Archive
Programming Punched card machines
Punched card machines, or Tabulating machines, or Unit Record equipment, or according to a 1931 article Super Computing machines, were electromechanical devices that summarised information contained on punched cards (aka tabulating cards). These machines date from 1884, with the publication of Herman Hollerith’s patent application 18840923. In 1948 the electronic valve based IBM 603 calculating punch machine was launched.
The image below (from Wikipedia) shows an IBM 80 column card. When introduced in 1928, the card contained 10 rows, with rows 11 and 12 (known as zone punching positions) added later to support non-digit characters. The paper: “Do Not Fold, Spindle or Mutilate”: A Cultural History of the Punch Card takes a wry look at the social impact of these cards.

Manufacturers sold a range of single purpose Punch machines. Single purposes included: sorting cards, duplicating cards with specified changes to column contents, printing card contents, and simple accounting (adding/subtracting values).
Yes, Punched card machines can be programmed. The vast majority of machines were used by businesses for accounting and stock control, but since the early 1930s a few were used by researchers for scientific computations.
A Punch machine program consisted of cables that directed the flow of electrical signals from one to eighty output sockets (one for each of the 80 columns on a punched card), through various control/manipulation subsystems, to produce an output, e.g., printing a cheque, an itemised invoice, or creating an updated card. The input/output sockets (the terminology of the day was entry/exit sockets) for each subsystem were arranged on the machine’s Control panel (more commonly known as a plugboard).
Each plugboard contains a row of reader output sockets, one for each of the 80 card columns, a row of input sockets that connected to a printing mechanism, and sockets providing input/output for other operations. For example, a connection from, say, the 50’th column of the reader output socket to the 70’th column of the print input socket would print the contents of the 50’th column of the card in the 70’th column of the paper/card output.
The image below (from Wikipedia) shows connections for a program on an IBM 402:

Like many early computers, Punch machine architecture is bit-serial. That is, values are represented as a constant-duration sequence of bits (with the 12 rows of a column forming a card cycle), rather than a parallel sequence of bits (e.g., a byte) all appearing at the same time. The duration of the sequence is driven by the card reader, which moves the card (bottom to top) across a row of metal brushes (one for each column), completing an electric circuit (generating a pulse) when the brush makes contact through a hole in the card.
Once a card cycle completes, the bit sequences are gone (some machines could store a few column values). Some Punch machines read the same card multiple times (three is the maximum I have seen). Multiple readings make it possible to use input from the first/second reading to select the operations to be performed on the input during subsequent readings.
An example of the need for multiple reads. Holes in the zone punching positions may specify an alphabetic character or a special data specific meaning, e.g., accounting records could indicate that a column value is a credit rather than a debit by punching a hole in the 11’th row of the appropriate column. To maintain backwards compatibility, the zone punching positions appear near the top of the punch card, and are read last, leaving the digits pulses unchanged. If a zone punching position has a special meaning, the first read is used to detect whether, say, the 11’th row contains a hole, and the digit value is obtained on the second read (see X Elimination on page 126).
Punch machine programs did not support loops. Loops are implemented by including a human in the chain of execution. The body of the loop performs a calculation on the input cards, writing the results to new cards. These new cards are moved to the input hopper, and the program run again, iterating until the desired accuracy is obtained (or not).
Naming convergence in a network of pairwise interactions
While naming and categorizing things are perhaps the two most contentious issues in software engineering, there is often a great deal of similarity in the names and categorizes used by unconnected groups. These characteristics of naming and categorization are general observed behaviors across cultures and languages, with software engineering being a particular example.
Studies have found that a particular name for a thing is likely to become adopted by a group, if around 25% of its members actively promote the use of the name. The terms tipping point and critical mass have been applied to the 25% quantity.
What factors could cause 25% of the members of a group to select a particular name, and why does a tipping point occur at around this percentage?
The paper Experimental evidence for scale-induced category convergence across populations by Douglas Guilbeault (PhD thesis behind the paper), Andrea Baronchelli, and Damon Centola experimentally investigated factors that can cause a name to be adopted by 25% of a group’s members, and the researchers proposed a model that exhibits behavior similar to the experimental results (the supplement contains the technical details).
The experiment asked subjects to play the “Grouping Game”. The 1,480 online subjects were divided into networks containing either 2, 6, 8, 24 or 50 members. The interaction between members of a network only occurred via randomly selected pairs (the same pair for the network of two), with one person designated as the speaker and the other as the hearer. A pair saw three randomly selected images, such as the one below. For the speaker only, one of the images was highlighted, and they had to give a name containing at most six characters to the image. The hearer saw the name given by the speaker to one of the images, and had 30 seconds to choose the image they considered to have been named. If the image selected by the hearer was the one named by the speaker, both received a small payment, otherwise an even smaller amount was deducted from their final payment. Each subject played 100 rounds with the randomly chosen members of their network.

The images were created as a series of 50+ distinct patterns whose shape slowly morphed along a continuum, as in the following image:

The experimental results were that larger networks converged to a consistent, within group, naming of the images (using a few names), while smaller groups rarely converged and used many different names. The researchers proposed that as the network size grew, common names were encountered more often than rarer names, increasing the likelihood of reaching a tipping point. This behavior is similar to the birthday paradox, where there is a 50% probability that in a room of 23 people, two people will share the same birthday.
In the experiment, some networks included confederates trained to use a small subset of names, i.e., the researchers created a common set of names. It was hypothesized built-in human preferences would produce common patterns in the real world that, for larger groups, would cause tipping points to occur, amplifying the more common patterns to become group norms.
The supplement to the paper develops a theoretical model based on the probability of  identical items being contained in a sample of
identical items being contained in a sample of  items, when sampling without replacement. The solution involves the hypergeometric distribution, which is difficult to deal with analytically, so simulation is needed. The results show a tipping point at around 25%.
items, when sampling without replacement. The solution involves the hypergeometric distribution, which is difficult to deal with analytically, so simulation is needed. The results show a tipping point at around 25%.
The plot below shows a density plot for one 50-subject network over 15 trials (after 100 rounds of pairwise interaction), with each color denoting one of the 14 chosen names (height of the curve denotes likelihood of the same name being chosen for that image; code and data):
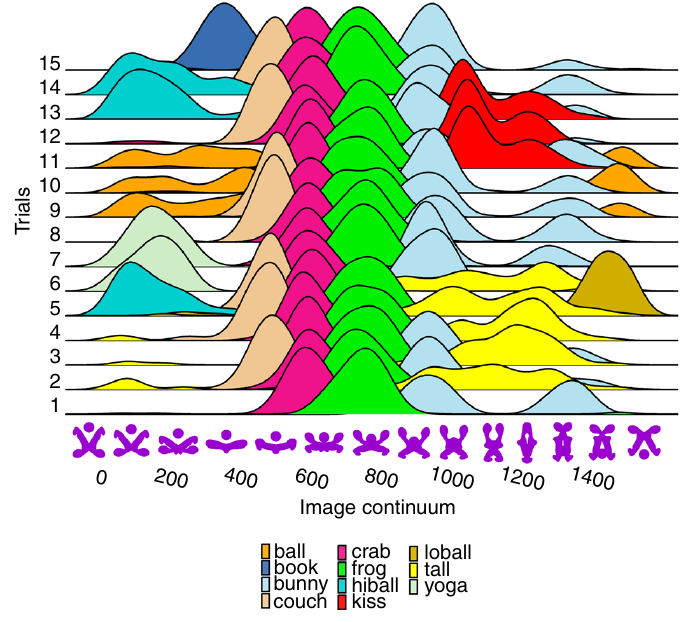
This plot shows that the same name is often used across trials, and naming boundaries between some images.
The plot below shows a density plot for one 2-subject network over 15 trials (after 100 rounds of pairwise interaction), with each color denoting one of the 72 chosen names (height of the curve denotes likelihood of the same name being chosen for that image; code and data):
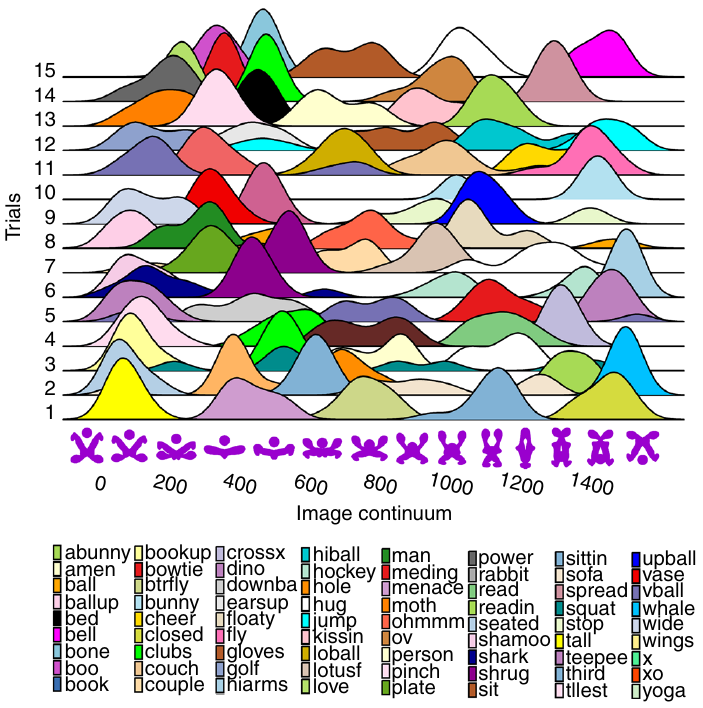
Here there is no consistent naming across trials, a much greater diversity of names appearing, and no obvious naming boundaries between images.
Christmas books for 2025
My rate of book reading has remained steady this year, however, my ability to buy really interesting books has declined. Consequently, the list of honourable mentions is longer than the main list. Hopefully my luck/skill will improve next year. As is usually the case, most book were not published in this year.
Liberal Fascism: The secret history of the Left from Mussolini to the Politics of Meaning by Jonah Goldberg is reviewed in a separate post.
Oxygen: The molecule that made the world by Nick Lane, a professor of evolutionary biochemistry, published in 2016. The book discusses changes in the percentage of oxygen in the Earth’s atmosphere over billions of years and the factors that are thought to have driven these changes. The content is at the technical end of popular science writing. The author is a strong proponent that life (which over a billion or so years produced most of the oxygen in the atmosphere) originated in hydrothermal vents, not via lightening storms in the Earth’s primordial atmosphere (as suggested by the Miller–Urey experiment). The Wikipedia article on the origins of life contains a lot more words on the Miller–Urey experiment.
“By the Numbers: Numeracy, Religion and the Quantitative Transformation of Early Modern England” by Jessica Marie Otis, a professor of history, published in 2024. Here, early modern England starts around 1543 with the publication of an arithmetic textbook, The Ground of Artes, that was republished 45 times up until 1700. As the title suggests, the book discusses the factors driving the spread of numeracy into the general population, e.g., the need for traders and organizations to keep accounts, and the people to keep track of time. For the general reader, the book is rather short at 160 readable pages. Historians get to enjoy the 51 pages of notes and 37 pages of bibliography.
For insightful long, discursive book reviews that are often more interesting than the books themselves (based on those I have purchased), see: Mr. and Mrs. Psmith’s Bookshelf. This year, Astral Codex ran a Non-Book Review Contest.
The blog Worshipping the Future by Helen Dale and Lorenzo Warby continues to be an excellent read. It is “… a series of essays dissecting the social mechanisms that have led to the strange and disorienting times in which we live.” The series is a well written analysis that attempts to “… understand mechanisms of how and the why, …” of Woke.
As an aside, one of the few pop cds I bought this year turned out to be excellent: “PARANOÏA, ANGELS, TRUE LOVE” by Christine and the Queens.
Honourable mentions
The Knowledge: How to Rebuild Our World from Scratch by Lewis Dartnell, an astrobiologist. Assuming you are among the approximately 5% of people still alive after civilizations collapses (the book does not talk about this, but without industrial scale production of food, most people will starve to death), how can useful modern day items (i.e., available in the last hundred years or so) be created? Items include ammonia-based fertilizer, electricity, radio receiver and simple drugs. The processes sound a lot easier to do than they are likely to be in practice (manufacturing processes invariably make use of a lot of tacit knowledge), but then it is a popular book covering a lot of ground. It’s really a list of items to consider, along with some starting ideas.
“Goodbye, Eastern Europe: An Intimate History of a Divided Land” by Jacob Mikanowski, a historian and science writer, published in 2023. A history of Eastern Europe from the first century to today, covering the countries encircled by Germany, the Baltic Sea, Russia, and the Black Sea/Mediterranean. The story is essentially one of migrations, and mass slaughters, with the accompanying creation and destruction of cultures. Harrowing in places. It’s no wonder that the people from that part of the world cling to whatever roots they have.
“Reframe Your Brain: The User Interface for Happiness and Success” by Scott Adams of Dilbert fame, published in 2023. To quote Wikipedia: “Cognitive reframing is a psychological technique that consists of identifying and then changing the way situations, experiences, events, ideas and emotions are viewed.” This book contains around 200 reframes of every day situations/events/emotions, with accompanying discussion. Some struck me as a bit outlandish, but sometimes outlandish has the desired effect.
Details on your best books of the year very welcome in the comments.
Lifetime of coding mistakes in the Linux kernel
What is the lifetime of coding mistakes in the Linux kernel? Some coding mistakes result in fault reports (some of which are fixed), while many are removed when the source that contains them is deleted/changed during ongoing development.
After fixing the coding mistake(s) in the kernel that generated a reported fault, developer(s) log the commit that introduced the coding mistake, along with the commit that fixed it. This logging started in 2013, and I only found out about it this week. To be exact, I discovered the repo: A dataset of Linux Kernel commits created by Maes Bermejo, Gonzalez-Barahona, Gallego, and Robles.
The log contains the commit hashes for the 90,760 fixes made to the 63 mainline kernel versions from 3.12 to 6.13. The complete log of 1,233,421 commits has to be searched to extract the details, e.g., date, lines added, etc.
The kernel development process involves regular release cycles of around 80 days. Developers submit the code they want to be included in the next release, this goes through a series of reviews, with Linus making the final decision.
The following analysis is based on the coding mistakes introduced between successive kernel releases, e.g., version 3.13 coding mistakes are those introduced into the source between 4 Nov 2013 (the day after version 3.12 was released) and 19 Jan 2014 (when version 3.13 was released). Code will have been worked on, and mistakes created/fixed, before it reached the kernel, which ensures some level of maturity.
The number of people working with pre-release code is likely to be tiny, compared to the number running released kernels. Consequently, the characteristics of coding mistake lifetime is expected to be different pre/post release, if only because more users are likely to report more faults.
The plot below shows the pre-release daily mistake fixed density against days since start of work on the current release, the red line is a fitted regression line mapped to density (fitted regression is a biexponential; code and data):
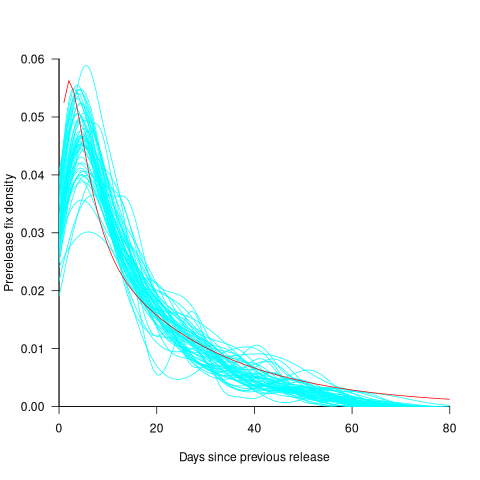
For all versions, the prior to release daily fix rate follows a consistent pattern: Most fixes occur in the first few days, with roughly an exponential decline to the release date.
The following analysis builds a broad brush model of cumulative fixes over time across 53 mainline kernel releases (the final 10 releases were not included because of their relatively short history).
The number of users of a new kernel takes time to increase as it percolates onto systems, e.g., adopted by Linux distributions and then installed by users, or installed by cloud providers. Eventually, code first included in a particular version will be running on most systems.
The post release daily fix rate is best modelled using the cumulative number of fixes, i.e., total number of fixes up to a given day since release. The models fitted below are based on dividing the post release cumulative fixes into before/after 200 days since release. The 200-day division is a round number (technically, a nearby value may provide a better fit) that supports the fitting of good quality before/after regression models. Averaged over all releases, 42% of fixes occurred within 200-days, and 58% after 200-days.
The plot below shows the cumulative number of post-release fixed faults, in red, for various kernel versions, with fitted regression lines in green and blue (grey line is at 200-days; code and data):

The equation fitted to the before 200-days fixes had the following form:
}")
where:  is a kernel version specific constant; see plot below.
is a kernel version specific constant; see plot below.
The equation fitted to the after 200-days fixes had the following form:

where:  is a kernel version specific constant; see plot below.
is a kernel version specific constant; see plot below.
Approximately, after release, the cumulative fix rate starts out quadratic in elapsed days, with the rate decreasing over time, until after 200-days the rate settles down to following the cube-root of days.
Comparing the number of post-release fixes across versions, there is a lot more variability in the first 200-days (i.e., the model fit to the data is sometimes very poor), relatively to after 200-days (where the model fit is consistently good).
Each kernel release has its own characteristics, parameterised by the values , and in the above equations. The plot below shows these values across versions, with red for , blue/green for , and grey line showing normalised LOC added/changed in the release (code and data):
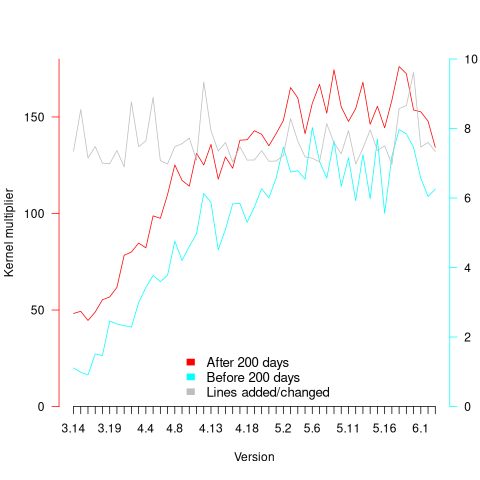
The plot clearly shows a large increase in the number of fixes between kernel version 3.14 and later versions. The before 200-days rate (blue/green) increase by a factor of seven, while the after 200-days rate increased by a factor of three.
Is this increase driven by some underlying factor in kernel development, or is it an external factor such as an increase in the number of users (more users leads to more faults reports), or the extensive post-release fuzz testing that is now common.
The number of lines of code added/changed, indicated by the grey line (shifted to fit plot axes) cannot be added to the fitted models because they exactly correlate with their respective version.
What is driving the long-term rate of fixes, i.e., cube-root of elapsed days?
Actually, what people are really want to know is what can be done to reduce the number of fixes required after release. When people ask me this, my usual reply is: “Spend more on testing”.
The probability of a coding mistake causing a fault report is decreasing: fixes reduce the number of remaining mistakes, and source added in one kernel version may be removed in a later version.
Perhaps the set of input behaviors is growing, producing the distinct conditions needed to trigger different coding mistakes, or the faults are occurring but are only reported when experienced by a small subset of users.
As always, more data is needed.
Decline in downloads of once popular packages
What happens to the popularity of Open source packages, measured in monthly downloads, once they cease to be updated or attract new users?
If the software does not have any competition within its domain, there is no reason why its popularity should decline. In practice, there are usually alternative packages offering the same or similar functionality. Even when alternatives are available, existing practice and sunk costs can slow migration. A year or so after I started using Asciidoc to write by Software Engineering book, the author announced that he was no longer going to update the software; initially there was no alternative, but the software did what I wanted, and I have been happily using it over the last 12 years.
The paper: Do All Software Projects Die When Not Maintained? Analyzing Developer Maintenance to Predict OSS Usage by Emily Nguyen measured the monthly downloads, commits and other characteristics of 38K GitHub packages having at least 10K downloads during any month between January 2015 and December 2020. The data made available (more here) is a subset, i.e., downloads for 1,583 projects starting in May 2015.
The author investigated the connection between various project characteristics (focusing on commits or lack thereof in particular) and downloads by fitting a Cox proportional hazards model.
The plot below shows the 67 monthly downloads for a selection of packages; the red line is a fitted local regression used to smooth the data (code and data):

Reasons for a decline from a peak number of downloads include: competition from alternative packages, change of fashion, and market saturation, or perhaps the peak was caused by a one-off event. Whatever the reason for a peak+decline, my interest is learning about patterns in the rate of decline.
Some of the monthly package downloads in the above plot have an obvious peak and decline, with others continually increasing, and others having multiple peaks. The following algorithm was used to select packages having a peak followed by a decline, based on the predicted values from a fitted loess model:
- find the month with the most downloads, this is the primary peak,
- if this month is within 10 months of the end of the measurement period, this is not a peak/decline package,
- does a secondary peak exist? A secondary peak is a month containing the most downloads from 10 months after the end of the primary peak, where the number of downloads is within 66% of the primary peak downloads,
- the secondary peak becomes the primary peak, provided it is not within 10 months of the end of the measurement period.
The final fraction of the primary peak is the average monthly download during the last three months divided by the peak month downloads.
The plot below shows the 693 packages whose final fraction of peak was below 0.6 against months from peak to the last month (at the end of 2020), with the red line showing a fitted regression of the form  (code and data):
(code and data):

As the above plot shows, there don’t appear to be any patterns in the decline of package downloads, and  is a poor predictor of fraction of peak.
is a poor predictor of fraction of peak.
Perhaps a more sophisticated peak+decline selection algorithm will uncover some patterns. Both ChatGPT (its generated python script failed) and Grok (very wrong answers) failed miserably at classifying the plots. Deepseek will only process images to extract text.
Occurrence of binary operator overloading in C++
Operator overloading, like many programming language constructs, was first supported in the 1960s (Algol 68 also provided a means to specify a precedence for the operator). C++ is perhaps the most widely used language supporting operator overloading; but not redefining their precedence.
I have always thought that operator overloading was more talked about than actually used (despite its long history, I have not been able to find any published usage information). A previous post noted that the CodeQL databases hosted by GitHub provides the data needed to measure usage, and having wrestled with the documentation (ql scripts used), C++ operator overload usage data is available.
The table below shows the total uses of overloaded and ‘usual’ binary operators in the source code (excluding headers) of 77 C++ repositories on GitHub (the 100 repositories C/C+ MRVA). The table is ordered by total occurrences of overloads, with the Percentage column showing the percentage use of overloaded operators against the total for the respective operator (i.e.,  ; code and data):
; code and data):
Binary Overload Usual Total Percentage << 103,855 20,463 124,318 83.5 == 21,845 118,037 139,882 15.6 != 14,749 69,273 84,022 17.6 * 12,849 57,906 70,755 18.2 + 10,928 103,072 114,000 9.6 && 8,183 64,148 72,331 11.3 - 5,064 77,775 82,839 6.1 <= 3,960 18,344 22,304 17.8 & 3,320 27,388 30,708 10.8 < 1,351 93,393 94,744 1.4 >> 1,082 11,038 12,120 8.9 / 1,062 29,023 30,085 3.5 > 537 44,556 45,093 1.2 >= 473 27,738 28,211 1.7 | 293 13,959 14,252 2.0 ^ 71 1,248 1,319 5.4 <=> 13 12 25 52.0 % 11 9,338 9,349 0.1 || 9 53,829 53,838 0.017 |
Use of the overloaded << operator is driven by standard library I/O, rather than left shifting.
There are seven operators where 10-20% of the usage is overloaded, which is a lot higher than I was expecting (not that I am a C++ expert).
How much does overloaded binary operator usage vary across projects? In the plot below, each vertical colored violin plot shows the distribution of overload usage for one operator across all 77 projects (the central black lines denote the range of the central 50% of the points; code and data):

While there is some variation between these 77 projects, in most cases a non-trivial percentage of an operator's usage is overloaded.
Fifth anniversary of Evidence-based Software Engineering book
Yesterday was the 5th anniversary of the publication of my book Evidence-based Software Engineering.
The general research trajectory I was expecting in the 2020s (e.g., more sophisticated statistical analysis and more evidence based studies) has been derailed by the arrival of LLMs three years ago. Almost all software engineering researchers have jumped on the LLM bandwagon, studying whatever LLM use case is likely to result in a published paper. While I have noticed more papers using statistical techniques discovered after the digital computer was invented (perhaps influenced by the second half of the book), there seems to be a lot fewer evidence based papers being published. I don’t expect researches studying software engineering to jump off the LLM bandwagon in the next few years.
The net result of this lack of new research findings is that the book contents are not yet in need of an update.
On a positive note, LLMs’ mathematical problem-solving capabilities have significantly reduced the time needed to analyse models of software engineering processes.
Had today’s LLMs been available while I was writing the book, the text would probably have included many more theoretical models and their analysis. ‘Probably’, because sometimes the analysis finds that a model does not provide meaningfully mimic reality, so it’s possible that only a few more models would have been included.
My plan for the next year is to use LLM’s mathematical problem-solving capabilities to help me analyse models of software engineering processes. A discussion of any interested results found will appear on this blog. I’m hoping that there will be active conversations on the evidence based software engineering Discord channel.
It makes sense to hone my model analysis skills by starting with the subject I am most familiar with, i.e., source code. It also helps that tools are available for obtaining more source measurement data.
I will continue to write about any interesting papers that appear on the arXiv lists cs.se and cs.PL, as well as the major conferences. There won’t be time to track the minor conferences.
Questions raised during model analysis sometimes suggest ideas that, when searched for, lead to new data being discovered. Discovering new data using a previously untried search phrase is always surprising.
Best tool for measuring lots of source code
Human written source code contains various common usage patterns. This blog has analysed a variety of these patterns, and in a few cases built models of processes that replicate these patterns. The data for this analysis has primarily comes from programs written in C and Java, because these are the languages that researchers most often study (tool availability and herd mentality).
Do these common usage patterns occur in other languages, or at least other C/Java like languages? I think so, and have set out to collect the necessary data. Obtaining this data requires large quantities of code written in many languages, and the ability to analyse code written in these languages.
GitHub contains huge quantities of code. There are two freely available source code analysis tools supporting many languages: Opengrep (the Open source version of semgrep) and CodeQL.
CodeQL’s method of operation had previously put me off trying it. The method is a two stage process: First a database of information is created by extracting information during a project’s build process (e.g., running existing makefiles and host compilers), followed by querying this database using a declarative language (think minimalist SQL with lots of built-in functions). This approach has the huge advantage of not having to worry about handling compiler dialects/options, however, I’m an ingrained user of tools that process individual files.
From the research perspective, CodeQL has a major feature that is not available with other tools. GitHub, who now owns CodeQL, host thousands of project databases and GitHub Actions allows third-parties to scan up to 1,000 databases of the most popular projects. Access to existing CodeQL databases removes the need to download repo/build project/store database locally.
CodeQL, like other static analysis tools, was designed to find issues/problems in code, and so might not support the kind of functionality I needed to extract source code measurements. The best way to find out if the data of interest could be extracted is to try and do it.
In the best developer tradition, I downloaded a prebuilt release (available for Linux, Windows and Mac; called CodeQL Bundles), skimmed the documentation, ran a simple QL script and spent an hour or two trying to figure out why I was getting Java runtime errors, e.g., “no String-argument constructor/factory method to deserialize from String value“.
Progress would have been faster if I had used Visual Studio Code, available free from the owners of GitHub, rather than the command line. The documentation is not command line oriented. Visual Studio handles details like creating a qlpack.yml file (whose necessary existence I eventually found out about). Also, the harmless looking metadata appearing in comments is necessary and had better match the output parameters of the query. How hard is it to warn that a file could not be found, or that metadata is missing?
The code databases are queried using the declarative language QL, which is a kind of minimal SQL (with the select appearing last, rather than first). The import statement specifies the language, or rather the name of a library module.
The imported library contains classes for each language construct (e.g., BlockStmt, Function, ArrayExpr, etc). In the query below, the line “from LocalScopeVariable lv” extracts all local scope variables, which can subsequently be referred to via the name lv. The where line lists conditions that must be met (in this example, not be a parameter and not be accessed; testing for unused variables). The select line invokes methods that return various kinds of information about the class, e.g., the name of the variable, and location within the source.
/** * @id compound-stmt * @kind problem * @problem.severity warning */ import cpp from LocalScopeVariable lv where not lv instanceof Parameter and not exists(lv.getAnAccess()) select "", ""+lv.getName()+ ","+lv.getLocation().getStartLine()+ ","+lv.getLocation().getEndLine()+ ","+lv.getEnclosingFunction()+","+bs.getFile() |
The output generated is driven by the select, whose number/kind of arguments must match that specified by the metadata.
Developers can write and call functions, such as this one:
predicate header_suffix(string fstr) { fstr = "h" or fstr = "H" or fstr = "hpp" } |
The QL language is a declarative logical query language with roots in Datalog (subset of Prolog). The claim that it is an object-oriented language is technically correct, in that it groups functions into things called classes and supports various constructs usually found in object-oriented languages. The language has the feel of an academic project that happened to be used in a tool that was in the right place at the right time. Using host compilers to enable the tool to support many languages must have been very attractive to GitHub.
Coding in a declarative logic language requires a major mindset change. There are no loops, if statements or assignments. The query is one, potentially very long and complicated, predicate. A mindset change is necessary, but not sufficient, some fluency with the library of functions available is also needed. For instance, the isSideEffectFree predicate is true/false, but does not return a value (so there is nothing to print). I wanted to output 0/1, depending on whether a function was side effect free or not. When asked, all the LLMs questioned insisted that QL supported if-statements and assignment, just like other languages. After lots of dead-ends, an LLM claimed that “CodeQL automatically treats boolean expressions in count as 1/0″, and a test run showed this to be the case:
count(int dummy | dummy = 1 and func.isSideEffectFree() | dummy) |
The QL scripts needed to extract all the data of immediate interest to me were easily implemented. Looking at existing scripts has given me some ideas for more patterns I might measure. CodeQL currently supports 10 languages, and their classes appear to be slightly different (my initial focus is C, C++, Java and Python).
Visual Studio Code is required to run multi-repository variant analysis, i.e., scan up to 1,000 project databases on GitHub. It was after installing the CodeQL extension that I discovered how much smoother the process is within this IDE, compared to the command line (and off course the output is slightly different). There may be alternatives to Visual Studio, but I’m sticking with what the official documentation says.
Stepping back, is CodeQL a useful tool?
For me it is currently very useful, because of the large number of project databases. Some practice is needed to achieve some fluency in the use of a declarative logic language, not a major hurdle.
The need to run queries against a project database may be a major inconvenience for some developers, depending on working practices. Those practicing continuous integration should be ok.
Distribution of method chains in Java and Python
Some languages support three different ways of organizing a sequence of functions/methods, with calls taking as their first argument the value returned by the immediately prior call. For instance, Java supports the following possibilities:
r1=f1(val); r2=f2(r1); r3=f3(r2); // Sequential calls r3=f3(f2(f1(val))); // Nested calls, read right to left r3=val.f1().f2().f3(); // Method chain, read left to right |
Simula 67 was the first language to support the dot-call syntax used to code method chains. Ten years later Smalltalk-76 supported sending a message to the result of a prior send, which could be seen as a method chain rather than a nested call (because it is read left to right; Smalltalk makes minimal use of punctuator characters, so the syntax is not distinguishable).
How common are method chains in source code, and what is the distribution of chain length? Two studies have investigated this question: An Empirical Study of Method Chaining in Java by Nakamaru (PhD thesis), Matsunaga, Akiyama, Yamazaki, and Chiba, and Method Chaining Redux: An Empirical Study of Method Chaining in Java, Kotlin, and Python by Keshk, and Dyer.
The plot below shows the number of Java method chains having a given length, for code available in a given year. The red line is a fitted regression line for 2018, based on a model fitted to the complete dataset (code and data):
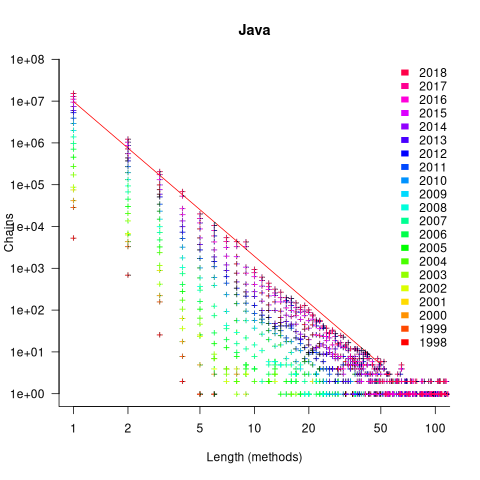
The fitted regression model is:

Why is the number of chains of all lengths growing by around 46% per year? I think this growth is driven by the growth in the amount of source measured. Measurements show that the percentage of source lines containing a method call is roughly constant. In the plot above, the number of unchained methods (i.e., chains of length one) increases in-step with the growth of chained methods. All chain lengths will grow at the same rate, if the source that contains them is growing.
What is responsible for the step change in the number of chains at around 10 methods? Nakamaru classified a random sample of 280 chains, and found that roughly 80% of chains longer than eight methods built an object, e.g., the following chain:
MoreObjects.toStringHelper(this) .add("iLine" , iLine) .add("lastK" , lastK) .add("spacesPending", spacesPending) .add("newlinesPending", newlinesPending) .add("blankLines", blankLines) .add("super", super.toString()) .toString() |
Are these chain usage patterns present in Python? The plot below shows the number of Python method chains having a given length, for code available in a given year. The red line is a fitted regression line for 2020, based on a model fitted to the complete dataset (code and data):

The fitted regression model is:

While this model is almost identical to the model fitted to the Java data (the annual growth rate is 39%), the above plot shows a large step change after chains of length two. Keshk’s paper focuses on replicating Nakamaru’s Java results, and then briefly discusses Python. I have an assortment of explanations, but nothing stands out.
Within code, how are method calls split between single calls and a chain of two or more calls?
The fractions in the plot below are calculated as the ratio of chains of length one (i.e., single method call) against chains containing two or more methods. The “j” shows Java ratios, and “p” Python ratios. The red lines show the fraction based on the total number of method calls, and the blue/green lines are based on occurrences of chains, i.e., chain of one vs chain of many (code and data):

The ratio of Java chains containing two or more methods vs one method, grew by around 6% a year between 2006 and 2018, which is only a small part of the overall 46% annual Java growth.
Method chaining is three times more common in Java than Python. In 2020 around a quarter of all method calls were in a chain of two or more, and single method calls were around ten times more common than multi-call chains.
In Python, the use of method chains has roughly remained unchanged over 15 years, with around 5% of all method calls appearing in a chain.
I don’t have a good idea for why method chains are three times more common in Java than Python. Are nested calls the more common usage in Python, or do developers use a sequence of calls communicating using temporary variables?
What of languages that don’t support method chaining, e.g., C. Is the distribution of the number of nested calls (or sequence of calls using temporaries) a power law with an exponent close to 3.7?
Suggestions and pointers to more data welcome.
Finding links between gcc source code and the C Standard
How close is the agreement between the behavior of a compiler and its corresponding language specification?
In the previous century, some Standards’ bodies offered a compiler validation service. However, even when the number of commercial compilers numbered in the hundreds, this service was not commercially viable. These days there are only a handful of industrial strength compilers.
The availability of huge quantities of Open source, for some languages, has created a new language specification. Being able to turn much of this source into executable programs has become an effective measure of compiler correctness.
Those working on C/C++ compilers (Open source or otherwise), often claim that they implement the requirements contained in the corresponding ISO Standard. Some are active in the ISO Standards’ process, and I believe that they do strive to implement the requirements contained in the language standard.
How confident can we be that all the requirements contained in a language standard are correctly implemented by a compiler?
There is a cottage industry of testing compiler runtime behavior, often using fuzzers, and sometimes a compiler is one of the programs chosen to test new fuzzing techniques. This research checks optimization and code generation.
This runtime testing is all well and good, but a large percentage of the text in a language specification contains requirements on the syntax and semantics. The quality of syntax/semantic testing depends on how well the people writing the tests understand the language semantics. It takes a year or two of detailed study to achieve an effective compiler-level of understanding of these ‘front-end’ requirements.
The approach taken by the Model Implementation C Checker to show syntax/semantic correctness was to cross-referenced every if-statement in the front-end to one or more lines in the C90 Standard (the 1990 edition of the ISO C Standard), or an internal house-keeping reference (the source contained 3K references to 1.3K requirements in the C Standard). This compiler/checker was formally validated by BSI. As far as I know, this is the only compiler source cross-referenced at the level of individual lines/if-statements; there are compilers whose source contains cross-references to the sections of a language specification.
The main benefit of this cross-referencing process is insuring that every requirement in the C Standard is addressed by the compiler (correctly or otherwise). Other benefits include providing packets of wording for targeted tests and the ability to generate a runtime trace of all language features involved in compiling a given translation unit.
Replicating this cross-referencing for the gcc or llvm C compiler front-ends would be a huge amount of work for somebody who already has a detailed knowledge of the C Standard, along with some knowledge of compilers. The number of pages in the Standard relating to the C language has grown from 101 pages in C90 to 190 pages in C23. At an average of 14 cross-referenceable lines per page, the expected number of cross-references is now likely to be around 2,700.
LLMs are great at extracting information from text, can generate impressive quality C conformance tests, and are much, much cheaper than C language experts. How good are LLMs at working out which section(s)/paragraph(s) in the C Standard are implemented by the source code of a function contained in, say, gcc?
The LLM prompt I used to test out the idea was:
List the section and paragraph number of the latest ISO C standard containing the requirements implemented in the following source code from a C compiler |
Links to all responses from: ChatGPT5 Thinking, Grok3 Fast and Gok3 Expert.
It is very likely that text from the various versions of the C Standard were in the training data of the larger LLMs, so I did not include this material in the prompt. ChatGPT5 Thinking listed the 2024 draft N3220 as its source document.
The source code was copied from the C front-end code of gcc (i.e., the directory: gcc-15.1.0/gcc/c), which contains 67KLOC, with 6.8K if-statements.
Starting small, the following code looked like an easy test (I removed the comment containing text from the C Standard and obscured the big clue in the original function name: null_pointer_constant_p):
bool check_is_n_ptr (const_tree expr) { /* This should really operate on c_expr structures, but they aren't yet available everywhere required. */ tree type = TREE_TYPE (expr); if (expr == nullptr_node) return true; return (TREE_CODE (expr) == INTEGER_CST && !TREE_OVERFLOW (expr) && integer_zerop (expr) && (INTEGRAL_TYPE_P (type) || (TREE_CODE (type) == POINTER_TYPE && VOID_TYPE_P (TREE_TYPE (type)) && TYPE_QUALS (TREE_TYPE (type)) == TYPE_UNQUALIFIED))); } |
Wow, ChatGPT5 Thinking’s response even included a note on why the code checks for an unqualified type:
Here are the exact C23 (ISO/IEC 9899:2024) clauses that your function is implementing:
6.3.2.3 Pointers, ¶3 — Definition of a null pointer constant: “An integer constant expression
with the value 0, such an expression cast to type void *, or the predefined constant nullptr
is called a null pointer constant.”
6.6 Constant expressions, ¶8 — What qualifies as an integer constant expression
(your INTEGER_CST / INTEGRAL_TYPE_P checks).
6.6 Constant expressions, ¶4 — Range requirement for constant expressions
(motivates the !TREE_OVERFLOW (expr) check).
6.4.4.6 Predefined constants, ¶¶1–3 — nullptr is a predefined constant (token classification;
ties to your expr == nullptr_node fast-path).
6.3.2.4 nullptr_t, ¶¶1–2 — Conversions of nullptr_t (confirms nullptr converts to any pointer
type yielding the null pointer value).
Notes
• The “cast to type void *” wording in 6.3.2.3 means unqualified void *,
which is why your code insists the pointed-to void is unqualified.
Grok3 Fast’s response was even more expansive (and almost instantaneous), listing examples of section/paragraphs containing uses of null pointers, and pointing out that the wording was unchanged until C23 (when the nullptr keyword was introduced, along with its type nullptr_t). It also pointed out gcc specific features of the implementation (the prompt did not identify the compiler).
That’s enough of the easy questions. The following code (comments removed, function name unchanged) is essentially asking a question: What is the promoted type of the argument?
tree c_type_promotes_to (tree type) { tree ret = NULL_TREE; if (TYPE_MAIN_VARIANT (type) == float_type_node) ret = double_type_node; else if (c_promoting_integer_type_p (type)) { if (TYPE_UNSIGNED (type) && (TYPE_PRECISION (type) == TYPE_PRECISION (integer_type_node))) ret = unsigned_type_node; else ret = integer_type_node; } if (ret != NULL_TREE) return (TYPE_ATOMIC (type) ? c_build_qualified_type (ret, TYPE_QUAL_ATOMIC) : ret); return type; } |
ChatGPT5 listed six references. Three were good, and the other three were closely related, but I would not have cited them. The seven Grok3 references came from several documents using slightly different section numbers. Updating the prompt to explicitly name N3220 as the document to use did not change Grok3’s cited references (for this question).
All the code in the previous questions was there because of text in the C Standard. How do ChatGPT5/Grok3 handle the presence of code that does not have standard associated text?
The following function contains code to handle named address spaces (defined in a 2005 Technical Report: TR 18037 Extensions to support embedded processors).
static tree qualify_type (tree type, tree like) { addr_space_t as_type = TYPE_ADDR_SPACE (type); addr_space_t as_like = TYPE_ADDR_SPACE (like); addr_space_t as_common; /* If the two named address spaces are different, determine the common superset address space. If there isn't one, raise an error. */ if (!addr_space_superset (as_type, as_like, &as_common)) { as_common = as_type; error ("%qT and %qT are in disjoint named address spaces", type, like); } return c_build_qualified_type (type, TYPE_QUALS_NO_ADDR_SPACE (type) | TYPE_QUALS_NO_ADDR_SPACE_NO_ATOMIC (like) | ENCODE_QUAL_ADDR_SPACE (as_common)); } |
ChatGPT5 listed six good references and pointed out the association between the named address space code and TR 18037. Grok3 Fast hallucinated extensive quoted text/references from TR 18037 related to named address spaces. Grok3 Expert pointed out that the Standard does not contain any requirements related to named address spaces and listed two reasonable references.
Finding appropriate cross-references is the time-consuming first step. Next, I want the LLM to add them as comments next to the corresponding code.
I picked a 312 line function, and updated the prompt to add comments to the attached file:
Find the section and paragraph numbers in the ISO C standard, specified in document N3220, containing the requirements implemented in the source code contained in the attached file, and add these section and paragraph numbers at the corresponding places in the code as comment |
ChatGPT5 Thinking thought for 5 min 46 secs (output), and Grok3 Expert thought for 3 mins 4 secs (output).
Both ChatGPT5 and Grok3 modified the existing code, either by joining adjacent lines, changing variable names, or deleting lines. ChatGPT made far fewer changes, while the Grok3 output was 65 lines shorter than the original (including the added comments).
Both LLMs added comments to blocks of if-statements (my fault for not explicitly specifying that every if should be cross-referenced), with ChatGPT5 adding the most cross-references.
One way to stop the LLMs making unasked for changes to the source is to have them focus on the added comments, i.e., ask for a diff that can be fed into patch. The updated prompt is:
Find the section and paragraph numbers in the ISO C standard, specified in document N3220, containing the requirements implemented by each if statement in the source code contained in the attached file. Create a diff file that patch can use to add these section and paragraph numbers as comments at the corresponding lines in the original code |
ChatGPT5 Thinking thought for around 4 min (it reported inconsistent values (output), and Grok3 Expert thought for 5 min 1 sec (output).
The ChatGPT5 patch contained many more cross-references than its earlier output, with comments on more if-statements. The Grok3 patch was a third the size of the ChatGPT5 patch.
How well did the LLMs perform?
ChatGPT5 did very well, and its patch output would be a good starting point for a detailed human expert edit. Perhaps an improved prompt, or some form of fine-tuning would useful improve performance.
Grok3 Fast does not appear to be usable, but Grok3 Expert could be used as an independent check against ChatGPT5 output.
Working at the section/paragraph level it is not always possible to give the necessary detailed cross-reference because some paragraphs contain multiple requirements. It might be easier to split the C Standard text into smaller chunks, rather than trying to get LLMs to give line offsets within a paragraph.
Recent Comments