Archive
Naming convergence in a network of pairwise interactions
While naming and categorizing things are perhaps the two most contentious issues in software engineering, there is often a great deal of similarity in the names and categorizes used by unconnected groups. These characteristics of naming and categorization are general observed behaviors across cultures and languages, with software engineering being a particular example.
Studies have found that a particular name for a thing is likely to become adopted by a group, if around 25% of its members actively promote the use of the name. The terms tipping point and critical mass have been applied to the 25% quantity.
What factors could cause 25% of the members of a group to select a particular name, and why does a tipping point occur at around this percentage?
The paper Experimental evidence for scale-induced category convergence across populations by Douglas Guilbeault (PhD thesis behind the paper), Andrea Baronchelli, and Damon Centola experimentally investigated factors that can cause a name to be adopted by 25% of a group’s members, and the researchers proposed a model that exhibits behavior similar to the experimental results (the supplement contains the technical details).
The experiment asked subjects to play the “Grouping Game”. The 1,480 online subjects were divided into networks containing either 2, 6, 8, 24 or 50 members. The interaction between members of a network only occurred via randomly selected pairs (the same pair for the network of two), with one person designated as the speaker and the other as the hearer. A pair saw three randomly selected images, such as the one below. For the speaker only, one of the images was highlighted, and they had to give a name containing at most six characters to the image. The hearer saw the name given by the speaker to one of the images, and had 30 seconds to choose the image they considered to have been named. If the image selected by the hearer was the one named by the speaker, both received a small payment, otherwise an even smaller amount was deducted from their final payment. Each subject played 100 rounds with the randomly chosen members of their network.

The images were created as a series of 50+ distinct patterns whose shape slowly morphed along a continuum, as in the following image:

The experimental results were that larger networks converged to a consistent, within group, naming of the images (using a few names), while smaller groups rarely converged and used many different names. The researchers proposed that as the network size grew, common names were encountered more often than rarer names, increasing the likelihood of reaching a tipping point. This behavior is similar to the birthday paradox, where there is a 50% probability that in a room of 23 people, two people will share the same birthday.
In the experiment, some networks included confederates trained to use a small subset of names, i.e., the researchers created a common set of names. It was hypothesized built-in human preferences would produce common patterns in the real world that, for larger groups, would cause tipping points to occur, amplifying the more common patterns to become group norms.
The supplement to the paper develops a theoretical model based on the probability of  identical items being contained in a sample of
identical items being contained in a sample of  items, when sampling without replacement. The solution involves the hypergeometric distribution, which is difficult to deal with analytically, so simulation is needed. The results show a tipping point at around 25%.
items, when sampling without replacement. The solution involves the hypergeometric distribution, which is difficult to deal with analytically, so simulation is needed. The results show a tipping point at around 25%.
The plot below shows a density plot for one 50-subject network over 15 trials (after 100 rounds of pairwise interaction), with each color denoting one of the 14 chosen names (height of the curve denotes likelihood of the same name being chosen for that image; code and data):
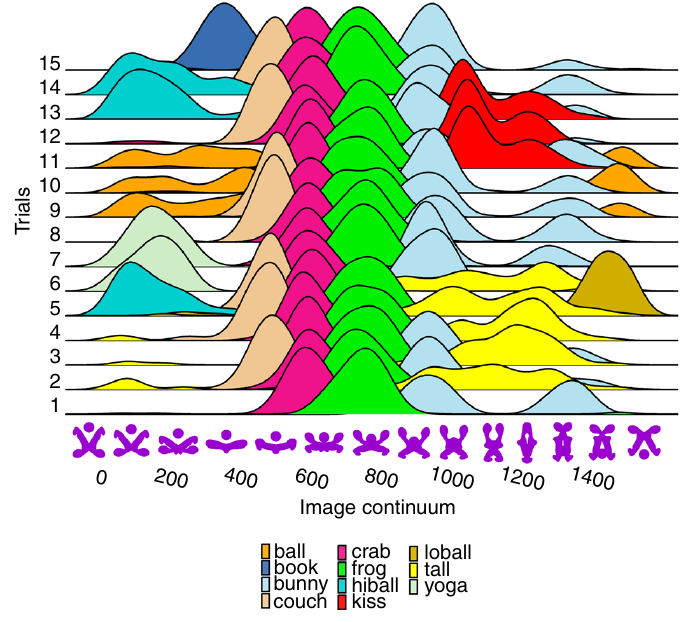
This plot shows that the same name is often used across trials, and naming boundaries between some images.
The plot below shows a density plot for one 2-subject network over 15 trials (after 100 rounds of pairwise interaction), with each color denoting one of the 72 chosen names (height of the curve denotes likelihood of the same name being chosen for that image; code and data):
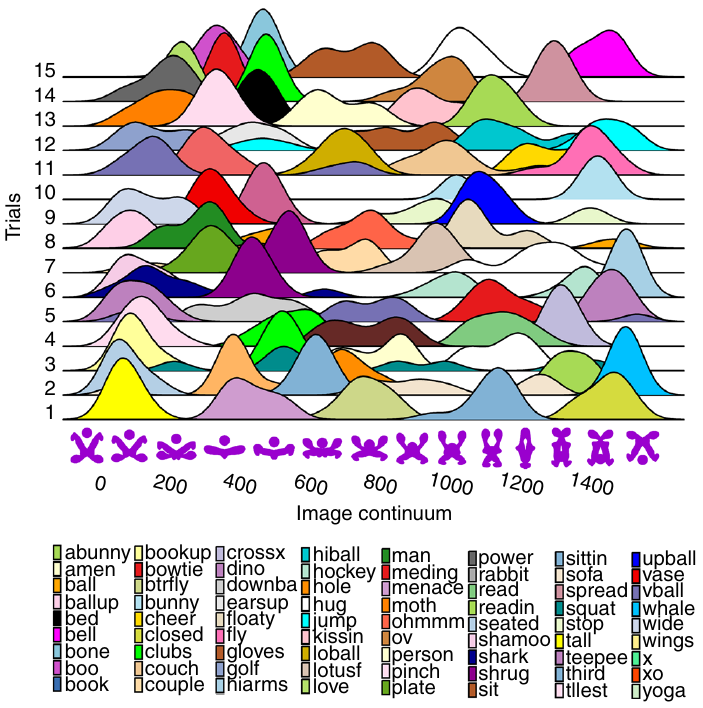
Here there is no consistent naming across trials, a much greater diversity of names appearing, and no obvious naming boundaries between images.
Positive and negative descriptions of numeric data
Effective human communication is based on the cooperative principle, i.e., listeners and speakers act cooperatively and mutually accept one another to be understood in a particular way. However, when seeking to present a particular point of view, speakers may prefer to be economical with the truth.
To attract citations and funding, researchers sell their work via the papers they publish (or blogs they write), and what they write is not subject to the Advertising Standards Authority rule that “no marketing communication should mislead, or be likely to mislead, by inaccuracy, ambiguity, exaggeration, omission or otherwise” (my default example).
When people are being economical with the truth, when reporting numeric information, are certain phrases or words more likely to be used?
The paper: Strategic use of English quantifiers in the reporting of quantitative information by Silva, Lorson, Franke, Cummins and Winter, suggests some possibilities.
In an experiment, subjects saw the exam results of five fictitious students and had to describe the results in either a positive or negative way. They were given a fixed sentence and had to fill in the gaps by selecting one of the listed words; as in the following:
all all
most most right
In this exam .... of the students got .... of the questions .....
some some wrong
none none |
If you were shown exam results with 2 out of 5 students failing 80% of questions and the other 3 out of 5 passing 80% of questions, what positive description would you use, and what negative description would you use?
The 60 subjects each saw 20 different sets of exam results for five fictitious students. The selection of positive/negative description was random for each question/subject.
The results found that when asked to give a positive description, most responses focused on questions that were right, and when asked to give a negative description, most responses focused on questions that were wrong
How many questions need to be answered correctly before most can be said to be correct? One study found that at least 50% is needed.
“3 out of 5 passing 80%” could be described as “… most of the students got most of the questions right.”, and “2 out of 5 students failing 80%” could be described as “… some of the students got most of the questions wrong.”
The authors fitted a Bayesian linear mixed effect models, which showed a somewhat complicated collection of connections between quantifier use and exam results. The plots below provide a visual comparison of the combination of quantifier use for positive (upper) and negative (lower) descriptions.
The alluvial plot below shows the percentage flow, for Positive descriptions, of each selected quantifier through student and question, and then adjective (code+data):

For the same distribution of exam results, the alluvial plot below shows the percentage flow, for Negative descriptions, of each selected quantifier through student and question, and then adjective (code+date):

Other adjectives could be used to describe the results (e.g., few, several, many, not many, not all), and we will have to wait for the follow-up research to this 2024 paper.
Impact of developer uncertainty on estimating probabilities
For over 50 years, it has been known that people tend to overestimate the likelihood of uncommon events/items occurring, and underestimate the likelihood of common events/items. This behavior has replicated in many experiments and is sometimes listed as a so-called cognitive bias.
Cognitive bias has become the term used to describe the situation where the human response to a problem (in an experiment) fails to match the response produced by the mathematical model that researchers believe produces the best output for this kind of problem. The possibility that the mathematical models do not reflect the reality of the contexts in which people have to solve the problems (outside of psychology experiments), goes against the grain of the idealised world in which many researchers work.
When models take into account the messiness of the real world, the responses are a closer match to the patterns seen in human responses, without requiring any biases.
The 2014 paper Surprisingly Rational: Probability theory plus noise explains biases in judgment by F. Costello and P. Watts (shorter paper), showed that including noise in a probability estimation model produces behavior that follows the human behavior patterns seen in practice.
If a developer is asked to estimate the probability that a particular event,  , occurs, they may not have all the information needed to make an accurate estimate. They may fail to take into account some s, and incorrectly include other kinds of events as being s. This noise,
, occurs, they may not have all the information needed to make an accurate estimate. They may fail to take into account some s, and incorrectly include other kinds of events as being s. This noise,  , introduces a pattern into the developer estimate:
, introduces a pattern into the developer estimate:
*P_E + N*(1-P_E)=(1-2N)*P_E+N")
where:  is the developer’s estimated probability of event occurring,
is the developer’s estimated probability of event occurring,  is the actual probability of the event, and is the probability that noise produces an incorrect classification of an event as
is the actual probability of the event, and is the probability that noise produces an incorrect classification of an event as  or (for simplicity, the impact of noise is assumed to be the same for both cases).
or (for simplicity, the impact of noise is assumed to be the same for both cases).
The plot below shows actual event probability against developer estimated probability for various values of , with a red line showing that at  , the developer estimate matches reality (code):
, the developer estimate matches reality (code):

The effect of noise is to increase probability estimates for events whose actually probability is less than 0.5, and to decrease the probability when the actual is greater than 0.5. All estimates move towards 0.5.
What other estimation behaviors does this noise model predict?
If there are two events, say  and
and  , then the noise model (and probability theory) specifies that the following relationship holds:
, then the noise model (and probability theory) specifies that the following relationship holds:
+P(B) == P(A & B)+P(A delim{|}{B}{})")
where: ") denotes the probability of its argument.
denotes the probability of its argument.
The experimental results show that this relationship does hold, i.e., the noise model is consistent with the experiment results.
This noise model can be used to explain the conjunction fallacy, i.e., Tversky & Kahneman’s famous 1970s “Lindy is a bank teller” experiment.
What predictions does the noise model make about the estimated probability of experiencing  (
( ) occurrences of the event in a sequence of
) occurrences of the event in a sequence of  assorted events (the previous analysis deals with the case
assorted events (the previous analysis deals with the case  )?
)?
An estimation model that takes account of noise gives the equation:

where:  is the developer’s estimated probability of experiencing s in a sequence of length , and
is the developer’s estimated probability of experiencing s in a sequence of length , and  is the actual probability of there being .
is the actual probability of there being .
The plot below shows actual event probability against developer estimated probability for various values of , with a red line showing that at , the developer estimate matches reality (code):

This predicted behavior, which is the opposite of the case where , follows the same pattern seen in experiments, i.e., actual probabilities less than 0.5 are decreased (towards zero), while actual probabilities greater than 0.5 are increased (towards one).
There have been replications and further analysis of the predictions made by this model, along with alternative models that incorporate noise.
To summarise:
When estimating the probability of a single event/item occurring, noise/uncertainty will cause the estimated probability to be closer to 50/50 than the actual probability.
When estimating the probability of multiple events/items occurring, noise/uncertainty will cause the estimated probability to move towards the extremes, i.e., zero and one.
Evolution has selected humans to prefer adding new features
Assume that clicking within any of the cells in the image below flips its color (white/green). Which cells would you click on to create an image that is symmetrical along the horizontal/vertical axis?

In one study, 80% of subjects added a block of four green cells in each of the three white corners. The other 20% (18 of 91 subjects) made a ‘subtractive’ change, that is, they clicked the four upper left cells to turn them white (code+data).
The 12 experiments discussed in the paper People systematically overlook subtractive changes by Adams, Converse, Hales, and Klotz (a replication) provide evidence for the observation that when asked to improve an object or idea, people usually propose adding something rather than removing something.
The human preference for adding, rather than removing, has presumably evolved because it often provides benefits that out weigh the costs.
There are benefits/costs to both adding and removing.
Creating an object:
- may produce a direct benefit and/or has the potential to increase the creator’s social status, e.g., ‘I made that’,
- incurs the cost of time and materials needed for the implementation.
Removing an object may:
- produce savings, but these are not always directly obvious, e.g., simplifying an object to reduce the cost of adding to it later. Removing (aka sacking) staff is an unpopular direct saving,
- generate costs by taking away any direct benefits it provides and/or reducing the social status enjoyed by the person who created it (who may take action to prevent the removal).
For low effort tasks, adding probably requires less cognitive effort than removing; assuming that removal is not a thoughtless activity. Chesterton’s fence is a metaphor for prudence decision-making, illustrating the benefit of investigating to find out if any useful service provided by what appears to be a useless item.
There is lots of evidence that while functionality is added to software systems, it is rarely removed. The measurable proxy for functionality is lines of code. Lots of source code is removed from programs, but a lot more is added.
Some companies have job promotion requirements that incentivize the creation of new software systems, but not their subsequent maintenance.
Open source is a mechanism that supports the continual adding of features to software, because it does not require funding. The C++ committee supply of bored consultants proposing new language features, as an outlet for their creative urges, will not dry up until the demand for developers falls below the supply of developers.
Update
The analysis in the paper More is Better: English Language Statistics are Biased Toward Addition by Winter, Fischer, Scheepers, and Myachykov, finds that English words (based on the Corpus of Contemporary American English) associated with an increase in quantity or number are much more common than words associated with a decrease. The following table is from the paper:
Word Occurrences
add 361,246
subtract 1,802
addition 78,032
subtraction 313
plus 110,178
minus 14,078
more 1,051,783
less 435,504
most 596,854
least 139,502
many 388,983
few 230,946
increase 35,247
decrease 4,791 |
Deciding whether a conclusion is possible or necessary
Psychologists studying human reasoning have primarily focused on syllogistic reasoning, i.e., the truthfulness of a necessary conclusion from two stated premises, as in the following famous example:
All men are mortal.
Socrates is a man.
Therefore, Socrates is mortal. |
Another form of reasoning is modal reasoning, which deals with possibilities and necessities; for example:
All programmers like jelly beans,
Tom likes jelly beans,
Therefore, it is possible Tom is a programmer. |
Possibilities and necessities are fundamental to creating software. I would argue (without evidence) that possibility situations occur much more frequently during software development than necessarily situations.
What is the coding impact of incorrect Possible/Necessary decisions (the believability of a syllogism has been found to influence subject performance)?
- Conclusion treated as possible, while being necessary: A possibility involves two states, while necessity is a single state. A possible condition implies coding an
if/else(or perhaps one arm of anif), while a necessary condition is at most one arm of anif(or perhaps nothing).The likely end result of making this incorrect decision is some dead code.
- Conclusion treated as necessary, while being possible: Here two states are considered to be a single state.
The likely end result of making this incorrect decision is incorrect code.
What have the psychology studies found?
The 1999 paper: Reasoning About Necessity and Possibility: A Test of the Mental Model Theory of Deduction by J. St. B. T. Evans, S. J. Handley, C. N. J. Harper, and P. N. Johnson-Laird, experimentally studied three predictions (slightly edited for readability):
- People are more willing to endorse conclusions as Possible than as Necessary.
- It is easier to decide that a conclusion is Possible if it is also Necessary. Specifically, we predict more endorsements of Possible for Necessary than for Possible problems.
- It is easier to decide that a conclusion is not Necessary if it is also not Possible. Specifically, we predict that more Possible than Impossible problems will be endorsed as Necessary.
Less effort is required to decide that a conclusion is Possible because just one case needs to be found, while making a Necessary decision requires evaluating all cases.
In one experiment, subjects (120 undergraduates studying psychology) saw a screen containing a question such as the following (an equal number of questions involved NECESSARY/POSSIBLE):
GIVEN THAT
Some A are B
IS IT NECESSARY THAT
Some B are not A |
Subjects saw each of the 28 possible combinations of four Premises and seven Conclusions. The table below shows eight combinations of the four Premises and seven conclusions, the Logic column shows the answer (N=Necessary; I=Impossible; P=Possible), and the Necessary/Possible columns show the number of subjects answering that the conclusion was Necessary/Possible:
Premise Conclusion Logic Necessary Possible All A are B Some A are B N 65 82 All A are B No A are B I 3 12 Some A are B All A are B P 3 53 Some A are B No A are B I 8 55 No A are B Some A are not B N 77 80 No A are B No B are A I 7 25 Some A are not B All A are B I 2 3 Some A are not B Some B are A P 70 95 |
The table below shows the percentage of answer specifying that the conclusion was Necessary/Possible (2nd/3rd rows), when the Logical answer was one of Impossible/Necessary/Possible (code+data):
Logic I N P
N 8% 59% 38%
P 19% 71% 60% |
The percentage of Possible answers is always much higher than Necessary answers (when a Conclusion is Necessary, it is also Possible), even when the Conclusion is Impossible. The 38% of Necessary answers for when the Conclusion is only Possible is somewhat concerning, as this decision could produce coding mistakes.
The paper ran a second experiment involving two premises, like the Jelly bean example, attempting to distinguish strong/weak forms of Possible.
Do these results replicate?
The 2024 study Necessity, Possibility and Likelihood in Syllogistic Reasoning by D. Brand, S. Todorovikj, and M. Ragni, replicated the results. This study also investigated the effect of using Likely, as well as Possible/Necessary. The results showed that responses for Likely suggested it was a middle ground between Possible/Necessary.
After writing the above, I asked Grok: list papers that have studied the use of syllogistic reasoning by software developers: nothing software specific. The same question for modal reasoning returned answers on the use of Modal logic, i.e., different subject. Grok did a great job of summarising the appropriate material in my Evidence-base Software Engineering book.
CPU power consumption and bit-similarity of input
Changing the state of a digital circuit (i.e., changing its value from zero to one, or from one to zero) requires more electrical power than leaving its state unchanged. During program execution, the power consumed by each instruction depends on the value of its operand(s). The plot below, from an earlier post, shows how the power consumed by an 8-bit multiply instruction varies with the values of its two operands:
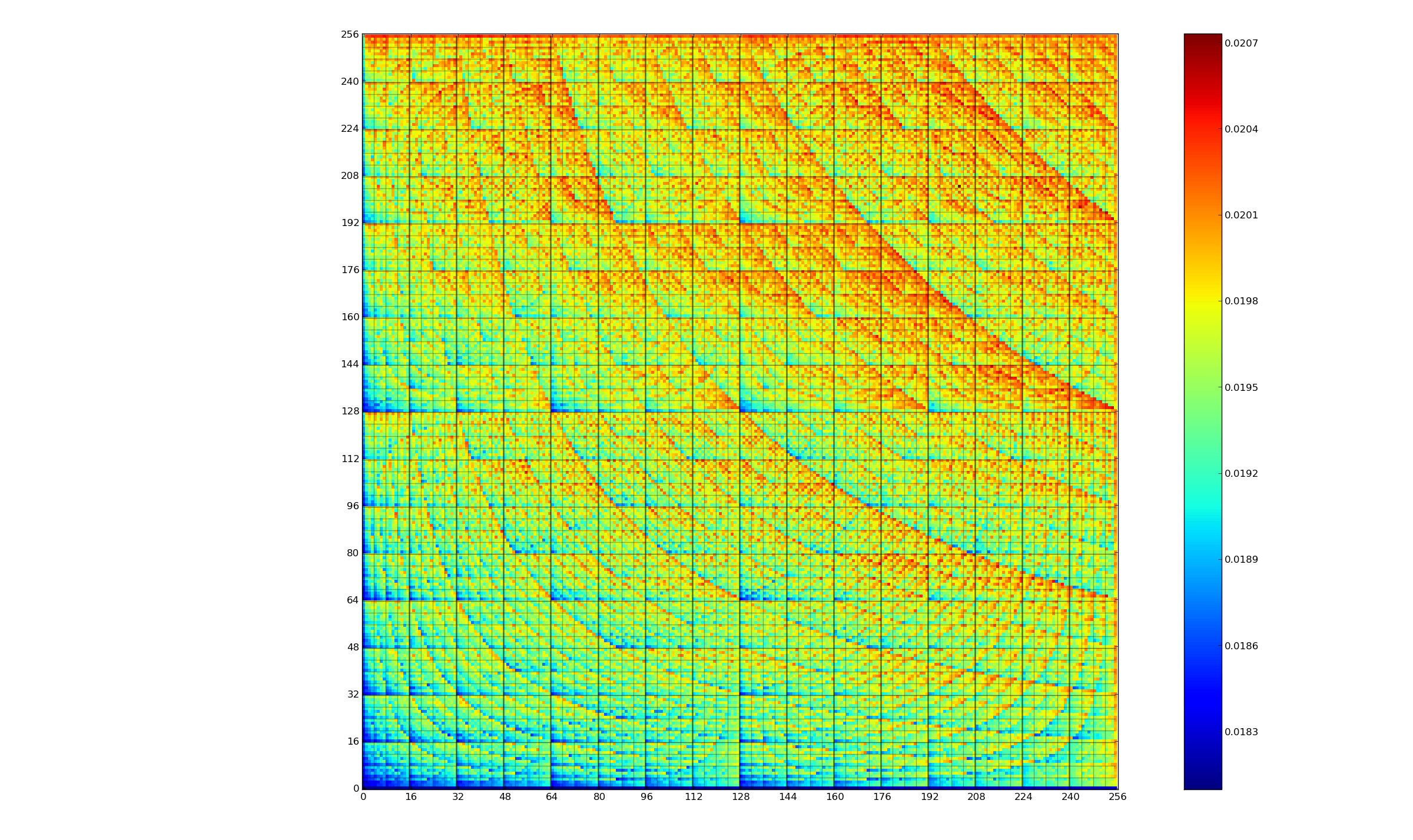
An increase in cpu power consumption produces an increase in its temperature. If the temperature gets too high, the cpu’s DVFS (dynamic voltage and frequency scaling) will slow down the processor to prevent it overheating.
When a calculation involves a huge number of values (e.g., an LLM size matrix multiply), how large an impact is variability of input values likely to have on the power consumed?
The 2022 paper: Understanding the Impact of Input Entropy on FPU, CPU, and GPU Power by S. Bhalachandra, B. Austin, S. Williams, and N. J. Wright, compared matrix multiple power consumption when all elements of the matrices had the same values (i.e., minimum entropy) and when all elements had different random values (i.e., maximum entropy).
The plot below shows the power consumed by an NVIDIA A100 Ampere GPU while multiplying two 16,384 by 16,384 matrices (performed 100 times). The GPU was power limited to 400W, so the random value performance was lower at 18.6 TFLOP/s, against 19.4 TFLOP/s for same values; (I don’t know why the startup times differ; code+data):
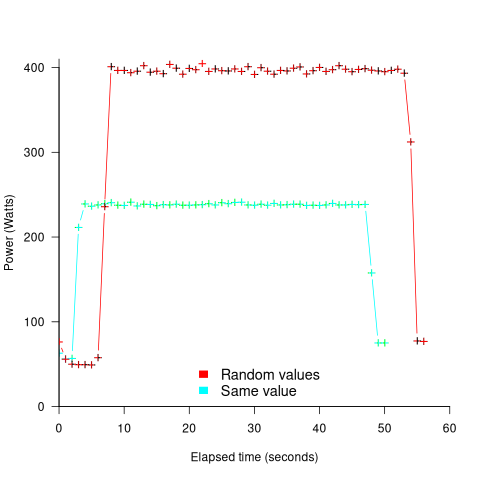
This 67% performance difference is more than an interesting factoid. Large computations are distributed over multiple GPUs, and the output from each GPU is sometimes feed as input to other GPUs. The flow of computations around a cluster of GPUs needs to be synchronised, and having compute time depend on the distribution of the input values makes life complicated.
Is it possible to organise a sequence of calculation to reduce the average power consumed?
The higher order bits of small integers are zero, but how many long calculations involve small integers? The bit pattern of floating-point values are more difficult to predict, but I’m sure there is a PhD thesis or two waiting to be written around this issue.
Comparing developer/LLM coding performance
Lots of claims are being made about how LLMs will soon outperform developers on coding tasks. Given the lack of any effective measure of developer performance, these claims are meaningless. At some point, lower costs will entice management to accept good enough LLM performance as a replacement for human developers, i.e., LLM don’t need to be technically better than developers.
The outperform claims are, currently, marketing puff, and I was not expecting anybody to make a serious attempt to compare developer/LLM performance. However, concerns about AI exceeding human capacity to control it (and maybe wiping out humans) has resulted in some well funded AI safety research groups. There is at least one group actively recruiting developers to “… establish human performance baselines on tasks related to software engineering, machine learning, and cybersecurity …”.
The most talked about AI threat scenarios all seem to start with recursive self-improvement, i.e., LLMs training themselves, exponentially improving with each iteration (the implied exponential always seems to be continuously up, rather than getting exponentially closer to a maximum).
Can current LLMs improve themselves faster than a developer can?
Implementing a new LLM is beyond the ability of today’s LLM, but they can implement some of the components used to build an LLM. How does LLM performance compare against developers, on the implementation of these components?
The paper RE-Bench: Evaluating frontier AI R&D capabilities of language model agents against human experts from METR (Model Evaluation & Threat Research) comes with code and “… anonymized human expert data coming soon.” for seven tasks. The baseline was derived from the performance of 61 human experts.
I’m always pleased to see researchers doing experiments with developers. I wish there were more groups doing this kind of thing.
However, I think that these researchers have made the common mistake of using very complicated subject tasks in their experiment. Most software development tasks are mundane, with the occasional complicated task (which can often be solved by using an appropriate package/library). The tasks may be representative of the harder tasks that need to be done, but they are not representative of the complete LLM implementation scenario.
A consequence of using complicated tasks is that most subjects only had enough time to complete one task (they were given 8 hours). With so few tasks (seven) the confidence intervals are going to be very wide on any general statement about human/LLM performance. With around ten subjects per task, the individual task confidence intervals are also going to be wide.
Task 7 made me laugh: “… that generates solutions to CodeContests problems in Rust, …”
Why Rust? Did they happen to have access to lots of Rust experts, or does the research group contain enthusiastic fans of Rust? I suspect the latter. There is a certain kind of highly intelligent developer who strongly believes that writing programs in a particular language imbues the code with magical properties (their rationale won’t be worded that way). For the last few years, Rust has been one of these pixie dust languages. Many decades ago, C had this charisma.
Perhaps each generation of ever more ‘intelligent’ LLMs will choose to design a new language to use to implement their ‘successor’.
There are a myriad of tasks related to software engineering. Solving GitHub issues is a thankless task, and having LLMs reliably close open issues would be of enormous benefit. A study published two months ago obtained a 1.96% solution rate (no explicit testing of developers).
Indented vs non-indented if-statements: performance difference
To non-developers discussions about the visual layout of source code can seem somewhat inconsequential. Layout probably ought to be inconsequential, being based on experimental studies that discovered how source should be visually organised to minimise the cognitive effort consumed by developers while processing it.
In practice software engineering is not evidence-based. There are two kinds of developers: those willing to defend to the death the layout they use, and those that have moved on.
In its simplest form visual layout involves indenting code some number of spaces from the left margin. Use of indentation has not always been widespread, and people wrote papers extolling the readability benefits of indenting code.
My experience with talking to developers about indentation is that they are heavily influenced by the indentation practices adopted by those around them when first learning a language. Layout habits from any prior language tend to last awhile, depending on the amount of time spent with the prior language.
As far as I know, I have had zero success arguing that the Gestalt principles of perception provide a useful framework for deciding between different code layouts.
The layout issue that attracts the most discussion is probably the indentation of if-statements. What, if any, is the evidence around this issue?
Developer indentation discussions focus on which indentation is better than the alternatives (whatever better might be). A more salient question would be the size of the developer performance difference, or is the difference large enough to care about?
Researchers have used several techniques for measuring difference in developer performance, including: code comprehension (i.e., number of correct answers to questions about the code they have just read), subjective ratings (i.e., how hard did the subjects find the task), and time to complete a task (e.g., modify source, find coding mistake).
The subjects have invariably been a small sample of undergraduates studying for a computing degree, so the usual caveats about applicability to professional developers apply.
Until 2023, the most detailed work I know of is a PhD thesis from 1974 studying the impact of mnemonic/meaningless variable names plus none/some indentation (experiments 1, 2 and 9), and a 1983 paper which compared subject performance with indentation of none and 2/4/6 spaces (contains summary data only). Both studies used small programs.
The 2023 paper Indentation in Source Code: A Randomized Control Trial on the Readability of Control Flows in Java Code with Large Effects by J. Morzeck, S. Hanenberg, O. Werger, and V. Gruhn measured the time taken by 20 subjects to answer 12 questions about the value printed by a randomly generated program containing a nested if-statement. The following shows an example without/with indentation (values were provided for i and j):
if (i != j) { if (i != j) { if (j > 10) { if (j > 10) { if (i < 10) { if (i < 10) { print (5); print (5); } else { } else { print (10); print (10); } } } else { } else { print (12); print (12); } } } else { } else { if (i < 10) { if (i < 10) { print (23); print (23); } else { } else { print (15); print (15); } } } } |
A fitted regression model found that the average response time of 122 seconds (yes, very slow) for non-indented code decreased to 44 seconds (not quite as slow) for indented code, i.e., about three times faster (code+data). This huge performance improvement is very different from most software engineering experiments where the largest effect is the between subjects performance, with learning producing the next largest effect.
Evidence that indentation is very effective, but nobody doubted this. There has been a follow-up study, more on that another time.
Measuring non-determinism in the Linux kernel
Developers often assume that it’s possible to predict the execution path a program will take, for a given set of input values, i.e., program behavior is deterministic. The execution path may be very complicated, and may depend on the contents of certain files (e.g., SQL engines), but it’s deterministic.
There is one kind of program where determinism is not an option; operating systems are non-deterministic when running in a mode where interrupts can occur.
How much non-determinism can occur in, say, Linux? For instance, when a program calls a system function (e.g., open, read, write, close), how often does the execution sequence follow the function call tree that appears in the source code, and how many different call sequences actually occur during program execution (because of diversions caused by an interrupt; ignoring control flow within functions)?
A study by Imanol Allende ran the same program 500K+ times, and traced every function call that occurred within the Linux kernel (thanks to Imanol for sending me the data and answering my questions). The program used appears below; the system calls traced were open (two distinct calls), read, write, and close (two distinct calls); a total of six system calls.
// #includes omitted int main(int argc, char **argv) { unsigned char result; int fd1, fd2, ret; char res_str[10]={0}; fd1 = open("/dev/urandom", O_RDONLY); fd2 = open("/dev/null", O_WRONLY); ret = read(fd1 , &result, 1); sprintf(res_str ,"%d", result); ret = write(fd2, res_str, strlen(res_str)); close(fd1); close(fd2); return ret; } |
Analysing each of these six distinct calls, in around 98% of program runs, each call follows the same sequence of function calls within the kernel (the common case for write involves a chain of around 10 function calls). During the other 2’ish% of calls, the common sequence was interrupted for some reason, and the logged call trace includes additional called functions, e.g., calls involving the Read, Copy, Update synchronization mechanism. The plot below shows the growth in the number of unique traces against the number of program runs (436,827 of them) for the close(fd2) call; a fitted regression line is in red, with the first 1,000 runs not included in the fit (code+data):
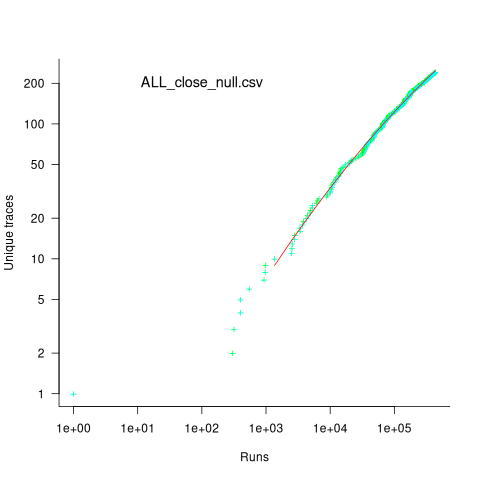
The fitted regression model is ^2") , suggesting that the growth in unique traces is slowing (this equation peaks at around
, suggesting that the growth in unique traces is slowing (this equation peaks at around  ), while the model fitted to some of the system calls implies ever continuing growth.
), while the model fitted to some of the system calls implies ever continuing growth.
Allende investigated more sophisticated techniques for estimating the total number of unique traces, including: extreme value theory and species estimation techniques from ecology.
While around 98% of traces are the common case, over half of the unique traces occurred once in 436,827 runs. The plot below shows the number of occurrences of each unique trace, for the close(fd2) call, with an attempted fit of a bi-exponential model (in red; code+data):
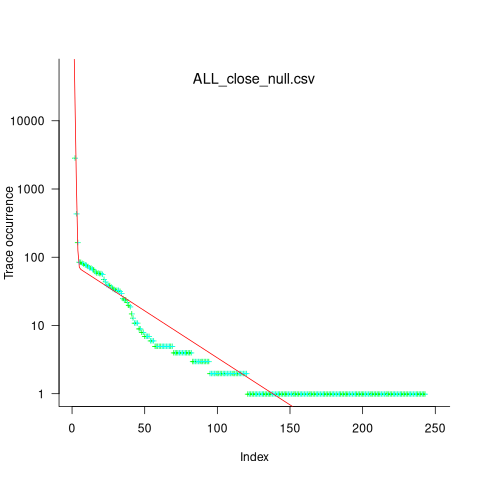
The analysis above looked at one system call, the program contains six system calls. If, for each system call, the probability of the most common trace is 98%, then the probability of all six calls following their respective common case is 89%. As the number of distinct system calls made by a program goes up, the global common case becomes less common, and the number of distinct program traces increases multiplicatively.
A surprising retrospective task estimation dataset
When estimating the time needed to implement a task, the time previously needed to implement similar tasks provides useful guidance. The implementation time for these previous tasks may itself be estimated, because the actual time was not measured or this information is currently unavailable.
How accurate are developer time estimates of previously completed tasks?
I am not aware of any software related dataset of estimates of previously completed tasks (it’s hard enough finding datasets containing information on the actual implementation time). However, I recently found the paper Dynamics of retrospective timing: A big data approach by Balcı, Ünübol, Grondin, Sayar, van Wassenhove, and Wittmann. The data analysed comes from a survey questionnaire, where 24,494 people estimated the how much time they had spent answering the questions, along with recording the current time at the start/end of the questionnaire. The supplementary data is in MATLAB format, and is also available as a csv file in the Blursday database (i.e., RT_Datasets).
Some of the behavior patterns seen in software engineering estimates appear to be general human characteristics, e.g., use of round numbers. An analysis of the estimation performance of a wide sample of the general population could help separate out characteristics that are specific to software engineering and those that apply to the general population.
The following table shows the percentage of answers giving a particular Estimate and Actual time, in minutes. Over 60% of the estimates are round numbers. Actual times are likely to be round numbers because people often give a round number when asked the time (code+data):
Minutes Estimate Actual
20 18% 8.5%
15 15% 5.3%
30 12% 7.6%
25 10% 6.2%
10 7.7% 2.1% |
I was surprised to see that the authors had fitted a regression model with the Actual time as the explanatory variable and the Estimate as the response variable. The estimation models I have fitted always have the roles of these two variables reversed. More of this role reversal difference below.
The equation fitted to the data by the authors is (they use the term Elapsed, for consistency with other blog articles I continue to use Actual; code+data):

This equation says that, on average, for shorter Actual times the Estimate is higher than the Actual, while for longer Actual times the average Estimate is lower.
Switching the roles of the variables, I expected to see a fitted model whose coefficients are somewhat similar to the algebraically transformed version of this equation, i.e.,  . At the very least, I expected the exponent to be greater than one.
. At the very least, I expected the exponent to be greater than one.
Surprisingly, the equation fitted with the variables roles reversed is very similar, i.e., the equations are the opposite of each other:

This equation says that, on average, for shorter Estimate times the Actual time is higher than the Estimate, while for longer Estimate times the average Actual is lower, i.e., the opposite behavior specifie dby the earlier equation.
I spent some time trying to understand how it was possible for data to be fitted such that (x ~ y) == (y ~ x), even posting a question to Cross Validated. I might, in a future post, discuss the statistical issues behind this behavior.
So why did the authors of this paper treat Actual as an explanatory variable?
After a flurry of emails with the lead author, Fuat Balcı (who was very responsive to my questions), where we both doubled checked the code/data and what we thought was going on, Fuat answered that (quoted with permission):
“The objective duration is the elapsed time (noted by the experimenter based on a clock reading), and the estimate is the participant’s response. According to the psychophysical approach the mapping between objective and subjective time can be defined by regressing the subjective estimates of the participants on the objective duration noted by the experimenter. Thus, if your research question is how human’s retrospective experience of time changes with the duration of events (e.g., biases in time judgments), the y-axis should be the participant’s response and the x-axis should be the actual duration.”
This approach has a logic to it, and is consistent with the regression modelling done by other researchers who study retrospective time estimation.
So which modelling approach is correct, and are people overestimating or underestimating shorter actual time durations?
Going back to basics, the structure of this experiment does not produce data that meets one of the requirements of the statistical technique we are both using (ordinary least squares) to fit a regression model. To understand why ordinary least squares, OLS, is not applicable to this data, it’s necessary to delve into a technical detail about the mathematics of what OLS does.
The equation actually fitted by OLS is:  , where
, where  is an error term (i.e., ‘noise’ caused by all the effects other than ). The value of is assumed to be exact, i.e., not contain any ‘noise’.
is an error term (i.e., ‘noise’ caused by all the effects other than ). The value of is assumed to be exact, i.e., not contain any ‘noise’.
Usually, in a retrospective time estimation experiment, subjects hear, for instance, a sound whose duration is decided in advance by the experimenter; subjects estimate how long each sound lasted. In this experimental format, it makes sense for the Actual time to appear on the right-hand-side as an explanatory variable and for the Estimate response variable on the left-hand-side.
However, for the questionnaire timing data, both the Estimate and Actual time are decided by the person giving the answers. There is no experimenter controlling one of the values. Both the Estimate and Actual values contain ‘noise’. For instance, on a different day a person may have taken more/less time to actually answer the questionnaire, or provided a different estimate of the time taken.
The correct regression fitting technique to use is errors-in-variables. An errors-in-variables regression fits the equation:  + epsilon") , where:
, where:  is the true value of and
is the true value of and  is its associated error. A selection of packages are available for fitting a variety of errors-in-variables models.
is its associated error. A selection of packages are available for fitting a variety of errors-in-variables models.
I regularly see OLS used in software engineering papers (including mine) where errors-in-variables is the technically correct technique to use. Researchers are either unaware of the error issues or assuming that the difference is not important. The few times I have fitted an errors-in-variables model, the fitted coefficients have not been much different from those fitted by an OLS model; for this dataset the coefficient difference is obviously important.
The complication with building an errors-in-variables model is that values need to be specified for the error terms and . With OLS the value of is produced as part of the fitting process.
How might the required error values be calculated?
If some subjects round reported start/stop times, there may not be any variation in reported Actual time, or it may jump around in 5-minute increments depending on the position of the minute hand on the clock.
Learning researchers have run experiments where each subject performs the same task multiple times. Performance improves with practice, which makes it difficult to calculate the likely variability in the first-time performance. If we assume that performance is skill based, the standard deviation of all the subjects completing within a given timeframe could be used to calculate an error term.
With 60% of Estimates being round numbers, there might not be any variation for many people, or perhaps the answer given will change to a different round number. There is Estimate data for different, future tasks, and a small amount of data for the same future tasks. There is data from many retrospective studies using very short time intervals (e.g., tens of seconds), which might be applicable.
We could simply assume that the same amount of error is present in each variable. Deming regression is an errors-in-variables technique that supports this approach, and does not require any error values to be specified. The following equations have been fitted using Deming regression (code+data):

and

While these two equations are consistent with each other, we don’t know if the assumption of equal errors in both variables is realistic.
What next?
Hopefully it will be possible to work out reasonable error values for the Actual/Estimate times. Fitting a model using these values will tell us wether any over/underestimating is occurring, and the associated span of time durations.
I also need to revisit the analysis of software task estimation times.
Recent Comments