Projects are worked on in fits and starts
Companies whose business is designing, developing, and maintaining custom software applications (i.e., a software house) have the difficult job of keeping their expensive employees busy with paying work. Work on an existing project may be held up for various reasons, and the start date of new projects is invariably uncertain.
A solution to the on/off nature of project work is for staff to distribute their time across multiple projects. If one project is held up, there is another project available for them to book their time to.
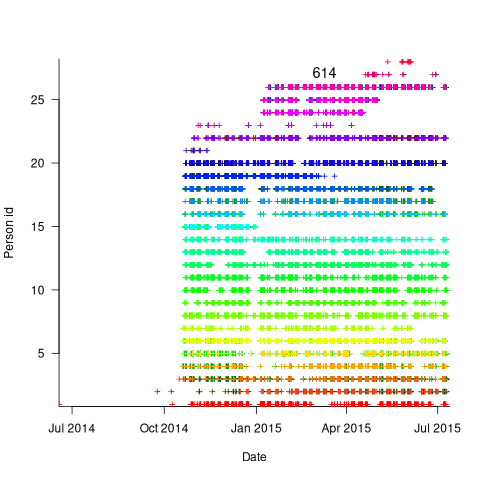
The plot below is for project 614 in the CESAW dataset, and shows the days on which 28 people worked on this project between July 2014 and July (code+data):
The published models of the software development lifecycle are based on perceptions of the workings of large DOD and NASA projects from the 1960s and 1970s. These projects are treated as self-contained entities, with people being available when needed and individually interchangeable. This perception fits with the software physics thinking of the time, along with the early 1960s work of Norden, and the use of differential equations to model the evolution of project manpower. These models fitted the small amount of available data as well as several other models. With some hand waving it is possible to make models such as the Putnam model look good.
With 28 people working on project 614, it’s possible that individual contributions don’t have a big impact on totals, i.e., the total time spent per week (say) does not fluctuate widely. The plot below shows the total hours per week spent on design, coding and test (total project time as roughly three staff years; code+data):
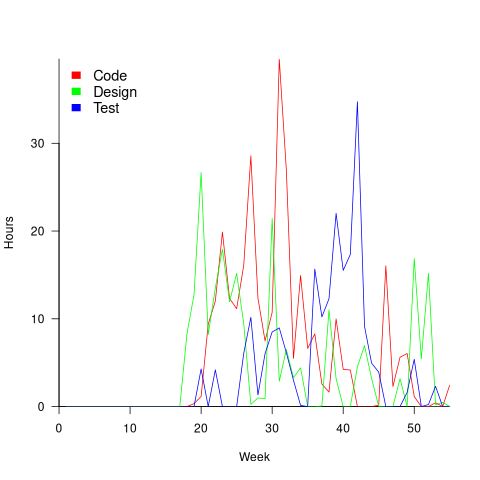
Plenty of wide fluctuations, plus some expected large drops in time spent on the project. For instance, a big drop in all activities around Christmas, and a smaller dip around Thanksgiving.
Having 28 people work on a three-person year project does seem a bit extreme (average of seven-weeks per person). On the other hand, I may be out of date, not having been a team member on a large project in decades.
The total effort required by the projects in the CESAW dataset range from three-person months to three-person years, which I suspect (no data on this question) straddles the range of time spent on the majority of software projects. The projects mostly involve people spending a non-large percentage of time on a project. The data is anonymised on a project basis, and it is not possible to count the number of projects a person is working on at any time.
To summarise: Building a good enough model of software project staffing requires taking into account organization wide staffing priorities. Existing models don’t do this.
Most companies have far to much WIP – work in progress – and that included projects. Thus stop-start project work is the norm. Add in BAU/DevOps and it is even more so.
Often the decision as to which project gets worked on (and which paused) is often down to decibel management rather than rational decisions.
One consequence of this is work estimation times are meaningless. You can have perfect estimates but if the project is paused – or even just disrupted by other work – then the estimates will be inaccurate (even before you consider switching overhead).
WIP is a good testable hypothesis. We should be able to compute WIP with the CESAW set. We can also look at gaps in actual work. My colleague Tapajit Dey did some work on this that are looing to publish in the next year.
We can also test the hypothesis that bork blocks affect the project. An alternative hypothesis is WIP goes up, but other work is worked on without closing out the other WIP.
I have to re-read Derek’s analysis to comment more.
For that “project”, the work is more or less ongoing. The plan increments are closer to what count as projects. That team (and some related ones) were pretty good at taking an incremental plan and refreshing it with a disciplined closeout procedure that make the independent increments look like part of one continuous project.
IIRC, that is a group that had real requirements engineers logging time to supply the work to the development staff.
@Bill Nichols
I picked that project because the plot looked good. The plots in our paper on the CESAW dataset were chosen for their variety. The SEA data warehouse ought to contain enough projects that common patterns emerge.
Why is WIP bad? Because it’s inventory that has not shipped, because the developers will spend time getting back up to speed to finish it off? There must be some good reasons why WIP exists, nobody seems to talk about these.