Archive
A safety-critical certification of the Linux kernel
This week there was an announcement on the system-safety mailing list that the Red Hat In-Vehicle Operating System (a version of the Linux kernel, plus a few subsystems) had been certified as being “… capable for use in ASIL B applications, …”. The Automotive Safety Integrity Levels (ASIL A is the lowest level, with D the highest; an example of ASIL B is controlling brake lights) are defined by ISO 26262, an international standard for functional safety of electrical and/or electronic systems installed in production road vehicles.
Given all I had heard about the problems that needed to be solved to get a safety certification for something as large and complicated as the Linux kernel, I wanted to know more about how Red Hat had achieved this certification.
The traditional, idealised, approach to certifying software is to check that all requirements are documented and traceable to the design, source code, tests, and test results. This information can be used to ensure that every requirement is implemented and produces the intended behavior, and that no undocumented functionality has been implemented.
When this approach is not practical (because of onerous time/cost), a potential get out of jail card is to use a Rigorous Development Process. Certification friendly development processes appear to revolve around lots of bureaucracy and following established buzzword techniques. The only development processes that have sometimes produced very reliable software all involve spending lots of time/money.
The major problems with certifying Linux are the apparent lack of specification/requirements documents, and a development process that does not claim to be rigorous.
The Red Hat approach is to treat the Linux man pages as the specification, extract the requirements from these pages, and then write the appropriate tests. Traceability looks like it is currently on the to-do list.
I have spent a lot of time working to understand specifications and their requirements; first with the C Standard and then with the Microsoft Server Protocols. This is the first time I have encountered man pages being used in a formal setting (sometimes they are used as one of the inputs to a reimplementation of a library).
Very little Open source software has a written specification in the traditional sense of a document cited in a contract that the vendor agrees to implement. Manuals, READMEs and help pages are not written in the formal style of a specification. A common refrain is that the source code is the specification. However, source is a specification of what the program does, it is not a specification of what the program is supposed to do.
The very nature of the Agile development process demands that there not be a complete specification. It’s possible that user stories could be treated as requirements.
There is an ISO Standard with Linux in its title: the Linux Base Standard. The goal of this Standard “… is to develop and promote a set of open standards that will increase compatibility among Linux distributions and enable software applications to run on any compliant system …”, i.e., it is not a specification of an OS kernel.
POSIX is a specification of the behavior of an OS (kernel functionality is specified by POSIX.1, .2 is shell and utilities, plus other .x documents). It’s many years since I tracked POSIX/Linux compliance, which was best described as “highly compatible”. Both Grok3 and ChatGPT o4 agree that “highly compatible” is still true, and list some known incompatibilities.
While they are not written in the form of a specification, the Linux man pages do have a consistent structure and are intended to be up-to-date. A person with a background of working with Linux kernels could probably extract meaningful requirements.
How many requirements are needed to cover the behavior of the Linux kernel?
On my computer running a 6.8.0-51 kernel, the /usr/include/linux directory contains 587 header files. Based on an analysis from 20 years ago (table 1897.1), most of these headers only declare macros and types (e.g., memory layout), not function declarations. The total number of function declarations in these headers is probably in the low thousands. POSIX (2008 version) defines 1,177 functions, but the number of system calls is probably around 300-400. Android implements 821 of these functions, of which 343 are system call related.
Let’s assume 2,000 functions. Some of these functions have an argument that specifies one or more optional values, each specifying a different sub-behavior. How many different sub-behaviors are there? If we assume that each kind of behavior is specified using a C macro, then Table 1897.1 suggests there might be around 10k C macros defined in these headers.
With positive/negative tests for each case, in round numbers we get (ignoring explicit testing of the values of struct members): *2 = 24,000") test files.
test files.
This calculation does not take into account combinations of options. I’m assuming that each test file will loop through various combinations of its kind of sub-behavior.
The 1990 C compiler validation suite contained around 1k tests. Thirty-five years later, 24k test files for a large OS feels low, but then combination testing should multiply the number of actual tests by at least an order of magnitude.
What is this hand-wavy analysis missing?
I suspect that the kernel is built with most of the optional functionality conditionally compiled out. This could significantly reduce the number of api functions and the supported options.
I have not taken into account any testing of the user-visible kernel data structures (because I don’t have any occurrence data).
Comments from readers with experience in testing OSes most welcome.
Another source of Linux specific information is the Linux Kernel documentation project. I don’t have any experience using this documentation, but the API documentation is very minimalist (automatically extracted from the source; the Assessment report lists this document as [D124], but never references it in the text).
Readers familiar with safety standards will be asking about the context in which this certification applies. Safety functions are not generic; they are specific to a safety-related system, i.e., software+hardware. This particular certification is for a Safety Element out of Context (SEooC), where “out of context” here means without the context of a system or knowledge of the safety goals. SEooC supports a bottom up approach to safety development, i.e., Safety Elements can be combined, along with the appropriate analysis and testing, to create a safety-related system.
This certification is the first of what I think will be many certifications of Linux, some at more rigorous safety levels.
Documentation as a signal of program size
Developers and researchers invariably measure program size in lines of code, while senior managers measure by resources consumed per accounting period, e.g., money and people.
What size signals are visible to the users of a program?
Before CDs became generally available at the start of the 1990s, software for desktop computers was delivered on floppy discs that did not have the capacity to hold documentation (i.e., 128K to 1.4M), which was distributed in printed book form.
For instance, the first version of Turbo Pascal came with one 5¼ floppy (the compiler+IDE occupied 28K) and a 276-page reference manual.
Today, people are familiar with the intangible nature of software. In previous ages, people wanted to see and feel something for their money, and printed manuals were the substance they received (some products attached the floppies inside the back covers). Physical manuals were also thought to reduce software piracy (when CDs arrived, there was lots of hand-wringing over including electronic manuals).
Microsoft Windows bucked the trend, distributed with almost no physical paper, but many floppies; 13 3½ floppies for the initial upgrade to Windows 95, and 26 for Service Release 2 (oh, the fun of spending an afternoon swapping disks to rebuild a machine). Microsoft Office 97 standard edition was available on 45 floppies, the professional edition on 55.
The problem with distributing manuals in printed book form is that updates are costly; customers need a whole new book and the existing inventory needs to be scrapped. Documentation for Mainframe/Minicomputer/Workstations came in ring binders, allowing updates on an individual page basis. The Sun 4 that arrived at my office (to have a COBOL code generator written for the SPARC cpu) came with around 3-feet of ring binders. I have seen offices with a wall of shelves filled with vendor ring binders.
Is there any correlation between a project’s lines of code and pages of it’s documentation?
Most developers hate writing documentation; readmes don’t count. This means that only (well) funded development projects are likely to pay for an author to produce some amount of non-trivial documentation (a widely used application eventually attracts an external author interested in explaining things). Some Open source projects do contain files believed to be documentation; documentation research is primarily focused on accuracy (see section 6.4.4).
The only data I am aware of containing LOC, documentation page counts, and development man months is the 1979 paper The Characteristics of Large Systems by Belady and Lehman, which lists values for 37 “… independent programs developed in a large software house.” How much of the documentation was user focused, requirements+business logic, or developer focused? I have no idea (a fitted regression model, code+data, shows an almost linear relationship between LOC and document pages). Tests are not broken out as a separate item (code, documentation, not recorded?)
The plot below shows delivered: source lines of code, documentation pages, and total man months, x/y-axis both using log scales (code+data):
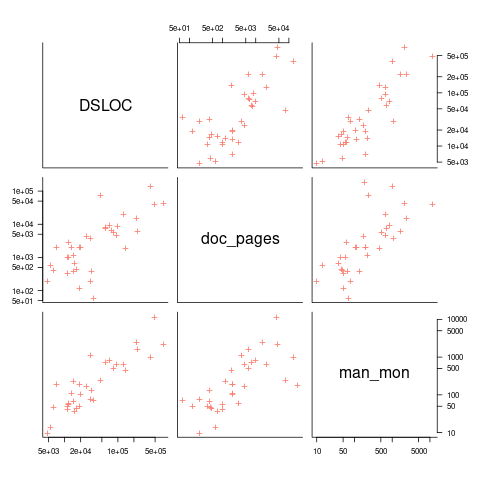
The total man months of implementation for each project is taken up by writing the code and documentation. The following equation is a good fit (explaining just 80% of the variance; code+data):  , but is only slightly better than
, but is only slightly better than  . Given the high correlation between
. Given the high correlation between  and
and  , including both in the same model is probably not a good idea (the equation:
, including both in the same model is probably not a good idea (the equation:  explains just over 50% of the variance).
explains just over 50% of the variance).
There are a few possible outliers in the data. Perhaps removing these would make the picture clearer.
For me, what stands out, compared to today’s projects, is the relatively low DSLOC (a few tens of thousands) and high pages of documentation (thousands). Projects could be smaller/simpler in the 1970s because they were often replacing humans doing the work, not previously written systems; or, perhaps projects were limited by available computer memory, often well less than a megabyte. Perhaps I think the page count is high because I don’t have an accurate idea of how much online documentation is created these days.
Recent Comments