Archive
Chinese research in software engineering
China and the Future of Science is the title of a recent article on the blog The Scholar’s Stage. In a series of posts the author, Tanner Greer, has been discussing how Chairman Xi and the Chinese central committee have reoriented the party towards a new goal. In 2026, the aim of China’s communist enterprise is to lead humanity through what they call “the next round of techno scientific revolution and industrial transformation.”.
The Chinese view is that: the first industrial revolution happened in Britain, which was the most powerful country of the 19th century; the second and third (computers) industrial revolutions happened in the USA, which was the most powerful country of the 20th century; the fourth industrial revolution is going to happen in China, which is going to be the most powerful country of the 21st century.
This is a software engineering blog, so I will leave the discussion of any fourth industrial revolution and whether China will lead it to others.
One practical consequence of the Chinese central committee’s focus is lots of funding for science/engineering research, and Chinese academics incentivised to do world-class work. How do you measure an individual’s or institution’s research performance? The Chinese have adopted the Western metric, i.e., counting papers published (weighted by journal impact factor) and number of citations. In 2025, eight of the top ten universities in the CWTS Leiden Ranking are Chinese, with the top western university in the number three spot and the other appearing at number ten. In 2005, six of the top ten universities were in the US.
In a post reviewing software engineering in 2023, I said: “it was very noticeable that many of the authors of papers at major conferences had Asian names. I would say that, on average, papers with Asian author names were better than papers by authors with non-Asian names.”
If software engineering researchers in China are publishing highly cited papers, why am I not seeing blog posts discussing them or hearing people talk about them? The answer is the same for Chinese and Western papers, i.e., little or no industrial relevance (when I point this out to academics they tell me that their work will be found to be relevant in years to come; ha ha {at least in software engineering}).
I label much of the research in software engineering as butterfly-collecting, in the sense that project source code is collected (often via GitHub) and various characteristics are measured and discussed. Much like the biological world was studied 200 years ago. There is no over arching theory, or attempt to model the relationships between different collections.
The incentives have pushed Chinese researchers, in software engineering, to become better butterfly collectors than Western researchers. Also, like Western researchers, they are mostly analysing the data using pre-computer statistical techniques.
If the aim is to publish papers and attract citations, it makes sense for Chinese researchers to study the same topics as Western researchers and analyse the data using the same (pre-computer) statistical techniques. Papers are more likely to be accepted for publication by Westerner reviewers when the subject matter is familiar to those reviewers. There are many tales of researchers having problems publishing papers that introduce new ideas and techniques.
The Central committee don’t just want to appear to be leading the world in engineering research, they want the Chinese to be making the discoveries that enable China to be the most powerful country in the world. For software engineering this means some Chinese researchers must stop following the research agenda set by their Western counterparts, and start asking “what are the important problems in software engineering“, and then researching those problems. If they are effective, a few will be enough.
My Evidence-based Software Engineering book lists and organises some of possible questions to ask, and also contains examples of modern statistical analysis.
China has lots of very good researchers. Perhaps they have all been sucked into the mania vortex around LLMs, and we will have to wait for things to subside. Remember, major discoveries are often made by small group of people.
70% of new software engineering papers on arXiv are LLM related
Subjectively, it feels like LLMs dominate the software engineering research agenda. Are most researchers essentially studying “Using LLMs to do …”? What does the data on papers published since 2022, when LLMs publicly appeared, have to say?
There is usually a year or two delay between doing the research work and the paper describing the work appearing in a peer reviewed conference/journal. Sometimes the researcher loses interest and no paper appears.
Preprint servers offer a fast track to publication. A researcher uploads a paper, and it appears the next day, with a peer reviewed version appearing sometime later (or not at all). Preprint publication data provides the closest approximation to real-time tracking of research topics. arXiv is the major open-access archive for research papers in computing, physics, mathematics and various engineering fields. The software engineering subcategory is cs.SE; every weekday I read the abstracts of the papers that have been uploaded, looking for a ‘gold dust’ paper.
The python package arxivscraper uses the arXiv api to retrieve metadata associated with papers published on the site. A surprisingly short program extracted the 15,899 papers published in the cs.SE subcategory since 1st January 2022.
A paper’s titles had to capture people’s attention using a handful of words. Putting the name of a new tool/concept in the title is likely to attract attention. The three words in the phrase Large Language Model consume a lot of title space, but during startup the abbreviated form (i.e., LLM) may not be generally recognised. The plot below shows the percentage of papers published each month whose title (case-insensitive) is matched either the regular expression “llm” or “large language model” (code and data):

Peak Large Language Model appears to be at the end of 2024. As time goes by new phrases/abbreviations stop being new and attention is grabbed by other phrases. Did peak LLM in titles occur at the end of 2025?
A paper’s abstract summarises its contents and has space for a lot more words. The plot below shows the percentage of papers published each month whose abstract (case-insensitive) is matched by either the regular expression “llm” or “large language model” (code and data):
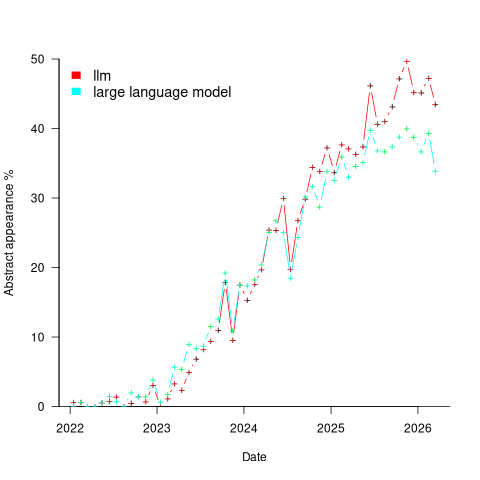
Peak, or plateauing, Large Language Model appears to be towards the end of 2025. Is the end of 2025 a peak of LLM in abstracts, or is it a plateauing with the decline yet to start? We should know by the end of this year.
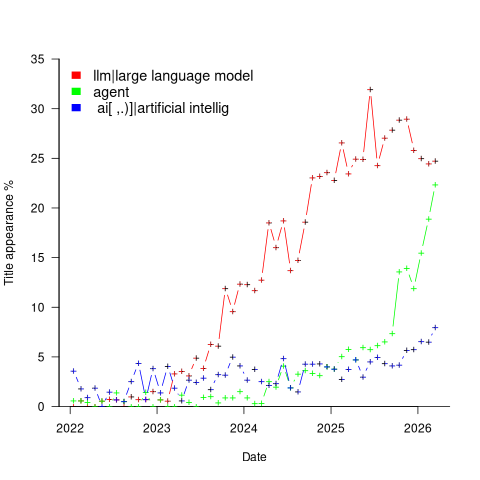
Other phrases associated with LLMs are AI, artificial intelligence and agents. The plot below shows the percentage of papers published each month whose title (case-insensitive) is matched by each of the regular expressions “llm|large language model“, or “ ai[ ,.)]|artificial intellig“, or “agent” (code and data):
Counting the papers containing one or more of these LLM-related phrases gives an estimate of the number of software engineering papers studying this topic. The plot below shows the percentage of papers published each month whose title or abstract (case-insensitive) is matched by one or more of the regular expressions “llm|large language model“, or “ ai[ ,.)]|artificial intellig“, or “agent” (code and data):
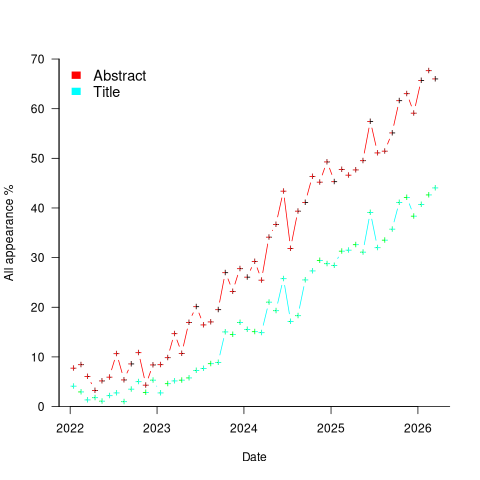
If the rate of growth is unchanged, around 18-month from now 100% of papers published in arXiv’s cs.SE subcategory will be LLM-related.
I expect the rate of growth to slow, and think it will stop before reaching 100% (I was expecting it to be higher than 70% in February). How much higher will it get? No idea, but herd mentality is a powerful force. Perhaps OpenAI going bankrupt will bring researchers to their senses.
Update
Martin Monperrus did an agentic replication of the analysis discussed in this post!
Benchmarking fuzzers
Fuzzing has become a popular area of research in the reliability & testing community, with a stream of papers claiming to have created a better tool/algorithm. The claims of ‘betterness’, made by the authors, often derive from the number of previously unreported faults discovered in some collection of widely used programs.
Developers in industry will be interested in using fuzzing if it provides a cost-effective means of discovering coding mistakes that are likely to result in customers experiencing a serious fault. This requirement roughly translates to: minimal cost for finding maximal distinct mistakes (finding the same mistake more than once is wasted effort); whether a particular coding mistake is likely to produce a serious customer fault is a decision decided by people.
How do different fuzzing tools compare, when benchmarking the number of distinct mistakes they each find, for a given amount of cpu time?
TL;DR: I don’t know, and this approach is probably not a useful way of comparing fuzzers.
Fuzzing researchers are currently competing on the number of previously unreported faults discovered, i.e., not listed in the fuzzed program’s database of fault reports. Most research papers only report the number of distinct faults discovered in each program fuzzed, the amount of wall clock hours/days used (sometimes weeks), and the characteristics of the computer/cluster on which the campaign was run. This may be enough information to estimate an upper bound on faults per unit of cpu time; more detailed data is rarely available (I have emailed the authors of around a dozen papers asking for more detailed data).
A benchmark based on comparing faults discovered per unit of cpu time only makes sense when the new fault discovery rate is roughly constant. Experience shows that discovery time can vary by orders of magnitude.
Code coverage is a fuzzer performance metric that is starting to be widely used by researchers. Measures of coverage include: statements/basic blocks, conditions, or some object code metric. Coverage has the advantage of providing defined fuzzer objectives (e.g., generate input that causes uncovered code to be executed), and is independent of the number of coding mistakes present in the code.
How is a fuzzer likely to be used in industry?
The fuzzing process may be incremental, discovering a few coding mistakes, fixing them, rinse and repeat; or, perhaps fuzzing is run in a batch over, say, a weekend when the test machine is available.
The current research approach is batch based, not fixing any of the faults discovered (earlier researchers fixed faults).
Not fixing discovered faults means that underlying coding mistakes may be repeatedly encountered, which wastes cpu time because many fuzzers terminate the run when the program they are testing crashes (a program crash is a commonly encountered fuzzing fault experience). The plot below shows the number of occurrences of the same underlying coding mistake, when running eight fuzzers on the program JasPer; 77 distinct coding mistakes were discovered, with three fuzzers run over 3,000 times, four run over 1,500 times, and one run 62 times (see Green Fuzzing: A Saturation-based Stopping Criterion using Vulnerability Prediction by Lipp, Elsner, Kacianka, Pretschner, Böhme, and Banescu; code+data):
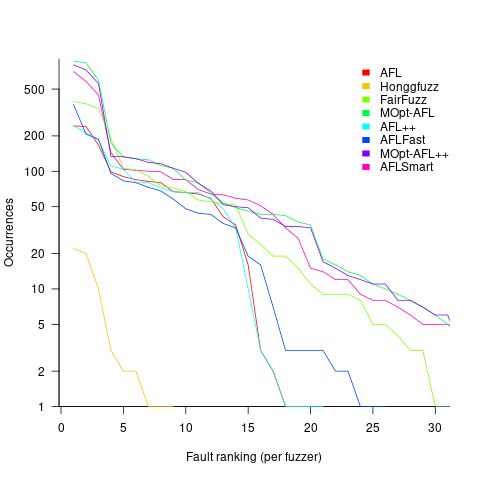
I have not seen any paper where the researchers attempt to reduce the number of times the same root cause coding mistake is discovered. Researchers are focused on discovering unreported faults; and with around 98% of fault discoveries being duplicates, appear to have resources to squander.
If developers primarily use a find/fix iterative process, then duplicate discoveries will be an annoying drag on cpu time. However, duplicate discoveries are going to make it difficult to effectively benchmark fuzzers.
Payback time-frame for research in software engineering
What are the major questions in software engineering that researchers should be trying to answer?
A high level question whose answer is likely to involve life, the universe, and everything is: What is the most cost-effective way to build software systems?
Viewing software engineering research as an attempt to find the answer to a big question mirrors physicists quest for a Grand Unified Theory of how the Universe works.
Physicists have the luxury of studying the Universe at their own convenience, the Universe does not need their input to do a better job.
Software engineering is not like physics. Once a software system has been built, the resources have been invested, and there is no reason to recreate it using a more cost-effective approach (the zero cost of software duplication means that manufacturing cost is the cost of the first version).
Designing and researching new ways of building software systems may be great fun, but the time and money needed to run the realistic experiments needed to evaluate their effectiveness is such that they are unlikely to be run. Searching for more cost-effective software development techniques by paying to run the realistic experiments needed to evaluate them, and waiting for the results to become available, is going to be expensive and time-consuming. A theory is proposed, experiments are run, results are analysed; rinse and repeat until a good-enough cost-effective technique is found. One iteration will take many years, and this iterative process is likely to take many decades.
Very many software systems are being built and maintained, and each of these is an experiment. Data from these ‘experiments’ provides a cost-effective approach to improving existing software engineering practices by studying the existing practices to figure out how they work (or don’t work).
Given the volume of ongoing software development, most of the payback from any research investment is likely to occur in the near future, not decades from now; the evidence shows that source code has a short and lonely existence. Investing for a payback that might occur 30-years from now makes no sense; researchers I talk to often use this time-frame when I ask them about the benefits of their research, i.e., just before they are about to retire. Investing in software engineering research only makes economic sense when it is focused on questions that are expected to start providing payback in, say, 3-5 years.
Who is going to base their research on existing industry practices?
Researching existing practices often involves dealing with people issues, and many researchers in computing departments are not that interested in the people side of software engineering, or rather they are more interested in the computer side.
Algorithm oriented is how I would describe researchers who claim to be studying software engineering. I am frequently told about the potential for huge benefits from the discovery of more efficient algorithms. For many applications, algorithms are now commodities, i.e., they are good enough. Those with a career commitment to studying algorithms have a blinkered view of the likely benefits of their work (most of those I have seen are doing studying incremental improvements, and are very unlikely to make a major break through).
The number of researchers studying what professional developers do, with an aim to improving it, is very small (I am excluding the growing number of fake researchers doing surveys). While I hope there will be a significant growth in numbers, I’m not holding my breadth (at least in the short term; as for the long term, Planck’s experience with quantum mechanics was: “Science advances one funeral at a time”).
The aims of software engineering research
Physics researchers aim to explain the workings of the universe (technically they build models whose behavior mimics that of the universe we can measure), biologists the workings of biological systems, and psychologists the working of the human mind.
What are researchers in software engineering aiming to do?
Talking to academics, the answer is that they aim to do research that can be published in a high impact journal.
What do those involved in commercial software development think software engineering researchers should be aiming to achieve?
Most of the commercial developers I have asked have never thought about the subject; hardly surprising, they have plenty of other issues to think about.
Those who pay for software, rather than create it, want it to be cheaper and delivered faster.
Vendors are under some pressure to reduce costs and deliver sooner. But since its inception, software has been a sellers market, which means the customer pressure does not have the impact it has in other industries.
The very large organizations who pay lots of money for software for their own use (e.g., the U.S. Department of Defence) recognise that research into software production may well save them lots of money, and at one time interesting things were being discovered, but then funding got rerouted to people with an aversion to actual software engineering, i.e., academics.
Cheaper and faster will always be of interest, and will start to become a hot topic in software engineering research once software starts to becoming a buyers market.
Maintaining existing systems continues its growth to dominating what nearly every software developer does. Dependencies on the rest of the software world (e.g., libraries and compilers) is starting to consume a large percentage of maintenance costs. Managers want to know which packages are likely to have a long and stable lifetime, and which are likely to be short-lived. An understanding of the evolution of software ecosystems is a pressing need. This is really cheaper and faster over the long term.
Cheaper and faster (short term for development, long term for maintenance) covers everything.
It’s tempting to list personnel selection, i.e., who is likely to make the best software developer. But why should the process of selecting software developers be any different from the processes used to select people to become doctors, lawyers and other professions? I’m sure that those involved in the various professions would like a magic wand that points to the appropriate people (for some definition of appropriate), this magic wand is no more likely to exist for software developers than any other profession.
What do you think the aims of software engineering research should be?
Recent Comments