Archive
Multiple estimates for the same project
The first question I ask, whenever somebody tells me that a project was delivered on schedule (or within budget), is which schedule (or budget)?
New schedules are produced for projects that are behind schedule, and costs get re-estimated.
What patterns of behavior might be expected to appear in a project’s reschedulings?
It is to be expected that as a project progresses, subsequent schedules become successively more accurate (in the sense of having a completion date and cost that is closer to the final values). The term cone of uncertainty is sometimes applied as a visual metaphor in project management, with the schedule becoming less uncertain as the project progresses.
The only publicly available software project rescheduling data, from Landmark Graphics, is for completed projects, i.e., cancelled projects are not included (121 completed projects and 882 estimates).
The traditional project management slide has some accuracy metric improving as work on a project approaches completion. The plot below shows the percentage of a project completed when each estimate is made, against the ratio  ; the y-axis uses a log scale so that under/over estimates appear symmetrical (code+data):
; the y-axis uses a log scale so that under/over estimates appear symmetrical (code+data):
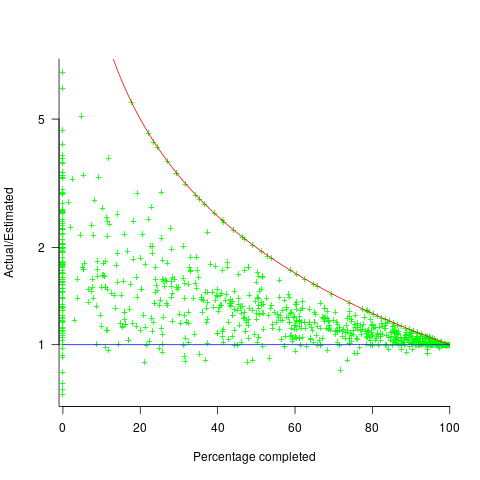
The closer a point to the blue line, the more accurate the estimate. The red line shows maximum underestimation, i.e., estimating that the project is complete when there is still more work to be done. A new estimate must be greater than (or equal) to the work already done, i.e.,  , and
, and  .
.
Rearranging, we get:  (plotted in red). The top of the ‘cone’ does not represent managements’ increasing certainty, with project progress, it represents the mathematical upper bound on the possible inaccuracy of an estimate.
(plotted in red). The top of the ‘cone’ does not represent managements’ increasing certainty, with project progress, it represents the mathematical upper bound on the possible inaccuracy of an estimate.
In theory there is no limit on overestimating (i.e., points appearing below the blue line), but in practice management are under pressure to deliver as early as possible and to minimise costs. If management believe they have overestimated, they have an incentive to hang onto the time/money allocated (the future is uncertain).
Why does management invest time creating a new schedule?
If information about schedule slippage leaks out, project management looks bad, which creates an incentive to delay rescheduling for as long as possible (i.e., let’s pretend everything will turn out as planned). The Landmark Graphics data comes from an environment where management made weekly reports and estimates were updated whenever the core teams reached consensus (project average was eight times).
The longer a project is being worked on, the greater the opportunity for more unknowns to be discovered and the schedule to slip, i.e., longer projects are expected to acquire more re-estimates. The plot below shows the number of estimates made, for each project, against the initial estimated duration (red/green) and the actual duration (blue/purple); lines are loess fits (code+data):
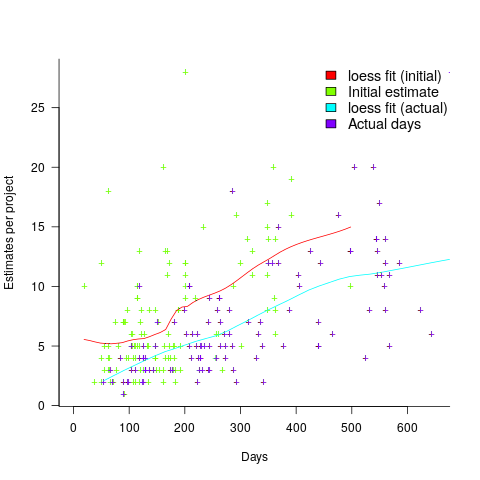
What might be learned from any patterns appearing in this data?
When presented with data on the sequence of project estimates, my questions revolve around the reasons for spending time creating a new estimate, and the amount of time spent on the estimate.
A lot of time may have been invested in the original estimate, but how much time is invested in subsequent estimates? Are later estimates simply calculated as a percentage increase, a politically acceptable value (to the stakeholder funding for the project), or do they take into account what has been learned so far?
The information needed to answer these answers is not present in the data provided.
However, this evidence of the consistent provision of multiple project estimates drives another nail in to the coffin of estimation research based on project totals (e.g., if data on project estimates is provided, one estimate per project, were all estimates made during the same phase of the project?)
The CESAW dataset: a brief introduction
I have found that the secret for discovering data treasure troves is persistently following any leads that appear. For instance, if a researcher publishes a data driven paper, then check all their other papers. The paper: Composing Effective Software Security Assurance Workflows contains a lot of graphs and tables, but no links to data, however, one of the authors (William R. Nichols) published The Cost and Benefits of Static Analysis During Development which links to an amazing treasure trove of project data.
My first encounter with this data was this time last year, as I was focusing on completing my Evidence-based software engineering book. Apart from a few brief exchanges with Bill Nichols the technical lead member of the team who obtained and originally analysed the data, I did not have time for any detailed analysis. Bill was also busy, and we agreed to wait until the end of the year. Bill’s and my paper: The CESAW dataset: a conversation is now out, and focuses on an analysis of the 61,817 task and 203,621 time facts recorded for the 45 projects in the CESAW dataset.
Our paper is really an introduction to the CESAW dataset; I’m sure there is a lot more to be discovered. Some of the interesting characteristics of the CESAW dataset include:
- it is the largest publicly available project dataset currently available, with six times as many tasks as the next largest, the SiP dataset. The CESAW dataset involves the kind of data that is usually encountered, i.e., one off project data. The SiP dataset involves the long term evolution of one company’s 20 projects over 10-years,
- it includes a lot of information I have not seen elsewhere, such as: task interruption time and task stop/start {date/time}s (e.g., waiting on some dependency to become available)
- four of the largest projects involve safety critical software, for a total of 28,899 tasks (this probably more than two orders of magnitude more than what currently exists). Given all the claims made about the development about safety critical software being different from other kinds of development, here is a resource for checking some of the claims,
- the tasks to be done, to implement a project, are organized using a work-breakdown structure. WBS is not software specific, and the US Department of Defense require it to be used across all projects; see MIL-STD-881. I will probably annoy those in software management by suggesting the one line definition of WBS as: Agile+structure (WBS supports iteration). This was my first time analyzing WBS project data, and never having used it myself, I was not really sure how to approach the analysis. Hopefully somebody familiar with WBS will extract useful patterns from the data,
- while software inspections are frequently talked about, public data involving them is rarely available. The WBS process has inspections coming out of its ears, and for some projects inspections of one kind or another represent the majority of tasks,
- data on the kinds of tasks that are rarely seen in public data, e.g., testing, documentation, and design,
- the 1,324 defect-facts include information on: the phase where the mistake was made, the phase where it was discovered, and the time taken to fix.
As you can see, there is lots of interesting project data, and I look forward to reading about what people do with it.
Once you have downloaded the data, there are two other sources of information about its structure and contents: the code+data used to produce the plots in the paper (plus my fishing expedition code), and a CESAW channel on the Evidence-based software engineering Slack channel (no guarantees about response time).
Software engineering research problems having worthwhile benefits
Which software engineering research problems are likely to yield good-enough solutions that provide worthwhile benefits to professional software developers?
I can think of two (hopefully there are more):
- what is the lifecycle of software? For instance, the expected time-span of the active use of its various components, and the evolution of its dependency ecosystem,
- a model of the main processes involved in a software development project.
Solving problems requires data, and I think it is practical to collect the data needed to solve these two problems; here is some: application lifetime data, and detailed project data (a lot more is needed).
Once a good-enough solution is available, its practical application needs to provide a worthwhile benefit to the customer (when I was in the optimizing compiler business, I found that many customers were not interested in more compact code unless the executable was at least a 10% smaller; this was the era of computer memory often measured in kilobytes).
Investment decisions require information about what is likely to happen in the future, and an understanding of common software lifecycles is needed. The fact that most source code has a brief existence (a few years) and is rarely modified by somebody other than the original author, has obvious implications for investment decisions intended to reduce future maintenance costs.
Running a software development project requires an understanding of the processes involved. This knowledge is currently acquired by working on projects managed by people who have successfully done it before. A good-enough model is not going to replace the need for previous experience, some amount of experience is always going to be needed, but it will provide an effective way of understanding what is going on. There are probably lots of different good-enough ways of running a project, and I’m not expecting there to be a one-true-way of optimally running a project.
Perhaps the defining characteristic of the solution to both of these problems is lots of replication data.
Applications are developed in many ecosystems, and there is likely to be variations between the lifecycles that occur in different ecosystems. Researchers tend to focus on Github because it is easily accessible, which is no good when replications from many ecosystems are needed (an analysis of Github source lifetime has been done).
Projects come in various shapes and sizes, and a good-enough model needs to handle all the combinations that regularly occur. Project level data is not really present on Github, so researchers need to get out from behind their computers and visit real companies.
Given the payback time-frame for software engineering research, there are problems which are not cost-effective to attempt to answer. Suggestions for other software engineering problems likely to be worthwhile trying to solve welcome.
Learning useful stuff from the Projects chapter of my book
What useful, practical things might professional software developers learn from the Projects chapter in my evidence-based software engineering book?
This week I checked the projects chapter; what useful things did I learn (combined with everything I learned during all the other weeks spent working on this chapter)?
There turned out to be around three to four times more data publicly available than I had first thought. This is good, but there is a trap for the unweary. For many topics there is one data set, and that one data set may not be representative. What is needed is a selection of data from various sources, all relating to a given topic.
Some data is better than no data, provided small data sets are treated with caution.
Estimation is a popular research topic: how long will a project take and how much will it cost.
After reading all the papers I learned that existing estimation models are even more unreliable than I had thought, and what is more, there are plenty of published benchmarks showing how unreliable the models really are (these papers never seem to get cited).
Models that include lines of code in the estimation process (i.e., the majority of models) need a good estimate of the likely number of lines in the final software system. One issue that nobody had considered was the impact of developer variability on the number of lines written to implement the same functionality, which turns out to be large. Oops.
Machine learning has infested effort estimation research. What the machine learning models actually do is estimate adjustment, i.e., they do not create their own estimate but adjust one passed in as input to the model. Most estimation data sets are tiny, and only contain a few different variables; unless the estimate is included in the training phase, the generated model produces laughable results. Oops.
The good news is that there appear to be lots of recurring patterns in the project data. This is good news because recurring patterns are something to be explained by a theory of software project development (apparent randomness is bad news, from the perspective of coming up with a model of what is going on). I think we are still a long way from having workable theories, but seeing patterns is a good sign that one or more theories will be possible.
I think that the main takeaway from this chapter is that software often has a short lifetime. People in industry probably have a vague feeling that this is true, from experience with short-lived projects. It is not cost effective to approach commercial software development from the perspective that the code will live a long time; some code does live a long time, but most dies young. I see the implications of this reality being a major source of contention with those in academia who have spent too long babbling away in front of teenagers (teaching the creation of idealized software that lives on forever), and little or no time building software systems.
A lot of software is written by teams of people, however, there is not a lot of data available on teams (software or otherwise). Given the difficulty of hiring developers, companies have to make do with what they have, so a theory of software teams might not be that useful in practice.
Readers might have a completely different learning experience from reading the projects chapter. What useful things did you learn from the projects chapter?
Student projects for 2019/2020
It’s that time of year when students are looking for an interesting idea for a project (it might be a bit late for this year’s students, but I have been mulling over these ideas for a while, and might forget them by next year). A few years ago I listed some suggestions for student projects, as far as I know none got used, so let’s try again…
Checking the correctness of the Python compilers/interpreters. Lots of work has been done checking C compilers (e.g., Csmith), but I cannot find any serious work that has done the same for Python. There are multiple Python implementations, so it would be possible to do differential testing, another possibility is to fuzz test one or more compiler/interpreter and see how many crashes occur (the likely number of remaining fault producing crashes can be estimated from this data).
Talking to the Python people at the Open Source hackathon yesterday, testing of the compiler/interpreter was something they did not spend much time thinking about (yes, they run regression tests, but that seemed to be it).
Finding faults in published papers. There are tools that scan source code for use of suspect constructs, and there are various ways in which the contents of a published paper could be checked.
Possible checks include (apart from grammar checking):
- incorrect or inaccurate numeric literals.
Checking whether the suspect formula is used is another possibility, provided the formula involved contains known constants.
- inconsistent statistics reported (e.g., “8 subjects aged between 18-25, average age 21.3″ may be correct because 21.3*8 == 170.4, ages must add to a whole number and the values 169, 170 and 171 would not produce this average), and various tools are available (e.g., GRIMMER).
Citation errors are relatively common, but hard to check automatically without a good database (I have found that a failure of a Google search to return any results is a very good indicator that the reference does not exist).
There are lots of tools available for taking pdf files apart; I use pdfgrep a lot
Number extraction. Numbers are some of the most easily checked quantities, and anybody interested in fact checking needs a quick way of extracting numeric values from a document. Sometimes numeric values appear as numeric words, and dates can appear as a mixture of words and numbers. Extracting numeric values, and their possible types (e.g., date, time, miles, kilograms, lines of code). Something way more sophisticated than pattern matching on sequences of digit characters is needed.
spaCy is my tool of choice for this sort of text processing task.
Projects chapter of ‘evidence-based software engineering’ reworked
The Projects chapter of my evidence-based software engineering book has been reworked; draft pdf available here.
A lot of developers spend their time working on projects, and there ought to be loads of data available. But, as we all know, few companies measure anything, and fewer hang on to the data.
Every now and again I actively contact companies asking data, but work on the book prevents me spending more time doing this. Data is out there, it’s a matter of asking the right people.
There is enough evidence in this chapter to slice-and-dice much of the nonsense that passes for software project wisdom. The problem is, there is no evidence to suggest what might be useful and effective theories of software development. My experience is that there is no point in debunking folktales unless there is something available to replace them. Nature abhors a vacuum; a debunked theory has to be replaced by something else, otherwise people continue with their existing beliefs.
There is still some polishing to be done, and a few promises of data need to be chased-up.
As always, if you know of any interesting software engineering data, please tell me.
Next, the Reliability chapter.
Publishing information on project progress: will it impact delivery?
Numbers for delivery date and cost estimates, for a software project, depend on who you ask (the same is probably true for other kinds of projects). The people actually doing the work are likely to have the most accurate information, but their estimates can still be wildly optimistic. The managers of the people doing the work have to plan (i.e., make worst/best case estimates) and deal with people outside the team (i.e., sell the project to those paying for it); planning requires knowledge of where things are and where they need to be, while selling requires being flexible with numbers.
A few weeks ago I was at a hackathon organized by the people behind the Project Data and Analytics meetup. The organizers (Martin Paver & co.) had obtained some very interesting project related data sets. I worked on the Australian ICT dashboard data.
The Australian ICT dashboard data was courtesy of the Queensland state government, which has a publicly available dashboard listing digital project expenditure; the Victorian state government also has a dashboard listing ICT expenditure. James Smith has been collecting this data on a monthly basis.
What information might meaningfully be extracted from monthly estimates of project delivery dates and costs?
If you were running one of these projects, and had to provide monthly figures, what strategy would you use to select the numbers? Obviously keep quiet about internal changes for as long as possible (today’s reduction can be used to offset a later increase, or vice versa). If the client requests changes which impact date/cost, then obviously update the numbers immediately; the answer to the question about why the numbers changed is that, “we are responding to client requests” (i.e., we would otherwise still be on track to meet the original end-points).
What is the intended purpose of publishing this information? Is it simply a case of the public getting fed up with overruns, with publishing monthly numbers is seen as a solution?
What impact could monthly publication have? Will clients think twice before requesting an enhancement, fearing public push back? Will companies doing the work make more reliable estimates, or work harder?
Project delivery dates/costs change because new functionality/work-to-do is discovered, because the appropriate staff could not be hired and other assorted unknown knowns and unknowns.
Who is looking at this data (apart from half a dozen people at a hackathon on the other side of the world)?
Data on specific projects can only be interpreted in the context of that project. There is some interesting research to be done on the impact of public availability on client and vendor reporting behavior.
Will publication have an impact on performance? One way to get some idea is to run an A/B experiment. Some projects have their data made public, others don’t. Wait a few years, and compare project performance for the two publication regimes.
Huge effort data-set for project phases
I am becoming a regular reader of software engineering articles written in Chinese and Japanese; or to be more exact, I am starting to regularly page through pdfs looking at figures and tables of numbers, every now and again cutting-and-pasting sequences of logograms into Google translate.
A few weeks ago I saw the figure below, and almost fell off my chair; it’s from a paper by Yong Wang and Jing Zhang. These plots are based on data that is roughly an order of magnitude larger than the combined total of all the public data currently available on effort break-down by project phase.
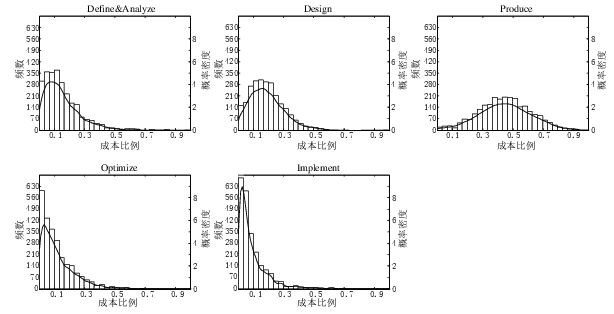
Projects are often broken down into phases, e.g., requirements, design, coding (listed as ‘produce’ above), testing (listed as ‘optimize’), deployment (listed as ‘implement’), and managers are interested in knowing what percentage of a project’s budget is typically spent on each phase.
Projects that are safety-critical tend to have high percentage spends in the requirements and testing phase, while in fast moving markets resources tend to be invested more heavily in coding and deployment.
Research papers on project effort usually use data from earlier papers. The small number of papers that provide their own data might list effort break-down for half-a-dozen projects, a few require readers to take their shoes and socks off to count, a small number go higher (one from the Rome period), but none get into three-digits. I have maybe a few hundred such project phase effort numbers.
I emailed the first author and around a week later had 2,570 project phase effort (man-hours) percentages (his co-author was on marriage leave, which sounded a lot more important than my data request); see plot below (code+data).
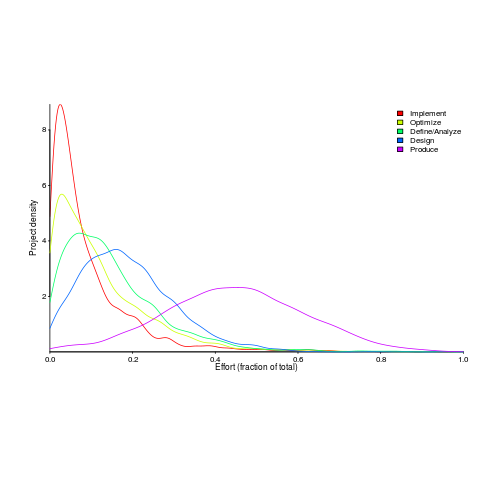
I have tried to fit some of the obvious candidate distributions to each phase, but none of the fits were consistently good across the phases (see code for details).
This project phase data is from small projects, i.e., one person over a few months to ten’ish people over more than a year (a guess based on the total effort seen in other plots in the paper).
A typical problem with samples in software engineering is their small size (apart from bugs data, lots of that is available, at least in uncleaned form). Having a sample of this size means that it should be possible to have a reasonable level of confidence in the results of statistical tests. Now we just need to figure out some interesting questions to ask.
Projects chapter added to “Empirical software engineering using R”
The Projects chapter of my Empirical software engineering book has been added to the draft pdf (download here).
This material turned out to be harder to bring together than I had expected.
Building software projects is a bit like making sausages in that you don’t want to know the details, or in this case those involved are not overly keen to reveal the data.
There are lots of papers on requirements, but remarkably little data (Soo Ling Lim’s work being the main exception).
There are lots of papers on effort prediction, but they tend to rehash the same data and the quality of research is poor (i.e., tweaking equations to get a better fit; no explanation of why the tweaks might have any connection to reality). I had not realised that Norden did all the heavy lifting on what is sometimes called the Putnam model; Putnam was essentially an evangelist. The Parr curve is a better model (sorry, no pdf), but lacked an evangelist.
Accurate estimates are unrealistic: lots of variation between different people and development groups, the client keeps changing the requirements and developer turnover is high.
I did turn up a few interesting data-sets and Rome came to the rescue in places.
I have been promised more data and am optimistic some will arrive.
As always, if you know of any interesting software engineering data, please tell me.
I’m looking to rerun the workshop on analyzing software engineering data. If anybody has a venue in central London, that holds 30 or so people+projector, and is willing to make it available at no charge for a series of free workshops over several Saturdays, please get in touch.
Reliability chapter next.
Failed projects + the Cloud = Software reuse
Code reuse is one of those things that sounds like a winning idea to those outside of software development; those who write software for a living are happy to reuse other peoples’ code but don’t want the hassle involved with others reusing their own code. From the management point of view, where is the benefit in having your developers help others get their product out the door when they should be working towards getting your product out the door?
Lots of projects get canceled after significant chunks of software have been produced, some of it working. It would be great to get some return on this investment, but the likely income from selling software components is rarely large enough to make it worthwhile investing the necessary resources. The attractions of the next project are soon appear more enticing than hanging around baby-sitting software from a cancelled project.
Cloud services, e.g., AWS and Azure to name two, look like they will have a big impact on code reuse. The components of a failed project, i.e., those bits that work tolerably well, can be packaged up as a service and sold/licensed to other companies using the same cloud provider. Companies are already offering a wide variety of third-party cloud services, presumably the new software got written because no equivalent services was currently available on the provider’s cloud; well perhaps others are looking for just this service.
The upfront cost of sales is minimal, the services your failed re-purposed software provides get listed in various service directories. The software can just sit there waiting for customers to come along, or you could put some effort into drumming up customers. If sales pick up, it may become worthwhile offering support and even making enhancements.
What about the software built for non-failed projects? Software is a force multiplier and anybody working on a non-failed project wants to use this multiplier for their own benefit, not spend time making it available for others (I’m not talking about creating third-party APIs).
Recent Comments