Archive
70% of new software engineering papers on arXiv are LLM related
Subjectively, it feels like LLMs dominate the software engineering research agenda. Are most researchers essentially studying “Using LLMs to do …”? What does the data on papers published since 2022, when LLMs publicly appeared, have to say?
There is usually a year or two delay between doing the research work and the paper describing the work appearing in a peer reviewed conference/journal. Sometimes the researcher loses interest and no paper appears.
Preprint servers offer a fast track to publication. A researcher uploads a paper, and it appears the next day, with a peer reviewed version appearing sometime later (or not at all). Preprint publication data provides the closest approximation to real-time tracking of research topics. arXiv is the major open-access archive for research papers in computing, physics, mathematics and various engineering fields. The software engineering subcategory is cs.SE; every weekday I read the abstracts of the papers that have been uploaded, looking for a ‘gold dust’ paper.
The python package arxivscraper uses the arXiv api to retrieve metadata associated with papers published on the site. A surprisingly short program extracted the 15,899 papers published in the cs.SE subcategory since 1st January 2022.
A paper’s titles had to capture people’s attention using a handful of words. Putting the name of a new tool/concept in the title is likely to attract attention. The three words in the phrase Large Language Model consume a lot of title space, but during startup the abbreviated form (i.e., LLM) may not be generally recognised. The plot below shows the percentage of papers published each month whose title (case-insensitive) is matched either the regular expression “llm” or “large language model” (code and data):

Peak Large Language Model appears to be at the end of 2024. As time goes by new phrases/abbreviations stop being new and attention is grabbed by other phrases. Did peak LLM in titles occur at the end of 2025?
A paper’s abstract summarises its contents and has space for a lot more words. The plot below shows the percentage of papers published each month whose abstract (case-insensitive) is matched by either the regular expression “llm” or “large language model” (code and data):
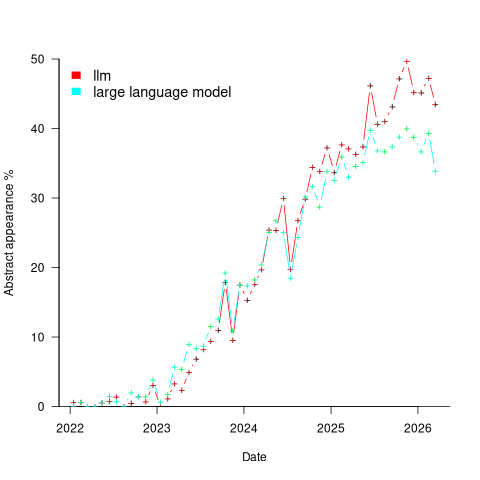
Peak, or plateauing, Large Language Model appears to be towards the end of 2025. Is the end of 2025 a peak of LLM in abstracts, or is it a plateauing with the decline yet to start? We should know by the end of this year.
Other phrases associated with LLMs are AI, artificial intelligence and agents. The plot below shows the percentage of papers published each month whose title (case-insensitive) is matched by each of the regular expressions “llm|large language model“, or “ ai[ ,.)]|artificial intellig“, or “agent” (code and data):
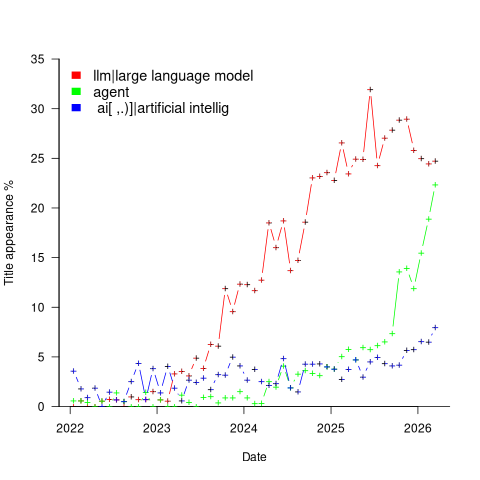
Counting the papers containing one or more of these LLM-related phrases gives an estimate of the number of software engineering papers studying this topic. The plot below shows the percentage of papers published each month whose title or abstract (case-insensitive) is matched by one or more of the regular expressions “llm|large language model“, or “ ai[ ,.)]|artificial intellig“, or “agent” (code and data):
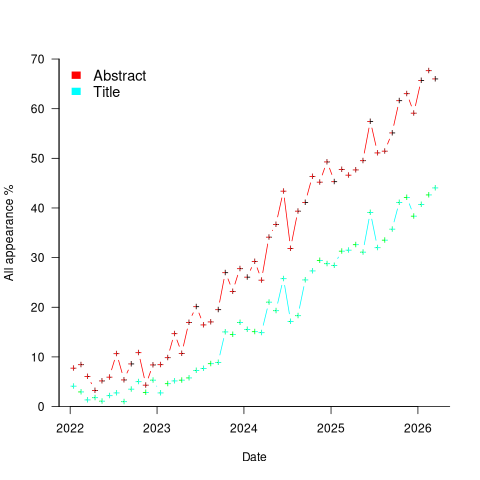
If the rate of growth is unchanged, around 18-month from now 100% of papers published in arXiv’s cs.SE subcategory will be LLM-related.
I expect the rate of growth to slow, and think it will stop before reaching 100% (I was expecting it to be higher than 70% in February). How much higher will it get? No idea, but herd mentality is a powerful force. Perhaps OpenAI going bankrupt will bring researchers to their senses.
Update
Martin Monperrus did an agentic replication of the analysis discussed in this post!
Recent Comments