Archive
Answering via a scale to improve estimation accuracy
The human brain differs from the brain of other animals in having two number processing systems: 1) the approximate number system (present in other animals), and 2) language.
Round numbers are often given in answers when using language, to questions having a numeric answer. While use of round numbers may be conversationally appropriate, they decrease the accuracy of the answer.
Numeric values can be specified without using language. For instance, by pointing at a position on a scale representing a sequence of increasing/decreasing values, such as a ruler. Are answers given by pointing at a scale less likely to be round numbers, and more importantly are they likely to be more accurate than answers given using language?
Various studies by psychologists have investigated response differences between answering using language and scales. The analysis below is based on data from the paper: On the round number bias and wisdom of crowds in different response formats for numerical estimation by Honda, Kagawa and Shirasuna. This study asked 1,805 subjects to estimate the number of dots in an image, like the one below, with images containing: 183, 287, 360, 453, 554, 633, 719, 807, or 986 dots (randomly selected):

Subjects responded using a randomly selected one of six different scales or using language (i.e., typing a number). The scales differed in axis labeling and some were zero based (subjects had to slide the blue colored circle from zero to a position, rather than clicking on a position); see image below:

The plot below shows the normalised occurrences of estimate values (rounded to the nearest value divisible by five) made using language (red) and one of the scales (blue/green), with grey line showing actual number of dots. There was little difference between the various kinds of scales, and all the scale answers have been aggregated (code+data):
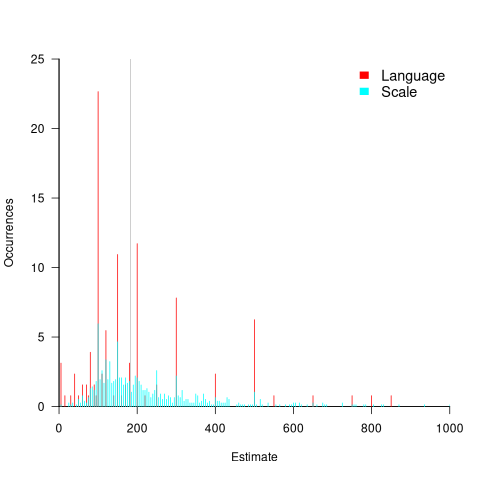
The red spikes clearly show many language given answers are at round numbers. The answers given using a scale are much less likely to be round numbers, with the blue/green lines showing the use of a wider selection of estimates.
Are answers given using language likely to be more or less accurate than answer given using a scale?
The plot above shows that few responses are close to the actual value, which means that no fitted model is going to explain much of the variability in the data. All the regression models I fitted to the difference between answers and actuals found that languages responses were less accurate, on average (code+data). Combining the explanatory variables in a variety of different ways did not significantly affect the quality of the fitted model.
In hand-wavy terms, the average error in the language responses was at most 10% larger than the scale responses.
To summaries, scale responses are likely to be more accurate, but a lot less likely to be a round number.
People are willing to tradeoff accuracy for being able to communicate using a round number. For instance, I once pointed out to a manager that changing all 1-hour estimates to 1.25 hours would significantly improve accuracy; he was unwilling to give up the greater uncertainty implied by the 1-hour estimate.
Will this behavior replicate for software task estimates? Is it possible to shift a scale answer to the closest round number without losing the accuracy advantage?
We will have to wait until somebody does the appropriate study.
Early research on economies of scale for computer systems
Before microprocessor cost/performance wiped out (in the early 1990s) other cpu platforms (e.g., mainframes and minis), people argued that computer hardware benefited from economies of scale.
The claimed benefit was more bang for the buck, i.e., more compute for less money.
Checking this claim requires treating pre-microprocessor computer systems and the later microprocessor-based systems as two separate cases, because many of the factors driving costs and performance are very different.
Today’s large microprocessor-based computer systems achieve economies of scale through discounts from bulk purchases and spreading fixed costs across multiple systems. The data is available, and the economic analysis is straight forward.
A lack of reliable data on the costs of designing/building pre-microprocessor computer systems rules out an economic analysis of cost/performance from first principles. The data that was/is available is the cost of computer systems and some indicators of performance (such as instruction timings or benchmarks).
Now, the observed fact that the cost of compute was decreasing over time is unrelated to the claim that the cost of compute decreases as the size of the computer increases.
Assuming a power law relationship between computer cost,  , and size,
, and size,  , at a point in time, we have:
, at a point in time, we have:  , where
, where  is some constant. Economies of scale occur when:
is some constant. Economies of scale occur when: 
In his detailed cost/performance analysis of computers between 1944-1967, Kenneth Knight treated computers launched in the same year as effectively occurring at the same time. He also built a single model, with year included as an explanatory variable, which means the fitted rate of decrease is the same over all years (rather than varying between years).
The plot below uses Knight’s 1953-1961 data, and shows operations per second against seconds per dollar (a confusing combination, but what Knight used), with fitted regression lines for three years using Knight’s model (code and data)
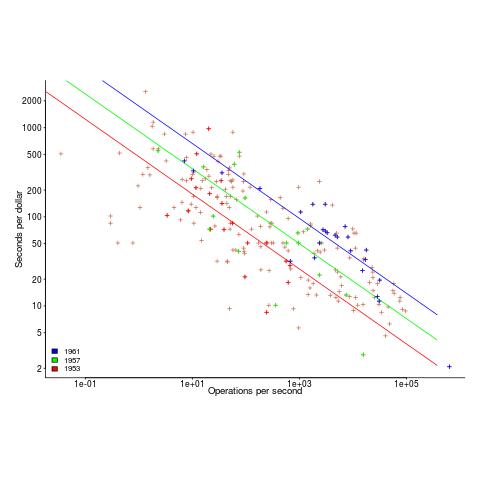
The fitted exponent for this form of x/y axis maps to a value which has , i.e., there are economies of scale.
It so happens that the value of the Knight’s fitted exponent is close to that proposed in a 1953 paper (“High speed arithmetic: The digital computer as a research tool”, no online copy):
It used to cost one cent to do a multiplication on a desk calculator; now it is more like four cents; but with these big machines we can do a million in an hour for $400, and that means twenty-five multiplications for a cent! I believe that there is a fundamental rule, which I modestly call Grosch's law, giving added economy only as the square root of the increase in speed-that is, to do a calculation ten times as cheaply you must do it one hundred times as fast. |
which did indeed become widely known as Grosch’s law.
Having been given a lucky kick-start by Knight (fitted individually, years are not close to Grosch’s law), checking for agreement with Grosch’s law became a focus for later studies. While various papers highlighted problems with the later data analysis (e.g., the regression techniques and sample noise producing mathematical artifacts), Grosch’s law ceased being a thing because mainframes/minicomputers ceased being a thing.
Did mainframe/mincomputers have economies of scale in the years after Knight’s data? It’s difficult to tell, the publicly available data is too sparse to support reliable analysis.
Recent Comments