Archive
Investigating an LLM generated C compiler
Spending over $20,000 on API calls, a team at Anthropic plus an LLM (Claude Opus version 4.6) wrote a C compiler capable of compiling the Linux kernel and other programs to a variety of cpus. Has Anthropic commercialised monkeys typing on keyboards, or have they created an effective sheep herder?
First of all, does this compiler handle a non-trivial amount of the C language?
Having written a variety of industrial compiler front ends, optimizers, code generators and code analysers (which paid off the mortgage on my house), along with a book that analysed of the C Standard, sentence by sentence (download the pdf), I’m used to finding my way around compilers.
Claude’s C compiler source appears to be surprisingly well written/organised (based on a few hours reading of the code). My immediate thought was that this must be regurgitation of pieces from existing compilers. Searches for a selection of comments in the source failed to find any matches. Stylistically, the code is written by an entity that totally believes in using abstractions; functions call functions that call functions, that call …, eventually arriving at a leaf function that just assigns a value. Not at all like a human C compiler writer (well, apart from this one).
There are some oddities in an implementation of this (small) size. For instance, constant folding includes support for floating-point literals. Use of floating-point is uncommon, and opportunities to fold literals rare. Perhaps this support was included because, well, an LLM did the work. But it increases the amount of code that can be incorrect, for little benefit. When writing a compiler in an implementation language different from the one being compiled, differences between the two languages can have an impact. For instance, Claude C uses Rust’s 128-bit integer type during constant folding, despite this and most other C compilers only supporting at most 64-bit integer types.
A README appears in each of the 32 source directories, giving a detailed overview of the design and implementation of the activities performed by the code. The average length is 560 lines. These READMEs look like edited versions of the prompts used.
To get a sense of how the compiler handled rarely used language features and corner cases, I fed it examples from my book (code). The Complex floating point type is supported, along with Universal Character Names, fiddly scoping rules, and preprocessor oddities. This compiler is certainly non-trivial.
The compiler’s major blind spot is failing to detect many semantic constraints, e.g., performing arithmetic on variables having a struct type, or multiple declarations of functions and variables with the same name in the same scope (the parser README says “No type checking during parsing”; no type checking would be more accurate). The training data is source code that compiles to machine code, i.e., does not contain any semantic errors that a compiler is required to flag. It’s not surprising that Claude C fails to detect many semantic errors. There is a freely available collection of tests for the 80 constraint clauses in the C Standard that can be integrated into the Claude C compiler test suite, including the prompts used to generate the tests.
A compiler is an information conveyor belt. Source is first split into tokens (based on language specific rules), which are parsed to build a tree representation and a symbol table, which is then converted to SSA form so that a sequence of established algorithms can be used to lower the level of abstraction and detect common optimizations patterns, the low-level representation is mapped to machine code, and written to a file in the format for an executable program.
The prompts used to orchestrate the information processing conveyor belt have not been released. I’m guessing that the human team prompted the LLM with a detailed specification of the interfaces between each phase of the compiler.
The compiler is implemented in Rust, the currently fashionable language, and the obvious choice for its PR value. The 106K of source is spread across 351 files (average 531 LOC), and built in 17.5 seconds on my system.
LLMs make mistakes, with coding benchmark success rates being at best around 90%. Based on these numbers, the likelihood of 351 files being correctly generated, at the same time, is  (with 99% probability of correctness we get
(with 99% probability of correctness we get  ). Splitting the compiler into, say, 32 phases each in a directory containing 11 files, and generating and testing each phase independently significantly increases the probability of success (or alternatively, significantly reduces the number of repetitions of the generate code and test process). The success probability of each phase is:
). Splitting the compiler into, say, 32 phases each in a directory containing 11 files, and generating and testing each phase independently significantly increases the probability of success (or alternatively, significantly reduces the number of repetitions of the generate code and test process). The success probability of each phase is:  , and if the same phase is generated 13 times, i.e.,
, and if the same phase is generated 13 times, i.e., }/{log(1-0.90^{11})}") , there is a 99% probability that at least one of them is correct.
, there is a 99% probability that at least one of them is correct.
Some code need not do anything other than pass on the flow of information unchanged. For instance, code to perform the optimization common subexpression elimination does exist, but the optimization is not performed (based on looking at the machine code generated for a few tests; see codegen.c). Detecting non-functional code could require more prompting skill than generating the code. The prompt to implementation this optimization (e.g., write Rust code to perform value numbering) is very different from the prompt to write code containing common subexpressions, compile to machine code and check that the optimization is performed.
There is little commenting in the source for the lexer, parser, and machine code generators, i.e., the immediate front end and final back end. There is a fair amount of detailed commenting in source of the intervening phases.
The phases with little commenting are those which require lots of very specific, detailed information that is not often covered in books and papers. I suspect that the prompts for this code contains lots of detailed templates for tokenizing the source, building a tree, and at the back end how to map SSA nodes to specific instruction sequences.
The intermediate phases have more publicly available information that can be referenced in prompts, such as book chapters and particular papers. These prompts would need to be detailed instructions on how to annotate/transform the tree/SSA conveyed from earlier phases.
Formal methods and LLM generated mathematical proofs
Formal methods have been popping up in the news again, or at least on the technical news sites I follow.
Both mathematics and software share the same pattern of usage of formal methods. The input text is mapped to some output text. Various characteristics of the output text are checked using proof assistant(s). Assuming the mapping from input to output is complete and accurate, and the output has the desired characteristics, various claims can then be made about the input text, e.g., internally consistent. For software systems, some of the claims of correctness made about so-called formally verified systems would make soap powder manufacturers blush.
Mathematicians have been using LLMs to help find proofs of unsolved maths problems. Human written proofs are traditionally checked by other humans reading them to verify that the claimed proof is correct. LLMs generated proofs are sometimes written in what is called a formal language, this proof-as-program can then be independently checked by a proof assistant (the Lean proof assistant is a popular choice; Rocq is popular for proofs about software).
Software developers are well aware that LLM generated code contains bugs, and mathematicians have discovered that LLM generated proof-programs contain bugs. A mathematical proof bug involves Lean reporting that the LLM generated proof is true, when the proof applies to a question that is different from the actual question asked. Developers have probably experienced the case where an LLM generates a working program that does not do what was requested.
An iterative verification-and-refinement pipeline was used for LLMs well publicised solving of International Mathematical Olympiad problems.
A cherished belief of fans of formal methods is that mathematical proofs are correct. Experience with LLMs shows that a sequence of steps in a generated proof may be correct, but the steps may go down a path unrelated to the question posed in the input text. Also, proof assistants are programs, and programs invariably contain coding mistakes, which sometimes makes it possible to prove that false is true (one proof assistant currently has 83 bug reports of false being proved true).
It is well known, at least to mathematicians, that many published proofs contain mistakes, but that these can be fixed (not always easily), and the theorem is true. Unfortunately, journals are not always interested in publishing corrections. A sample of 51 reviews of published proofs finds that around a third contain serious errors, not easily corrected.
Human written proofs contain intentional gaps. For instance, it is assumed that readers can connect two steps without more details being given, or the author does not want to deter reviewers with an overly long proof. If LLM generated proofs are checked by proof assistants, then the gap between steps needs to be of a size supported by the assistant, and deterring reviewers is not an issue. Does this mean that LLM generated proof is likely to be human unfriendly?
Software is often expressed in an imperative language, which means it can be executed and the output checked. Theorems in mathematics are often expressed in a declarative form, which makes it difficult to execute a theorem to check its output.
For software systems, my view is that formal methods are essentially a form of  -version programming, with
-version programming, with  . Two programs are written, with one nominated to be called the specification; one or more tools are used to analyse both programs, checking that their behavior is consistent, and sometimes other properties. Mistakes may exist in the specification program or the non-specification program.
. Two programs are written, with one nominated to be called the specification; one or more tools are used to analyse both programs, checking that their behavior is consistent, and sometimes other properties. Mistakes may exist in the specification program or the non-specification program.
Using LLMs to help solve mathematical problems is a rapidly evolving field. We will have to wait and see whether end-to-end LLM generated proofs turn out to be trustworthy, or remain as a very useful aid.
My 2025 in software engineering
Unrelenting talk of LLMs now infests all the software ecosystems I frequent.
- Almost all the papers published (week) daily on the Software Engineering arXiv have an LLM themed title. Way back when I read these LLM papers, they seemed to be more concerned with doing interesting things with LLMs than doing software engineering research.
- Predictions of the arrival of AGI are shifting further into the future. Which is not difficult given that a few years ago, people were predicting it would arrive within 6-months. Small percentage improvements in benchmark scores are trumpeted by all and sundry.
- Towards the end of the year, articles explaining AI’s bubble economics, OpenAI’s high rate of loosing money, and the convoluted accounting used to fund some data centers, started appearing.
Coding assistants might be great for developer productivity, but for Cursor/Claude/etc to be profitable, a significant cost increase is needed.
Will coding assistant companies run out of money to lose before their customers become so dependent on them, that they have no choice but to pay much higher prices?
With predictions of AGI receding into the future, a new grandiose idea is needed to fill the void. Near the end of the year, we got to hear people who must know it’s nonsense claiming that data centers in space would be happening real soon now.
I attend one or two, occasionally three, evening meetups per week in London. Women used to be uncommon at technical meetups. This year, groups of 2–4 women have become common in meetings of 20+ people (perhaps 30% of attendees); men usually arrive individually. Almost all women I talked to were (ex) students looking for a job; this was also true of the younger (early 20s) men I spoke to. I don’t know if attending meetups been added to the list of things to do to try and find a job.
Tom Plum passed away at the start of the year. Tom was a softly spoken gentleman whose company, PlumHall, sold a C, and then C++, compiler validation suite. Tom lived on Hawaii, and the C/C++ Standard committees were always happy to accept his invitation to host an ISO meeting. The assets of PlumHall have been acquired by Solid Sands.
Perennial was the other major provider of C/C++ validation suites. It’s owner, Barry Headquist, is now enjoying his retirement in Florida.
The evidence-based software engineering Discord channel continues to tick over (invitation), with sporadic interesting exchanges.
What did I learn/discover about software engineering this year?
Software reliability research is a bigger mess than I had previously thought.
I now regularly use LLMs to find mathematical solutions to my experimental models of software engineering processes. Most go nowhere, but a few look like they have potential (here and here and here).
Analysis/data in the following blog posts, from the last 12-months, belongs in my book Evidence-Based Software Engineering, in some form or other (2025 was a bumper year):
Naming convergence in a network of pairwise interactions
Lifetime of coding mistakes in the Linux kernel
Decline in downloads of once popular packages
Distribution of method chains in Java and Python
Modeling the distribution of method sizes
Distribution of integer literals in text/speech and source code
Percentage of methods containing no reported faults
Half-life of Open source research software projects
Positive and negative descriptions of numeric data
Impact of developer uncertainty on estimating probabilities
After 55.5 years the Fortran Specialist Group has a new home
When task time measurements are not reported by developers
Evolution has selected humans to prefer adding new features
One code path dominates method execution
Software_Engineering_Practices = Morals+Theology
Long term growth of programming language use
Deciding whether a conclusion is possible or necessary
CPU power consumption and bit-similarity of input
Procedure nesting a once common idiom
Functions reduce the need to remember lots of variables
Remotivating data analysed for another purpose
Half-life of Microsoft products is 7 years
How has the price of a computer changed over time?
Deep dive looking for good enough reliability models
Apollo guidance computer software development process
Example of an initial analysis of some new NASA data
Extracting information from duplicate fault reports
I visited Foyles bookshop on Charing cross road during the week (if you’re ever in London, browsing books in Foyles is a great way to spend an afternoon).
Computer books once occupied almost half a floor, but is now down to five book cases (opposite is statistics occupying one book case, and the rest of mathematics in another bookcase):

Around the corner, Gender Studies and LGBTQ+ occupies seven bookcases (the same as last year, as I recall):

Fifth anniversary of Evidence-based Software Engineering book
Yesterday was the 5th anniversary of the publication of my book Evidence-based Software Engineering.
The general research trajectory I was expecting in the 2020s (e.g., more sophisticated statistical analysis and more evidence based studies) has been derailed by the arrival of LLMs three years ago. Almost all software engineering researchers have jumped on the LLM bandwagon, studying whatever LLM use case is likely to result in a published paper. While I have noticed more papers using statistical techniques discovered after the digital computer was invented (perhaps influenced by the second half of the book), there seems to be a lot fewer evidence based papers being published. I don’t expect researches studying software engineering to jump off the LLM bandwagon in the next few years.
The net result of this lack of new research findings is that the book contents are not yet in need of an update.
On a positive note, LLMs’ mathematical problem-solving capabilities have significantly reduced the time needed to analyse models of software engineering processes.
Had today’s LLMs been available while I was writing the book, the text would probably have included many more theoretical models and their analysis. ‘Probably’, because sometimes the analysis finds that a model does not provide meaningfully mimic reality, so it’s possible that only a few more models would have been included.
My plan for the next year is to use LLM’s mathematical problem-solving capabilities to help me analyse models of software engineering processes. A discussion of any interested results found will appear on this blog. I’m hoping that there will be active conversations on the evidence based software engineering Discord channel.
It makes sense to hone my model analysis skills by starting with the subject I am most familiar with, i.e., source code. It also helps that tools are available for obtaining more source measurement data.
I will continue to write about any interesting papers that appear on the arXiv lists cs.se and cs.PL, as well as the major conferences. There won’t be time to track the minor conferences.
Questions raised during model analysis sometimes suggest ideas that, when searched for, lead to new data being discovered. Discovering new data using a previously untried search phrase is always surprising.
Finding links between gcc source code and the C Standard
How close is the agreement between the behavior of a compiler and its corresponding language specification?
In the previous century, some Standards’ bodies offered a compiler validation service. However, even when the number of commercial compilers numbered in the hundreds, this service was not commercially viable. These days there are only a handful of industrial strength compilers.
The availability of huge quantities of Open source, for some languages, has created a new language specification. Being able to turn much of this source into executable programs has become an effective measure of compiler correctness.
Those working on C/C++ compilers (Open source or otherwise), often claim that they implement the requirements contained in the corresponding ISO Standard. Some are active in the ISO Standards’ process, and I believe that they do strive to implement the requirements contained in the language standard.
How confident can we be that all the requirements contained in a language standard are correctly implemented by a compiler?
There is a cottage industry of testing compiler runtime behavior, often using fuzzers, and sometimes a compiler is one of the programs chosen to test new fuzzing techniques. This research checks optimization and code generation.
This runtime testing is all well and good, but a large percentage of the text in a language specification contains requirements on the syntax and semantics. The quality of syntax/semantic testing depends on how well the people writing the tests understand the language semantics. It takes a year or two of detailed study to achieve an effective compiler-level of understanding of these ‘front-end’ requirements.
The approach taken by the Model Implementation C Checker to show syntax/semantic correctness was to cross-referenced every if-statement in the front-end to one or more lines in the C90 Standard (the 1990 edition of the ISO C Standard), or an internal house-keeping reference (the source contained 3K references to 1.3K requirements in the C Standard). This compiler/checker was formally validated by BSI. As far as I know, this is the only compiler source cross-referenced at the level of individual lines/if-statements; there are compilers whose source contains cross-references to the sections of a language specification.
The main benefit of this cross-referencing process is insuring that every requirement in the C Standard is addressed by the compiler (correctly or otherwise). Other benefits include providing packets of wording for targeted tests and the ability to generate a runtime trace of all language features involved in compiling a given translation unit.
Replicating this cross-referencing for the gcc or llvm C compiler front-ends would be a huge amount of work for somebody who already has a detailed knowledge of the C Standard, along with some knowledge of compilers. The number of pages in the Standard relating to the C language has grown from 101 pages in C90 to 190 pages in C23. At an average of 14 cross-referenceable lines per page, the expected number of cross-references is now likely to be around 2,700.
LLMs are great at extracting information from text, can generate impressive quality C conformance tests, and are much, much cheaper than C language experts. How good are LLMs at working out which section(s)/paragraph(s) in the C Standard are implemented by the source code of a function contained in, say, gcc?
The LLM prompt I used to test out the idea was:
List the section and paragraph number of the latest ISO C standard containing the requirements implemented in the following source code from a C compiler |
Links to all responses from: ChatGPT5 Thinking, Grok3 Fast and Gok3 Expert.
It is very likely that text from the various versions of the C Standard were in the training data of the larger LLMs, so I did not include this material in the prompt. ChatGPT5 Thinking listed the 2024 draft N3220 as its source document.
The source code was copied from the C front-end code of gcc (i.e., the directory: gcc-15.1.0/gcc/c), which contains 67KLOC, with 6.8K if-statements.
Starting small, the following code looked like an easy test (I removed the comment containing text from the C Standard and obscured the big clue in the original function name: null_pointer_constant_p):
bool check_is_n_ptr (const_tree expr) { /* This should really operate on c_expr structures, but they aren't yet available everywhere required. */ tree type = TREE_TYPE (expr); if (expr == nullptr_node) return true; return (TREE_CODE (expr) == INTEGER_CST && !TREE_OVERFLOW (expr) && integer_zerop (expr) && (INTEGRAL_TYPE_P (type) || (TREE_CODE (type) == POINTER_TYPE && VOID_TYPE_P (TREE_TYPE (type)) && TYPE_QUALS (TREE_TYPE (type)) == TYPE_UNQUALIFIED))); } |
Wow, ChatGPT5 Thinking’s response even included a note on why the code checks for an unqualified type:
Here are the exact C23 (ISO/IEC 9899:2024) clauses that your function is implementing:
6.3.2.3 Pointers, ¶3 — Definition of a null pointer constant: “An integer constant expression
with the value 0, such an expression cast to type void *, or the predefined constant nullptr
is called a null pointer constant.”
6.6 Constant expressions, ¶8 — What qualifies as an integer constant expression
(your INTEGER_CST / INTEGRAL_TYPE_P checks).
6.6 Constant expressions, ¶4 — Range requirement for constant expressions
(motivates the !TREE_OVERFLOW (expr) check).
6.4.4.6 Predefined constants, ¶¶1–3 — nullptr is a predefined constant (token classification;
ties to your expr == nullptr_node fast-path).
6.3.2.4 nullptr_t, ¶¶1–2 — Conversions of nullptr_t (confirms nullptr converts to any pointer
type yielding the null pointer value).
Notes
• The “cast to type void *” wording in 6.3.2.3 means unqualified void *,
which is why your code insists the pointed-to void is unqualified.
Grok3 Fast’s response was even more expansive (and almost instantaneous), listing examples of section/paragraphs containing uses of null pointers, and pointing out that the wording was unchanged until C23 (when the nullptr keyword was introduced, along with its type nullptr_t). It also pointed out gcc specific features of the implementation (the prompt did not identify the compiler).
That’s enough of the easy questions. The following code (comments removed, function name unchanged) is essentially asking a question: What is the promoted type of the argument?
tree c_type_promotes_to (tree type) { tree ret = NULL_TREE; if (TYPE_MAIN_VARIANT (type) == float_type_node) ret = double_type_node; else if (c_promoting_integer_type_p (type)) { if (TYPE_UNSIGNED (type) && (TYPE_PRECISION (type) == TYPE_PRECISION (integer_type_node))) ret = unsigned_type_node; else ret = integer_type_node; } if (ret != NULL_TREE) return (TYPE_ATOMIC (type) ? c_build_qualified_type (ret, TYPE_QUAL_ATOMIC) : ret); return type; } |
ChatGPT5 listed six references. Three were good, and the other three were closely related, but I would not have cited them. The seven Grok3 references came from several documents using slightly different section numbers. Updating the prompt to explicitly name N3220 as the document to use did not change Grok3’s cited references (for this question).
All the code in the previous questions was there because of text in the C Standard. How do ChatGPT5/Grok3 handle the presence of code that does not have standard associated text?
The following function contains code to handle named address spaces (defined in a 2005 Technical Report: TR 18037 Extensions to support embedded processors).
static tree qualify_type (tree type, tree like) { addr_space_t as_type = TYPE_ADDR_SPACE (type); addr_space_t as_like = TYPE_ADDR_SPACE (like); addr_space_t as_common; /* If the two named address spaces are different, determine the common superset address space. If there isn't one, raise an error. */ if (!addr_space_superset (as_type, as_like, &as_common)) { as_common = as_type; error ("%qT and %qT are in disjoint named address spaces", type, like); } return c_build_qualified_type (type, TYPE_QUALS_NO_ADDR_SPACE (type) | TYPE_QUALS_NO_ADDR_SPACE_NO_ATOMIC (like) | ENCODE_QUAL_ADDR_SPACE (as_common)); } |
ChatGPT5 listed six good references and pointed out the association between the named address space code and TR 18037. Grok3 Fast hallucinated extensive quoted text/references from TR 18037 related to named address spaces. Grok3 Expert pointed out that the Standard does not contain any requirements related to named address spaces and listed two reasonable references.
Finding appropriate cross-references is the time-consuming first step. Next, I want the LLM to add them as comments next to the corresponding code.
I picked a 312 line function, and updated the prompt to add comments to the attached file:
Find the section and paragraph numbers in the ISO C standard, specified in document N3220, containing the requirements implemented in the source code contained in the attached file, and add these section and paragraph numbers at the corresponding places in the code as comment |
ChatGPT5 Thinking thought for 5 min 46 secs (output), and Grok3 Expert thought for 3 mins 4 secs (output).
Both ChatGPT5 and Grok3 modified the existing code, either by joining adjacent lines, changing variable names, or deleting lines. ChatGPT made far fewer changes, while the Grok3 output was 65 lines shorter than the original (including the added comments).
Both LLMs added comments to blocks of if-statements (my fault for not explicitly specifying that every if should be cross-referenced), with ChatGPT5 adding the most cross-references.
One way to stop the LLMs making unasked for changes to the source is to have them focus on the added comments, i.e., ask for a diff that can be fed into patch. The updated prompt is:
Find the section and paragraph numbers in the ISO C standard, specified in document N3220, containing the requirements implemented by each if statement in the source code contained in the attached file. Create a diff file that patch can use to add these section and paragraph numbers as comments at the corresponding lines in the original code |
ChatGPT5 Thinking thought for around 4 min (it reported inconsistent values (output), and Grok3 Expert thought for 5 min 1 sec (output).
The ChatGPT5 patch contained many more cross-references than its earlier output, with comments on more if-statements. The Grok3 patch was a third the size of the ChatGPT5 patch.
How well did the LLMs perform?
ChatGPT5 did very well, and its patch output would be a good starting point for a detailed human expert edit. Perhaps an improved prompt, or some form of fine-tuning would useful improve performance.
Grok3 Fast does not appear to be usable, but Grok3 Expert could be used as an independent check against ChatGPT5 output.
Working at the section/paragraph level it is not always possible to give the necessary detailed cross-reference because some paragraphs contain multiple requirements. It might be easier to split the C Standard text into smaller chunks, rather than trying to get LLMs to give line offsets within a paragraph.
Modeling the distribution of method sizes
The number of lines of code in a method/function follows the same pattern in the three languages for which I have measurements: C, Java, Pharo (derived from Smalltalk-80).
The number of methods containing a given number of lines is a power law, with an exponent of 2.8 for C, 2.7 for Java and 2.6 for Pharo.
This behavior does not appear to be consistent with a simplistic model of method growth, in lines of code, based on the following three kinds of steps over a 2-D lattice: moving right with probability  , moving up and to the right with probability
, moving up and to the right with probability  , and moving down and to the right with probability
, and moving down and to the right with probability  . The start of an
. The start of an if or for statement are examples of coding constructs that produce a step followed by a step at the end of the statement; steps are any non-compound statement. The image below shows the distinct paths for a method containing four statements:

For this model, if  the probability of returning to the origin after taking
the probability of returning to the origin after taking  is a complicated expression with an exponentially decaying tail, and the case
is a complicated expression with an exponentially decaying tail, and the case  is a well studied problem in 1-D random walks (the probability of returning to the origin after taking steps is
is a well studied problem in 1-D random walks (the probability of returning to the origin after taking steps is  approx n^{-1.5}") ).
).
Possible changes to this model to more closely align its behavior with source statement production include:
- include terms for the correlation between statements, e.g., assigning to a local variable implies a later statement that reads from that variable,
- include context terms in the up/down probabilities, e.g., nesting level.
Measuring statement correlation requires handling lots of special cases, while measurements of up/down steps is easily obtained.
How can / probabilities be written such that step length has a power law with an exponent greater than two?
ChatGPT 5 told me that the Langevin equation and Fokker–Planck equation could be used to derive probabilities that produced a power law exponent greater than two. I had no idea had they might be used, so I asked ChatGPT, Grok, Deepseek and Kimi to suggest possible equations for the / probabilities.
The physics model corresponding to this code related problem involves the trajectories of particles at the bottom of a well, with the steepness of the wall varying with height. This model is widely studied in physics, where it is known as a potential well.
Reaching a possible solution involved refining the questions I asked, following suggestions that turned out to be hallucinations, and trying to work out what a realistic solution might look like.
One ChatGPT suggestion that initially looked promising used a Metropolis–Hastings approach, and a logarithmic potential well. However, it eventually dawned on me that ^a") , where
, where  is nesting level, and
is nesting level, and  some constant, is unlikely to be realistic (I expect the probability of stepping up to decrease with nesting level).
some constant, is unlikely to be realistic (I expect the probability of stepping up to decrease with nesting level).
Kimi proposed a model based on what it called algebraic divergence:
=r/{z(y)},U(y)={u_0y^{1-2/{alpha}}}/{z(y)}, D(y)={d_0y^{1-2/{alpha}}}/{z(y)}")
where: ") normalises the probabilities to equal one,
normalises the probabilities to equal one, =r+u_0y^{1-2/alpha}+d_0y^{1-2/alpha}") ,
,  is the up probability at nesting 0,
is the up probability at nesting 0,  is the down probability at nesting 0, and
is the down probability at nesting 0, and  is the desired power law exponent (e.g., 2.8).
is the desired power law exponent (e.g., 2.8).
For C,  , giving
, giving =r/{z(y)},U(y)={u_0y^{0.29}}/{z(y)}, D(y)={d_0y^{0.29}}/{z(y)}")
The average length of a method, in LOC, is given by:
![E[LOC]={alpha r}/{2(d_0-u_0)}+O(e^{lambda}-1)](https://shape-of-code.com/wp-content/plugins/wpmathpub/phpmathpublisher/img/math_969.5_ffcacf0bb8190096d4d17fb475c0a290.png "E[LOC]={alpha r}/{2(d_0-u_0)}+O(e^{lambda}-1)") , where:
, where: }/{d_0+u_0}")
For C, the mean function length is 26.4 lines, and the values of  , , and need to be chosen subject to the constraint
, , and need to be chosen subject to the constraint  .
.
Combining the normalization factor with the requirement  , shows that as increases,
, shows that as increases, ") slowly decreases and
slowly decreases and ") slowly increases.
slowly increases.
One way to judge how closely a model matches reality is to use it to make predictions about behavior patterns that were not used to create the model. The behavior patterns used to build this model were: function/method length is a power law with exponent greater than 2. The mean length, ![E[LOC]](https://shape-of-code.com/wp-content/plugins/wpmathpub/phpmathpublisher/img/math_981.5_0ac27fa76bd7c6e393f3497c9f30db7e.png "E[LOC]") , is a tuneable parameter.
, is a tuneable parameter.
Ideally a model works across many languages, but to start, given the ease of measuring C source (using Coccinelle), this one language will be the focus.
I need to think of measurable source code patterns that are not an immediate consequence of the power law pattern used to create the model. Suggestions welcome.
It’s possible that the impact of factors not included in this model (e.g., statement correlation) is large enough to hide any nesting related patterns that are there. While different kinds of compound statements (e.g., if vs. for) may have different step probabilities, in C, and I suspect other languages, if-statement use dominates (Table 1713.1: if 16%, for 4.6% while 2.1%, non-compound statements 66%).
Percentage of methods containing no reported faults
It is often said, with some evidence, that 80% of reported faults, for a program, occur in 20% of its code. I think this pattern is a consequence of 20% of the code being executed 80% of the time, while many researchers believe that 20% of the source code has characteristics that result in it containing 80% of the coding mistakes.
The 20% figure is commonly measured as a percentage of methods/functions, rather than a percentage of lines of code.
This post investigates the expected fraction of a program’s methods that remain fault report free, based on two probability models.
Both models assume that coding mistakes are uniformly scattered throughout the code (i.e., every statement has the same probability of containing a mistake) and that the corresponding coding mistake is contained within a single method (the evidence suggests that this is true for 50% of faults).
A simple model is to assume that when a new fault is reported, the probability that the corresponding coding mistake appears in a particular method is proportional to the method’s length,  in lines of code, of the method. The evidence shows that the distribution of methods containing a given number of lines, , is well-fitted by a power law (for Java:
in lines of code, of the method. The evidence shows that the distribution of methods containing a given number of lines, , is well-fitted by a power law (for Java:  ).
).
If  reported faults have been fixed in a program containing
reported faults have been fixed in a program containing  methods/functions, what is the expected number of methods that have not been modified by the fixing process?
methods/functions, what is the expected number of methods that have not been modified by the fixing process?
The answer (with help from: mostly Kimi, with occasional help from Deepseek (who don’t have a share chat options), ChatGPT 5, Grok, and some approximations; chat logs) is:
}Li_b(e^{-{F/M}{{zeta(b)}/{zeta(b-1)}}})")
where:  is the Riemann zeta function,
is the Riemann zeta function,  is the polylogarithm function and
is the polylogarithm function and  for Java.
for Java.
The plot below shows the predicted fraction of unmodified methods against number of faults, for programs of various sizes; the grey lines show the rough approximation:  (code+data):
(code+data):
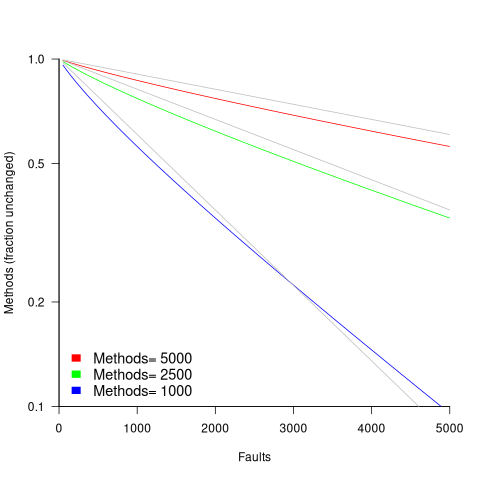
The observed behavior of most reported faults involving a subset of a program’s methods can be modelled using some form of preferential attachment.
One preferential attachment model specifies that the likelihood of a coding mistake appearing in a method is proportional to ") , where is the number of previously detected coding mistakes in the method.
, where is the number of previously detected coding mistakes in the method.
The estimated number of unmodified methods is now:
}Li_b(({M zeta(b-1)}/{M zeta(b-1)+a*(F+1) zeta(b)})^{1/a})")
where: is the average value of  over all faults (if
over all faults (if  , then
, then  for a power law with exponent 2.35).
for a power law with exponent 2.35).
The plot below shows the predicted fraction of unmodified methods against number of faults for a program containing 1,000 methods, for various values of , with the black line showing the fraction of unmodified methods predicted by the simple model above (code+data):
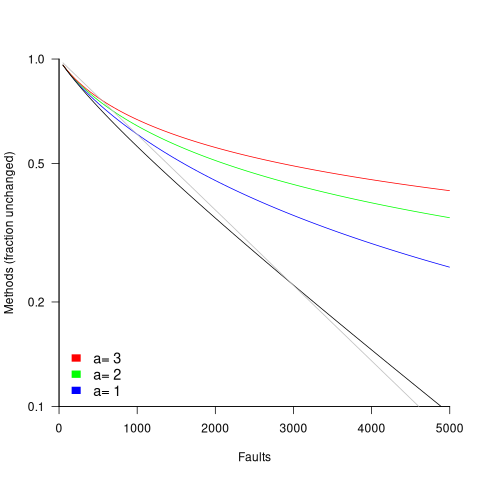
In practice, random selection of the method containing a coding mistake will introduce some fuzziness in the predicted fraction of unmodified methods.
As the number of reported faults grows, the attraction of methods involved in previous reported faults slows the rate at which methods experience their first detected coding mistake.
How realistic are these models?
By focusing on the number of unmodified methods, many complications are avoided.
Both models assume that an unchanging number of methods in a program and that the length of each method is fixed. This assumption holds between each release of a program.
For actively maintained programs, the number of methods in a program changes over time, and the length of some existing methods also changes (if a program were not actively maintained, reported faults would not get fixed).
These models are unlikely to be applicable to programs with short release cycles, where there are few reported faults between releases.
How well do the models’ predictions agree with the data?
At the moment, I am not aware of a dataset containing the appropriate data. Number of faults vs unmodified methods has been added to my list of interesting patterns to notice.
Summary of the derivation of the solutions for the two models.
Simple model
The expected number of unmodified methods, ") , is:
, is:
=sum{L=1}{T}{m_L{P(U_LF)}}") , where
, where  is the length of the longest method,
is the length of the longest method,  is the number of methods of length , and
is the number of methods of length , and ") is the probability that a method of length will be unmodified after fault reports.
is the probability that a method of length will be unmodified after fault reports.
The evidence shows that the distribution of methods containing a given number of lines, , is well-fitted by a power law (for Java: ).
Given a program containing methods, the number of methods of length is:
 , where for Java.
, where for Java.
If is large and  , then the sum can be approximated by the Riemann zeta function, , giving:
, then the sum can be approximated by the Riemann zeta function, , giving:
}}")
The probability that a method containing lines will not be modified by a fault report (assuming that fixing the mistake only involves one method) is:  , where
, where  is the total lines of code in the program, and the probability of this method not being modified after fault reports is approximately:
is the total lines of code in the program, and the probability of this method not being modified after fault reports is approximately:
^F approx e^{{-F*L}/{P_t}}")
The expected number of empty boxes is:
}}*e^{{-F*L}/{P_t}}}=M/{zeta(b)}Li_b(e^{-F/{P_t}})")
The number of lines of code in a program containing methods is:
}}}=M/{zeta(b)}sum{L=1}{T}{L^{1-b}}=M{{zeta(b-1)}/{zeta(b)}}")
Finally giving:
}Li_b(e^{-{F/M}{{zeta(b)}/{zeta(b-1)}}})")
where is the polylogarithm function.
This equation is roughly, for the purposes of understanding the effect of each variable:

Preferential attachment model
When a mistake is corrected in a method, the attraction weight of that method increases (alternatively, the attraction weight of the other methods decreases). The probability that a method is not modified after fault reports is now:
}=prod{k=0}{F}{{P_t+a*k-L}/{P_t+a*k}}={Gamma({P_t}/a)Gamma({P_t-L}/a+F+1)}/{Gamma({P_t-L}/a)Gamma(P_t/a+F+1)}")
where:  the average value of over all faults, and
the average value of over all faults, and  is the gamma function.
is the gamma function.
applying the Stirling/Gamma–ratio rule, i.e., }/{Gamma(z+b)} approx z^{a-b}") we get:
we get:
})^{F/a} = ((P_t/{P_t+a*(F+1)})^{1/a})^F")
where the expression ^{1/a})^F") is the preferential attachment version of the expression
is the preferential attachment version of the expression ^F") appearing in the simple model derivation. Using this preferential attachment expression in the analysis of the simple model, we get:
appearing in the simple model derivation. Using this preferential attachment expression in the analysis of the simple model, we get:
I don’t have a rough approximation for this expression.
Predicted impact of LLM use on developer ecosystems
LLMs are not going to replace developers. Next token prediction is not the path to human intelligence. LLMs provide a convenient excuse for companies not hiring or laying off developers to say that the decision is driven by LLMs, rather than admit that their business is not doing so well
Once the hype has evaporated, what impact will LLMs have on software ecosystems?
The size and complexity of software systems is limited by the human cognitive resources available for its production. LLMs provide a means to reduce the human cognitive effort needed to produce a given amount of software.
Using LLMs enables more software to be created within a given budget, or the same amount of software created with a smaller budget (either through the use of cheaper, and presumably less capable, developers, or consuming less time of more capable developers).
Given the extent to which companies compete by adding more features to their applications, I expect the common case to be that applications contain more software and budgets remain unchanged. In a Red Queen market, companies want to be perceived as supporting the latest thing, and the marketing department needs something to talk about.
Reducing the effort needed to create new features means a reduction in the delay between a company introducing a new feature that becomes popular, and the competition copying it.
LLMs will enable software systems to be created that would not have been created without them, because of timescales, funding, or lack of developer expertise.
I think that LLMs will have a large impact on the use of programming languages.
The quantity of training data (e.g., source code) has an impact on the quality of LLM output. The less widely used languages will have less training data. The table below lists the gigabytes of source code in 30 languages contained in various LLM training datasets (for details see The Stack: 3 TB of permissively licensed source code by Kocetkov et al.):
Language TheStack CodeParrot AlphaCode CodeGen PolyCoder HTML 746.33 118.12 JavaScript 486.2 87.82 88 24.7 22 Java 271.43 107.7 113.8 120.3 41 C 222.88 183.83 48.9 55 C++ 192.84 87.73 290.5 69.9 52 Python 190.73 52.03 54.3 55.9 16 PHP 183.19 61.41 64 13 Markdown 164.61 23.09 CSS 145.33 22.67 TypeScript 131.46 24.59 24.9 9.2 C# 128.37 36.83 38.4 21 GO 118.37 19.28 19.8 21.4 15 Rust 40.35 2.68 2.8 3.5 Ruby 23.82 10.95 11.6 4.1 SQL 18.15 5.67 Scala 14.87 3.87 4.1 1.8 Shell 8.69 3.01 Haskell 6.95 1.85 Lua 6.58 2.81 2.9 Perl 5.5 4.7 Makefile 5.09 2.92 TeX 4.65 2.15 PowerShell 3.37 0.69 FORTRAN 3.1 1.62 Julia 3.09 0.29 VisualBasic 2.73 1.91 Assembly 2.36 0.78 CMake 1.96 0.54 Dockerfile 1.95 0.71 Batchfile 1 0.7 Total 3135.95 872.95 715.1 314.1 253.6 |
The major companies building LLMs probably have a lot more source code (as of July 2023, the Software Heritage had over  unique source code files); this table gives some idea of the relative quantities available for different languages, subject to recency bias. At the moment, companies appear to be training using everything they can get their hands on. Would LLM performance on the widely used languages improve if source code for most of the 682 languages listed on Wikipedia was not included in their training data?
unique source code files); this table gives some idea of the relative quantities available for different languages, subject to recency bias. At the moment, companies appear to be training using everything they can get their hands on. Would LLM performance on the widely used languages improve if source code for most of the 682 languages listed on Wikipedia was not included in their training data?
Traditionally, developers have had to spend a lot of time learning the technical details about how language constructs interact. For the first few languages, acquiring fluency usually takes several years.
It’s possible that LLMs will remove the need for developers to know much about the details of the language they are using, e.g., they will define variables to have the appropriate type and suggest possible options when type mismatches occur.
Removing the fluff of software development (i.e., writing the code) means that developers can invest more cognitive resources in understanding what functionality is required, and making sure that all the details are handled.
Removing a lot of the sunk cost of language learning removes the only moat that some developers have. Job adverts could stop requiring skills with particular programming languages.
Little is currently known about developer career progression, which means it’s not possible to say anything about how it might change.
Since they were first created, programming languages have fascinated developers. They are the fashion icon of software development, with youngsters wanting to program in the latest language, or at least not use the languages used by their parents. If developers don’t invest in learning language details, they have nothing language related to discuss with other developers. Programming languages will cease to be a fashion icon (cpus used to be a fashion icon, until developers did not need to know details about them, such as available registers and unique instructions). Zig could be the last language to become fashionable.
I don’t expect the usage of existing language features to change. LLMs mimic the characteristics of the code they were trained on.
When new constructs are added to a popular language, it can take years before they start to be widely used by developers. LLMs will not use language constructs that don’t appear in their training data, and if developers are relying on LLMs to select the appropriate language construct, then new language constructs will never get used.
By 2035 things should have had time to settle down and for the new patterns of developer behavior to be apparent.
An attempt to shroud text from LLMs
Describe the items discussed in the following sentences: “phashyon es cycklyq. chuyldren donth wanth tew weywr chloths vat there pairent weywr. pwroggwrammyng languij phashyon hash phricksionz vat inycially inqloob impleementaision suppoort, lybrareyz (whych sloa doun adopsion, ant wunsh establysht jobz ol avaylable too suppourt ecksysting kowd (slowyng doun va demighz ov a langguij).”
I was at the {Tech: Europe} hackathon yesterday, and my ‘inspired’ idea was to transform sentences such that while people could (eventually) still understand them, LLMs would fail miserably.
My team-mates from the last hackathon applied too late to be accepted, pitching the idea to people without a team failed to convince anyone to join me, and the idea pitches I heard did not convince me to join someone else.
Many years ago, I implemented a sounds like tool, which generates character sequences that an English reader would recognise (perhaps slowly) as sounding like the input word (also used in a previous hack). Surely, replacing every word in a sentence with a randomly chosen sounds-like character sequence would seriously confuse LLMs (wrapper code around sounds like tool).
My ‘inspired’ idea failed hard with: Grok, ChatGPT, Deepseek (no sharable link), and Perplexity.
Grok’s response yesterday (this recent response does not begin by giving the corrected sentence):
The sentences provided contain numerous typographical errors, making them challenging to interpret. However, by correcting the likely typos, the intended meaning can be inferred as follows: Corrected Sentences: "Fashion is cyclical. Children don’t want to wear clothes that their parents wore. Programming language fashion has frictions that initially include implementation support, libraries (which slow down adoption), and once established, jobs are available to support existing code (slowing down the demise of a language)." |
Time to do some pivoting, with options including:
- Update source-like tool. LLMs operate on tokens, which are short common character sequences, which may or may not be complete words. The sounds-like tool could be enhanced to be token aware, and attempt to change all tokens within a word. While the tokenization sequence list varies between LLMs, I assume that most, say, 10,000 common character sequences are always treated as tokens. The list of GPT2 tokens is available.
- Narrow the use case. Anybody monitoring text messages will want to keep costs down by using as small a model as possible, and will likely want to keep the text in-house. Check the ability of small models to handle sounds-like sentences.
- Add non-sounds-like changes. For instance, adding underscores, changing some letters to upper case, and changing ‘l’ to the number ‘1’.
With only a few hours available (this was essentially an afternoon hack), I opted to investigate the performance of small models.
Below is the edited output (‘…’ indicates further text was generated) of models containing 14.8, 8.29, 4.02, 2.03 billion parameters. These Open weights models ran under LM Studio on my local machine (which does not have a GPU, so the response is sluuuugish).
I was surprised at how well the models performed, particularly the 4.02B parameter reasoning model. The responses did not start to go wrong until the model size was reduced to 2 billion parameters. We will have to wait and see if tiny models continue to improve, such that a model containing under a billion parameters can reliably interpret sounds-like sentences.
I’m still clinging to the possibility that sentences can be modified such that humans can understand them, but LLMs cannot (AGI, which LLMs are not close to achieving, will by definition have human level ability).
deepseek-r1-distil-qwen-14b has 14.8B parameters and is currently a leading model at this size. Its response was:
The sentences discuss several items:
Fashion Cycles: The first sentence appears to suggest that fashion (phashyon)
is cyclic (cycklyq), meaning it follows repeating trends or cycles.
Children's Preferences for Clothing: The second sentence discusses children
not wanting to wear the same clothes as their parents, implying a
generational difference in fashion preferences.
Programming Language Trends and Challenges:
o The third sentence talks about programming languages (pwroggwrammyng languij)
having fads or trends (phashyon hash phricksionz), which are initially
implemented but can slow down adoption due to libraries taking time to develop.
o It also mentions that these fads may eventually lead to the decline of
existing codebases (ecksysting kowd) because they become outdated or unsupported.
Overall, the sentences touch on fashion trends, generational differences in
clothing preferences, and challenges related to programming language adoption
and maintenance.
2.68 tok/sec • 826 tokens • 29.94s to first token |
Perhaps vision models will not be as proficient with this kind of text. Qwen2.5-VL-7B-Instruct is an 8.29B parameter vision model.
The sentences you've provided appear to be a mix of misspelled and jumbled words, making it challenging to understand the intended meaning. However, I'll attempt to interpret them based on common themes in technology and programming. 1. "phashyon es cycklyq." - This seems to be an incomplete or corrupted phrase that might refer to something related to fashion being cyclical. 2. "chuyldren donth wanth tew weywr chloths vat there pairent weywr." - This appears to be a misspelled and jumbled sentence, possibly referring to children not wanting to wear clothes their parents wore when they were young. 3. "pwroggwrammyng languij phashyon hash phricksionz vat inycially inqloob impleementaision suppoort." - This phrase seems to be discussing programming languages and the friction or challenges associated with implementing initial support for new features or functionalities within these languages. 4. "lybrareyz (whych sloa doun adopsion, ant wunsh establysht jobz ol avaylable too suppourt ecksysting kowd (slowyng doun va demighz ov a langguij)" - This part appears to be discussing libraries that slow down adoption and the desire for established jobs or roles available to support existing code, which in turn slows down development of languages. In summary: ... 4.06 tok/sec • 392 tokens • 13.46s to first token |
Qwen3-4b is a 4.02B parameter model with reasoning abilities:
Thought for 2 minutes 47 seconds The sentences discuss two main topics: 1. A Metaphorical Observation: "Children don’t want to wear clothes their parents wear." This is a metaphorical statement suggesting that individuals (e.g., developers) may resist adopting technologies or practices that are inherited from older generations (e.g., legacy code, outdated programming languages). It highlights a generational or cultural resistance to following established norms. 2. Technical Discussion on Programming Languages and Libraries: "Programming languages have features initially included in implementation support, libraries that slow down adoption and establish jobs for existing code, slowing the decline of a language." This refers to: o Programming Language Features: Some programming languages include built-in support for specific functionalities (e.g., syntax, tools) that are essential for development. o Libraries and Ecosystems: Libraries or frameworks in a programming language can influence adoption by providing tools that simplify tasks. However, if these libraries become outdated or complex, they may slow down the adoption of newer versions of the language. o Maintenance and Decline: The text suggests that maintaining compatibility with existing code (e.g., legacy systems) can help sustain a programming language, even as newer technologies emerge. This creates a tension between innovation and backward compatibility. Key Concepts: o Metaphor vs. Technicality: The first part uses a metaphor to illustrate resistance to inherited practices, while the second part delves into technical aspects of software development. o Language Evolution: The discussion highlights how programming languages balance innovation (new features) with preservation (supporting existing code), which can affect their longevity and adoption. This interplay between metaphor and technical detail underscores themes of generational change, technological inertia, and the challenges of maintaining compatibility in software ecosystems. 5.59 tok/sec • 1290 tokens • 7.67s to first token |
Qwen3-1.7B is a 2.03B parameter model, i.e., a smaller version of Qwen3-4b used above.
Thought for 1 minutes 8 seconds The sentences discuss several interconnected themes, blending technical and metaphorical elements: 1. Phishing (Cyclic Behavior): The first sentence references "phashyon" (likely a misspelling of "phishing") as cyclic or recurring, suggesting phishing attacks that repeat or evolve over time. 2. Children's Clothing and Parental Influence: A metaphorical statement about children not wanting to wear clothes their parents wear, implying a generational or cultural disconnect in preferences or values. 3. Programming Languages and Technical Concepts: The text introduces complex technical terms: o Phishing Zones (possibly a misinterpretation of "phishing zones" as areas where phishing attacks occur). o Implementation Support and Libraries (e.g., libraries that slow down adoption or require stable ecosystems). o Ecosystems (referring to software or technical environments) and Job Creation in these systems. 4. Adoption and Slowdown: Libraries are described as "slowing down adoption" and "slowly reducing values over a language," suggesting challenges in integrating new technologies or standards. 5. Confusion and Mixed Language Elements: The text contains mixed syntax (e.g., "pwroggwrammyng" → "programming"), mistranslations, and unclear phrasing, likely due to linguistic errors or intentional ambiguity. Key Items Discussed:... 10.32 tok/sec • 1081 tokens • 2.93s to first token |
Thanks to our {Tech: Europe} hosts who kept us fed and watered.
ClearRoute x Le Mans 24h Hackathon 2025
This weekend, Team Awesome (Sam, Frank and yours truly) took part in the [London] ClearRoute x Le Mans 24h Hackathon 2025 (ClearRoute is an engineering consultancy and Le Mans is an endurance-focused sports car race).
London hackathons have been thin on the ground during the last four years. I suspect that the chilling of the economic climate, with the end of the zero interest-rate policy, caused companies to cut back funding for projects whose benefits were rather indirect. Things do seem to be picking up. This is my second hackathon this year, there are two hacks next weekend and one the following weekend.
Based on the title, the theme of the hackathon was obviously the Le Mans 24 hour car race, and we were asked to use ClearRoute’s LLM-based tools to find ways to improve race team performance.
I was expecting the organisers to provide us with interesting race data. After asking about data and hearing the dreaded suggestion, “find some on the internet”, I was almost ready to leave. However, the weekend was rescued by a sudden inspired idea.
My limited knowledge of motorsport racing comes from watching Formula 1 on TV (until the ever-increasing number of regulations created a boring precession), and I remembered seeing teams penalized because they broke an important rule. The rule infringement may have been spotted by a race marshal, or a member of another team, who then reported it to the marshals.
Le Mans attracts 60+ racecars each year, in three categories (each with their own rules document). The numbers for 2025 were 21 Hypercars, 17 LMP2 prototypes, and 24 LMGT3 cars (the 2025 race ran this weekend).
Manually checking the behavior of 60+ cars against a large collection of ever-changing rules is not practical. Having an LLM-based Agent check text descriptions of racing events for rule violations would not only be very cost-effective, but it would also reduce the randomness of somebody happening to be in the right place and time to see an infringement.
This idea now seems obvious, given my past use of LLMs to check software conformance and test generation.
Calling an idea inspired is all well and good, if it works. This being a hackathon, suck-it-and-see is the default response to will it work questions.
One of the LLMs made available was Gemini Flash, which has a 1 million token input context window. The 161 page pdf of the Le Mans base technical rules document probably contains a lot less than 1 million tokens. The fact that the documents were written in French (left column of page) and English (right column) was initially more of a concern.
Each team was given a $100 budget to spend on LLMs, and after spending a few percent of our budget we had something that looked like it worked, i.e., it detected all 14 instances of race-time checkable rule violations listed by Grok.
My fellow team-mates knew as much about motor racing as I did, and we leaned heavily on what our favourite LLMs told us. I was surprised at how smoothly and quickly the app was up and running; perhaps because so much of the code was LLM generated. Given how flawed human written hackathon code can be, I cannot criticize LLM generated hackathon code.
Based on our LLM usage costs during application creation and testing, checking the events associated with one car over 24 hours is estimated to be around $36.00, and with a field of 60 cars the total estimated cost is $2,160.
Five teams presented on Sunday afternoon, and Team Awesome won! The source code is available on GitHub.
Motorcar racing is a Red Queen activity. If they are not already doing so, I expect that teams will soon be using LLMs to check what other teams are doing.
Thanks to our ClearRoute hosts who kept us fed and watered, and were very responsive to requests for help.
Recent Comments