Archive
Agile and Waterfall as community norms
While rapidly evolving computer hardware has been a topic of frequent public discussion since the first electronic computer, it has taken over 40 years for the issue of rapidly evolving customer requirements to become a frequent topic of public discussion (thanks to the Internet).
The following quote is from the Opening Address, by Andrew Booth, of the 1959 Working Conference on Automatic Programming of Digital Computers (published as the first “Annual Review in Automatic Programming”):
'Users do not know what they wish to do.' This is a profound truth. Anyone who has had the running of a computing machine, and, especially, the running of such a machine when machines were rare and computing time was of extreme value, will know, with exasperation, of the user who presents a likely problem and who, after a considerable time both of machine and of programmer, is presented with an answer. He then either has lost interest in the problem altogether, or alternatively has decided that he wants something else. |
Why did the issue of evolving customer requirements lurk in the shadows for so long?
Some of the reasons include:
- established production techniques were applied to the process of building software systems. What is now known in software circles as the Waterfall model was/is an established technique. The figure below is from the 1956 paper Production of Large Computer Programs by Herbert Benington (Winston Royce’s 1970 paper has become known as the paper that introduced Waterfall, but the contents actually propose adding iterations to what Royce treats as an established process):
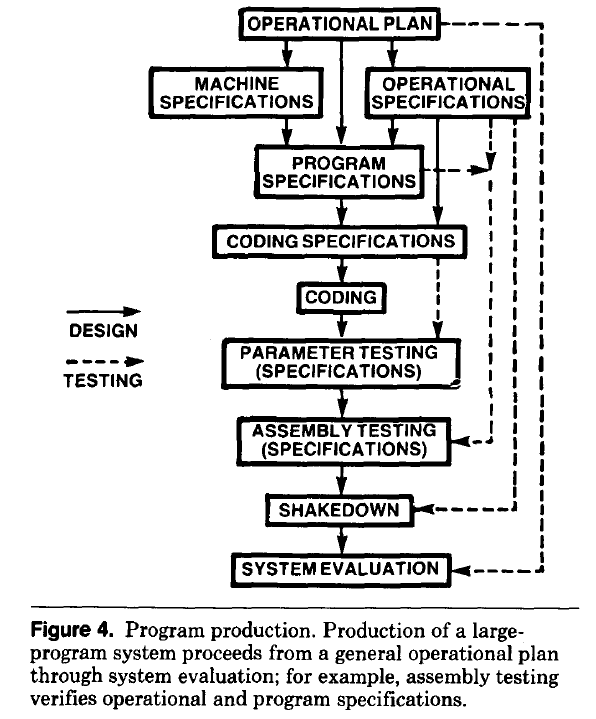
- management do not appreciate how quickly requirements can change (at least until they have experience of application development). In the 1980s, when microcomputers were first being adopted by businesses, I had many conversations with domain experts who were novice programmers building their first application for their business/customers. They were invariably surprised by the rate at which requirements changed, as development progressed.
While in public the issue lurked in the shadows, my experience is that projects claiming to be using Waterfall invariably had back-channel iterations, and requirements were traded, i.e., drop those and add these. Pre-Internet, any schedule involving more than two releases a year could be claimed to be making frequent releases.
Managers claimed to be using Waterfall because it was what everybody else did (yes, some used it because it was the most effective technique for their situation, and on some new projects it may still be the most effective technique).
Now that the issue of rapidly evolving requirements is out of the closet, what’s to stop Agile, in some form, being widely used when ‘rapidly evolving’ needs to be handled?
Discussion around Agile focuses on customers and developers, with middle management not getting much of a look-in. Companies using Agile don’t have many layers of management. Switching to Agile results in a lot of power shifting from middle management to development teams, in fact, these middle managers now look surplus to requirements. No manager is going to support switching to a development approach that makes them redundant.
Adam Yuret has another theory for why Agile won’t spread within enterprises. Making developers the arbiters of maximizing customer value prevents executives mandating new product features that further their own agenda, e.g., adding features that their boss likes, but have little customer demand.
The management incentives against using Agile in practice does not prevent claims being made about using Agile.
Now that Agile is what everybody claims to be using, managers who don’t want to stand out from the crowd find a way of being part of the community.
Estimating quantities from several hundred to several thousand
How much influence do anchoring and financial incentives have on estimation accuracy?
Anchoring is a cognitive bias which occurs when a decision is influenced by irrelevant information. For instance, a study by John Horton asked 196 subjects to estimate the number of dots in a displayed image, but before providing their estimate subjects had to specify whether they thought the number of dots was higher/lower than a number also displayed on-screen (this was randomly generated for each subject).
How many dots do you estimate appear in the plot below?

Estimates are often round numbers, and 46% of dot estimates had the form of a round number. The plot below shows the anchor value seen by each subject and their corresponding estimate of the number of dots (the image always contained five hundred dots, like the one above), with round number estimates in same color rows (e.g., 250, 300, 500, 600; code+data):
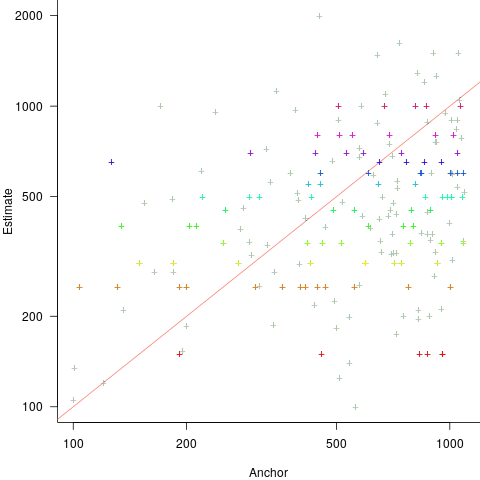
How much influence does the anchor value have on the estimated number of dots?
One way of measuring the anchor’s influence is to model the estimate based on the anchor value. The fitted regression equation  explains 11% of the variance in the data. If the higher/lower choice is included the model, 44% of the variance is explained; higher equation is:
explains 11% of the variance in the data. If the higher/lower choice is included the model, 44% of the variance is explained; higher equation is:  and lower equation is:
and lower equation is:  (a multiplicative model has a similar goodness of fit), i.e., the anchor has three-times the impact when it is thought to be an underestimate.
(a multiplicative model has a similar goodness of fit), i.e., the anchor has three-times the impact when it is thought to be an underestimate.
How much would estimation accuracy improve if subjects’ were given the option of being rewarded for more accurate answers, and no anchor is present?
A second experiment offered subjects the choice of either an unconditional payment of $2.50 or a payment of $5.00 if their answer was in the top 50% of estimates made (labelled as the risk condition).
The 196 subjects saw up to seven images (65 only saw one), with the number of dots varying from 310 to 8,200. The plot below shows actual number of dots against estimated dots, for all subjects; blue/green line shows  , and red line shows the fitted regression model
, and red line shows the fitted regression model  (code+data):
(code+data):
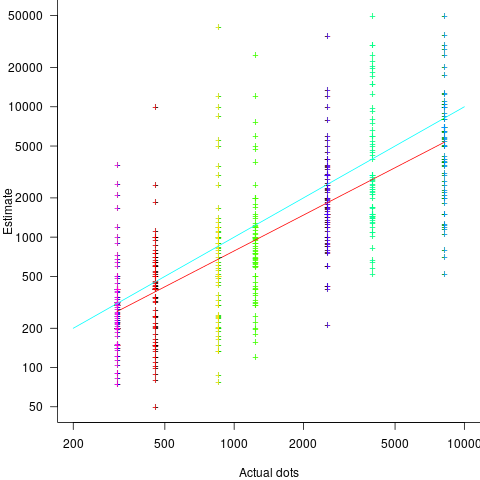
The variance in the estimated number of dots is very high and increases with increasing actual dot count, however, this behavior is consistent with the increasing variance seen for images containing under 100 dots.
Estimates were not more accurate in those cases where subjects chose the risk payment option. This is not surprising, performance improvements require feedback, and subjects were not given any feedback on the accuracy of their estimates.
Of the 86 subjects estimating dots in three or more images, 44% always estimated low and 16% always high. Subjects always estimating low/high also occurs in software task estimates.
Estimation patterns previously discussed on this blog have involved estimated values below 100. This post has investigated patterns in estimates ranging from several hundred to several thousand. Patterns seen include extensive use of round numbers and increasing estimate variance with increasing actual value; all seen in previous posts.
Research software code is likely to remain a tangled mess
Research software (i.e., software written to support research in engineering or the sciences) is usually a tangled mess of spaghetti code that only the author knows how to use. Very occasionally I encounter well organized research software that can be used without having an email conversation with the author (who has invariably spent years iterating through many versions).
Spaghetti code is not unique to academia, there is plenty to be found in industry.
Structural differences between academia and industry make it likely that research software will always be a tangled mess, only usable by the person who wrote it. These structural differences include:
- writing software is a low status academic activity; it is a low status activity in some companies, but those involved don’t commonly have other higher status tasks available to work on. Why would a researcher want to invest in becoming proficient in a low status activity? Why would the principal investigator spend lots of their grant money hiring a proficient developer to work on a low status activity?
I think the lack of status is rooted in researchers’ lack of appreciation of the effort and skill needed to become a proficient developer of software. Software differs from that other essential tool, mathematics, in that most researchers have spent many years studying mathematics and understand that effort/skill is needed to be able to use it.
Academic performance is often measured using citations, and there is a growing move towards citing software,
- many of those writing software know very little about how to do it, and don’t have daily contact with people who do. Recent graduates are the pool from which many new researchers are drawn. People in industry are intimately familiar with the software development skills of recent graduates, i.e., the majority are essentially beginners; most developers in industry were once recent graduates, and the stream of new employees reminds them of the skill level of such people. Academics see a constant stream of people new to software development, this group forms the norm they have to work within, and many don’t appreciate the skill gulf that exists between a recent graduate and an experienced software developer,
- paid a lot less. The handful of very competent software developers I know working in engineering/scientific research are doing it for their love of the engineering/scientific field in which they are active. Take this love away, and they will find that not only does industry pay better, but it also provides lots of interesting projects for them to work on (academics often have the idea that all work in industry is dull).
I have met people who have taken jobs writing research software to learn about software development, to make themselves more employable outside academia.
Does it matter that the source code of research software is a tangled mess?
The author of a published paper is supposed to provide enough information to enable their work to be reproduced. It is very unlikely that I would be able to reproduce the results in a chemistry or genetics paper, because I don’t know enough about the subject, i.e., I am not skilled in the art. Given a tangled mess of source code, I think I could reproduce the results in the associated paper (assuming the author was shipping the code associated with the paper; I have encountered cases where this was not true). If the code failed to build correctly, I could figure out (eventually) what needed to be fixed. I think people have an unrealistic expectation that research code should just build out of the box. It takes a lot of work by a skilled person to create to build portable software that just builds.
Is it really cost-effective to insist on even a medium-degree of buildability for research software?
I suspect that the lifetime of source code used in research is just as short and lonely as it is in other domains. One study of 214 packages associated with papers published between 2001-2015 found that 73% had not been updated since publication.
I would argue that a more useful investment would be in testing that the software behaves as expected. Many researchers I have spoken to have not appreciated the importance of testing. A common misconception is that because the mathematics is correct, the software must be correct (completely ignoring the possibility of silly coding mistakes, which everybody makes). Commercial software has the benefit of user feedback, for detecting some incorrect failures. Research software may only ever have one user.
Research software engineer is the fancy title now being applied to people who write the software used in research. Originally this struck me as an example of what companies do when they cannot pay people more, they give them a fancy title. Recently the Society of Research Software Engineering was setup. This society could certainly help with training, but I don’t see it making much difference with regard status and salary.
Update
This post generated a lot of discussion on the research software mailing list, and Peter Schmidt invited me to do a podcast with him. Here it is.
Main memory: the crucial component that vendors don’t mention
CPU performance hogs the limelight when people discuss the year-on-year increases in computing power that used to occur.
This focus on cpu performance was/is driven by marketing, the people with the money either don’t want customers thinking about the performance impact of main memory size or speed, or want them to treat the processor as the most important component of a computer. Vendors want processor performance to drive customer purchase decisions.
Hardware manufacturers used to entice new customers with low cost machines, containing minimal memory. Once a customer started to use their shiny new computer, they found that it did save them lots of time and money, but also they needed more memory (which could only be brought from the manufacturer and was not cheap).
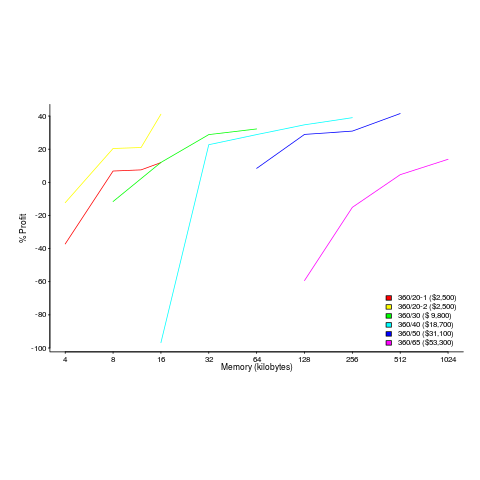
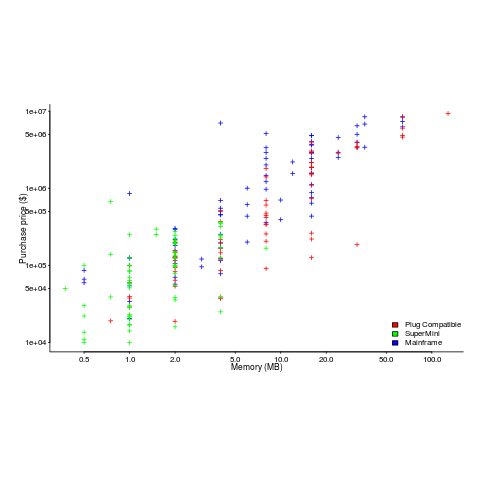
The plot below shows the prices IBM charged for System 360s, in 1966. Anti-trust investigations uncover all kinds of interesting data, like selling low-spec equipment at a loss to entice customers and make life difficult for competitors (code+data for all plots).
The plot below (data from the 19 Aug 1985 issue of ComputerWorld) shows how the price of computers increased as the minimum about of memory they supported increased.
Yes, in 1985 top end computers came with over 50M of memory; but most customers thought themselves lucky if they had a few megabytes.
If the processor is slow, it just takes longer for programs to run. If the computer does not have enough memory, programs cannot run. For most applications memory requirements are addressed first, followed by processor performance; memory requirements is the number one issue. The optimizations that commercial compilers could perform were limited by the memory capacity of developer machines.
Intel’s main line of business used to be selling memory chips, but these chips became commodity items as more companies entered the market; Intel bet the farm on selling processors and the rest is history. As a seller of a unique product it was/is in Intel’s interest to spend lots of money on marketing the benefits of processor performance; sellers of commodity items (such as memory chips) don’t have nearly as much to gain from generic product marketing, because customers may choose to buy from other sellers (in such markets sellers have to concentrate on marketing themselves).
Memory capacity/speed and cpu speed are two aspects of system performance; they need to be balanced to meet customer drive application requirements. The plot below shows the SPEC cpu integer performance of 4,332 systems running at various clock rates; the colors denote the different peak memory transfer rates of the memory chips in these systems (code+data).
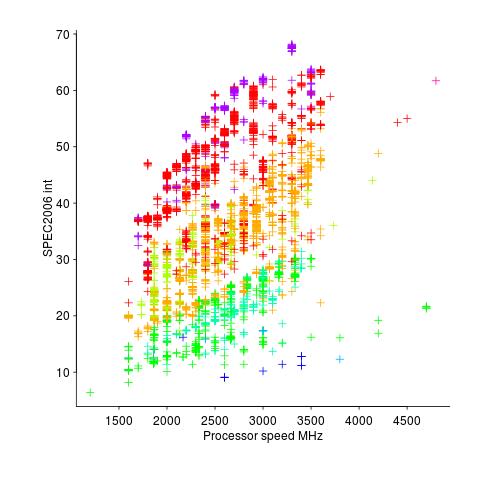
These days (and perhaps in the past, I don’t have any data), memory performance is a much better predictor of system performance, but vendors don’t have an incentive to market this fact.
Unappreciated bubble research
Every now and again an academic journal dedicates a single issue to one topic. I laughed when I saw the topic of an upcoming special issue on “Enhancing Credibility of Empirical Software Engineering”.
If you work in industry, you probably have a completely different interpretation of the intent of this issue, compared to somebody working in academia, i.e., you think the topic is about getting academic researchers to work on stuff of interest to industry. In academia the issue is about getting industry to treat the research work being done in universities as relevant to their needs, i.e., industry just does not appreciate how useful the work being done in universities is to solving real world problems.
Yes fellow industrialists, the credibility problem is all down to us not appreciating the work of those hard-working academics (I was once at a university meeting and the Dean referred to the industrialists at the meeting, which confused me because I did not know any were present; sometime later the penny dropped and I realised he was talking abut me and another guy who was working in industry).
The real problem is that most research academics have little idea what goes on in industry and what research results might be of interest to industry. This is not surprising given that the academic career ladder keeps people within the confines of the university bubble.
I regularly have academics express surprise that somebody in industry, i.e., me, knows about this-that-or-the-other. This baffled me for a while, until I realised that many academics really do regard people working in industry as simpletons; I now reply that its because I paid more for my degree and did not have the usual labotomy before graduating. Now they are baffled.
The solution to the problem of industrial research relevance is for academics to be willing to move outside the university bubble, to go out and interact with people in industry. However, there are powerful incentives pushing academics away from talking to industry:
- academic performance is measured by papers published and the chances of getting a paper published are improved if it involves a fashionable topic (yes fellow industrialists, academics suffer from this problem too). Stuff that industry is interested in is not fashionable, at least not yet. I don’t see many researchers being willing to risk working on very unfashionable topics in the hope that their work might get published,
- contact with industry will open the eyes of many academics to the interesting work being done there and the much higher paying jobs available (at least for those who are any good). Heads’ of department don’t want to lose their good people and have every incentive to discourage researchers having any contact with industry. The senior staff are sufficiently embedded in the system that they can be trusted to talk to industry, rather like senior communist party members being allowed to visit the West during the cold war.
An alternative way for academic research to connect with industry is for the research to be done by people with a lot of industry experience. There are a surprising number of people working in industry who are bored and are contemplating doing a PhD for something interesting to do (e.g., a public proclamation).
Again there are powerful incentives pushing against industry contact. PhD students do the academic grunt work and so compliant people are needed, i.e., recent graduates who will accept that this is how things work, not independent people who know better (such as those with a decent amount of industry experience). Worries about industrialists not being willing to tow-the-line with respect to departmental thinking are probably groundless, plenty of this sort of thing goes on in industry.
I found out at the weekend that only one central London university offers a computing related part-time PhD program (Birkbeck; few people can afford to a significant drop in income); part-time students are not around to do the grunt work.
Producing software for money and/or recognition
In the commercial environment money makes the world go around, while in academia recognition (e.g., number of times your work is cited, being fawned over at conferences, impressive job titles) is the coin of the realm (there are a few odd balls who do it out of love for the subject or a desire to understand how things work, but modern academia is a large bureaucracy whose primary carrot is recognition).
There is an incentive problem for those writing software in academia; software does not attract much, if any, recognition.
Does the lack of recognition for writing software matter? Surely what counts are the research results, not the tools used to get there (be they writing software or doing mathematics).
A recent paper bemoans the lack of recognition for the development of Python packages for Astronomy researchers. Well, its too late now, they have written the software and everybody gets to make perfect copies for free.
What the authors of Astropy want, is for researchers who use this software to include a citation to it in any published papers. Do all 162 authors deserve equal credit? If a couple of people add a new package, should they get a separate citation? What if a new group of people take over maintenance, when should the citation switch over from the old authors/maintainers to the new ones? These are a couple of the thorny questions that need to be answered.
R is perhaps the most widely used academic developed software ecosystem. A small dedicated group of people has invested a lot of their time over many years to make something special. A lot more people have invested effort to create a wide variety of add-on packages.
The base R library includes the citation function, which returns the BibTeX information for a given package; ready to be added to a research papers work flow.
Both commercial and academic producers need to periodically create new versions to keep ahead of the competition, attract more customers and obtain income. While they both produce software to obtain ‘income’, commercial and academic software systems have different incentives when it comes to support for end users of the software.
Keeping existing customers happy is the way to get them to pay for upgrades and this means maintaining compatibility with what went before. Managers in commercial companies make sure that developers don’t break backwards compatibility (developers hate having to code around what went before and would love to throw it all away).
In the academic world it does not matter whether end users upgrade, as long as they cite the package, the version used is irrelevant; so there is a lot less pressure to keep backwards compatibility. Academics are supposed to create new stuff, they are researchers after all, so the incentives are pushing them to create brand new packages/systems to be seen as doing new stuff (and obtain a whole new round of citations). A good example is Hadley Wickham, who has created some great R packages, who seems to be continually moving on, e.g., reshape -> reshape2 -> tidyr (which is what any good academic is supposed to do).
The run-time performance of a system is something end users always complain about, but often get used to. The reason is invariably that there is little or no incentive to address this issue (for both commercial and academic systems). Microsoft Windows is slower than it need be and the R interpreter could go a lot faster (the design of the interpreter looks like something out of the 1980s; I’m seeing a lot of packages in R only, so the idea that R programs spend all their time executing in C/Fortran libraries may be out of date. Where is the incentive to use post-2000 designs?)
How many new versions of a software package can be produced before enough people stop being willing to pay for an update? How many different packages solving roughly the same problem can academics produce?
I don’t think producing new packages for income has a long term future.
Recent Comments