Halstead & McCabe metrics: The wisdom of the ancients
Study after study finds that the predictive power of both the Halstead metric and the McCabe cyclomatic complexity metric is no better than counting lines of code, for the characteristics of interest. Why do people continue to use and cite the Halstead and McCabe metrics?
My experience, talking to people, is that many believe these metrics have greater predictive power than lines of code. Sometimes I explain the situation, other times I move on.
Those who are aware of the facts often continue to use these metrics. Why do they do this?
Given the lack of alternative metrics that are more effective than lines of code, for the claimed uses of Halstead/McCabe, following the herd is the easy option (I regularly point this out to people, after explaining that Halstead/McCabe don’t do what is claimed on the tin). Tools are available to calculate the metrics; the manual effort is clicking buttons or running a command.
Why were the Halstead/McCabe metrics ‘successful’, in that they are the ones people cite/use today?
Both were formulated in the mid-1970s, when the discussion around measuring software started in earnest, so they had some first-mover advantage (within a few years they were both being suggested for use by US Military). Individuals promoted their ideas: Maurice Halstead was a senior professor, with colleagues and lots of graduate students, who advertised the metric via their publications; Thomas McCabe was working for the NSA when his famous paper was published, and went on to form a company working in the area of source code analysis.
The Halstead/McCabe metrics can both be calculated by processing the source one line at a time (just count decision points for McCabe, no need for the pretentious graph theory stuff). In the 1970s, computer memory was often measured in kilobytes, which made it difficult to implement complicated metrics that required keeping dependency information in memory.
Metrics based on the subroutine/function/procedure/method as the measured unit of source code had an implementation and usage advantage over metrics based on larger units of code.
In the 1990s, object-oriented programming, in the form of C++ and then Java, took off. The common view, by those caught up in the times, was that object-oriented software was so different from what went before that it needed its own metrics.
The 1991 paper: Towards a Metrics Suite for Object Oriented Design, by Chidamber and Kemerer, introduced the six CK metrics (as they become known; 1992 update). The nearest this paper comes to citing the Halstead/McCabe work is to say: “Some early work has recognized the shortcomings of existing metrics and the need for new metrics especially designed for OO.” The paper followed in the footsteps of the earlier work in not providing any evidence for the claims made (the update contains histograms of metric values from a C++ project and a Smalltalk project).
The 1996 paper: Evaluating the Impact of Object-Oriented Design on Software Quality, by Abreu and Melo, introduced the MOOD metrics (Metrics for Object-Oriented Design).
At the end of 2022 the total citation counts returned by Google Scholar were: McCabe 8,670, Halstead 4,900, CK 8,160, and MOOD 354.
The plot below shows the number of new citations returned by Google Scholar, each year, for the respective metrics papers (or book for Halstead; code+data):
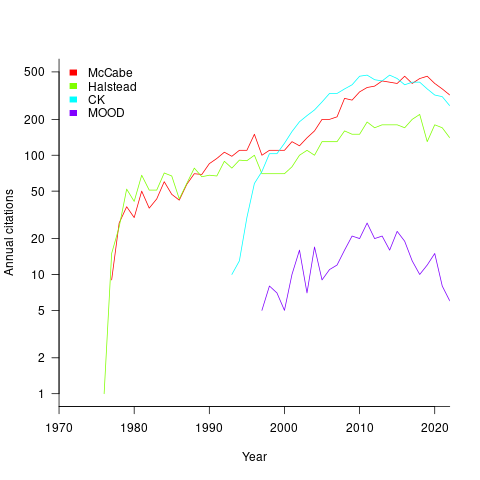
The ongoing growth in annual rate of citation probably has more to do with the growth in the number of software papers published each year, rather than these metric papers being cited by an expanding number of research fields.
Do authors tend to cite one or the other of Halstead/McCabe, or both?
Using Google Scholar’s ‘search within’ option to find the subset of papers that included a string matching the title of a paper: 46% of the Halstead citations include a citation of the McCabe paper, and 25% of the McCabe citations include a citation of the Halstead paper.
The Inciteful’s paper network (with citation counts: Halstead 1,052 and McCabe 4,970) found 657 papers citing both (62% of the Halstead total, 12% of the McCabe).
It’s not possible to make use of the OpenCitations API because it is DOI based, and the Halstead citation is a book.
The only metric I give credence to is Kolmogorov Complexity, which answers a completely different question, the information content of the problem domain, and is much more interesting than metrics beloved of micromanagers.
@Fazal Majid
Kolmogorov Complexity has the ‘benefit’ that it’s impractical to calculate, so you can claim whatever value is helpful. But then I remember a paper from a few years ago which calculated the value for strings up to 5(?) characters. I have it stored some-place safe, which I will find real soon now…
Interesting article. Recently, I started reading some studies that used the electroencephalogram on programmers to evaluate cognitive effort when reading code, and then compare it with code metrics (such as Halstead, McCabe, Cognitive Complexity, among others). The results of the studies suggest that the way the human brain understands code complexity is different from those assessed by current metrics.
Besides the number of lines of code (maybe even indentation), what other code metrics do you know of that are useful for improving software quality?
@Adriel Bento
Nobody has done the experimental research needed to find a metric that is more informative than lines of code. Readability research is mostly opinions, but researchers are starting to use eye trackers to find out what developers are actually looking at.
The Human cognition chapter of my Evidence-based software engineering book contains lots of references to material that may be of use to you.