Archive
The probability of encountering a given variable
If I am reading through the body of a function, what is the probability of a particular variable being the next one I encounter? A good approximation can be calculated as follows: Count the number of occurrences of all variables in the function definition up to the current point and work out the percentage occurrence for each of them, the probability of a particular variable being seen next is approximately equal to its previously seen percentage. The following graph is the evidence I give for this approximation.
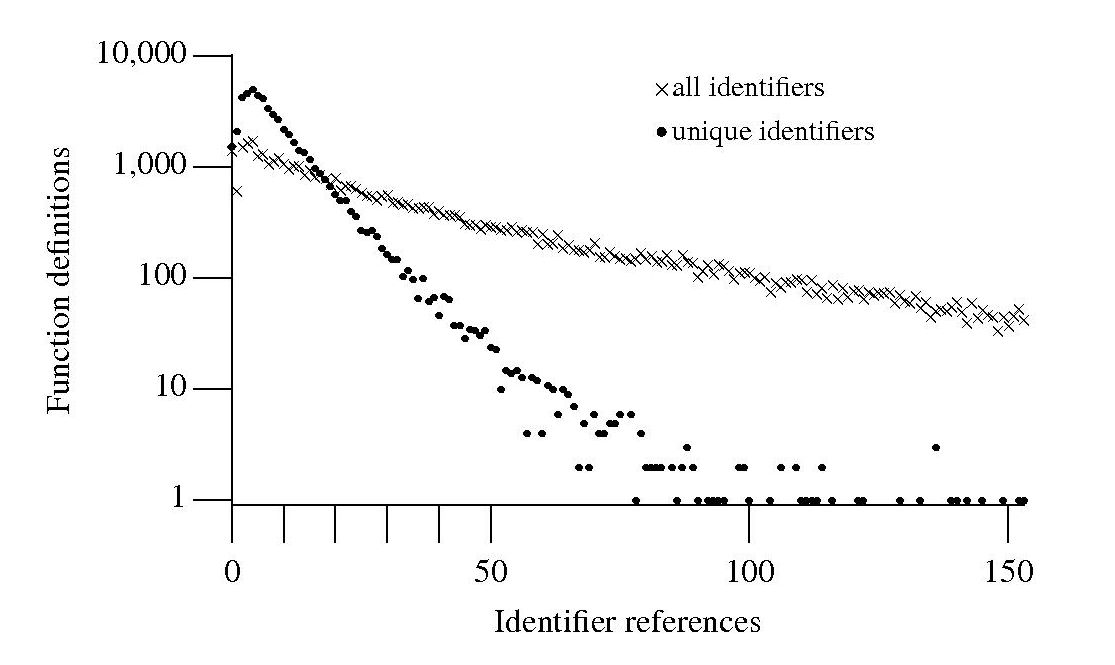
The graph shows a count of the number of C function definitions containing identifiers that are referenced a given number of times, e.g., if the identifier x is referenced five times in one function definition and ten times in another the function definition counts for five and ten are both incremented by one. That one axis is logarithmic and the bullets and crosses form almost straight lines hints that a Zipf-like distribution is involved.
There are many processes that will generate a Zipf distribution, but the one that interests me here is the process where the probability of the next occurrence of an event occurring is proportional to the probability of it having previously occurred (this includes some probability of a new event occurring; follow the link to Simon’s 1955 paper).
One can think of the value (i.e., information) held in a variable as having a given importance and it is to be expected that more important information is more likely to be operated on than less important information. This model appeals to me. Another process that will generate this distribution is that of Monkeys typing away on keyboards and while I think source code contains lots of random elements I don’t think it is that random.
The important concept here is operated on. In x := x + 1; variable x is incremented and the language used requires (or allowed) that the identifier x occur twice. In C this operation would only require one occurrence of x when expressed using the common idiom x++;. The number of occurrences of a variable needed to perform an operation on it, in a given languages, will influence the shape of the graph based on an occurrence count.
One graph does not provide conclusive evidence, but other measurements also produce straightish lines. The fact that the first few entries do not form part of an upward trend is not a problem, these variables are only accessed a few times and so might be expected to have a large deviation.
More sophisticated measurements are needed to count operations on a variable, as opposed to occurrences of it. For instance, few languages (any?) contain an indirection assignment operator (e.g., writing x ->= next; instead of x = x -> next;) and this would need to be adjusted for in a more sophisticated counting algorithm. It will also be necessary to separate out the effects of global variables, function calls and the multiple components involved in a member selection, etc.
Update: A more detailed analysis is now available.
Readability, an experimental view
Readability is an attribute that source code is often claimed to have, but what is it? While people are happy to use the term they have great difficulty in defining exactly what it is (I will eventually get around discussing my own own views in post). Ray Buse took a very simply approach to answering this question, he asked lots of people (to be exact 120 students) to rate short snippets of code and analysed the results. Like all good researchers he made his data available to others. This posting discusses my thoughts on the expected results and some analysis of the results.
The subjects were first, second, third year undergraduates and postgraduates. I would not expect first year students to know anything and for their results to be essentially random. Over the years, as they gain more experience, I would expect individual views on what constitutes readability to stabilize. The input from friends, teachers, books and web pages might be expected to create some degree of agreement between different students’ view of what constitutes readability. I’m not saying that this common view is correct or bears any relationship to views held by other groups of people, only that there might be some degree of convergence within a group of people studying together.
Readability is not something that students can be expected to have explicitly studied (I’m assuming that it plays an insignificant part in any course marks), so their knowledge of it is implicit. Some students will enjoy writing code and spends lots of time doing it while (many) others will not.
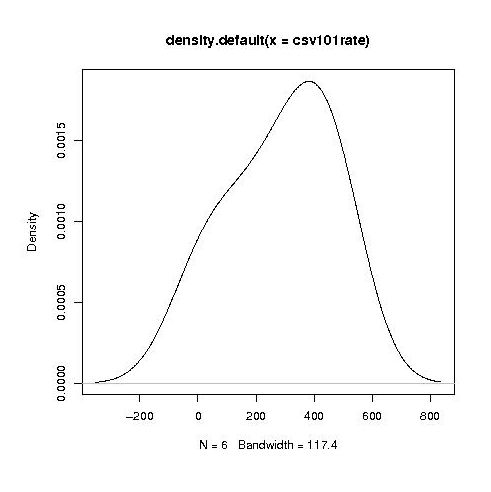
Separating out the data by year the results for first year students look like a normal distribution with a slight bulge on one side (created using plot(density(1_to_5_rating_data)) in R).
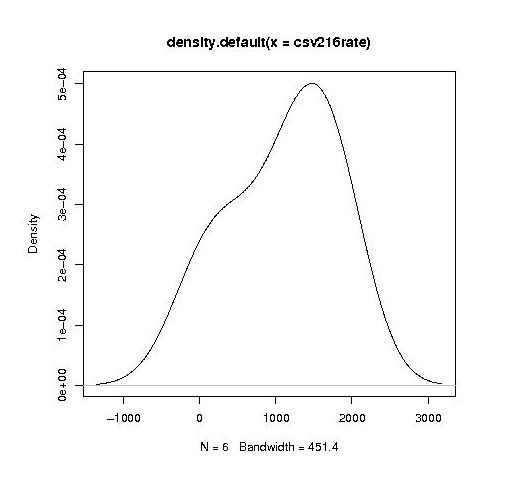
year by year this bulge turns (second year):
into a hillock (final year):
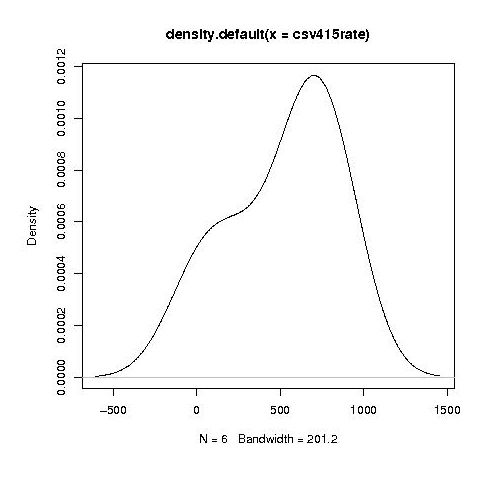
It is tempting to interpret these results as the majority of students assigning an essentially random rating, with a slight positive bias, for the readability of each snippet, with a growing number of more experienced students assigning less than average rating to some snippets.
Do the student’s view converge to a common opinion on readability? The answers appears to be No. An analysis of the final year data using Fleiss’s Kappa shows that there is virtually no agreement between students ratings. In fact every Interrater Reliability and Agreement function I tried said the same thing. Some cluster analysis might enable me to locate students holding similar views.
In an email exchange with Ray Buse I learned that the postgraduate students had a relatively wide range of computing expertise, so I did not analyse their results.
I wish I had thought of this approach to measuring readability. Its simplicity makes it amenable for use in a wide range of experimental situations. The one change I would make is that I would explicitly create the snippets to have certain properties, rather than randomly extracting them from existing source.
The sound of code
Speech, it is claimed, is the ability that separates humans from all other animals, yet working with code is almost exclusively based on sight. There are instances of ‘accidental’ uses of sound, e.g., listening to disc activity to monitor a programs process or in days of old the chatter of other mechanical parts.
Various projects have attempted to intentionally make use of sound to provide an interface to the software development process, including:
- People like to talk about what they do and perhaps this could be used to overcome developers dislike of writing comments. Unfortunately automated processing of natural language (assuming the speech to text problem is solved) has not reached the stage where it is possible to automatically detect when the topic of conversation has changed or to figure out what piece of code is being discussed. Perhaps the reason why developers find it so hard to write good comments is because it is a skill that requires training and effort, not random thoughts that happen to come to mind.
- Rather than relying on the side-effects of mechanical vibration it has been proposed that programs intentionally produce audio output that aids developers monitor their progress. Your authors experience with interpreting mechanically generated sound is that it requires a great deal of understanding of a program’s behavior and that it is a very low bandwidth information channel.
- Writing code by talking (i.e., voice input of source code) initially sounds attractive. As a form of input speech is faster than typing, however computer processing of speech is still painfully slow. Another problem that needs to be handled is the large number of different ways in which the same thing can and is spoken, e.g., numeric values. As a method of output reading is 70% faster than listening.
Unless developers have to spend lots of time commuting in person, rather than telecommuting, I don’ see a future for speech input of code. Audio program execution monitoring probably has market is specialist niches, no more.
I do see a future for spoken mathematics, which is something that people who are not a mathematicians might want to do. The necessary formating commands are sufficiently obtuse that they require too much effort from the casual user.
Incorrect spelling
While even a mediocre identifier name can provide useful information to a reader of the source a poorly chosen name can create confusion and require extra effort to remember. An author’s good intent can be spoiled by spelling mistakes, which are likely to be common if the developer is not a native speaker of the English (or whatever natural language is applicable).
Identifiers have characteristics which make them difficult targets for traditional spell checking algorithms; they often contain specialized words, dictionary words may be abbreviated in some way (making phonetic techniques impossible) and there is unlikely to be any reliable surrounding context.
Identifiers share many of the characteristics of search engine queries, they contain a small number of words that don’t fit together into a syntactically correct sentence and any surrounding context (e.g., previous queries or other identifiers) cannot be trusted. However, search engines have their logs of millions of previous search queries to fall back on, enabling them to suggest (often remarkably accurate) alternatives to non-dictionary words, specialist domains and recently coined terms. Because developers don’t receive any feedback on their spelling mistakes revision control systems are unlikely to contain any relevant information that can be mined.
One solution is for source code editors to require authors to fully specify all of the words used in an identifier when it is declared; spell checking and suitable abbreviation rules being applied at this point. Subsequent uses of the identifier can be input using the abbreviated form. This approach could considerably improve consistency of identifier usage across a project’s source code (it could also flag attempts to use both orderings of a word pair, e.g., number count and count number). The word abbreviation mapping could be stored (perhaps in a comment at the end of the source) for use by other tools and personalized developer preferences stored in a local configuration file. It is time for source code editors to start taking a more active role in helping developers write readable code.
Semantic pattern matching (Coccinelle)
I have just discovered Coccinelle a tool that claims to fill a remarkable narrow niche (providing semantic patch functionality; I have no idea how the name is pronounced) but appears to have a lot of other uses. The functionality required of a semantic patch is the ability to write source code patterns and a set of transformation rules that convert the input source into the desired output. What is so interesting about Coccinelle is its pattern matching ability and the ability to output what appears to be unpreprocessed source (it has to be told the usual compile time stuff about include directory paths and macros defined via the command line; it would be unfair of me to complain that it needs to build a symbol table).
Creating a pattern requires defining identifiers to have various properties (eg, an expression in the following example) followed by various snippets of code that specify the pattern to match (in the following <… …> represents a bracketed (in the C compound statement sense) don’t care sequence of code and the lines starting with +/- have the usual patch meaning (ie, add/delete line)). The tool builds an abstract syntax tree so urb is treated as a complete expression that needs to be mapped over to the added line).
@@ expression lock, flags; expression urb; @@ spin_lock_irqsave(lock, flags); <... - usb_submit_urb(urb) + usb_submit_urb(urb, GFP_ATOMIC) ...> spin_unlock_irqrestore(lock, flags); |
Coccinelle comes with a bunch of predefined equivalence relations (they are called isomophisms) so that constructs such as if (x), if (x != NULL) and if (NULL != x) are known to be equivalent, which reduces the combinatorial explosion that often occurs when writing patterns that can handle real-world code.
It is written in OCaml (I guess there had to be some fly in the ointment) and so presumably borrows a lot from CIL, perhaps in this case a version number of 0.1.3 is not as bad as it might sound.
My main interest is in counting occurrences of various kinds of patterns in source code. A short-term hack is to map the sought-for pattern to some unique character sequence and pipe the output through grep and wc. There does not seem to be any option to output a count of the matched patterns … yet 🙂
What I changed my mind about in 2008
A few years ago The Edge asked people to write about what important issue(s) they had recently changed their mind about. This is an interesting question and something people ought to ask themselves every now and again. So what did I change my mind about in 2008?
1. Formal verification of nontrivial C programs is a very long way off. A whole host of interesting projects (e.g., Caduceus, Comcert and Frame-C) going on in France has finally convinced me that things are a lot closer than I once thought. This does not mean that I think developers/managers will be willing to use them, only that they exist.
2. Automatically extracting useful information from source code identifier names is still a long way off. Yes, I am a great believer in the significance of information contained in identifier names. Perhaps because I have studied the issues in detail I know too much about the problems and have been put off attacking them. A number of researchers (e.g., Emily Hill, David Shepherd, Adrian Marcus, Lin Tan and a previously blogged about project) have simply gone ahead and managed to extract (with varying amount of human intervention) surprising amounts of useful from identifier names.
3. Theoretical analysis of non-trivial floating-point oriented programs is still a long way off. Daumas and Lester used the Doobs-Kolmogorov Inequality (I had to look it up) to deduce the probability that the rounding error in some number of floating-point operations, within a program, will exceed some bound. They also integrated the ideas into NASA’s PVS system.
You can probably spot the pattern here, I thought something would not happen for years and somebody went off and did it (or at least made an impressive first step along the road). Perhaps 2008 was not a good year for really major changes of mind, or perhaps an earlier in the year change of mind has so ingrained itself in my mind that I can no longer recall thinking otherwise.
The 30% of source that is ignored
Approximately 30% of source code is not checked for correct syntax (developers can make up any rules they like for its internal syntax), semantic accuracy or consistency; people are content to shrug their shoulders at this this state of affairs and are generally willing to let it pass. I am of course talking about comments; the 30% figure comes from my own measurements with other published measurements falling within a similar ballpark.
Part of the problem is that comments often contain lots of natural language (i.e., human not computer language) and this is known to be very difficult to parse and is thought to be unusable without all sorts of semantic knowledge that is not currently available in machine processable form.
People are good at spotting patterns in ambiguous human communication and deducing possible meanings from it, and this has helped to keep comment usage alive, along with the fact that the information they provide is not usually available elsewhere and comments are right there in front of the person reading the code and of course management loves them as a measurable attribute that is cheap to do and not easily checkable (and what difference does it make if they don’t stay in sync with the code).
One study that did attempt to parse English sentences in comments found that 75% of sentence-style comments were in the past tense, with 55% being some kind of operational description (e.g., “This routine reads the data.”) and 44% having the style of a definition (e.g., “General matrix”).
There is a growing collection of tools for processing natural language (well at least for English). However, given the traditionally poor punctuation used in comments, the use of variable names and very domain specific terminology, full blown English parsing is likely to be very difficult. Some recent research has found that useful information can be extracted using something only a little more linguistically sophisticated than word sense disambiguation.
The designers of the iComment system sensibly limited the analysis domain (to memory/file lock related activities), simplified the parsing requirements (to looking for limited forms of requirements wording) and kept developers in the loop for some of the processing (e.g., listing lock related function names). The aim was to find inconsistencies between the requirements expressed in comments and what the code actually did. Within the Linux/Mozilla/Wine/Apache sources they found 33 faults in the code and 27 in the comments, claiming a 38.8% false positive rate.
If these impressive figures can be replicated for other kinds of coding constructs then comment contents will start to leave the dark ages.
Predictions for 2009
If the shape of code does change over time, it changes very slowly. Styles become more or less popular, but again the time-scale is generally longer than a year. Anyway, here are my predictions for goings on the in the community that shapes code.
1) Functional programming will continue to entrance the young whose idealism will continue to be dashed when they have to deal with the real world. Ok, I started with something obvious that will still be true in 20 years and I promise not to to to keep repeating myself on this one every year.
2) The LLVM project will die. I am surprised that it has lasted this long, but it is probably costing Apple so little that it is not on management’s radar. Who needs another C compiler; perhaps 10 years ago they could have given the moribund gcc project a run for its money, but an infusion of keen people and a complete reworking of its internals has kept gcc as the leading contender to be the only C compiler developers use in 10 years time.
3) Static analysis will go mainstream. The driving force will not be developers loosing their aversion to being told of their mistakes, but because the world’s economic predicament will force them to deliver better performance in less time, ie they will be forced to use tools to help them find coding faults. The fact that various groups are starting to add hooks to the mainstream compilers (e.g., Microsoft’s Phoenix, gcc’s Dehydra), ensuring compatibility with an existing code base and making it easier for developers use, also helps. The gcc people may yet shoot themselves in the foot. Of course people will continue to develop new stand-alone tools and extract money from government to do something that sounds useful.
4) Natural language programming will finally gain a foothold. One of the big unnoticed announcements of the year was the Attempto project releasing the source code of their controlled English system.
5) The rate of gcc’s progress to world domination will accelerate. There are still quite a few market niches where gcc is a minority player (eg, embedded systems) and various compilers need to disappear for it to gain market share. Compiler writing has never been a very profitable business and compiler companies usually go bust or are taken over by hardware vendors looking for customer lock-in. The current economic situation means that compiler companies are both more likely to go bust and to not be brought, ie, their compilers will (commercially) disappear.
6) The number of people involved in writing software will continue to decline in the West and increase in the East. These days there is not a lot of difference in cost between east/west, it is the quality of developers (or rather there are more of a reasonable standard available). The declining standards in science/engineering education is the driving factor, the economic situation is just creating extra exposure.
Recommendations for teachers of programming
The software developers I deal with usually have at least 3 or more years professional experience in industry (I have not taught a beginners programming class in over 25 years) and these recommendations are based on what I tell these people. I like to think that they are applicable to teaching those with a lot less experience.
First. Application domain expertise generally has greater value than programming expertise. That is, an investment of time in learning the application domain will yield a greater return on investment that learning more programming techniques.
Implications:
Second. Computer time is cheap, people time is expensive.
Implications:
Third. Most software is written to solve an immediate problem, used a few times, and then forgotten about (I know of software projects costing in the millions where the code was never used; my own contribution to never used code is somewhat smaller, but still much larger than I would have liked). The point is that writing software involves a cost/benefit trade-off, how much should I invest in making code maintainable given the risk that the benefits from this investment may not be recouped.
Implications:
Fourth. Don’t fool yourself that you are teaching programming; you probably just give a lecture or two and expect students to pick up the details from one of the assigned course books.
Implications:
Fifth. Coding style does exist and can have an effect on the cost of writing and maintaining code as well as how well a compiler can optimize it. These costs and benefits vary with the context in which the code was created and used. A good programmer will adopt a coding style appropriate to the context, just like an actor plays a role with the appropriate characterization (eg, comedy, thriller, suspense). It takes more experience than most undergraduate have to be able to properly discern what style is being used, let alone be capable of changing their own style.
Implications:
Unexpected experimental effects
The only way to find out the factors that effect developers’ source code performance is to carry out experiments where they are the subjects. Developer performance on even simple programming tasks can be effected by a large number of different factors. People are always surprised at the very small number of basic operations I ask developers to perform in the experiments I run. My reply is that only by minimizing the number of factors that might effect performance can I have any degree of certainty that the results for the factors I am interested in are reliable.
Even with what appear to be trivial tasks I am constantly surprised by the factors that need to be controlled. A good example is one of the first experiments I ever ran. I thought it would be a good idea to replicate, using a software development context, a widely studied and reliably replicated human psychological effect; when asked to learn and later recall/recognize a list of words people make mistakes. Psychologists study this problem because it provides a window into the operation structure of the human memory subsystem over short periods of time (of the order of at most tens of seconds). I wanted to find out what sort of mistakes developers would make when asked to remember information about a sequence of simple assignment statements (e.g.,
qbt = 6;).I carefully read the appropriate experimental papers and had created lists of variables that controlled for every significant factor (e.g., number of syllables, frequency of occurrence of the words in current English usage {performance is better for very common words}) and the list of assignment statements was sufficiently long that it would just overload the capacity of short term memory (about 2 seconds worth of sound).
The results contained none of the expected performance effects, so I ran the experiment again looking for different effects; nothing. A chance comment by one of the subjects after taking part in the experiment offered one reason why the expected performance effects had not been seen. By their nature developers are problem solvers and I had set them a problem that asked them to remember information involving a list of assignment statements that appeared to be beyond their short term memory capacity. Problem solvers naturally look for patterns and common cases and the variables in each of my carefully created list of assignment statements could all be distinguished by their first letter. Subjects did not need to remember the complete variable name, they just needed to remember the first letter (something I had not controlled for). Asking around I found that several other subjects had spotted and used the same strategy. My simple experiment was not simple enough!
I was recently reading about an experiment that investigated the factors that motivate developers to comment code. Subjects were given some code and asked to add additional functionality to it. Some subjects were given code containing lots of comments while others were given code containing few comments. The hypothesis was that developers were more likely to create comments in code that already contained lots of comments, and the results seemed to bear this out. However, closer examination of the answers showed that most subjects had cut and pasted chunks (i.e., code and comments) from the code they were given. So code the percentage of code in the problem answered mimicked that in the original code (in some cases subjects had complicated the situation by refactoring the code).