Archive
Identifier names chosen to hold the same information
Identifier naming is a contentious issue dominated by opinions and existing habits, with almost no experimental evidence (rather like software engineering practices in general).
One study found that around 40% of all non-white-space characters in the visible source of C programs are identifiers (comments representing 31% of the characters in the .c files), representing 29% of the visible tokens in the .c files.
Some years ago I spent a long time studying the word related experiments run by psychologists, looking for possible parallels with identifier usage. The crucial identifier naming factor is the semantic associations a name triggers in the reader’s mind. Choosing a name requires making a cost-benefit tradeoff. The greater quantity of information that might be communicated by longer names has to be balanced against both the cost of reading the name and ignoring the name when searching for other information.
The semantic association network present in a person’s head is the result of the words they have encountered and the context in which they were encountered. Different people are likely to make different associations. Shared culture and experiences increases the likelihood of shared naming associations.
A study by Nelson, McEvoy, and Schreiber gave subjects (over time, 6,000 students at the University of South Florida) a booklet containing 100 words, and asked them to write down the first word that came to mind that was meaningfully related or strongly associated to each of these words (data here, a total of 612,627 responses to 5,024 distinct words). The mean number of different responses to the same word was 14.4, with a standard deviation of 5.2.
There are patterns in the names of identifiers. For instance, operands of bitwise and logical operators have names that include words whose semantics is associated with the operations usually performed by these operands, such as: flag, status, state, and mask. One experiment (with a small sample size) found that developers make use of operand names to make operator precedence decisions.
A study by Feitelson, Mizrahi, Noy, Shabat, Eliyahu, and Sheffer, investigated the variable names chosen by developers to hold specific information. The 334 subjects (students and professional developers) were asked to suggest a name for a variable, constant, or data structure based on a description of the information it would contain, plus other questions relating to interpreting the semantics associated with a name.
The authors cite a problem that I think is actually a benefit: “A major problem in studying spontaneous naming is that the description of the context and the question itself necessarily use words.” When writing code a well-chosen name communications information about the context, which helps readers understand what is going on. The authors’ solution to this perceived problem was to give the description in either Hebrew or English (the subjects were native Hebrew speakers who are fluent in English), with subjects providing the name in English.
The answers to the 21 name generation questions had a mean of 53 distinct names (standard deviation 20.2; code and data). The table below shows the names chosen and the number of subjects choosing that name after seeing the description in Hebrew or English, for one of the questions.
Name Hebrew English b_elevator_door_state 1 b_is_door_open 1 curr_state 2 current_doors_state 1 door 3 1 door_current_status 1 door_is_closed 1 door_is_open 1 door_open 3 door_stat 1 door_state 10 12 door_status 4 doorstate 1 1 elevator_door_state 1 1 elevator_state 1 is_closed 1 1 is_door_closed 2 1 is_door_open 11 3 is_door_opened 2 2 is_elevator_open 1 is_o_pen 1 is_open 7 5 is_opened 2 state 1 status 1 status_of_door 1 |
While the names are distinct, some only differ by a permutation of words, e.g., door_is_open and is_door_open, or with one word missing, e.g., door_open and is_open, or two words missing, e.g., door.
If subjects are influenced by the description (e.g., using the word ordering that appears in the description, or only words from the description), the number of unique names would be smaller than if there was no such influence. The impact of influence would be that subjects seeing the English descriptions are likely to produce fewer unique names.
In 13 out of 21 questions, Hebrew subjects produced more unique names. However, a bootstrap test shows that the difference is not statistically significant.
I think a big threat to the validity of the study is only having subjects create one name. Writing software involves creating names for many variables, which has different cost-benefit tradeoffs than when creating a single variable. The names within a program share a common context and developers tend to follow informal patterns so that naming within the code has some degree of consistency. Adhering to these patterns restricts the possible set of names that might be chosen. Also, the existing use of a name may prevent it being reused for a new variable.
Programming competitions are one source for variable names implementing the same specification, at least for short program. Longer programs are more likely to have some variation in the algorithms used to implement the same functionality.
I expect greater consistency of identifier name selection within an LLM than across developers. LLM training will direct them down existing common patterns of usage, plus some random component.
Distribution of integer literals in text/speech and source code
Numeric values are an integral to communication between people. What is the distribution of integer values in text/speech, and does the use of integer literals in source code have a similar distribution?
- The paper Numbers in Context: Cardinals, Ordinals, and Nominals in American English by Greg Woodin, and Bodo Winter studied the 9+ million numbers contained in the Corpus of Contemporary American English (7,744,038 integer values). The plot below shows the number of occurrences of the smaller integer values, and a fitted regression line for values in the range 1..50 (code+data):

The frequency of integer values in this corpus is proportional to:
 .
. - The paper Frequency of occurrence of numbers in the World Wide Web by Dorogovtsev, Mendes, and Gama Oliveira found that the number of web pages containing a given integer value declines as the value increases, with the decline for non-round numbers being roughly proportional to
 (round numbers are much more frequent than adjacent values and bias fitted models), and including all values gives
(round numbers are much more frequent than adjacent values and bias fitted models), and including all values gives  (for values up to
(for values up to  ).
).
Programs are an implementation of a sliver of the world in which people live, and it is to be expected that the frequency of numeric literal values in source code is highly correlated with real world frequency. Numeric values also appear in the algorithms and mathematical expressions used to create implementations. I am not aware of any studies looking at the frequency of use of numeric constants in algorithms and mathematics. As an aside, the frequency of occurrence of mathematical expressions containing a given number of operators is similar to that in C source
What are the usage characteristics of integer literals in source code (floating-point literal use is very rare outside of particular application domains)?
The plot below shows occurrences of decimal (green) and hexadecimal (blue) literals in C source (data from fig 825.1 from my C book) with a regression line fitted to values 1..50 of the decimal data (code+data):

The frequency of decimal literal values in C source is proportional to: . Adding the hexadecimal values to the model has little effect.
The paper What do developers consider magic literals? A smalltalk perspective by Anquetil, Delplanque, Ducasse, Zaitsev, Fuhrman, and Guéhéneuc studied the use of literals in Smalltalk. The plot below shows the number of occurrences of all kinds of integer literals and a fitted regression line (code+data):

The frequency of integer literal values in Smalltalk source is proportional to:  .
.
The distribution of integer literals in both human communication and source code is well-fitted by a power law. Smalltalk appears to be the outlier, with an exponent of 1.7 vs 1.3-1.4. Perhaps it’s a sample size issue; 14,054 integer literals for Smalltalk and a million+ for the other datasets.
I had expected source code to contain a lot more zeroes/ones, relative to other values, than human communication. Zero/one are such common values that there are implicit short-cuts that people can use to express them; removing the effort/cost needed to explicitly specify them. Some programming languages specify default 0/1 values for common idioms, but C-like languages generally require explicit specification of values.
Maximum team size before progress begins to stall
On multi-person projects people have to talk to each other, which reduces the amount of time available for directly working on writing software. How many people can be added to a project before the extra communications overhead is such that the total amount of code, per unit time, produced by the team decreases?
A rarely cited paper by Robert Tausworthe provides a simple, but effective analysis.
The plot below shows team productivity rate for a given number of team sizes, based on the examples discussed below.
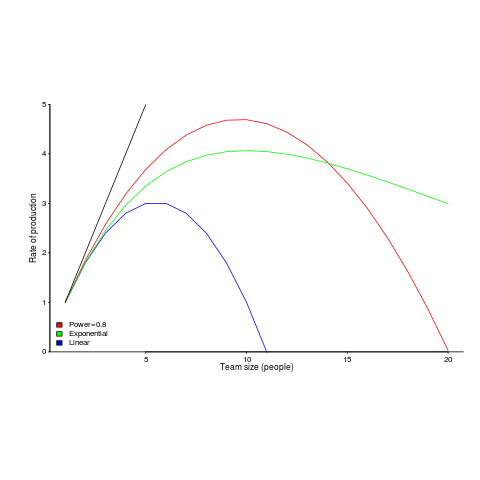
Activities are split between communicating and producing code.
If we assume the communications overhead is give by: ") , where
, where  is the percentage of one person’s time spent communicating in a two-person team,
is the percentage of one person’s time spent communicating in a two-person team,  the number of developers and
the number of developers and  a constant greater than zero (I’m using Tausworthe’s notation).
a constant greater than zero (I’m using Tausworthe’s notation).
The maximum team size, before adding people reduces total output, is given by: t_0})^{1/{alpha}}") .
.
If  (i.e., everybody on the project has the same communications overhead), then
(i.e., everybody on the project has the same communications overhead), then  , which for small is approximately
, which for small is approximately  . For example, if everybody on a team spends 10% of their time communicating with every other team member:
. For example, if everybody on a team spends 10% of their time communicating with every other team member:  .
.
In this team of five, 50% of each persons time will be spent communicating.
If  , then we have
, then we have *0.1})^{1/0.8}approx 10") .
.
What if the percentage of time a person spends communicating with other team members has an exponential distribution? That is, they spend most of their time communicating with a few people and very little with the rest; the (normalised) communications overhead is: t_1}") , where
, where  is a constant found by fitting data from the two-person team (before any more people are added to the team).
is a constant found by fitting data from the two-person team (before any more people are added to the team).
The maximum team size is now given by:  , and if
, and if  , then:
, then:  .
.
In this team of ten, 63% of each persons time will be spent communicating (team size can be bigger, but each member will spend more time communicating compared to the linear overhead case).
Having done this analysis, what is now needed is some data on the distribution of individual communications overhead. Is the distribution linear, square-root, exponential? I am not aware of any such data (there is a chance I have encountered something close and not appreciated its importance).
I have only every worked on relatively small teams, and am inclined towards the distribution of time spent communicating not being constant. Was it exponential or a power-law? I would not like to say.
Could a communications time distribution be reverse engineered from email logs? The cc’ing of people who might have an interest in a topic complicates the data analysis; time spent in meetings are another complication.
Pointers to data most welcome and as is any alternative analysis using data likely to have a higher signal/noise ratio.
Recent Comments