Archive
Reliability via N-version programming?
N-version programming was first proposed in 1978, probably the most known paper on the subject was published in 1986, after which activity was mostly within safety-critical systems circles. Cost was a major issue, it’s expensive to create one version of a program, and producing  independent versions is around times more expensive.
independent versions is around times more expensive.
Now that LLM have significantly reduced the cost of creating programs, people have started to experiment with creating many versions of a specification.
In the past, interest in N-version programming focused on reliability. The idea is that independent implementations of the same specification will contain different coding mistakes, and that when a fault is experienced in one implementation the others will behave as intended, e.g., in a system with  , a two-out-of-three vote is enough to ensure correct behavior.
, a two-out-of-three vote is enough to ensure correct behavior.
The 1986 Knight and Leveson paper found that coding mistakes were correlated, i.e., different implementations, written by different people, sometimes contained the same mistake (so three systems might not be enough to ensure high reliability). The results were replicated, with varying percentages of total and common faults experienced. The possibility that using the same specification for all implementations might be a significant contributor to common mistakes is often raised, but I am not aware of any published studies. There are also implementations issues such as the fuzziness of floating-point arithmetic.
On Monday this week the paper: Do programming languages still matter to your AI coding agent teammate? Evidence at scale from chess engines discussed using LLMs to create 34 chess engines spanning 17 programming languages, and on Thursday the paper N-Version Programming with Coding Agents by Ron, Baudry, and Monperrus (RBM) replicated the Knight/Leveson (KL) paper using programs generated by a variety of LLMs from the specification used by KL (originally used in my top, must-read paper on software fault analysis).
How did the KL and RBM results compare? The KL study involved 27 students each creating an implementation of the same specification in Pascal and had to pass an acceptance test containing 200 tests (randomly generated for each implementation, to prevent filtering of shared faults). The RBM study created 69 implementations (23 in each of Pascal, Python and Rust) of the same KL specification using different coding agents from five vendors. Implementations that failed the acceptance test (10 Pascal, 5 Python, 6 Rust) were not given the opportunity to fix the code.
Each implementation was given the same set of 1-million inputs, and the results compared against those obtained from an Oracle. Based on the number of times each implementation failed (i.e., produced incorrect output), and assuming that each implementation’s failures are independent of other implementations, it’s possible to calculate the expected number of cases where two or more distinct implementations fail on the same input (Kimi steps through the maths). The expected number of multiple failures on the same input is (the actual numbers are in brackets): KL 127 (1,255); RBM Pascal 6 (426), Python 57 (424), Rust 6 (424).
There are a lot more actual instances of two or more implementations failing on the same input, than would be the case if the failures were independent of each other (the statistical analysis shows that the much larger values are extremely unlikely; code+data). The implication is that similar coding mistakes are being made across implementations, leading to correlated failures.
The error rates for the LLM generated programs look a lot lower than those in the KL study. Are the LLM generated programs more reliable than the human written programs? Later studies with human subjects also had a much lower error rate, suggesting that the higher error rate in the KL study was caused by the use of student subjects.
Fans of a particular language will often claim that it has various desirable characteristics, e.g., readability, maintainability and reliability. There is no evidence for any of these claims, and I have always thought that, post-release of the program, programming language is essentially irrelevant. Mistakes and assumptions tend to be language independent. This small sample of programs for one problem don’t show any significant differences between languages (perhaps there is one, but a much larger sample will be needed to see it). In the past, multi-language studies have often used examples from Rosetta Code (also see sections 2.5 and 7.2.9 of my book). Given the perennial interest in comparing programming languages, I am expecting many papers on the subject over the next few years.
A more interesting question is the variability in the source code generated by different LLMs, for the same specification. I am expecting that it will contain some of the patterns in human written code, as well as some patterns of human variation.
Perhaps LLM source code generation does not need to become as reliable as compiler machine code generation, vendors just have to make sure that the mistakes they make are not correlated.
Statistical note: KL uses the Wald interval to estimate the statistical significance (and RBM replicates). There are issues with this approximation when the probability of failure is close to zero (it does not matter here because the difference between theory and practice is so large). These days libraries implementing the complicated, technically correct, approach are available, e.g., binomtest is in Python’s scipy.stats package and binomial.test is included in R’s base system.
How many ways of programming the same specification?
How many different ways are there of writing a program to implement a given specification? Non-trivial specifications probably have an enormous number of possible programming solutions. What about really simple specifications, say something based on the 3n+1 problem (write a programs that takes a list of integers and outputs their ‘3n+1’ length; ‘3n+1’ length algorithm: for integer  , if is even divide it by
, if is even divide it by  and assign the result to , otherwise is odd, multiply it by
and assign the result to , otherwise is odd, multiply it by  and add
and add  to give the new value of ; repeat the process, counting the number of iterations until reaches )?.
to give the new value of ; repeat the process, counting the number of iterations until reaches )?.
I can think of a dozen or so (slightly) different ways that I might write a program to solve this problem. If I really had to I could probably come up with a few hundred different solutions, but I think the source code of these programs would not look like something I would normally write. If I was to run a competition how many different answers might I get? If you twisted my arm I might have said 500. What do you think?
Meine van der Meulen studied the N-version programing for his PhD thesis (N groups independently write a program to the same specification, compare the output of the N programs and select the ‘best’ answer; cannot find a copy of the thesis online). This was empirical work and van der Meulen posted the above 3n+1 problem to a programming competition website and used the 95,497 submitted solutions for his analysis; he also kindly sent me a copy of the solutions (11,674 solutions were written in Pascal, the rest were in C).
Not all the solutions correctly solve the problem. I ignored this ‘detail’. There are also many duplicates (as in identical source code).
I am interested in differently coded solutions. I defined different as the sequence of operators/punctuators making up the program being different (or at least having a different MD5 checksum), so identifiers and comments are ignored. Should permutations in the order of independent adjacent statements really be counted as different? For the sack of keeping my life simple they current are. This definition of differently coded reduces the original 63,823 C programs down to 6,301. Wow, how are 6k+ different programs possible?
The original specification did not mention performance, but lots of developers did all sorts of weird and wonderful stuff to improve runtime performance. The most common optimization technique used (apart from some inventive ways of checking for odd/even) was to cache previous answers along with the solution for all the intermediate steps that were passed through on the way to 1 (the path from the starting value to 1 is very erratic and sometimes goes through values greater than the starting value) and check this cache to see whether it contains the current value of.
A common measure of program size is lines of code. What is the size distribution, in LOC, for these 6,301 programs? One program has been labeled an outlier and excluded from the analysis (most of its 8,345 lines were taken up with initializing a data structure with precomputed solutions).
The following plots lines of code against the number of programs containing that many lines (download code and data).
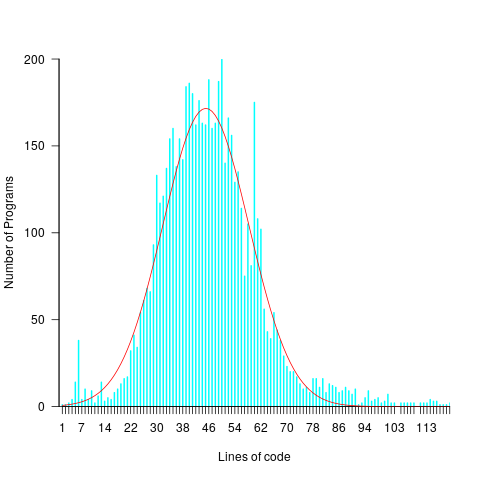
The mean program length is 46.3 lines, standard deviations 15.4. The red curve is a Normal distribution whose mean/sd has been tweaked to give a better visual fit (a Shapiro-Wilk test dispels any hope tht the distribution might be Normal). There is no reason to think that the data will be fitted by any known distribution and I’m not going to overfit on one data-point. If pushed I will wave my arms and describe the distribution as Normalish with added spikes and a fat right tail.
That spike around 60 lines is interesting. Is this group of solutions all doing the same thing but with different statement orderings? I have previously written about how gcc/llvm do a good job of turning the core of the algorithm into the same machine code. Perhaps a future version of these compilers will be able to tell us whether the programs clumping around 60 LOC are doing the same thing.
Recent Comments