Archive
Projects are worked on in fits and starts
Companies whose business is designing, developing, and maintaining custom software applications (i.e., a software house) have the difficult job of keeping their expensive employees busy with paying work. Work on an existing project may be held up for various reasons, and the start date of new projects is invariably uncertain.
A solution to the on/off nature of project work is for staff to distribute their time across multiple projects. If one project is held up, there is another project available for them to book their time to.
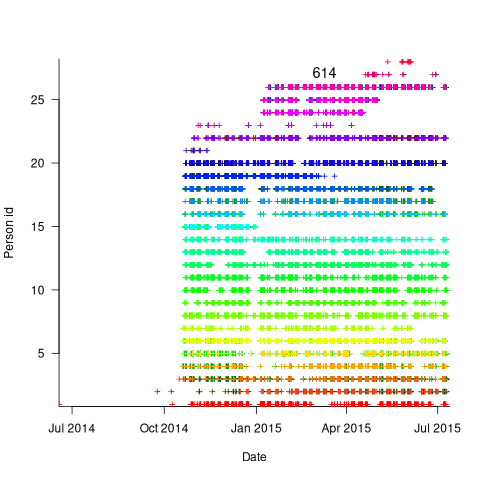
The plot below is for project 614 in the CESAW dataset, and shows the days on which 28 people worked on this project between July 2014 and July (code+data):
The published models of the software development lifecycle are based on perceptions of the workings of large DOD and NASA projects from the 1960s and 1970s. These projects are treated as self-contained entities, with people being available when needed and individually interchangeable. This perception fits with the software physics thinking of the time, along with the early 1960s work of Norden, and the use of differential equations to model the evolution of project manpower. These models fitted the small amount of available data as well as several other models. With some hand waving it is possible to make models such as the Putnam model look good.
With 28 people working on project 614, it’s possible that individual contributions don’t have a big impact on totals, i.e., the total time spent per week (say) does not fluctuate widely. The plot below shows the total hours per week spent on design, coding and test (total project time as roughly three staff years; code+data):
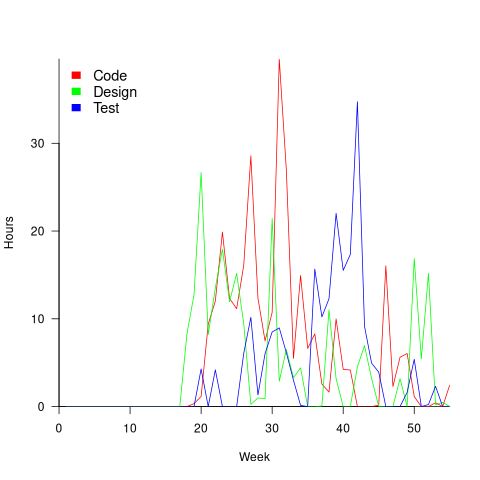
Plenty of wide fluctuations, plus some expected large drops in time spent on the project. For instance, a big drop in all activities around Christmas, and a smaller dip around Thanksgiving.
Having 28 people work on a three-person year project does seem a bit extreme (average of seven-weeks per person). On the other hand, I may be out of date, not having been a team member on a large project in decades.
The total effort required by the projects in the CESAW dataset range from three-person months to three-person years, which I suspect (no data on this question) straddles the range of time spent on the majority of software projects. The projects mostly involve people spending a non-large percentage of time on a project. The data is anonymised on a project basis, and it is not possible to count the number of projects a person is working on at any time.
To summarise: Building a good enough model of software project staffing requires taking into account organization wide staffing priorities. Existing models don’t do this.
Estimating Open source project lifecycle using the Bass model
Is it possible to reliably estimate the elapsed time that a multi-person Open source project spends under major active development, once it has been running for a year or so, and attracted some developers?
The paper Project Life Cycles in Open-Source Software by Das, Ieroshenko, Jain, Qiu, Chin, and Granger fits a Bass diffusion model to the number of monthly developers contributing to a project, and then extrapolates the fitted equation into the future. Is the Bass model a good fit to this kind of data, and how reliable might its prediction be?
What first caught my attention in this paper was the appearance of the sech function (i.e., the hyperbolic secant:  ) in the derived formula. The only other place I have encountered this function in software engineering is the Parr model of project staffing distribution, e.g., effort in hours per week. What’s more, both instances involve
) in the derived formula. The only other place I have encountered this function in software engineering is the Parr model of project staffing distribution, e.g., effort in hours per week. What’s more, both instances involve sech squared, i.e.,  .
.
Is this use of a coincidence, or is there an interesting connection? Let’s look at the paper.
The Bass diffusion model, or just Bass model, assumes that the number of people buying a new product is controlled by two factors: 1) independents who have a constant probability,  , of buying it, and 2) imitators whose probability of purchase depends on
, of buying it, and 2) imitators whose probability of purchase depends on  times the number of existing users of the product (see section 3.6.3 of my book). The Bass model has been extended to handle successive, overlapping generations of a product, e.g., IBM mainframes.
times the number of existing users of the product (see section 3.6.3 of my book). The Bass model has been extended to handle successive, overlapping generations of a product, e.g., IBM mainframes.
I have not seen the Bass model applied to software lifecycles before (a quick search found a 2014 paper using it to model the time-evolution of package dependencies).
The authors of the new paper introduced sech by normalising two variables in the Bass equation: ^2e^{(p+q)t}}/{(pe^{(p+q)t}+q)^2}")
Time,  is normalised by dividing by time of peak development,
is normalised by dividing by time of peak development,  , and number of developers,
, and number of developers,  , is normalised by dividing by peak number of developers,
, is normalised by dividing by peak number of developers,  , giving:
, giving:
)") , where
, where ") , and
, and  . It’s not possible to fit this equation to project data because the peak development values are not known (or might not yet have been reached).
. It’s not possible to fit this equation to project data because the peak development values are not known (or might not yet have been reached).
The equation in the Parr model is: ") , where the values of
, where the values of  and
and  are obtained by fitting a regression model to project data. The derivation of the Parr model assumes that as project implementation progresses, new problems that need to be solved are discovered (e.g., features to be implemented), an existing problem can spawn at most two new subproblems, and the number of new problems discovered at any time is proportional to the number of remaining problems (cannot find an online version of “An alternative to the Rayleigh curve model for software development effort”).
are obtained by fitting a regression model to project data. The derivation of the Parr model assumes that as project implementation progresses, new problems that need to be solved are discovered (e.g., features to be implemented), an existing problem can spawn at most two new subproblems, and the number of new problems discovered at any time is proportional to the number of remaining problems (cannot find an online version of “An alternative to the Rayleigh curve model for software development effort”).
A connection can be made between the Bass and Parr models by equating the number of developers contributing with the number of problems to be solved, with contributors treated as independents or imitators. The opportunities for potential contributors are likely to increase as a project starts up and then, for some projects decrease (projects such as the Linux kernel just keep on going). The problem implemented by a developer could spawn more than two subproblems.
In practice most of the implementation work on an Open source project is done by a small percentage of developers, with some projects dieing after loosing a few core developers. There is also the issue of the same person contributing using multiple identities.
One method for checking how well a model predicts future measurements is to compare the equations fitted using all the monthly data and, say, the first 75% months. The extent to which both fitted equations agree provides an indication of the likely accuracy of currently unknown future values. The Das et al paper fits the Bass model to the monthly contributor data from 23 projects. The plot below shows the number of monthly developers for numpy (since the project started), along with two fitted Bass models, one for all the data and the other for the first 75% of the data (code+data):
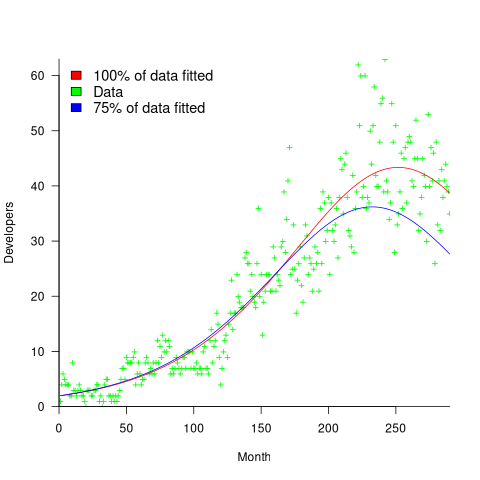
The example project used in the paper has a closer agreement between the two fitted equations, and some of the other projects have much less agreement. The Bass models assumes that monthly contributions are primarily driven by two factors. In practice there could be many other factors driving developer involvement in a project.
Predicting when a project is likely to stop growing is a notoriously difficult problem. Fitting a logistic equation to the growth in lines of code is another example of a model fitting the pattern present in the underlying equation (which flattens off).
It’s possible that weighting developer contribution by the amount of functionality (not lines of code) will produce a closer agreement between theory and practice.
The Putnam project staffing model predates the Parr mode, and later research found that the Putnam model was also a poor predictor of project durations. Both the Parr and Putnam equations can be derived using hazard analysis.
Applying the Bass multi-product generation model to software evolution is now on my to-do list, e.g., use of PHP versions.
Career progression: an invisible issue in software development
Career progression is an important issue in the development of some software systems, but its impact is rarely discussed, let along researched. A common consequence of career progression is that a project looses a member of staff, e.g., they move to work on a different project, or leave the company. Hiring staff and promoting staff are related neglected research areas.
Understanding the initial and ongoing development of non-trivial software systems requires an understanding of the career progression, and expectations of progression, of the people working on the system.
Effectively working on a software system requires some amount of knowledge of how it operates, or is intended to operate. The loss of a person with working knowledge of a system reduces the rate at which a project can be further developed. It takes time to find a suitable replacement, and for that person’s knowledge of the behavior of the existing system to reach a workable level.
We know that most software is short-lived, but know almost nothing about the involvement-lifetime of those who work on software systems.
There has been some research studying the durations over which people have been involved with individual Open source projects. However, I don’t believe the findings from this research, because I think that non-paid involvement on an Open source project has very different duration and motivation characteristics than a paying job (there are also data cleaning issues around the same person using multiple email addresses, and people working in small groups with one person submitting code).
Detailed employment data, in bulk, has commercial value, and so is rarely freely available. It is possible to scrape data from the adverts of job websites, but this only provides information about the kinds of jobs available, not the people employed.
LinkedIn contains lots of detailed employment history, and the US courts have ruled that it is not illegal to scrape this data. It’s on my list of things to do, and I keep an eye out for others making such data available.
The National Longitudinal Survey of Youth has followed the lives of 10k+ people since 1979 (people were asked to detail their lives in periodic surveys). Using this data, Joseph, Boh, Ang, and Slaughter investigated the job categories within the career paths of 500 people who had worked in a technical IT role. The plot below shows the career paths of people who had spent at least five years working in an IT role (code+data):

Employment history provides an upper bound for the time that a person is likely to have worked on a project (being employed to work on an Open source project while, over time, working at multiple companies is an edge case).
A company may have employees simultaneously working on multiple projects, spending a percentage of their time on each. How big a resource impact is the loss of such a person? Were they simply the same kind of cog in multiple projects, or did they play an important synchronization role across projects? Details on all the projects a person worked on would help answer some questions.
Building a software system involves a lot more than writing the code. Technical managers working on high level, broad brush, issues. The project knowledge that technical managers have contributes to ongoing work, and the impact of loosing a technical manager is probably more of a longer term issue than loosing a coding-developer.
There are systems that are developed and maintained by essentially one person over many years. These get written about and celebrated, but are comparatively rare.
One of the more reliable ways of estimating developer productivity is to measure the impact of them leaving a project.
How to avoid being a victim of Brooks’ law
The oft cited book The Mythical Man Month contains a statement that has become known as Brooks’ Law: “Adding manpower to a late software project makes it later”.
When people join a project they need to learn project specific information, this is information that can only be obtained from people already working on the project. Training up new staff (e.g., developers, documentation writers) reduces the amount of effort being directly invested in building the system; it is an investment in people whose benefit is the post-training productivity of those people adding their effort to the project.
Let’s assume that a newbie diverts from the project they are joining an amount of effort units of time,  , in training without contributing anything, and that this training/investment lasts for
, in training without contributing anything, and that this training/investment lasts for  units of time after which the trained person contributes an average of
units of time after which the trained person contributes an average of  of effort per unit of time until the project deadline. This investment in a newbie will cause the project to be delayed unless the following inequality holds:
of effort per unit of time until the project deadline. This investment in a newbie will cause the project to be delayed unless the following inequality holds:
 + (E_a+E_n)(D_r-D_t) gt E_a D_r")

where  is the average daily project effort available before a newbie joins and
is the average daily project effort available before a newbie joins and  is the number of units of time between the start of training and the delivery date/time.
is the number of units of time between the start of training and the delivery date/time.
This simplifies to:

an equation that makes the obvious point that as the deadline approaches the amount of time and effort spent training newbies needs to decrease if a worthwhile payback is to be achieved in the available time.
The quantity  is the amount of time remaining after the newbie finishes training (in practice this is rarely a well defined point in time, but let’s keep things simple) and is the only easily obtained information in the equation.
is the amount of time remaining after the newbie finishes training (in practice this is rarely a well defined point in time, but let’s keep things simple) and is the only easily obtained information in the equation.
The effort contribution of the newbie, , could be approximated using information on the effort contribution of other people doing a similar job on the project. At least it could be if data was available on what their effort contribution was, and we overlooked the possible 5:1 difference in performance found between software developers. In practice a newbie’s effort contribution ramps up from zero, perhaps even starting during the training period, to a relatively constant long term daily average. How long does it take for to reach the long term average? I have no idea.
How much effort, , goes into training a newbie? A very important factor will obviously be their existing level of expertise with the application domain, tools being used, coding skills, etc (pretty much everything was new, back in the day, for the project analysed by Brooks, so was probably very high). There is also the somewhat nebulous but very important ability, or lack of, to pick things up quickly.
Could data on be obtained by recording every encounter the newbie has with existing project members? This would certainly enable information on first order time interactions to be obtained, but it would not tell us anything about the knock on effects caused by the work of an existing project member being delayed because they were investing in the newbie.
If many people are being added to a project at the same time it is easy to imagine it grinding to a halt because of all the minor congestion that occurs within the network of dependencies that project progress is waiting on.
I have not been able to locate any applicable data relating to training on software development projects, but then this area is at the edge of what I know about. Pointers to data most welcome.
Recent Comments