Predicting the size of the Linux kernel binary
How big is the binary for the Linux kernel? Depending on the value of around 15,000 configuration options, the size of the version 5.8 binary could be anywhere between 7.3Mb and 2,134 Mb.
Who is interested in the size of the Linux kernel binary?
We are not in the early 1980s, when memory for a desktop microcomputer often topped out at 64K, and software was distributed on 360K floppies (720K when double density arrived; my companies first product was a code optimizer which reduced program size by around 10%).
While desktop systems usually have oodles of memory (disk and RAM), developers targeting embedded systems seek to reduce costs by minimizing storage requirements, security conscious organizations want to minimise the attack surface of the programs they run, and performance critical systems might want a kernel that fits within a processors’ L2/L3 cache.
When management want to maximise the functionality supported by a kernel within given hardware resource constraints, somebody gets the job of building kernels supporting various functionality to find out the size of the binaries.
At around 4+ minutes per kernel build, it’s going to take a lot of time (or cloud costs) to compare lots of options.
The paper Transfer Learning Across Variants and Versions: The Case of Linux Kernel Size by Martin, Acher, Pereira, Lesoil, Jézéquel, and Khelladi describes an attempt to build a predictive model for the size of the kernel binary. This paper includes an extensive list of references.
The author’s approach was to first obtain lots of kernel binary sizes by building lots of kernels using random permutations of on/off options (only on/off options were changed). Seven kernel versions between 4.13 and 5.8 were used, producing 243,323 size/option setting combinations (complete dataset). This data was used to train a machine learning model.
The accuracy of the predictions made by models trained on a single kernel version were accurate within that kernel version, but the accuracy of single version trained models dropped dramatically when used to predict the binary size of later kernel versions, e.g., a model trained on 4.13 had an accuracy of 5% MAPE predicting 4.13, when predicting 4.15 the accuracy is 20%, and 32% accurate predicting 5.7.
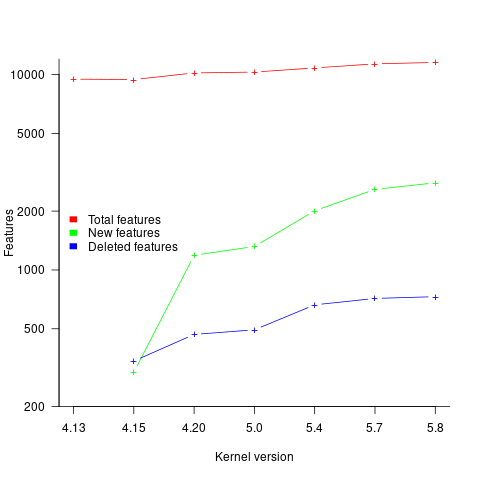
I think that the authors’ attempt to use this data to build a model that is accurate across versions is doomed to failure. The rate of change of kernel features (whose conditional compilation is supported by one or more build options) supported by Linux is too high to be accurately modelled based purely on information of past binary sizes/options. The plot below shows the total number of features, newly added, and deleted features in the modelled version of the kernel (code+data):
What is the range of impacts of each build option, on binary size?
If each build option is independent of the others (around 44% of conditional compilation directives in the kernel source contain one option), then the fitted coefficients of a simple regression model gives the build size increment when the corresponding option is enabled. After several cpu hours, the 92,562 builds involving 9,469 options in the version 4.13 build data were fitted. The plot below shows a sorted list of the size contribution of each option; the model  is 0.72, i.e., quite a good fit (code+data):
is 0.72, i.e., quite a good fit (code+data):
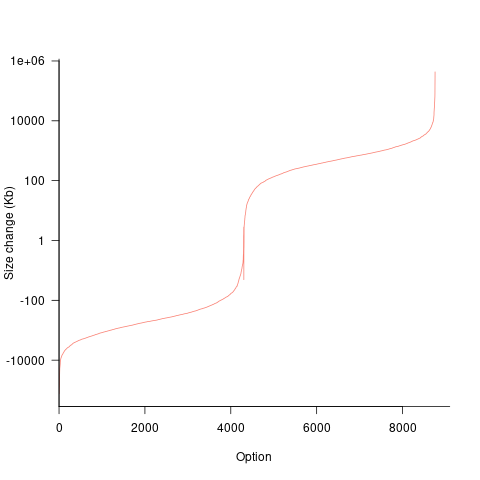
While the mean size increment for an enabled option is 75K, around 40% of enabled options decreases the size of the kernel binary. Modelling pairs of options (around 38% of conditional compilation directives in the kernel source contain two options) will have some impact on the pattern of behavior seen in the plot, but given the quality of the current model ( is 0.72) the change is unlikely to be dramatic. However, the simplistic approach of regression fitting the 90 million pairs of option interactions is not practical.
What might be a practical way of estimating binary size for any kernel version?
The size of a binary is essentially the quantity of code+static data it contains.
An estimate of the quantity of conditionally compiled source code dependent on a given option is likely to be a good proxy for that option’s incremental impact on binary size.
It’s trivial to scan source code for occurrences of options in conditional compilation directives, and with a bit more work, the number of lines controlled by the directive can be counted.
There has been a lot of evidence-based research on software product lines, and feature macros in particular. I was expecting to find a dataset listing the amount of code controlled by build options in Linux, but the data I can find does not measure Linux.
The Martin et al. build data is perfectfor creating a model linking quantity of conditionally compiled source code to change of binary size.
Anthropology and building software systems
Software systems are built by people, who are usually a member of one or more teams. While a lot of research effort has gone into studying the software/hardware used to build these systems, almost no effort has been invested in studying the activities of the people involved.
The study of human behaviors and cultures, in the broadest sense, sits within the field of Anthropology. The traditional image of an Anthropologist is someone who spends an extended period living with some remote tribe, publishing a monograph about their experiences on return to ‘civilisation’. In practice, anthropologists also study local tribes, such as professional workers.
Studies of the computer industry, by anthropologists, include: Global “Body Shopping” An Indian Labor System in the Information Technology Industry by Xiang Biao, and Cultures@SiliconValley by J. A. English-Lueck.
Reporters and professional authors sometimes write popular books for a general audience, which might be labelled pop anthropology. For instance, Kidder’s The Soul of a New Machine.
These academic/reporter publications are usually written by outsiders for an audience of outsiders. They are not intended to provide insights for insiders (Kidder’s book strikes me as reporting on the chaos that ensues when dysfunctional teams have to work together, which is not how it is described on its back cover).
If insiders want to learn about their community, some degree of insider knowledge is needed; exploring culture from the point of view of the subject of the study is known as Ethnography. Acquiring this knowledge can take years, an investment that will deter most researchers. Insightful insider commentary is most likely to come from insiders.
These days, insiders who write usually have blogs. Gerald Weinberg was an insider of times gone by, who wrote popular books for insiders about consulting in the software business; perhaps the most well known being “The Psychology of Computer Programming” (which really ought to be titled “The Sociology of Computer Programming”).
Who might be the consumers of research by anthropologists of software system development (assuming that a non-trivial amount eventually gets done)?
There are important outsiders, such as lawmakers looking to regulate.
Insiders only ever get to experience a sliver of the culture of software communities. The considered experiences of others can provide interesting insights, in particular learning about how teams working within other application domains operate.
Those seeking to change company culture ought to be looking to anthropology as a source of ideas for things that might work, or not.
History deals with the outcomes of past human behavior and culture, and there are a handful of historians of computing.
WebAssembly vs JavaScript performance: 2023 edition
WebAssembly is an assembly-like language intended to be executed by web browsers on an internal stack machine. The intent is that compilers for high-level languages (i.e., C, Cobol, and C#) treat WebAssembly just like they would the assembly language of a cpu. Some substantial applications have been ported, e.g., the R statistical environment, which is written in C and Fortran.
Some people claim that WebAssembly based applications will run faster, and consume less power, than those written in JavaScript or PHP. Now, one virtual machine is as much like any other. Performance differences are driven by compiler optimizations, the ease with which particular language features can be mapped to the available instructions, and an application’s use of easy/hard to map high-level language features.
Researchers have run benchmarks to compare the runtime performance and power consumption of Wasm against other browser based languages, and this post analyses the runtime performance results from two papers.
TL;DR: Relative performance for Wasm/JavaScript varies across browsers and programs. Everything interacts with everything else, which makes analysis complicated.
As is the case with most data analysis in software engineering, the researchers used rudimentary statistical techniques (which is a shame given the huge effort that went into collecting the data). The conclusions of both papers is that for WebAssembly/JavaScript, relative performance issues are complicated, but the techniques they used did not enable them to understand why.
What kind of statistical techniques are applicable for analysing these benchmarks?
Use of different languages/browsers might be expected to have some percentage impact on performance, e.g., programs written in language X will be p% faster/slower. The following equation is one modelling approach, and this equation can be fitted using nonlinear regression:
(1+c_j Browser_j)") , where:
, where:  is a constant,
is a constant,  is the fitted constant for language
is the fitted constant for language  , and
, and  is the fitted constant for browser
is the fitted constant for browser 
The problem with this equation is that it involves a separate equation for each combination of language/browser (assuming that all benchmarks are bundled together in the value of ). It is possible to use a single equation when there are just two languages/two browsers, by mapping them to the values 0/1.
All languages/browsers/benchmarks can be included in a single linear regression model by treating them as factors in a log transformed model; the equation is:  , where:
, where:  is the fitted constant for benchmark
is the fitted constant for benchmark  . The values of , , and are zero, or one for the corresponding fitted constant. All the factors on the right-hand-side are discrete, so a log transform has nothing to distort.
. The values of , , and are zero, or one for the corresponding fitted constant. All the factors on the right-hand-side are discrete, so a log transform has nothing to distort.
The fitted equation can then be transformed to:

This model assumes that each factor is independent of the others, i.e., the relative performance of each language does not depend on the browser, and that relative performance does not significantly vary between benchmarks, e.g., if  runs 10% faster when implemented in
runs 10% faster when implemented in  , then
, then  also runs close to 10% faster when implemented in .
also runs close to 10% faster when implemented in .
How well did the benchmark data from the two papers fit this model, and what were the performance numbers?
The study WebAssembly versus JavaScript: Energy and Runtime Performance by De Macedo, Abreu, Pereira, and Saraiva ran a wide range of benchmarks. It compared C/Wasm/JavaScript running on Chrome/Firefox/Edge. One set of benchmarks were 10 small compute-intensive programs (in Wasm/JavaScript), which were executed with small/medium/large amounts of input data; the other set of benchmarks were two large applications WasmBoy is a Game-boy/Gameboy Color Emulator (written in Typescript and compiled to Wasm), and PSPDFKit supporting viewing, annotating, and filling in forms in PDF documents (written in C/C++ and compiled to a both a subset of JavaScript and Wasm).
Results from the 10 small benchmarks showed strong interactions between browser and language (i.e., Wasm performance relative to JavaScript, varied between browsers; with Edge being faster and Firefox being slower), and a lot of interaction between benchmark and input data size. Support for Wasm is relatively new, relative to the much more mature JavaScript, so it’s not surprising that different browsers have different performance; I’m arm waving when I say that the input size dependency may be related to JIT issues (code).
When interactions are included, the fitted equation has the form:

Analysing the results for the two applications, we find that:
- WasmBoy: the factors were independent, and WebAssembly was faster than JavaScript. The
 factor was 0.84 for Wasm and 1 for JavaScript,
factor was 0.84 for Wasm and 1 for JavaScript, - PSPDFKit: there was interaction between the language and browser, with behavior similar to that seen for the small benchmarks.
The study Comparing the Energy Efficiency of WebAssembly and JavaScript in Web Applications on Android Mobile Devices by van Hasselt, Huijzendveld, Noort, de Ruijter, Islam, and Malavolta compared the performance of WebAssembly/JavaScript running compute intensive benchmarks on Firefox/Chrome.
Fitting a regression model to the data from the eight benchmarks showed strong interactions between benchmark programs and language, with each language being faster for some programs (code).
It’s not surprising that the results failed to show a conclusive performance advantage for either WebAssembly or JavaScript, across benchmarks. The situation might change as the wasm virtual machine is tuned, and compilers targetting wasm implement a wider range of optimizations.
Update
A performance analysis of C, Rust, Go, and Javascript compiled to Webassembler
Perturbed expressions may ‘recover’
This week I have been investigating the impact of perturbing the evaluation of random floating-point expressions. In particular, the impact of adding 1 (and larger values) at a random point in an expression containing many binary operators (simply some combination of add/multiply).
What mechanisms make it possible for the evaluation of an expression to be unchanged by a perturbation of +1.0 (and much larger values)? There are two possible mechanisms:
- the evaluated value at the perturbation point is ‘watered down’ by subsequent operations, such that the original perturbed value makes no contribution to the final result. For instance, the IEEE single precision float mantissa is capable of representing 6-significant digits; starting with, say, the value
0.23, perturbing by adding1.0gives1.23, followed by a sequence of many multiplications by values between zero and one could produce, say, the value6.7e-8, which when added to, say,0.45, gives0.45, i.e., the perturbed value is too small to affect the result of the add, - the perturbed branch of the expression evaluation is eventually multiplied by zero (either because the evaluation of the other branch produces zero, or the operand happens to be zero). The exponent of an IEEE single precision float can represent values as small as
1e-38, before underflowing to zero (ignoring subnormals); something that is likely to require many more multiplies than required to lose 6-significant digits.
The impact of a perturbation disappears when its value is involved in a sufficiently long sequence of repeated multiplications.
The probability that the evaluation of a sequence of  multiplications of random values uniformly distributed between zero and one produces a result less than
multiplications of random values uniformly distributed between zero and one produces a result less than  is given by
is given by }/{(N-1)!}") , where
, where  is the incomplete gamma function, and
is the incomplete gamma function, and  is the upper bounds (1 in our case). The plot below shows this cumulative distribution function for various (code):
is the upper bounds (1 in our case). The plot below shows this cumulative distribution function for various (code):
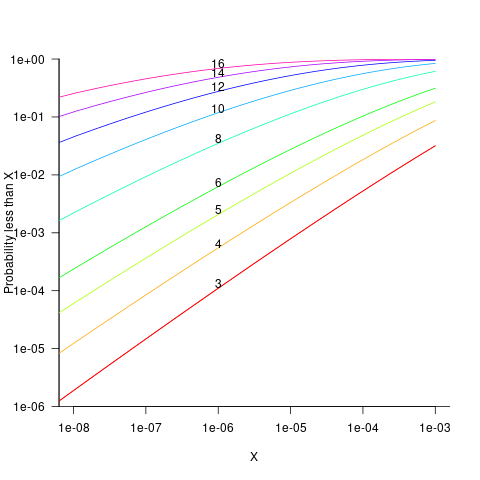
Looking at this plot, a sequence of 10 multiplications has around a 1-in-10 chance of evaluating to a value less than 1e-6.
In practice, the presence of add operations will increase the range of operands values to be greater than one. The expected distribution of result values for expressions containing various percentages of add/multiply operators is covered in an earlier post.
The probability that the evaluation of an expression involves a sequence of multiplications depends on the percentage of multiply operators it contains, and the shape of the expression tree. The average number of binary operator evaluations in a path from leaf to root node in a randomly generated tree of operands is proportional to  .
.
When an expression has a ‘bushy’ balanced form, there are many relatively distinct evaluation paths, the expected number of operations along a path is proportional to  . The plot below shows a randomly generated ‘bushy’ expression tree containing 25 binary operators, with 80% multiply, and randomly selected values (perturbation in red, additions in green; code+data):
. The plot below shows a randomly generated ‘bushy’ expression tree containing 25 binary operators, with 80% multiply, and randomly selected values (perturbation in red, additions in green; code+data):
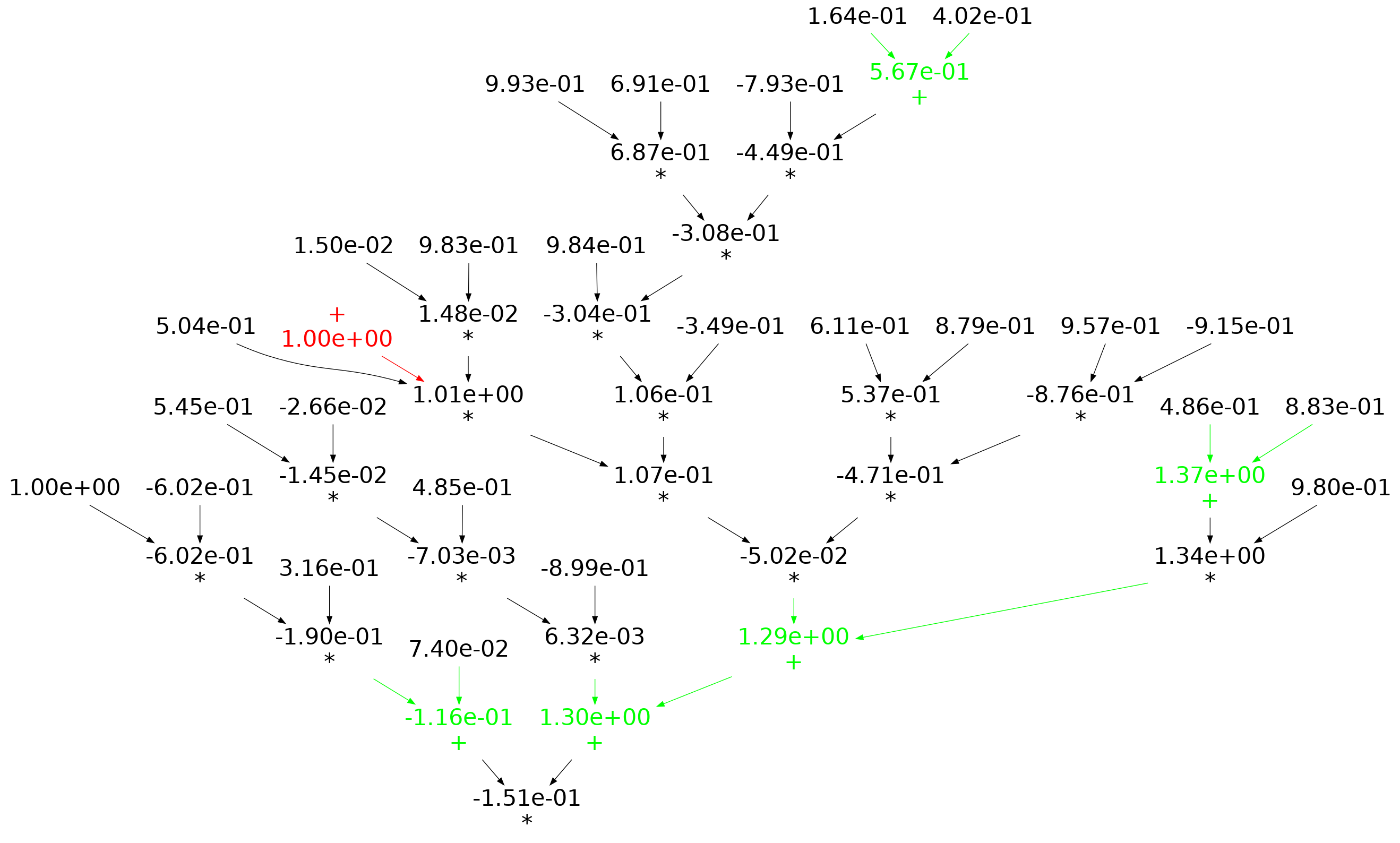
When an expression has a ‘tall’ form, there is one long evaluation path, with a few short paths hanging off it, the expected number of operations along the long path is proportional to . The plot below shows a randomly generated ‘tall’ expression tree containing 25 binary operators, with 80% multiply, and randomly selected values (perturbation in red, additions in green; code+data):

If, one by one, the result of every operator in an expression is systematically perturbed (by adding some value to it), it is known that in some cases the value of the perturbed expression is the same as the original.
The following results were obtained by generating 200 random C expressions containing some percentage of add/multiply, some number of operands (i.e., 25, 50, 75, 100, 150), one-by-one perturbing every operator in every expression, and comparing the perturbed result value to the original value. This process was repeated 200 times, each time randomly selecting operand values from a uniform distribution between -1 and 1. The perturbation values used were: 1e0, 1e2, 1e4, 1e8, 1e16. A 32-bit float type was used throughout.
Depending on the shape of the expression tree, with 80% multiplications and 100 operands, the fraction of perturbed expressions returning an unchanged value can vary from 1% to 40%.
The regression model fitted to the fraction of unchanged expressions contains lots of interactions (the simple version is that the fraction unchanged increases with more multiplications, decreases as the log of the perturbation value, the square root of the number of operands is involved; code+data):
*(sqrt{OPD}-0.007*AM)+sqrt{OPD}(0.05-0.08*AM)")
where:  is the fraction of perturbed expressions returning the original value,
is the fraction of perturbed expressions returning the original value,  the percentage of add operators (not multiply),
the percentage of add operators (not multiply),  the number of operands in the expression, and
the number of operands in the expression, and  the perturbation value.
the perturbation value.
There is a strong interaction with the shape of the expression tree, but I have not found a way of integrating this into the model.
The following plot shows the fraction of expressions unchanged by adding one, as the perturbation point moves up a tall tree, x-axis, for expressions containing 50 and 100 operands, and various percentages of multiplications (code+data):
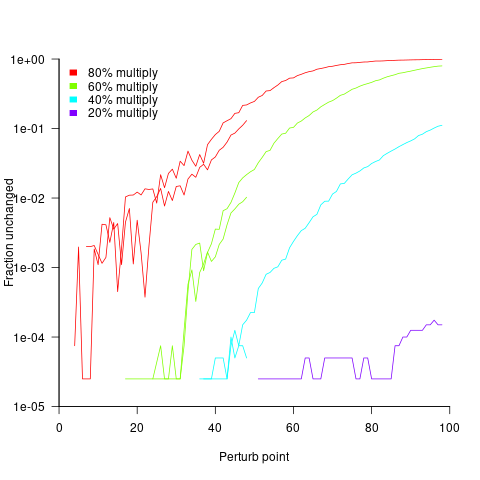
No attempt was made to count the number of expression evaluations where the perturbed value was eventually multiplied by zero (the second bullet point discussed at the start).
Distribution of add/multiply expression values
The implementation of scientific/engineering applications requires evaluating many expressions, and can involve billions of adds and multiplies (divides tend to be much less common).
Input values percolate through an application, as it is executed. What impact does the form of the expressions evaluated have on the shape of the output distribution; in particular: What is the distribution of the result of an expression involving many adds and multiplies?
The number of possible combinations of add/multiply grows rapidly with the number of operands (faster than the rate of growth of the Catalan numbers). For instance, given the four interchangeable variables: w, x, y, z, the following distinct expressions are possible: w+x+y+z, w*x+y+z, w*(x+y)+z, w*(x+y+z), w*x*y+z, w*x*(y+z), w*x*y*z, and w*x+y*z.
Obtaining an analytic solution seems very impractical. Perhaps it’s possible to obtain a good enough idea of the form of the distribution by sampling a subset of calculations, i.e., the output from plugging random values into a large enough sample of possible expressions.
What is needed is a method for generating random expressions containing a given number of operands, along with a random selection of add/multiply binary operators, then to evaluate these expressions with random values assigned to each operand.
The approach I used was to generate C code, and compile it, along with the support code needed for plugging in operand values (code+data).
A simple method of generating postfix expressions is to first generate operations for a stack machine, followed by mapping this to infix form to a postfix form.
The following awk generates code of the form (‘executing’ binary operators, o, right to left): o v o v v. The number of variables in an expression, and number of lines to generate, are given on the command line:
# Build right to left function addvar() { num_vars++ cur_vars++ expr="v " expr # choose variable later } function addoperator() { cur_vars-- expr="o " expr # choose operator later } function genexpr(total_vars) { cur_vars=2 num_vars=2 expr="v v" # Need two variables on stack while (num_vars <= total_vars) { if (cur_vars == 1) # Must push a variable addvar() else if (rand() > 0.2) # Seems to produce reasonable expressions addvar() else addoperator() } while (cur_vars > 1) # Add operators to use up operands addoperator() print expr } BEGIN { # NEXPR and VARS are command line options to awk if (NEXPR != "") num_expr=NEXPR else num_expr=10 for (e=1; e <=num_expr; e++) genexpr(VARS) } |
the following awk code maps each line of previously generated stack machine code to a C expression, wraps them in a function, and defines the appropriate variables.
function eval(tnum) { if ($tnum == "o") { printf("(") tnum=eval(tnum+1) #recurse for lhs if (rand() <= PLUSMUL) # default 0.5 printf("+") else printf("*") tnum=eval(tnum) #recurse for rhs printf(")") } else { tnum++ printf("v[%d]", numvars) numvars++ # C is zero based } return tnum } BEGIN { numexpr=0 print "expr_type R[], v[];" print "void eval_expr()" print "{" } { numvars=0 printf("R[%d] = ", numexpr) numexpr++ # C is zero based eval(1) printf(";\n") next } END { # print "return(NULL)" printf("}\n\n\n") printf("#define NUMVARS %d\n", numvars) printf("#define NUMEXPR %d\n", numexpr) printf("expr_type R[NUMEXPR], v[NUMVARS];\n") } |
The following is an example of a generated expression containing 100 operands (the array v is filled with random values):
R[0] = ((((((((((((((((((((((((((((((((((((((((((((((((( ((((((((((((((((((((((((v[0]*v[1])*v[2])+(v[3]*(((v[4]* v[5])*(v[6]+v[7]))+v[8])))*v[9])+v[10])*v[11])*(v[12]* v[13]))+v[14])+(v[15]*(v[16]*v[17])))*v[18])+v[19])+v[20])* v[21])*v[22])+(v[23]*v[24]))+(v[25]*v[26]))*(v[27]+v[28]))* v[29])*v[30])+(v[31]*v[32]))+v[33])*(v[34]*v[35]))*(((v[36]+ v[37])*v[38])*v[39]))+v[40])*v[41])*v[42])+v[43])+ v[44])*(v[45]*v[46]))*v[47])+v[48])*v[49])+v[50])+(v[51]* v[52]))+v[53])+(v[54]*v[55]))*v[56])*v[57])+v[58])+(v[59]* v[60]))*v[61])+(v[62]+v[63]))*v[64])+(v[65]+v[66]))+v[67])* v[68])*v[69])+v[70])*(v[71]*(v[72]*v[73])))*v[74])+v[75])+ v[76])+v[77])+v[78])+v[79])+v[80])+v[81])+((v[82]*v[83])+ v[84]))*v[85])+v[86])*v[87])+v[88])+v[89])*(v[90]+v[91])) v[92])*v[93])*v[94])+v[95])*v[96])*v[97])+v[98])+v[99])*v[100]); |
The result of each generated expression is collected in an array, i.e., R[0], R[1], R[2], etc.
How many expressions are enough to be a representative sample of the vast number that are possible? I picked 250. My concern was the C compilers code generator (I used gcc); the greater the number of expressions, the greater the chance of encountering a compiler bug.
How many times should each expression be evaluated using a different random selection of operand values? I picked 10,000 because it was a big number that did not slow my iterative trial-and-error tinkering.
The values of the operands were randomly drawn from a uniform distribution between -1 and 1.
What did I learn?
- Varying the number of operands in the expression, from 25 to 200, had little impact on the distribution of calculated values.
- Varying the form of the expression tree, from wide to deep, had little impact on the distribution of calculated values.
- Varying the relative percentage of add/multiply operators had a noticeable impact on the distribution of calculated values. The plot below shows the number of expressions (binned by rounding the absolute value to three digits) having a given value (the power law exponents fitted over the range 0 to 1 are: -0.86, -0.61, -0.36; code+data):
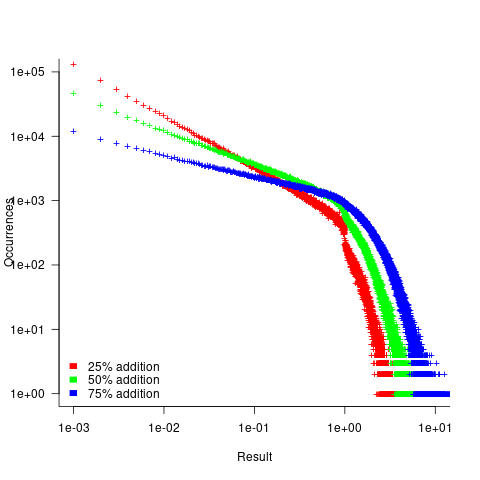
A rationale for the change in the slopes, for expressions containing different percentages of add/multiply, can be found in an earlier post looking at the distribution of many additions (the Irwin-Hall distribution, which tends to a Normal distribution), and many multiplications (integer power of a log).
- The result of many additions is to produce values that increase with the number of additions, and spread out (i.e., increasing variance).
- The result of many multiplications is to produce values that become smaller with the number of multiplications, and become less spread out.
Which recent application spends a huge amount of time adding/multiplying values in the range -1 to 1?
Large language models. Yes, under the hood they are all linear algebra; adding and multiplying large matrices.
LLM expressions are often evaluated using a half-precision floating-point type. In this 16-bit type, the exponent is biased towards supporting very small values, at the expense of larger values not being representable. While operations on a 10-bit significand will experience lots of quantization error, I suspect that the behavior seen above not noticeable change.
An evidence-based software engineering book from 2002
I recently discovered the book A Handbook of Software and Systems Engineering: Empirical Observations, Laws and Theories by Albert Endres and Dieter Rombach, completed in 2002.
The preface says: “This book is about the empirical aspects of computing. … we intend to look for rules and laws, and their underlying theories.” While this sounds a lot like my Evidence-based Software Engineering book, the authors take a very different approach.
The bulk of the material consists of a detailed discussion of 50 ‘laws’, 25 hypotheses and 12 conjectures based on the template: 1) a highlighted sentence making some claim, 2) Applicability, i.e., situations/context where the claim is likely to apply, 3) Evidence, i.e., citations and brief summary of studies.
As researchers of many years standing, I think the authors wanted to present a case that useful things had been discovered, even though the data available to them is nowhere near good enough to be considered convincing evidence for any of the laws/hypotheses/conjectures covered. The reasons I think this book is worth looking at are not those intended by the authors; my reasons include:
- the contents mirror the unquestioning mindset that many commercial developers have for claims derived from the results of software research experiments, or at least the developers I talk to about software research. I’m forever educating developers about the need for replications (the authors give a two paragraph discussion of the importance of replication), that sample size is crucial, and using professional developers as subjects.
Having spent twelve chapters writing authoritatively on 50 ‘laws’, 25 hypotheses and 12 conjectures, the authors conclude by washing their hands: “The laws in our set should not be seen as dogmas: they are not authoritatively asserted opinions. If proved wrong by objective and repeatable observations, they should be reformulated or forgotten.”
For historians of computing this book is a great source for the software folklore of the late 20th/early 21st century,
- the Evidence sections for each of the laws/hypotheses/conjectures is often unintentionally damming in its summary descriptions of short/small experiments involving a handful of people or a few hundred lines of code. For many, I would expect the reaction to be: “Is that it?”
Previously, in developer/researcher discussions, if a ‘fact’ based on the findings of long ago software research is quoted, I usually explain that it is evidence-free folklore; followed by citing The Leprechauns of Software Engineering as my evidence. This book gives me another option, and one with greater coverage of software folklore,
- the quality of the references, which are often to the original sources. Researchers tend to read the more recently published papers, and these are the ones they often cite. Finding the original work behind some empirical claim requires following the trail of citations back in time, which can be very time-consuming.
Endres worked for IBM from 1957 to 1992, and was involved in software research; he had direct contact with the primary sources for the software ‘laws’ and theories in circulation today. Romback worked for NASA in the 1980s and founded the Fraunhofer Institute for Experimental Software Engineering.
The authors cannot be criticized for the miniscule amount of data they reference, and not citing less well known papers. There was probably an order of magnitude less data available to them in 2002, than there is available today. Also, search engines were only just becoming available, and the amount of material available online was very limited in the first few years of 2000.
I started writing a book in 2000, and experienced the amazing growth in the ability of search engines to locate research papers (first using AltaVista and then Google), along with locating specialist books with Amazon and AbeBooks. I continued to use university libraries for papers, which I did not use for the evidence-based book (not that this was a viable option).
von Neumann’s deduction that biological reproduction is digital
We now know that the reproduction and growth of organisms is driven by DNA and proteins. The DNA contains the instructions which proteins execute.
If we travelled back in time, what arguments might we use to convince people that ‘our’ model for how organisms reproduced and grew was correct?
The General and Logical Theory of Automata is a talk given in 1948 by John von Neumann, four years before the discovery of the structure of DNA.
In this talk, von Neumann deduces from first principles:
- that the mechanism for organism reproduction must be digitally based, rather than analogue. His argument is based on error rates. The performance of the recently invented computers showed that it was possible for digital systems to return correct results for calculations requiring at least
 operations; while for analogue systems the signal/noise ratio is often
operations; while for analogue systems the signal/noise ratio is often  , with
, with  to
to  sometimes being possible.
sometimes being possible.
Prior to 1940s valve based electronic computers, relays were used to build what were essentially digital devices.
Relays go back to the mid-1800s, which is when Boolean algebra was created. The Jacquard weaving loom takes us back to the start of the 1800s, but there is not yet any digital mathematics to cite,
- it is possible for a simple machine to build a much more complicated machine. Twelve years earlier, Turing had published his results around the universal capabilities of a Turing machine, i.e., Turing completeness, the ability of any Turing machine to perform any calculation that any other Turing machine can calculate.
Turing completeness is a surprising result. An argument that it is possible for simple machines to build more complicated, prior to Turin, would have to rely on evidence such as ship building,
- a conceptual algorithm for a self-reproducing machine; this uses two Turing machines, and a mechanism for sequentially controlling operations.
A talk on automata obviously has to say something about organic computers, i.e., the brain. The von Neumann paper intermixes the discussion of neurons and reproduction. McCulloch, of McCulloch & Pitts neurons fame, was in the audience, as was the psychologist Karl Lashley, and neuroscientist Lorente de Nó. The recorded post talk discussion was mostly ‘brain’ oriented.
Conference vs Journal publication
Today is the start of the 2023 International Conference on Software Engineering (the 45’th ICSE, pronounced ick-see), the top ranked software systems conference and publication venue; this is where every academic researcher in the field wants to have their papers appear. This is a bumper year, of the 796 papers submitted 209 were accepted (26%; all numbers a lot higher than previous years), and there are 3,821 people listed as speaking/committee member/chairing session. There are also nine co-hosted conferences (i.e., same time/place) and twenty-two co-hosted workshops.
For new/niche conferences, the benefit of being co-hosted with a much larger conference is attracting more speakers/attendees. For instance, the International Conference on Technical Debt has been running long enough for the organizers to know how hard it is to fill a two-day program. The submission deadline for TechDebt 2023 papers was 23 January, six-weeks after researchers found out whether their paper had been accepted at ICSE, i.e., long enough to rework and submit a paper not accepted at ICSE.
Software research differs from research in many other fields in that papers published in major conferences have a greater or equal status compared to papers published in most software journals.
The advantage that conferences have over journals is a shorter waiting time between submitting a paper, receiving the acceptance decision, and accepted papers appearing in print. For ICSE 2023 the yes/no acceptance decision wait was 3-months, with publication occurring 5-months later; a total of 8-months. For smaller conferences, the time-intervals can be shorter. With journals, it can take longer than 8-months to hear about acceptance, which might only be tentative, with one or more iterations of referee comments/corrections before a paper is finally accepted, and then a long delay before publication. Established academics always have a story to tell about the time and effort needed to get one particular paper published.
In a fast changing field, ‘rapid’ publication is needed. The downside of having only a few months to decide which papers to accept, is that there is not enough time to properly peer-review papers (even assuming that knowledgable reviewers are available). Brief peer-review is not a concern when conference papers are refined to eventually become journal papers, but researchers’ time is often more ‘productively’ spent writing the next conference paper (productive in the sense of papers published per unit of effort), this is particularly true given that work invested in a journal publication does not automatically have the benefit of greater status.
The downside of rapid publication without follow-up journal publication, is the proliferation of low quality papers, and a faster fashion cycle for research topics (novelty is an important criterion for judging the worthiness of submitted papers).
Conference attendance costs (e.g., registration fee+hotel+travel+etc) can be many thousands of pounds/dollars, and many universities/departments will only fund those who to need to attend to present a paper. Depending on employment status, the registration fee for just ICSE is $1k+, with fees for each co-located events sometimes approaching $1k.
Conferences have ‘solved’ this speaker only funding issue by increasing the opportunities to present a paper, by, for instance, sessions for short 7-minute talks, PhD students, and even undergraduates (which also aids the selection of those with an aptitude for the publish or perish treadmill).
The main attraction of attending a conference is the networking opportunities it provides. Sometimes the only people at a session are the speakers and their friends. Researchers on short-term contracts will be chatting to Principle Investigators whose grant applications were recently approved. Others will be chatting to existing or potential collaborators; and there is always lots of socialising. ICSE even offers childcare for those who can afford to fly their children to Australia, and the locals.
There is an industrial track, but these are often treated as second class citizens, e.g., if a schedule clash occurs they will be moved or cancelled. There is even a software engineering in practice track. Are the papers on other tracks expected to be unconnected with software engineering practice, or is this an academic rebranding of work related to industry? While academics offer lip-service to industrial relevance, connections with industry are treated as a sign of low status.
In general, for people working in industry, I don’t think it’s worth attending an academic conference. Larger companies treat conferences as staff recruiting opportunities.
Are people working in industry more likely to read conference papers than journal papers? Are people working in industry more likely to read ICSE papers than papers appearing at other conferences?
My book Evidence Based Software Engineering cites 2,035 papers, and is a sample of one, of people working in industry. The following table shows the percentage of papers appearing in each kind of publication venue (code+data):
Published %
Journal 42
Conference 18
Technical Report 13
Book 11
Phd Thesis 3
Masters Thesis 2
In Collection 2
Unpublished 2
Misc 2 |
The 450 conference papers appeared at 285 different conferences, with 26% of papers appearing at the top ten conferences. The 871 journal papers appeared in 389 different journals, with 24% of the papers appearing in the top ten journals.
Count Conference 27 International Conference on Software Engineering 15 International Conference on Mining Software Repositories 14 European Software Engineering Conference 13 Symposium on the Foundations of Software Engineering 10 International Conference on Automated Software Engineering 8 International Symposium on Software Reliability Engineering 8 International Symposium on Empirical Software Engineering and Measurement 8 International Conference on Software Maintenance 7 International Conference on Software Analysis, Evolution, and Reengineering 7 International Conference on Program Comprehension Count Journal 28 Transactions on Software Engineering 27 Empirical Software Engineering 25 Psychological Review 21 PLoS ONE 19 The Journal of Systems and Software 18 Communications of the ACM 17 Cognitive Psychology 15 Journal of Experimental Psychology: Learning, Memory, & Cognition 14 Memory & Cognition 13 Psychonomic Bulletin & Review 13 Psychological Bulletin |
Transactions on Software Engineering has the highest impact factor of any publication in the field, and it and The Journal of Systems and Software rank second and third on the h5-index, with ICSE ranked first (in the field of software systems).
After scanning paper titles, and searching for pdfs, I have a to-study collection of around 20 papers and 10 associated datasets from this year’s ICSE+co-hosted.
The difference is significant
A statement that invariably appears in the published results of empirical studies comparing some property of two or more sets of numbers is that the difference is significant (if the difference is not significant, the paper is unlikely to be published). Here, the use of the word significant is the shortened form of the term statistically significant.
It is possible that two sets of measurements just so happen to have, for instance, the same/different mean value. Statistical significance is an estimate of the likelihood that an observed result is unlikely to have occurred by chance. The mechanics of calculating a numeric value for statistical significance can be complicated; the commonly seen p-value applies to a particular kind of statistical significance.
The fact that a difference is unlikely to have occurred by chance does not mean that the magnitude of the difference is of any practical use, or of any theoretical interest.
How large must a difference be to make it of practical use?
When I was in the business of selling code optimization tools for microcomputer software, a speed/code size improvement of at least 10% was needed before a worthwhile number of people were likely to pay for the software (a few would pay for less, and a few wanted more improvements before they would pay). I would not be surprised to find that very different percentages were applicable in other developer ecosystems.
In software engineering research papers, presentation of the practical use of work is often nothing more than a marketing pitch by the authors, not a list of estimated usefulness for different software ecosystems.
These days the presentation of material in empirical software engineering papers is often organized around a series of research questions, e.g., “How does X vary across projects?”, “Does the presence of X significantly impact the issue resolution time?”. One or more of these research questions are pitched as having practical relevance, and the statistical significance of the results is presented as vindication of this claimed relevance. Getting a paper published requires that those asked to review agree that the questions it asks and answers are interesting.
This method of paper organization and presentation is not unique to researchers in software engineering. To attract funding, all researchers need to actively promote the value of their wares.
The problem I have with software engineering papers is the widespread use of simplistic techniques (e.g., a Wilcoxon signed-rank test to check the significance of the difference between the means of two samples), and reporting little more than p-value significance; yes, included plots may sometimes be visually appealing, but other times just confused.
If researchers fitted regression models to their data, it becomes possible to estimate the contribution made by each of the attributes measured to the observed behavior. Surprisingly often, the size of the contribution is relatively small, while still being statistically significant.
By not building regression models, software researchers are cluttering up the list of known statistically significant behaviors with findings about factors whose small actual contribution makes it unlikely that they will be of practical interest.
Computer: Plot the data
Last Saturday I attended my first 24-hour hackathon in over 5-years (as far as I know, also the first 24-hour hackathon in London since COVID); the GenAI Hackathon.
I had a great idea for the tool to build. Readers will be familiar with the scene in sci-fi films where somebody says “Computer: Plot the data”, and a plot appears on the appropriate screen. I planned to implement this plot-the-data app using LLMs.
The easy option is to use speech to text, using something like OpenAI’s Whisper, as a front-end to a conventional plotting program. The hard option is to also use an LLM to generate the code needed to create the plot; I planned to do it the hard way.
My plan was to structure the internal functionality using langchain tools and agents. langchain can generate Python and execute this code.
I decided to get the plotting working first, and then add support for speech input. With six lines of Python I created a program that works every now and again; here is the code (which assumes that the environment variable OPENAI_API_KEY has been set to a valid OpenAI API key; the function create_csv_agent is provided by langchain):
from langchain.agents import create_csv_agent from langchain.llms import OpenAI import pandas agent = create_csv_agent(OpenAI(temperature=0.0, verbose=True), "aug-oct_day_items.csv", verbose=True) agent.run("Plot the Aug column against Oct column.") |
Sometimes this program figures out that it needs to call matplotlib to display the data, sometimes its output is a set of instructions for how this plot functionality could be implemented, sometimes multiple plots appear (with lines connecting points, and/or a scatter plot).
Like me, and others, readers who have scratched the surface of LLMs have read that setting the argument temperature=0.0 ensures that the output is always the same. In theory this is true, but in practice the implementation of LLMs contains some intrinsic non-determinism.
The behavior can be made more consistent by giving explicit instructions (just like dealing with humans). I prefixed the user input instructions to use matplotlib, use column names as the axis labels, and to generate a scatter plot, finally a request to display the plot is appended.
In the following code, the first call to plot_data specifies the ‘two month columns’, and the appropriate columns are selected from the csv file.
from langchain.agents import create_csv_agent from langchain.llms import OpenAI import pandas def plot_data(file_str, usr_str): agent = create_csv_agent(OpenAI(temperature=0.0, model_name="text-davinci-003", verbose=True), file_str, verbose=True) plot_txt="Use matplotlib to plot data and" +\ " use the column names for axis labels." +\ " I want you to create a scatter " +\ usr_str + " Display the plot." agent.run(plot_txt) plot_data("aug-oct_day_items.csv", "plot using the two month columns.") plot_data("task-est-act.csv", "plot using the estimates and actuals.") plot_data("task-est-act.csv", "plot the estimates and actuals using a logarithmic scale.") |
The first call to plot_data worked as expected, producing the following plot (code+data):
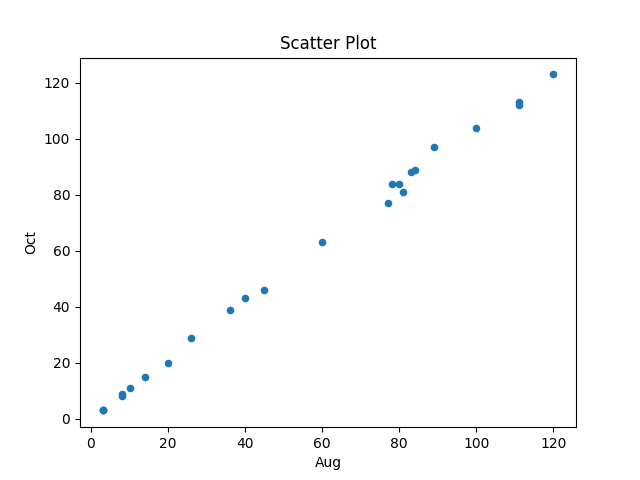
The second call failed with an ‘internal’ error. The generated Python has incorrect indentation:
IndentationError: unexpected indent (<unknown>, line 2) I need to make sure I have the correct indentation. |
While the langchain agent states what it needs to do to correct the error, it repeats the same mistake several times before giving up.
Like a well-trained developer, I set about trying different options (e.g., changing the language model) and searching various question/answer sites. No luck.
Finally, I broke with software developer behavior and added the line “Use the same indentation for each python statement.” to the prompt. Prompt engineering behavior is to explicitly tell the LLM what to do, not to fiddle with configuration options.
So now the second call to plot_data works, and the third call sometimes does odd things.
At the hack I failed to convince anybody else to work on this project with me. So I joined another project and helped out (they were very competent and did not really need my help), while fiddling with the Plot-the-data idea.
The code+test data is in the Plot-the-data Github repo. Pull requests welcome.
Recent Comments