Distribution of small project completion times
Records of project estimates and actual task times show that round numbers are very common. Various possible reasons have been suggested for why actual times are often reported as a round number. This post analyses the impact of round number reports of actual times on the accuracy of estimates.
The plot below shows the number of tasks having a given reported completion time for 1,525 tasks estimated to take 1-hour (code+data):
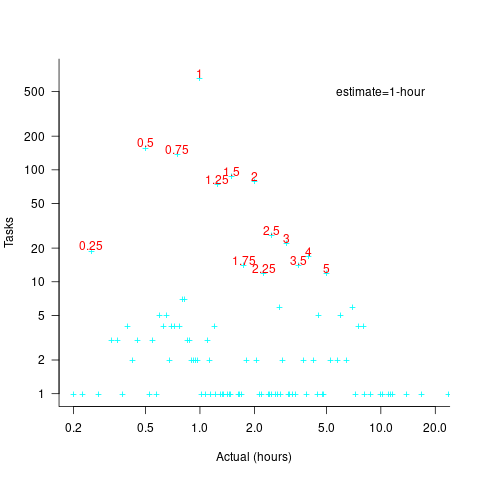
Of those 1,525 tasks estimated to take 1-hour, 44% had a reported completion time of 1-hour, 26% took less than 1-hour and 30% took more than 1-hour. The mean is 1.6 hours and the standard deviation 7.1. The spikiness of the distribution of actual times rules out analytical statistical analysis of the distribution.
If a large task is broken down into, say,  smaller tasks, all estimated to take the same amount of time
smaller tasks, all estimated to take the same amount of time  , what is the distribution of actual times for the large task?
, what is the distribution of actual times for the large task?
In the case of just two possible actual times to complete each smaller task, some percentage,  , of tasks are completed in actual time
, of tasks are completed in actual time  , and some percentage,
, and some percentage,  , completed in actual time
, completed in actual time  (with
(with  ). The probability distribution of the large task time,
). The probability distribution of the large task time, ") , for the two actual times case is:
, for the two actual times case is:
=(matrix{2}{1}{N k})(1-p_{t1})^k {p_{t1}}^{N-k}=(matrix{2}{1}{N k}){p_{t2}}^k (1-p_{t2})^{N-k}")
where:  , and
, and  .
.
The right-most equation is the probability distribution of the Binomial distribution, ") . The possible completion times for the large task start at
. The possible completion times for the large task start at  , followed by time increments of .
, followed by time increments of .
When there are three possible actual completion times for each smaller task, the calculation is complicated, and become more complicated with each new possible completion time.
A practical approach is to use Monte Carlo simulation. This involves simulating lots of large tasks containing smaller tasks. A sample of tasks is randomly drawn from the known 1,525 task actual times, and these actual times added to give one possible completion time. Running this process, say, 10,000 times produces what is known as the empirical distribution for the large task completion time.
The plot below shows the empirical distribution  smaller 1-hour tasks. The blue/green points show two peaks, the higher peak is a consequence of the use of round numbers, and the lower peak a consequence of the many non-round numbers. If the total times are rounded to 15 minute times, red points, a smoother distribution with a single peak emerges (code+data):
smaller 1-hour tasks. The blue/green points show two peaks, the higher peak is a consequence of the use of round numbers, and the lower peak a consequence of the many non-round numbers. If the total times are rounded to 15 minute times, red points, a smoother distribution with a single peak emerges (code+data):

When a large task involves smaller tasks estimated to take a variety of times, the empirical distribution of the actual time for each estimated time can be combined to give an empirical distribution of the large task (see sum_prob_distrib).
Provided enough information on task completion times is available, this technique works does what it says on the tin.
Recent Comments