Archive
Answering via a scale to improve estimation accuracy
The human brain differs from the brain of other animals in having two number processing systems: 1) the approximate number system (present in other animals), and 2) language.
Round numbers are often given in answers when using language, to questions having a numeric answer. While use of round numbers may be conversationally appropriate, they decrease the accuracy of the answer.
Numeric values can be specified without using language. For instance, by pointing at a position on a scale representing a sequence of increasing/decreasing values, such as a ruler. Are answers given by pointing at a scale less likely to be round numbers, and more importantly are they likely to be more accurate than answers given using language?
Various studies by psychologists have investigated response differences between answering using language and scales. The analysis below is based on data from the paper: On the round number bias and wisdom of crowds in different response formats for numerical estimation by Honda, Kagawa and Shirasuna. This study asked 1,805 subjects to estimate the number of dots in an image, like the one below, with images containing: 183, 287, 360, 453, 554, 633, 719, 807, or 986 dots (randomly selected):

Subjects responded using a randomly selected one of six different scales or using language (i.e., typing a number). The scales differed in axis labeling and some were zero based (subjects had to slide the blue colored circle from zero to a position, rather than clicking on a position); see image below:

The plot below shows the normalised occurrences of estimate values (rounded to the nearest value divisible by five) made using language (red) and one of the scales (blue/green), with grey line showing actual number of dots. There was little difference between the various kinds of scales, and all the scale answers have been aggregated (code+data):
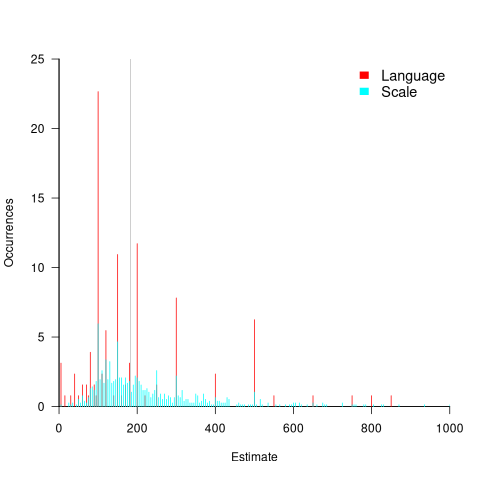
The red spikes clearly show many language given answers are at round numbers. The answers given using a scale are much less likely to be round numbers, with the blue/green lines showing the use of a wider selection of estimates.
Are answers given using language likely to be more or less accurate than answer given using a scale?
The plot above shows that few responses are close to the actual value, which means that no fitted model is going to explain much of the variability in the data. All the regression models I fitted to the difference between answers and actuals found that languages responses were less accurate, on average (code+data). Combining the explanatory variables in a variety of different ways did not significantly affect the quality of the fitted model.
In hand-wavy terms, the average error in the language responses was at most 10% larger than the scale responses.
To summaries, scale responses are likely to be more accurate, but a lot less likely to be a round number.
People are willing to tradeoff accuracy for being able to communicate using a round number. For instance, I once pointed out to a manager that changing all 1-hour estimates to 1.25 hours would significantly improve accuracy; he was unwilling to give up the greater uncertainty implied by the 1-hour estimate.
Will this behavior replicate for software task estimates? Is it possible to shift a scale answer to the closest round number without losing the accuracy advantage?
We will have to wait until somebody does the appropriate study.
Identifier names chosen to hold the same information
Identifier naming is a contentious issue dominated by opinions and existing habits, with almost no experimental evidence (rather like software engineering practices in general).
One study found that around 40% of all non-white-space characters in the visible source of C programs are identifiers (comments representing 31% of the characters in the .c files), representing 29% of the visible tokens in the .c files.
Some years ago I spent a long time studying the word related experiments run by psychologists, looking for possible parallels with identifier usage. The crucial identifier naming factor is the semantic associations a name triggers in the reader’s mind. Choosing a name requires making a cost-benefit tradeoff. The greater quantity of information that might be communicated by longer names has to be balanced against both the cost of reading the name and ignoring the name when searching for other information.
The semantic association network present in a person’s head is the result of the words they have encountered and the context in which they were encountered. Different people are likely to make different associations. Shared culture and experiences increases the likelihood of shared naming associations.
A study by Nelson, McEvoy, and Schreiber gave subjects (over time, 6,000 students at the University of South Florida) a booklet containing 100 words, and asked them to write down the first word that came to mind that was meaningfully related or strongly associated to each of these words (data here, a total of 612,627 responses to 5,024 distinct words). The mean number of different responses to the same word was 14.4, with a standard deviation of 5.2.
There are patterns in the names of identifiers. For instance, operands of bitwise and logical operators have names that include words whose semantics is associated with the operations usually performed by these operands, such as: flag, status, state, and mask. One experiment (with a small sample size) found that developers make use of operand names to make operator precedence decisions.
A study by Feitelson, Mizrahi, Noy, Shabat, Eliyahu, and Sheffer, investigated the variable names chosen by developers to hold specific information. The 334 subjects (students and professional developers) were asked to suggest a name for a variable, constant, or data structure based on a description of the information it would contain, plus other questions relating to interpreting the semantics associated with a name.
The authors cite a problem that I think is actually a benefit: “A major problem in studying spontaneous naming is that the description of the context and the question itself necessarily use words.” When writing code a well-chosen name communications information about the context, which helps readers understand what is going on. The authors’ solution to this perceived problem was to give the description in either Hebrew or English (the subjects were native Hebrew speakers who are fluent in English), with subjects providing the name in English.
The answers to the 21 name generation questions had a mean of 53 distinct names (standard deviation 20.2; code and data). The table below shows the names chosen and the number of subjects choosing that name after seeing the description in Hebrew or English, for one of the questions.
Name Hebrew English b_elevator_door_state 1 b_is_door_open 1 curr_state 2 current_doors_state 1 door 3 1 door_current_status 1 door_is_closed 1 door_is_open 1 door_open 3 door_stat 1 door_state 10 12 door_status 4 doorstate 1 1 elevator_door_state 1 1 elevator_state 1 is_closed 1 1 is_door_closed 2 1 is_door_open 11 3 is_door_opened 2 2 is_elevator_open 1 is_o_pen 1 is_open 7 5 is_opened 2 state 1 status 1 status_of_door 1 |
While the names are distinct, some only differ by a permutation of words, e.g., door_is_open and is_door_open, or with one word missing, e.g., door_open and is_open, or two words missing, e.g., door.
If subjects are influenced by the description (e.g., using the word ordering that appears in the description, or only words from the description), the number of unique names would be smaller than if there was no such influence. The impact of influence would be that subjects seeing the English descriptions are likely to produce fewer unique names.
In 13 out of 21 questions, Hebrew subjects produced more unique names. However, a bootstrap test shows that the difference is not statistically significant.
I think a big threat to the validity of the study is only having subjects create one name. Writing software involves creating names for many variables, which has different cost-benefit tradeoffs than when creating a single variable. The names within a program share a common context and developers tend to follow informal patterns so that naming within the code has some degree of consistency. Adhering to these patterns restricts the possible set of names that might be chosen. Also, the existing use of a name may prevent it being reused for a new variable.
Programming competitions are one source for variable names implementing the same specification, at least for short program. Longer programs are more likely to have some variation in the algorithms used to implement the same functionality.
I expect greater consistency of identifier name selection within an LLM than across developers. LLM training will direct them down existing common patterns of usage, plus some random component.
Learning useful stuff from the Human cognition chapter of my book
What useful, practical things might professional software developers learn from the Human cognition chapter in my evidence-based software engineering book (an updated beta was release this week)?
Last week I checked the human cognition chapter; what useful things did I learn (combined with everything I learned during all the other weeks spent working on this chapter)?
I had spent a lot of time of learning about cognition when writing my C book; for this chapter I was catching up on what had happened in the last 10 years, which included: building executable models has become more popular, sample size has gotten larger (mostly thanks to Mechanical Turk), more researchers are making their data available on the web, and a few new theories (but mostly refinements of existing ideas).
Software is created by people, and it always seemed obvious to me that human cognition was a major topic in software engineering. But most researchers in computing departments joined the field because of their interest in maths, computers or software. The lack of interested in the human element means that the topic is rarely a research topic. There is a psychology of programming interest group, but most of those involved don’t appear to have read any psychology text books (I went to a couple of their annual workshops, and while writing the C book I was active on their mailing list for a few years).
What might readers learn from the chapter?
Visual processing: the rationale given for many code layout recommendations is plain daft; people need to learn something about how the brain processes images.
Models of reading. Existing readability claims are a joke (or bad marketing, take your pick). Researchers have been using eye trackers, since the 1960s, to figure out what actually happens when people read text, and various models have been built. Market researchers have been using eye trackers for decades to work out where best to place products on shelves, to maximise sales. In the last 10 years software researchers have started using eye trackers to study how people read code; next they need to learn about some of the existing models of how people read text. This chapter contains some handy discussion and references.
Learning and forgetting: it takes time to become proficient; going on a course is the start of the learning process, not the end.
One practical take away for readers of this chapter is being able to give good reasons how other people’s proposals, that are claimed to be based on how the brain operates, won’t work as claimed because that is not how the brain works. Actually, most of the time it is not possible to figure out whether something will work as advertised (this is why user interface testing is such a prolonged, and expensive, process), but the speaker with the most convincing techno-babble often wins the argument 🙂
Readers might have a completely different learning experience from reading the human cognition chapter. What useful things did you learn from the human cognition chapter?
Recent Comments