Sample size needed to compare performance of two languages
A humungous organization wants to minimise one or more of: program development time/cost, coding mistakes made, maintenance time/cost, and have decided to use either of the existing languages X or Y.
To make an informed decision, it is necessary to collect the required data on time/cost/mistakes by monitoring the development process, and recording the appropriate information.
The variability of developer performance, and language/problem interaction means that it is necessary to monitor multiple development teams and multiple language/problem pairs, using statistical techniques to detect any language driven implementation performance differences.
How many development teams need to be monitored to reliably detect a performance difference driven by language used, given the variability of the major factors involved in the process?
If we assume that implementation times, for the same program, have a normal distribution (it might lean towards lognormal, but the maths is horrible), then there is a known formula. Three values need to be specified, and plug into this formula: the statistical significance (i.e., the probability of detecting an effect when none is present, say 5%), the statistical power (i.e., the probability of detecting that an effect is present, say 80%), and Cohen’s d; for an overview see section 10.2.
Cohen’s d is the ratio }/sigma") , where
, where  and
and  is the mean value of the quantity being measured for the programs written in the respective languages, and
is the mean value of the quantity being measured for the programs written in the respective languages, and  is the pooled standard deviation.
is the pooled standard deviation.
Say the mean time to implement a program is , what is a good estimate for the pooled standard deviation, , of the implementation times?
Having 66% of teams delivering within a factor of two of the mean delivery time is consistent with variation in LOC for the same program and estimation accuracy, and if anything sound slow (to me).
Rewriting the Cohen’s d ratio: }/{2*mu_x}={abs(1-{mu_y}/mu_x)}/2")
If the implementation time when using language X is half that of using Y, we get }/2=0.5") . Plugging the three values into the
. Plugging the three values into the pwr.t.test function, in R’s pwr package, we get:
> library("pwr")
> pwr.t.test(d=0.5, sig.level=0.05, power=0.8)
Two-sample t test power calculation
n = 63.76561
d = 0.5
sig.level = 0.05
power = 0.8
alternative = two.sided
NOTE: n is number in *each* group |
In other words, data from 64 teams using language X and 64 teams using language Y is needed to reliably detect (at the chosen level of significance and power) whether there is a difference in the mean performance (of whatever was measured) when implementing the same project.
The plot below shows sample size required for a t-test testing for a difference between two means, for a range of X/Y mean performance ratios, with red line showing the commonly used values (listed above) and other colors showing sample sizes for more relaxed acceptance bounds (code):
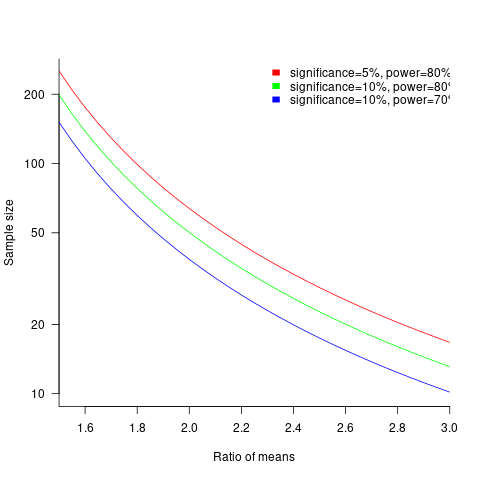
Unless the performance difference between languages is very large (e.g., a factor of three) the required sample size is going to push measurement costs into many tens of millions (£1 million per team, to develop a realistic application, multiplied by two and then multiplied by sample size).
For small programs solving certain kinds of problems, a factor of three, or more, performance difference between languages is not unusual (e.g., me using R for this post, versus using Python). As programs grow, the mundane code becomes more and more dominant, with the special case language performance gains playing an outsized role in story telling.
There have been studies comparing pairs of languages. Unfortunately, most have involved students implementing short problems, one attempted to measure the impact of programming language on coding competition performance (and gets very confused), the largest study I know of compared Fortran and Ada implementations of a satellite ground station support system.
The performance difference detected may be due to the particular problem implemented. The language/problem performance correlation can be solved by implementing a wide range of problems (using 64 teams per language).
A statistically meaningful comparison of the implementation costs of language pairs will take many years and cost many millions. This question is unlikely to every be answered. Move on.
My view is that, at least for the widely used languages, the implementation/maintenance performance issues are primarily driven by the ecosystem, rather than the language.
I fully agree with the last paragraph. Trying to introduce a possibly more suitable language is not an easy task (and sometimes a career-limiting task #6-). For embedded systems, one has the added yoke of whether certain languages and tools are even available for the particular processor.
@Nemo
Embedded systems tends to be a conservative ecosystem with regard to the software tools they use. This is very frustrating for the young guns wanting to use the latest fashionable thing, or to pad out their cv with some technology.