tools and processes to mine it. When I tell people that I’m looking for software engineering data, Github is invariably their first suggestion. Jira repos are occasionally analysed, it’s a question of finding a selection that make their data public.
Github contains so much code, it’s hard to argue that it is not representative of a decent amount of industrial code. There’s lots of software data that is rarely publicly available on Github (e.g., schedules and estimates), but this is a separate issue.
I see Github being the primary site for mining software engineering related data for many years to come.
Software engineering research is a field of dots
Software engineering research is a field of dots; people are fully focused on publishing papers about their chosen tiny little subject.
Where are the books joining the dots into even a vague outline?
Several software researchers have told me that writing books is not a worthwhile investment of their time, i.e., the number of citations they are likely to attract makes writing papers the only cost-effective medium (books containing an edited collection of papers continue to be published).
Butterfly collecting has become the method of study for many researchers. The butterflies in question often being Github repos that are collected together, based on some ‘interestingness’ metric, and then compared and contrasted in a conference paper.
The dots being collected are influenced by the problems that granting agencies consider to be important topics to fund (picking a research problem that will attract funding is a major consideration for any researcher). Fake research is one consequence of incentivizing people to use particular techniques in their research.
Whatever you think the aims of research in software engineering might be, funding the random collecting of dots does not seem like an effective strategy.
Perhaps it is just a matter of waiting for the field to grow up. Evidence-based software engineering research is still a teenager, and the novelty of butterfly collecting has yet to wear off.
My study of particular kinds of dots did not reveal many higher level patterns, although a number of folk theories were shown to be unfounded.
What impact might my evidence-based book have in 2021?
What impact might the release of my evidence-based software engineering book have on software engineering in 2021?
Lots of people have seen the book. The release triggered a quarter of a million downloads, or rather it getting linked to on Twitter and Hacker News resulted in this quantity of downloads. Looking at the some of the comments on Hacker News, I suspect that many ‘readers’ did not progress much further than looking at the cover. Some have scanned through it expecting to find answers to a question that interests them, but all they found was disconnected results from a scattering of studies, i.e., the current state of the field.
The evidence that source code has a short and lonely existence is a gift to those seeking to save time/money by employing a quick and dirty approach to software development. Yes, there are some applications where a quick and dirty iterative approach is not a good idea (iterative as in, if we make enough money there will be a version 2), the software controlling aircraft landing wheels being an obvious example (if the wheels don’t deploy, telling the pilot to fly to another airport to see if they work there is not really an option).
There will be a few researchers who pick up an idea from something in the book, and run with it; I have had a couple of emails along this line, mostly from just starting out PhD students. It would be naive to think that lots of researchers will make any significant changes to their existing views on software engineering. Planck was correct to say that science advances one funeral at a time.
I’m hoping that the book will produce a significant improvement in the primitive statistical techniques currently used by many software researchers. At the moment some form of Wilcoxon test, invented in 1945, is the level of statistical sophistication wielded in most software engineering papers (that do any data analysis).
Software engineering research has the feeling of being a disjoint collection of results, and I’m hoping that a few people will be interested in starting to join the dots, i.e., making connections between findings from different studies. There are likely to be a limited number of major dot joinings, and so only a few dedicated people are needed to make it happen. Why hasn’t this happened yet? I think that many academics in computing departments are lifestyle researchers, moving from one project to the next, enjoying the lifestyle, with little interest in any research results once the grant money runs out (apart from trying to get others to cite it). Why do I think this? I have emailed many researchers information about the patterns I have found in the data they sent me, and a common response is almost completely disinterest (some were interested) in any connections to other work.
What impact do you think ‘all’ the evidence presented will have?
Software research is 200 years behind biology research
Evidence-based software research requires access to data, and Github has become the primary source of raw material for many (most?) researchers.
Parallels are starting to emerge between today’s researchers exploring Github and biologists exploring nature centuries ago.
Centuries ago scientific expeditions undertook difficult and hazardous journeys to various parts of the world, collecting and returning with many specimens which were housed and displayed in museums and botanical gardens. Researchers could then visit the museums and botanical gardens to study these specimens, without leaving the comforts of their home country. What is missing from these studies of collected specimens is information on the habitat in which they lived.
Github is a living museum of specimens that today’s researchers can study without leaving the comforts of their research environment. What is missing from these studies of collected specimens is information on the habitat in which the software was created.
Github researchers are starting the process of identifying and classifying specimens into species types, based on their defining characteristics, much like the botanist Carl_Linnaeus identified stamens as one of the defining characteristics of flowering plants. Some of the published work reads like the authors did some measurements, spotted some differences, and then invented a plausible story around what they had found. As a sometime inhabitant of this glasshouse I will refrain from throwing stones.
Zoologists study the animal kingdom, and entomologists specialize in the insect world, e.g., studying Butterflys. What name might be given to researchers who study software source code, and will there be specialists, e.g., those who study cryptocurrency projects?
The ecological definition of a biome, as the community of plants and animals that have common characteristics for the environment they exist in, maps to the end-user use of software systems. There does not appear to be a generic name for people who study the growth of plants and animals (or at least I cannot think of one).
There is only so much useful information that can be learned from studying specimens in museums, no matter how up to date the specimens are.
Studying the development and maintenance of software systems in the wild (i.e., dealing with the people who do it), requires researchers to forsake their creature comforts and undertake difficult and hazardous journeys into industry. While they are unlikely to experience any physical harm, there is a real risk that their egos will be seriously bruised.
I want to do what I can to prevent evidence-based software engineering from just being about mining Github. So I have a new policy for dealing with PhD/MSc student email requests for data (previously I did my best to point them at the data they sought). From now on, I will tell students that they need to behave like real researchers (e.g., Charles Darwin) who study software development in the wild. Charles Darwin is a great role model who should appeal to their sense of adventure (alternative suggestions welcome).
Recent Comments