Archive
1970s: the founding decade of software reliability research
Reliability research is a worthwhile investment for very large organizations that fund the development of many major mission-critical software systems, where reliability is essential. In the 1970s, the US Air Force’s Rome Air Development Center probably funded most of the evidence-based software research carried out in the previous century. In the 1980s, Rome fell, and the dark ages lasted for many decades (student subjects, formal methods, and mutation testing).
Organizations sponsor research into software reliability because they want to find ways of reducing the number of coding mistakes, and/or the impact of these mistakes, and/or reduce the cost of achieving a given level of reliability.
Control requires understanding, and understanding reliability first requires figuring out the factors that are the primarily drivers of program reliability.
How did researchers go about finding these primary factors? When researching a new field (e.g., software reliability in the 1970s), people can simply collect the data that is right in front of them that is easy to measure.
For industrial researchers, data was collected from completed projects, and for academic researchers, the data came from student exercises.
For a completed project, the available data are the reported errors and the source code. This data be able to answer questions such as: what kinds of error occur, how much effort is needed to fix them, and how common is each kind of error?
Various classification schemes have been devised, including: functional units of an application (e.g., computation, data management, user interface), and coding construct (e.g., control structures, arithmetic expressions, function calls). As a research topic, kinds-of-error has not attracted much attention; probably because error classification requires a lot of manual work (perhaps the availability of LLMs will revive it). It’s a plausible idea, but nobody knows how large an effect it might be.
Looking at the data, it is very obvious that the number of faults increases with program size, measured in lines of code. These are two quantities that are easily measured and researchers have published extensively on the relationship between faults (however these are counted) and LOC (counted by function/class/file/program and with/without comments/blank lines). The problem with LOC is that measuring it appears to be too easy, and researchers keep concocting more obfuscated ways of counting lines.
What do we now know about the relationship between reported faults and LOC? Err, … The idea that there is an optimal number of LOC per function for minimizing faults has been debunked.
People don’t appear to be any nearer understanding the factors behind software reliability than at the end of the 1970s. Yes, tool support has improved enormously, and there are effective techniques and tools for finding and tracking coding mistakes.
Mistakes in programs are put there by the people who create the programs, and they are experienced by the people who use the programs. The two factors rarely researched in software reliability are the people building the systems and the people using them.
Fifty years later, what software reliability books/reports from the 1970s have yet to be improved on?
The 1987 edition (ISBN 0-07-044093-X) of “Software Reliability: Measurement, Prediction, Application” by Musa, Iannino, and Okumoto is based on research done in the 1970s (the 1990 professional edition is not nearly as good). Full of technical details, but unfortunately based on small datasets.
The 1978 book Software Reliability by Thayer, Lipow and Nelson, remains a go-to source for industrial reliability research data.
A good example of the industrial research funded by the Air Force is the 1979 report Software Data Baseline Analysis by D. L. Fish and T. Matsumoto. This is worth looking at just to learn how few rows of data later researchers have been relying on.
Evidence-based Software Engineering book: the last year
It’s now three years since my book, Evidence-based Software Engineering: based on the publicly available data, was released. What has happened in the last year, since I wrote about the first two years, and what might happen in the next year or so?
There is now a Discord channel for discussing evidence-based software engineering. Blog readers and anyone with an interest in the subject are most welcome.
I keep a copy of software related papers that I think might be worth looking at again, and have been meaning to make this list public. A question by ysch, a Discord channel member, asked after ways of checking whether a software paper was worth reading. This prompted me to create a Github repo containing the titles of these 7,756 saved papers, along with some data related annotations. On the more general question of paper quality, my view is that most papers are not worth reading, with a few being very well worth reading. People have to develop techniques for rapidly filtering out the high volume of drivel; techniques I use, and understanding the publication ecosystem.
This last year saw the sudden arrival of a new tool, LLMs. My experience with using ChatGPT (and other such LLMs) as an evidence-based research tool is that the answers are too generic or just plain wrong (for several months, one LLM reported that I had a degree in Divinity Studies). If I was writing a book, I suspect that they would provide a worthwhile copy-editing service.
I was hoping that the recently released GPT-4 vision model would do high quality text extraction from scanned pdfs, but the quality of output I have received is about the same as traditional OCR-based tools. I expect that the data extraction ability LLM based tools will get a lot better, because they are at the start of the learning curve and there is a commercial incentive for them to be a lot better.
An LLM is driven by the token weights learned during training. Roughly speaking, the more training data on a topic, the larger the trained weights for that topic. There is not a lot of data (i.e., text) relating to evidence-based software engineering, compared to the huge quantities available for some topics, so responses are generic and often parrot established folklore. The following image was generated by DALL-E3:

There is a tale of software product evolution waiting to be told via the data contained in magazine adverts; the magazines are on bitsavers, we just need LLMs to be good enough to reliably extract advert contents (currently, too many hallucinations).
The book contents continue to survive almost completely unscathed, primarily because reader feedback continues to be almost non-existent. Despite the close to 500k downloads (now averaging 4k-5k downloads per month, from the logs I have, with the mobile friendly version around 10%), most people I meet have not heard of the book. The concept of an evidence-based approach to software engineering continues to be met with blank looks, although a commonly cited listener use case for the book’s data is validating a pet theory (my suggestion that the data may show their pet theory to be wrong is not appreciated).
Analysis/data in the following blog posts, from the last 12-months, belongs in the book in some form or other:
Some human biases in conditional reasoning
Unneeded requirements implemented in Waterfall & Agile
Analysis of Cost Performance Index for 338 projects
Evaluating Story point estimation error
Frequency of non-linear relationships in software engineering data
Analysis of when refactoring becomes cost-effective
An evidence-based software engineering book from 2002
Perturbed expressions may ‘recover’
Predicting the size of the Linux kernel binary
Local variable naming: some previously unexplored factors
Optimal function length: an analysis of the cited data
Some data on the size of Cobol programs/paragraphs
Hardware/Software cost ratio folklore
Criteria for increased productivity investment
Likelihood of encountering a given sequence of statements
An evidence-based software engineering book from 2002
I recently discovered the book A Handbook of Software and Systems Engineering: Empirical Observations, Laws and Theories by Albert Endres and Dieter Rombach, completed in 2002.
The preface says: “This book is about the empirical aspects of computing. … we intend to look for rules and laws, and their underlying theories.” While this sounds a lot like my Evidence-based Software Engineering book, the authors take a very different approach.
The bulk of the material consists of a detailed discussion of 50 ‘laws’, 25 hypotheses and 12 conjectures based on the template: 1) a highlighted sentence making some claim, 2) Applicability, i.e., situations/context where the claim is likely to apply, 3) Evidence, i.e., citations and brief summary of studies.
As researchers of many years standing, I think the authors wanted to present a case that useful things had been discovered, even though the data available to them is nowhere near good enough to be considered convincing evidence for any of the laws/hypotheses/conjectures covered. The reasons I think this book is worth looking at are not those intended by the authors; my reasons include:
- the contents mirror the unquestioning mindset that many commercial developers have for claims derived from the results of software research experiments, or at least the developers I talk to about software research. I’m forever educating developers about the need for replications (the authors give a two paragraph discussion of the importance of replication), that sample size is crucial, and using professional developers as subjects.
Having spent twelve chapters writing authoritatively on 50 ‘laws’, 25 hypotheses and 12 conjectures, the authors conclude by washing their hands: “The laws in our set should not be seen as dogmas: they are not authoritatively asserted opinions. If proved wrong by objective and repeatable observations, they should be reformulated or forgotten.”
For historians of computing this book is a great source for the software folklore of the late 20th/early 21st century,
- the Evidence sections for each of the laws/hypotheses/conjectures is often unintentionally damming in its summary descriptions of short/small experiments involving a handful of people or a few hundred lines of code. For many, I would expect the reaction to be: “Is that it?”
Previously, in developer/researcher discussions, if a ‘fact’ based on the findings of long ago software research is quoted, I usually explain that it is evidence-free folklore; followed by citing The Leprechauns of Software Engineering as my evidence. This book gives me another option, and one with greater coverage of software folklore,
- the quality of the references, which are often to the original sources. Researchers tend to read the more recently published papers, and these are the ones they often cite. Finding the original work behind some empirical claim requires following the trail of citations back in time, which can be very time-consuming.
Endres worked for IBM from 1957 to 1992, and was involved in software research; he had direct contact with the primary sources for the software ‘laws’ and theories in circulation today. Romback worked for NASA in the 1980s and founded the Fraunhofer Institute for Experimental Software Engineering.
The authors cannot be criticized for the miniscule amount of data they reference, and not citing less well known papers. There was probably an order of magnitude less data available to them in 2002, than there is available today. Also, search engines were only just becoming available, and the amount of material available online was very limited in the first few years of 2000.
I started writing a book in 2000, and experienced the amazing growth in the ability of search engines to locate research papers (first using AltaVista and then Google), along with locating specialist books with Amazon and AbeBooks. I continued to use university libraries for papers, which I did not use for the evidence-based book (not that this was a viable option).
Focus of activities planned for 2023
In 2023, my approach to evidence-based software engineering pivots away from past years, which were about maximizing the amount of software engineering data gathered.
I plan to spend a lot more time attempting to join dots (i.e., finding useful patterns in the available data), and I also plan to spend time collecting my own data (rather than other peoples’ data).
I will continue to keep asking people for data, and I’m sure that new data will become available (and be the subject of blog posts). The amount of previously unseen data obtained by continuing to read pre-2020 papers is likely to be very small, and not worth targetting. Post-2020 papers will be the focus of my search for new data (mostly conference proceedings and arXiv’s software engineering recent submissions)
It would be great if there was an active community of evidence-based developers. The problem is that the people with the necessary skills are busily employed building real systems. I’m hopeful that people with the appropriate background and skills will come out of the woodwork.
Ideally, I would be running experiments with developer subjects; this is the only reliable way to verify theories of software engineering. While it’s possible to run small scale experiments with developer volunteers, running a workplace scale experiment will be expensive (several million pounds/dollars). I don’t move in the circles frequented by the very wealthy individuals who might fund such an experiment. So this is a back-burner project.
if-statements continue to be of great interest to me; they represent decisions that relate to requirements and tests that need to be written. I used to spend a lot of time measuring, mostly C, source code: how the same variable is tested in nested conditions, the use of else arms, and the structuring of conditions within a function. The availability of semgrep will, hopefully, enable me to measure various aspect of if-statement usage across different languages.
I hope that my readers continue to keep their eyes open for interesting software engineering data, and will let me know when they find any.
Evidence-based SE groups doing interesting work, 2021 version
Who are the research groups currently doing interesting work in evidenced-base software engineering (academics often use the term empirical software engineering)? Interestingness is very subjective, in my case it is based on whether I think the work looks like it might contribute something towards software engineering practices (rather than measuring something to get a paper published or fulfil a requirement for an MSc or PhD). I last addressed this question in 2013, and things have changed a lot since then.
This post focuses on groups (i.e., multiple active researchers), and by “currently doing” I’m looking for multiple papers published per year in the last few years.
As regular readers will know, I think that clueless button pushing (a.k.a. machine learning) in software engineering is mostly fake research. I tend to ignore groups that are heavily clueless button pushing oriented.
Like software development groups, research groups come and go, with a few persisting for many years. People change jobs, move into management, start companies based on their research, new productive people appear, and there is the perennial issue of funding. A year from now, any of the following groups may be disbanded or moved on to other research areas.
Some researchers leave a group to set up their own group (even moving continents), and I know that many people in the 2013 survey have done this (many in the Microsoft group listed in 2013 are now scattered across the country). Most academic research is done by students studying for a PhD, and the money needed to pay for these students comes from research grants. Some researchers are willing to spend their time applying for grants to build a group (on average, around 40% of a group’s lead researcher’s time is spent applying for grants), while others are happy to operate on a smaller scale.
Evidence-based research has become mainstream in software engineering, but this is not to say that the findings or data have any use outside of getting a paper published. A popular tactic employed by PhD students appears to be to look for what they consider to be an interesting pattern in code appearing on Github, and write a thesis that associated this pattern with an issue thought to be of general interest, e.g., predicting estimates/faults/maintainability/etc. Every now and again, a gold nugget turns up in the stream of fake research.
Data is being made available via personal Github pages, figshare, osf, Zenondo, and project or personal University (generally not a good idea, because the pages often go away when the researcher leaves). There is no current systematic attempt to catalogue the data.
There has been a huge increase in papers coming out of Brazil, and Brazilians working in research groups around the world, since 2013. No major Brazilian name springs to mind, but that may be because I have not noticed that they are Brazilian (every major research group seems to have one, and many of the minor ones as well). I may have failed to list a group because their group page is years out of date, which may be COVID related, bureaucracy, or they are no longer active.
The China list is incomplete. There are Chinese research groups whose group page is hosted on Github, and I have failed to remember that they are based in China. Also, Chinese pages can appear inactive for a year or two, and then suddenly be updated with lots of recent information. I have not attempted to keep track of Chinese research groups.
Organized by country, groups include (when there is no group page available, I have used the principle’s page, and when that is not available I have used a group member page; some groups make no attempt to help others find out about their work):
Belgium (I cite the researchers with links to pdfs)
Brazil (Garcia, Steinmacher)
Canada (Antoniol, Data-driven Analysis of Software Lab, Godfrey and Ptidel, Robillard, SAIL; three were listed in 2013)
China (Lin Chen, Lu Zhang, Minghui Zhou)
Germany (Chair of Software Engineering, CSE working group, Software Engineering for Distributed Systems Group, Research group Zeller)
Greece (listed in 2013)
Italy (listed in 2013)
Japan (Inoue lab, Kamei Web, Kula, and Kusumoto lab)
Spain (the only member of the group listed in 2013 with a usable web page)
Sweden (Chalmers, KTH {Baudry and Monperrus, with no group page})
Switzerland (SCG and REVEAL; both listed in 2013)
USA (Devanbu, Foster, Maletic, Microsoft, PLUM lab, SEMERU, squaresLab, Weimer; two were listed in 2013)
Sitting here typing away, I have probably missed out some obvious candidates (particularly in the US). Suggestions for omissions welcome (remember, this is about groups, not individuals).
What is known about software effort estimation in 2021
What do we know about software effort estimation, based on evidence?
The few publicly available datasets (e.g., SiP, CESAW, and Renzo) involve (mostly) individuals estimating short duration tasks (i.e., rarely more than a few hours). There are other tiny datasets, which are mostly used to do fake research. The patterns found across these datasets include:
- developers often use round-numbers,
- the equation:
 , where
, where  is a constant that varies between projects, often explains around 50% of the variance present in the data. This equation shows that developers under-estimate short tasks and over-estimate long tasks. The exponent,
is a constant that varies between projects, often explains around 50% of the variance present in the data. This equation shows that developers under-estimate short tasks and over-estimate long tasks. The exponent,  , applies across most projects in the data,
, applies across most projects in the data, - individuals tend to either consistently over or under estimate,
- developer estimation accuracy does not change with practice. Possible reasons for this include: variability in the world prevents more accurate estimates, developers choose to spend their learning resources on other topics.
Does social loafing have an impact on actual effort? The data needed to answer this question is currently not available (the available data mostly involves people working on their own).
When working on a task, do developers follow Parkinson’s law or do they strive to meet targets?
The following plot suggests that one or the other, or both are true (data):
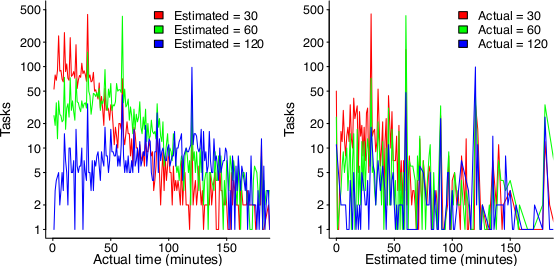
On the left: Each colored lines shows the number of tasks having a given actual implementation time, when they were estimated to take 30, 60 or 120 minutes (the right plot reverses the role of estimate/actual). Many of the spikes in the task counts are at round numbers, suggesting that the developer has fixated on a time to finish and is either taking it easy or striving to hit it. The problem is distinguishing them mathematically; suggestions welcome.
None of these patterns of behavior appear to be software specific. They all look like generic human behaviors. I have started emailing researchers working on project analytics in other domains, asking for data (no luck so far).
Other patterns may be present for many projects in the existing data, we have to wait for somebody to ask the right question (if one exists).
It is also possible that the existing data has some unusual characteristics that don’t apply to most projects. We won’t know until data on many more projects becomes available.
Evidence-based book: six months of downloads
When my C book was first made available as a freely downloadable pdf, in 2005, there were between 19k to 37k downloads in the first week. The monthly download rate remained stable at around 1k per month for several years, and now floats around 100 per month.
I was hoping to have many more downloads for my Evidence-based software engineering book. The pdf became available last year on November 8th, and there were around 10k downloads in the first week. Then a link to my blog post announcing the availability of the book was posted to news.ycombinator. That generated quarter million downloads of the pdf, with an end-of-month figure of 275,309 plus 16,135 for the mobile friendly version.
The initial release did not include a mobile friendly version. After a half-a-dozen or so requests in various forums, I quickly worked up a mobile friendly pdf (i.e., the line length was reduced to be visually readable on a mobile phone, or at least on my 7-year-old phone which is smaller than most).
In May a link to the book’s webpage was posted on news.ycombinator. This generated 125k+ downloads, and the top-rated comment was that this was effectively a duplicate of the November post.
The plot below shows the number of pdf downloads for A4 and mobile formats, along with the number of kilo-bytes downloaded, for the 6-months since the initial release (code+data):
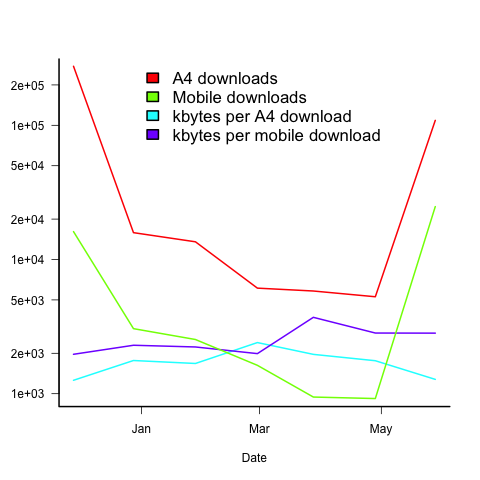
On average, there are five A4 downloads per mobile download (excluding November because of the later arrival of a mobile friendly version).
A download is rarely a complete copy (which is 23Mbyte), with the 6-month average being 1.7M for A4 and 2.5M for mobile. I have no idea of the reason for this difference.
The bytes per download is lower in the months when the ycombinator activity occurred. Is this because the ycombinator crowd tend to skim content (based on some of the comments, I suspect that many comments never read further than the cover)?
Copies of the pdf were made available on other sites, but based on the data I have seen, the downloads were not more than a few thousand.
I have not had any traffic spikes caused by non-English language interest. The C book experienced a ‘China’ spike, and I emailed the author of the blog post that caused it, to notify him of the Evidence-based book; he kindly posted an article on the book, but this did not generate a noticeable spike.
I’m confident that eventually a person in China/Russia/India/etc, with tens of thousands of followers, will post a link and there will be a noticeable download spike from that region.
What was the impact of content delivery networks and ISP caching? I have no idea. Pointers to write-ups on the topic welcome.
Evidence on the distribution and diversity of Christianity: 1900-2000
I recently read an article saying that Christianity had 33,830 denominations, with 150 having more than 1 million followers. Checking the references, World Christian Encyclopedia was cited as the source; David Barrett had spent 12 years traveling the world, talking to people to collect the data. An evidence-based man, after my own heart.
Checking the second-hand book sites, I found a copy of the 1982 edition available for a few pounds, and placed an order (this edition lists 20,800 denominations; how many more are there to be ‘discovered’).
The book that arrived was a bit larger than I had anticipated. This photograph shows just how large this book is, compared to other dead-tree data sources in my collection (on top, in red, is your regular 400 page book):

My interest in a data-driven discussion of the spread and diversity of religions, was driven by wanting ideas for measuring the spread and diversity of programming languages. Bill Kinnersley’s language list contains information on 2,500 programming languages, and there are probably an order of magnitude more languages waiting to be written about.
The data is available to researchers, but is not public 🙁
The World Christian Encyclopedia is way too detailed for my needs. I usually leave unwanted books on the book table of my local train station’s Coffee shop. I have left some unusual books there in the past, but this one feels like it needs a careful owner; I will see whether the local charity shop will take it in.
Foundations for Evidence-Based Policymaking Act of 2017
The Foundations for Evidence-Based Policymaking Act of 2017 was enacted by the US Congress on 21st December.
A variety of US Federal agencies are responsible for ensuring the safety of US citizens, in some cases this safety is dependent on the behavior of software. The FDA is responsible for medical device safety and the FAA publishes various software safety handbooks relating to aviation (the Department of transportation has a wider remit).
Where do people go to learn about the evidence for software related issues?
The book: Evidence-based software engineering: based on the publicly available evidence sounds like a good place to start.
Quickly skimming this (currently draft) book shows that no public evidence is available on lots of issues. Oops.
Another issue is the evidence pointing to some suggested practices being at best useless and sometimes fraudulent, e.g., McCabe’s cyclomatic complexity metric.
The initial impact of evidence-based policymaking will be companies pushing back against pointless government requirements, in particular requirements that cost money to implement. In some cases this is a good, e.g., no more charades about software being more testable because its code has a low McCable complexity.
In the slightly longer term, people are going to have to get serious about collecting and analyzing software related evidence.
The Open, Public, Electronic, and Necessary Government Data Act or the OPEN Government Data Act (which is about to become law) will be a big help in obtaining evidence. I think there is a lot of software related data sitting on disks and tapes, waiting to be analysed (NASA appears to have loads to data that they have down almost nothing with, including not making it publicly available).
Interesting times ahead.
Recent Comments