Archive
CPUs also exhibit hardware faults
The cpu is the one element of a computing platform that people rarely treat as a source of error caused by physically malfunction, i.e., randomly flipping a bit in a register or instruction pipeline. I once worked on a compiler for the Mototola 88000 using a test platform that contained alpha silicon (i.e., not yet saleable components where some of the instructions were known not to work; the generated assembler code was piped through a sed script that mapped these instructions into an alternative instruction sequence that did work) and the cpus in a few of the hardware updates turned out to be temperature sensitive; some of the instructions changed their behavior when they got too hot. People who write compilers using alpha silicon learn to expect this sort of thing.
Quite a bit has been published on faults in other hardware components. Some of the best recent empirical hardware fault data and analysis I have seen is that published by Google engineers on hard disc and dram memory fault occurrences in their server farms. They might have a problem publishing such results for the cpus they use because these commodity items generally don’t have the ability to report any detailed fault data, they just die or one of the programs being executed crashes.
As device fabrication continues to shrink erroneous behavior caused by cosmic ray impact will become more and more common. Housing a computer farm at a high altitude might not be a good idea (at 7500 ft cosmic ray-induced neutrons that can lead to soft errors are 6.4 times more common than at sea level).
IBM’s Power4 chip (“Power4 System Design for High Reliability” by Bossen, Tendler and Reick) is one of the few that provides error checking of cache contents, while IBM’s System z9 is one of the very few that provide parity checking on the cpu registers (“Enhanced I/O subsystem recovery and availability on the IBM System z9” by Oakes et al).
One solution to the problem of unreliable cpu behavior is for the compiler to insert consistency checks into the generated code. Two such checking methods are:
- ‘Signature Analysis’ which performs consistency checks between signatures calculated at compile time and runtime. A signature is associated with every basic block with the current signature being derived from the execution history. This technique can detect spurious changes to the flow of control caused by a hardware glitch.
- ‘Error Detection by Duplicated Instructions’ generates code which duplicates the behavior of some instruction sequence and compares the result calculated by both sequences, i.e., a source language construct is executed twice and an error raised if the results are different. The parallel instruction sequences use different sets of registers on the same cpu and ideally the instructions are scheduled to exploit instruction level parallelism
At the moment cosmic-ray induced hardware faults are probably very small change compared to faults in the code. Will code quality increase to the point where cosmic-ray faults become an issue or will devices get so small that they have to be lead lined to prevent background radiation corrupting them? Let the race begin.
Estimating variance when measuring source
Yesterday I finally delivered a paper on if/switch usage measurements to the ACCU magazine editor and today I read about a switch statement usage that, if common, would invalidate a chunk of my results. Does anything jump out at you in the following snippet?
switch (x) { case 1: { z++; ... break; } ... |
Yes, those { } delimiting the case-labeled statement sequence. A quick check of my C source benchmarks showed this usage occurring in around 1% of case-labels. Panic over.
What is the statistical significance, i.e., variance, of that 1%? Have I simply measured an unrepresentative sample, what would be a representative sample and what would be the expected variance within a representative sample?
I am interested in commercial software development, and so I have selected half a dozen or so largish code bases as my source benchmark, preferably written in a commercial environment even if currently available as Open source. I would prefer this benchmark to be an order of magnitude larger, and perhaps I will get around to adding more programs soon.
My if/switch measurements were aimed at finding usage characteristics that varied between the two kinds of selection statements. One characteristic measured was the number of equality tests in the associated controlling expression. For instance, in:
if (x == 1 || x == 2) z--; else if (x == 3) z++; |
the first controlling expression contains two equality tests, and the second one equality test.
Plotting the percentage of equality tests that occur in the controlling expressions of if-if/if-else-if sequences and switch statements, we get the following:
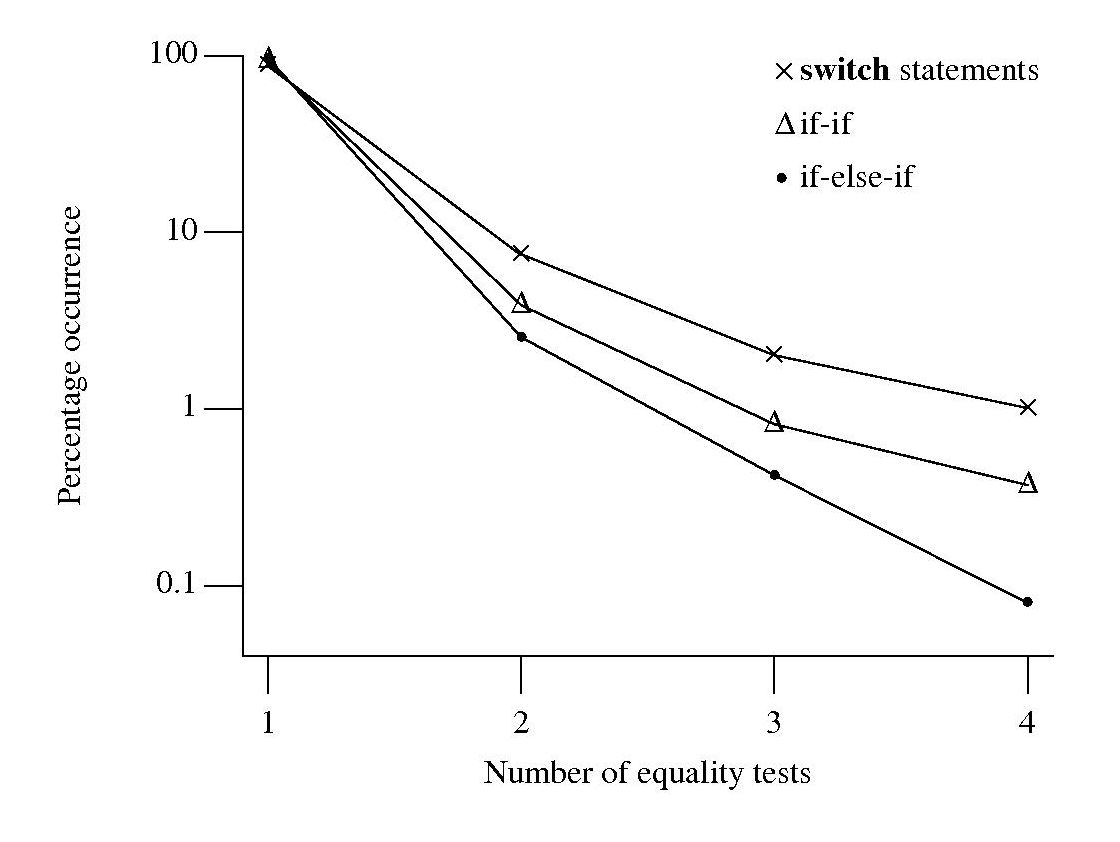
Do these results indicate that if-if/if-else-if sequences and switch statements differ in the number of equality tests contained in their controlling expressions? If I measured a completely different set of source code, would the results be very different?
To answer this question, a probability model is needed. Take as an example, the controlling expressions present in an if-if sequence. If each controlling expression is independent of the others, then the probability of two equality tests, for instance, occurring in any of these expressions is constant and thus given a large sample the distribution of two equality tests in the source has a binomial distribution. The same argument can be applied to other numbers of equality tests and other kinds of sequence.

For each measurement point in the above plot the associated error bars span the square-root of the variance of that point (assuming a binomial distribution, for a normal distribution the length of this span is known as the standard deviation). The error bars overlap, suggesting that the apparent difference in percentage of equality tests in each kind of sequence is not statistically significant.
The existence of some dependency between controlling expression equality tests would invalidate this simply analysis, or at least reduce its reliability. I did notice that in a sequence that containing two equality tests, the controlling expression that contained it tended to appear later in the sequence (the reverse of the example given above). Did I notice this because I tend to write this way? A question for another day.
Register vs. stack based VMs
Traditionally the virtual machine architecture of choice has been the stack machine; benefits include simplicity of VM implementation, ease of writing a compiler back-end (most VMs are originally designed to host a single language) and code density (i.e., executables for stack architectures are invariably smaller than executables for register architectures).
For a stack architecture to be an effective solution, two conditions need to be met:
- The generated code has to ensure that the top of stack is kept in sync with where the next instruction expects it to be. For instance, on its return a function cannot leave stuff lying around on the stack like it can leave values in registers (whose contents can simply be overwritten).
- Instruction execution needs to be generally free of state, so an add-two-integers instruction should not have to consult some state variable to find out the size of integers being added. When the value of such state variables have to be saved and restored around function calls, they effectively become VM registers.
Cobol is one language where it makes more sense to use a register based VM. I wrote one and designed two machine code generators for the MicroFocus Cobol VM and always find it difficult to explain to people what a very different kind of beast it is compared to the VMs usually encountered.
Parrot, the VM designed as the target for compiled PERL, is register based. A choice driven, I suspect, by the difficulty of ensuring a consistent top-of-stack and perhaps the dynamic typing of the language.
On register based cpus with 64k of storage, the code density benefits of a stack based VM are usually sufficient to cancel out the storage overhead of the VM interpreter and support a more feature rich application (provided speed of execution is not crucial).
If storage capacity is not a significant issue and a VM has to be used, what are the runtime performance differences between a register and stack based VM? Answering this question requires compiling and executing the same set of applications for the two kinds of VM. Something that until 2001 nobody had done, or at least not published the results.
A comparison of the Java (stack based) VM with a register VM (The Case for Virtual Register Machines) found that while the stack based code was more compact, fewer instructions needed to be executed on the register based VM.
Most VM instructions are very simple and take relatively little time to execute. When hosted on a pipelined processor the main execution time overhead of a VM is the instruction dispatch (Optimizing Indirect Branch Prediction Accuracy in Virtual Machine Interpreters) and reducing the number of VM instructions executed, even if they are larger and more complicated, can produce a worthwhile performance improvement.
Google has chosen a register based VM for its Android platform. While licensing issues may have been a consideration, there are a number of technical advantages to this decision:
- A register VM is likely to have an intrinsic performance advantage over a stack VM when hosted on a pipelined processor.
- Byte code verification is likely to be faster on a register VM (i.e., faster startup times) because stack height integrity checks will be greatly simplified.
- A register VM will be more forgiving of incorrect code (in the VM, generated by the compiler, code corrupted during program transmission or storage attacked by malware) than a stack VM.
Using Coccinelle to match if sequences
I have been using Coccinelle to obtain measurements of various properties of C if and switch statements. It is rare to find a tool that does exactly what is desired, but it is often possible to combine various tools to achieve the desired result.
I am interested in measuring sequences of if-else-if statements and one of the things I wanted to know was how many sequences of a given length occurred. Writing a pattern for each possible sequence was the obvious solution, but what is the longest sequence I should search for? A better solution is to use a pattern that matches short sequences and writes out the position (line/column number) where they occur in the code, as in the following Coccinelle pattern:
@ if_else_if_else @ expression E_1, E_2; statement S_1, S_2, S_3; position p_1, p_2; @@ if@p_1 (E_1) S_1 else if@p_2 (E_2) S_2 else S_3 @ script:python @ expr_1 << if_else_if_else.E_1; expr_2 << if_else_if_else.E_2; loc_1 << if_else_if_else.p_1; loc_2 << if_else_if_else.p_2; @@ print "--- ifelseifelse" print loc_1[0].line, " ", loc_1[0].column, " ", expr_1 print loc_2[0].line, " ", loc_2[0].column, " ", expr_2 |
noting that in a sequence of source such as:
if (x == 1) stmt_1; else if (x == 2) stmt_2; else if (x == 3) stmt_3; |
the tokens if (x == 2) will be matched twice, the first setting the position metavariable p_2 and then setting p_1. An awk script was written to read the Coccinelle output and merge together adjacent pairs of matches that were part of a longer if-else-if sequence.
The first pattern did not concern itself with the form of the controlling expression, it simply wrote it out. A second set of patterns was used to match those forms of controlling expression I was interested in, but first I had to convert the output into syntactically correct C so that it could be processed by Coccinelle. Again awk came to the rescue, converting the output:
--- ifelseifelse 186 2 op == FFEBLD_opSUBRREF 191 7 op == FFEBLD_opFUNCREF --- ifelseifelse 1094 3 anynum && commit 1111 8 ( c [ colon + 1 ] == '*' ) && commit |
into a separate function for each matched sequence:
void f_1(void) { // --- ifelseifelse /* 186 2 */ op == FFEBLD_opSUBRREF ; /* 191 7 */ op == FFEBLD_opFUNCREF ; } void f_2(void) { // --- ifelseifelse /* 1094 3 */ anynum && commit ; /* 1111 8 */ ( c [ colon + 1 ] == '*' ) && commit ; } |
The Coccinelle pattern:
@ if_eq_1 @ expression E_1; constant C_1, C_2; position p_1, p_2; @@ E_1 == C_1@p_1 ; E_1 == C_2@p_2 ; @ script:python @ expr_1<< if_eq_1.E_1; const_1 << if_eq_1.C_1; const_2 << if_eq_1.C_2; loc_1 << if_eq_1.p_1; loc_2 << if_eq_1.p_2; @@ print loc_1[0].line, " ", loc_1[0].column, " 3 ", expr_1, " == ", const_1 print loc_2[0].line, " ", loc_2[0].column, " 2 ", expr_1, " == ", const_2 |
matches a sequence of two statements which consist of an expression being compared for equality against a constant, with the expression being identical in both statements. Again positions were written out for post-processing, i.e., joining together matched sequences.
I was interested in any sequence of if-else-if that could be converted to an equivalent switch-statement. Equality tests against a constant is just one form of controlling expression that meets this requirement, another is the between operation. Separate patterns could be written and run over the generated C source containing the extracted controlling expressions.
Breaking down the measuring process into smaller steps reduced the amount of time needed to get a final result (with Coccinelle 0.1.19 the first pattern takes round 70 minutes, thanks to Julia Lawall‘s work to speed things up, an overhead that only has to occur once) and allows the same controlling expression patterns to be run against the output of both the if-else-if and if-if patterns.
At the end of this process I ended up with a list information (line numbers in source code and form of controlling expression) on if-statement sequences that could be rewritten as a switch-statement.
GLR parsing is the future
Traditionally parser generators have required that their input grammar be LALR(1) or some close variant (I would include LL(1) in this set). Back when 64k was an unimaginably large amount of memory being able to squeeze parser tables in a few kilobytes was very important; people received PhDs on parser table compression.
There is still a market for compact, fast parsers. Formal language grammars abound in communication protocols and vendors of communications hardware are very interested in keeping down costs by using minimizing the storage needed by their devices.
The trouble with LALR(1) is that value 1. It means that the parser only looks ahead one token in the input stream. This often means that a grammar is flagged as being ambiguous (i.e., it contains shift/reduce or reduce/reduce conflicts) when it is actually just locally ambiguous, i.e., reading tokens further head on the input stream would provide sufficient context to unambiguously specify the appropriate grammar production.
Restructuring a grammar to make it LALR(1) requires a lot of thought and skill and inexperienced users often give up. I once spent a month trying to remove the conflicts in the SQL/2 grammar specified by the SQL ISO standard; I managed to get the number down from over 1,000 to a small number that I decided I could live with.
It has taken a long time for parser generators to break out of the 64k mentality, but over the last few years it has started to happen. There have been two main approaches: 1) LR(n) provides a mechanism to look further ahead than one token, ie,
I think that GLR parsing is the future for two reasons:
- It is supported by the most widely used parser generator, bison.
- It enables working parsers to be created with much less thought and effort than a LALR(1) parser. (I don’t know how it compares against LR(n)).
GLR parsers resolve any language ambiguities by effectively delaying decisions until runtime in the hope that reading enough tokens will resolve local ambiguities. If an ambiguity in the token stream cannot be resolved a runtime error occurs (this is the one big downside of a GLR parser, the parser generated by a LALR(1) parser generator may produce lots of build time warnings but never produces errors when the parser is executed).
One example of a truly ambiguous construct (discussed here a while ago) is:
x * y; |
which in C/C++ could be a declaration of y to be a pointer to x, or an expression that multiplies x and y.
Tools that can detect these global ambiguities in a grammar are starting to appear, e.g., DTWA is a bison extension.
I reviewed an early draft of the new O’Reilly book “flex & bison” and tried to get the author to be more upbeat on GLR support in bison; I think I got him to be a bit less cautious.
To if-else-if or if-if, that is the question
I am currently measuring if-statements, occurring in visible source, that might be mapped to an equivalent switch-statement. The most obvious usage to look for is a sequence of if-else-if statements that all involve the same expression being tested against an integer constant, as in
if (x == 1) stmt_1; else if (x == 2) stmt_2; else if (x == 3) stmt_3; |
Another possible sequence is:
if (x == 1) stmt_1; if (x == 2) stmt_2; if (x == 3) stmt_3; |
provided all but the last conditionally executed arms do not change the value of the common control variable (e.g., x).
I started to wonder about what would cause a developer to chose one of these forms over the other. Perhaps the if-if form would be used when it was obvious that the common conditional variable was not modified in the conditionally executed arm. This would imply that there would be more statements in the arms of if-else-if sequences than if-if sequences. The following plot of percentage occurrence (over all detected if-else-if/if-if forms) of line number difference between pars of associated if-statements (e.g., when the controlling expression occurs on line
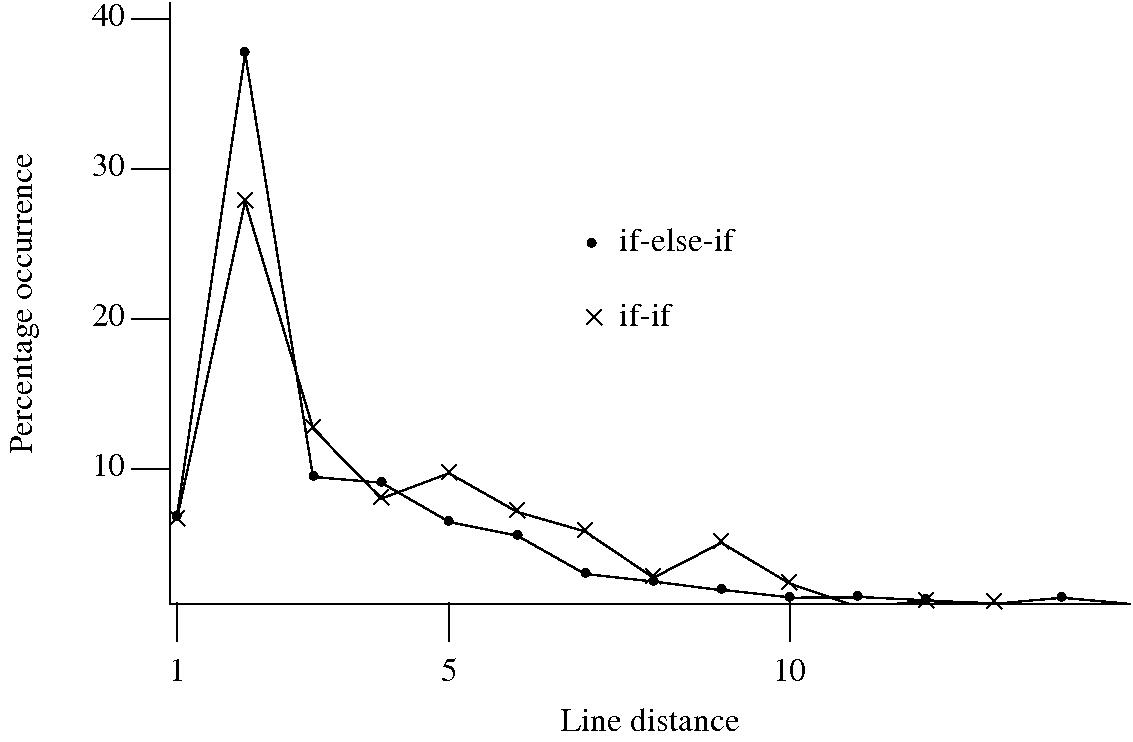
Just over a quarter of the arms contain a single statement (or to be exact the code is contained on a single line); this suggests that when using the if-else-if form most developers put the else and if on the same line. At the next distance along the percentage of if-else-if forms is twice as great as the if-if, probably because of else and if appearing on separate lines (as in the introductory example) in one case and less frequently a comment/blank line in the other. Next along, why the big increase in if-if forms? A comment + blank line, or perhaps no comment or blank line but the use of curly brackets (this is too off the track of where I am supposed to be going to investigate).
This morning I realized why the original plot did not look right, one of the data sets was a way off adding to 100%. An updated version has been uploaded.
It turns out that a single statement (or at least a single line) is more common in the if-else-if form, the opposite of what I had expected. At slightly larger distances there are still differences that can be attributed to else and if appearing on separate lines, curly brackets and a comment/blank line, but the effect is not as large as seen in the original, less accurate, plot.
I have a feeling that I ought to say something about the if-else-if form being preferred to the if-if form. One of the forms will have its behavior changed if the common control variable is modified in one of its arms. But is this an intended or unintended behavior? What is the typical characteristic usage of a common control variable, e.g., do they tend to be accessed but not modified in a given function definition? At the moment I see no obvious cost or benefit strongly favoring one usage over the other, so I will remain silent on the issue.
Implementing the between operation
What code do developers write to check whether a value lies between two bounds (i.e., a between operation)? I would write (where MIN and MAX might be symbolic names or numeric literals):
if ( x >= MIN && x <= MAX ) |
that is I would check the lowest value first. Performing the test in this order just seems the natural thing to do, perhaps because I live in a culture that writes left to write and a written sequence of increasing numbers usually has the lowest number on the left.
I am currently measuring various forms of if-statement conditional expressions that occur in visible source as part of some research on if/switch usage by developers and the between operation falls within the set of expressions of interest. I was not expecting to see any usage of the form:
if ( x <= MAX && x >= MIN ) |
that is with the maximum value appearing first. The first program measured threw up seven instances of this usage, all with the minimum value being negative and in five cases the maximum value being zero. Perhaps left to right ordering still applied, but to the absolute value of the bounds.
Measurements of the second and subsequent programs threw up instances that did not follow any of the patterns I had dreamt up. Of the 326 between operations appearing in the measured source 24 had what I consider to be the unnatural order. Presumably the developers using this form of between consider it to be natural, so what is their line of thinking? Are they thinking in terms of the semantics behind the numbers (in about a third of cases symbolic constants appear in the source rather than literals) and this semantics has an implied left to right order? Perhaps the authors come from a culture where the maximum value often appears on the left.
Suggestions welcome.
Searching for the source line implementing 3n+1
I have been doing some research on the variety of ways that different developers write code to implement the same specification and have been lucky enough to obtain the source code of approximately 6,000 implementations of a problem based on the 3n+1 algorithm. At some point this algorithm requires multiplying a value by three and adding one, e.g., n=3*n+1;.
While I expected some variation in the coding of many parts of the algorithm I did not expect to see much variation in the n=n*3+1;. I was in for a surprise, the following are some of the different implementations I have seen so far:
n = n + n + n + 1 ;
n += n + n + 1;
n = (n << 1) + n + 1;
n += (n << 1) + 1;
n *= 3; n++;
t = (n << 1) ; n = t + n + 1;
n = (n << 2) - n + 1;
I was already manually annotating the source and it was easy for me to locate the line implementing
I mentioned this search problem over drinks after a talk I gave at the Oxford branch of the ACCU last week and somebody (Huw ???) suggested that perhaps the code generated by gcc would be the same no matter how 3n+1 was implemented. I could see lots of reasons why this would not be the case, but the idea was interesting and worth investigation.
At the default optimization level the generated x86 code is different for different implemenetations, but optimizing at the “-O 3” level results in all but one of the above expressions generating the same evaluation code:
leal 1(%rax,%rax,2), %eax |
The exception is (n << 2) - n + 1 which results in shift/subtract/add. Perhaps I should report this as a bug in gcc :-)
I was surprised that gcc exhibited this characteristic and I plan to carry out more tests to trace out the envelope of this apparent "same generated code for equivalent expressions" behavior of gcc.
Will language choice converge to a few?
Will the number of commonly used programming languages converge to a few that remain commonly used for ever, will there be many relatively common languages in use, or will the (relatively) commonly used languages change over time?
There are plenty of advantages to having one programming language that everybody uses for ever. English+local dialects seems to be heading towards becoming the World’s one native language, but the programming language world seems to be moving in the direction of diversification and perhaps even experiencing changing popularity of those in common use.
What are the forces that drive programing language usage?
Existing code. If a company wants to maintain and update its software products it needs to hire people to use the language they are written in. This is a force that maintains the status quo.
Existing programmer skills. When given the task of writing new software where language usage is not specified, developers are likely to pick a language they already know. In the case of group development the choice is made by group leaders. This is a force that maintains the status quo.
Fashion. Every field has fashions and programming language usage is no exception. Using a particular language can be seen as sexy, leading-edge, innovative, the next big-thing, etc. Given the opportunity some developers will chose to learn and write code in this language.
Desire to learn a new language. Some developers like to learn new things and this includes programming languages. Given the opportunity such developers will sometimes chose to learn and write code in a language they find interesting.
The cost of creating and implementing a new language continues to be within the reach of one individual who is willing to invest the considerable effort required. Hundreds, if not thousands of new languages have been created every year almost since computers were first invented. The only change here over the last 40 years is probably an increase in the number of new languages.
What has changed in the last 15 years is ease of transmission (e.g., a ubiquitous computing platform and the Internet) and the growth of the fashion industry (e.g., book publishers).
Computing is bathed in newness. New products, new chips, new gadgets, new software, new features, new and improved, the latest. What self respecting developer would want to be caught dead using a language invented before they were born?
Publishers need a continuous stream of new subjects that will drive customers to buy books. What better subject than a hot new programming language?
At the moment we seem to be living through a period of programming language usage divergence. Will this evolutionary trend continue or are we currently in the Cambrian explosion period of software engineering evolution?
What are the forces acting against the use of new languages? At the moment the only significant forces acting against the use of new languages are existing source and existing developer expertise. There are weaker forces, for instance, the worry that in the years to come it will be difficult to find developers to maintain existing software written in what has become an obscure language, but most software has a short lifetime and in many application domains this is not an issue. Whether the fashion for newness will eventually diminish enough to significantly slow the take-up of new languages remains to be seen.
Dimensional analysis of source code
The idea of restricting the operations that can be performed on a variable based on attributes appearing in its declaration is actually hundreds of years old and is more widely known as dimensional analysis. Readers are probably familiar with the concept of type checking where, for instance, a value having a floating-point type is not allowed to be added to a value having a pointer type. Unfortunately, many of those computer languages that support the functionality I am talking about (e.g., Ada) also refer to it as type checking and differentiate it from the more common usage by calling it strong typing. The concept would be much easier for people to understand if a different term were used, e.g., unit checking or even dimension checking.
Dimensional analysis, as used in engineering and the physical sciences, relies on the fact that quantities are often expressed in terms of a small number of basic attributes, e.g., mass, length and time; velocity is calculated by dividing a length by a time,  and area is calculated by multiplying two lengths,
and area is calculated by multiplying two lengths,  . Adding a length quantity to a velocity has no physical meaning and suggests that something is wrong with the calculation, while dividing velocity by time,
. Adding a length quantity to a velocity has no physical meaning and suggests that something is wrong with the calculation, while dividing velocity by time,  , can be interpreted as acceleration. Dividing two quantities that have the same units results in what is known as a dimensionless number.
, can be interpreted as acceleration. Dividing two quantities that have the same units results in what is known as a dimensionless number.
Dimensional analysis can be used to check a calculation involving physical quantities for internal consistency and as a method for trying to deduce the combinations of quantities that an unknown equation might contain based on the physical units the result is known to be represented in.
The frink language has units of measure checking built into it.
How might dimensional analysis be used to check source code for internal consistency? Consider the following code:
x = a / b; c = a; y = c / b; if (x + y ... ... z = x + b; |
c is assigned a‘s value and is therefore assumed to have the same units of measurement. The value assigned to y is calculated by dividing c by b and the train of reasoning leading to the assumption that it has the same units of measurement as x is easy to follow. Based on this analysis, there is nothing suspicious about adding x and y, but adding x and b looks wrong (it would be perfectly ok if all of the variables in this code were dimensionless).
A number of tools have been written to check source code expressions for internal consistency e.g., Fortran (Automated computation and consistency checking of physical dimensions and units in scientific programs), C++ (Applied Template Metaprogramming in SI units) and C (Annotation-less Unit Type Inference for C), but so far only one PhD.
Providing a mechanism for developers to add unit information to variable declarations would enable compilers to perform consistency checks and reduce the likelihood of false positives being reported (because dimensionless values can generally be combined in any way). It is too late in the day for such a major feature to be added to the next revision of the C++ standard; the C standard is also being revised, but the committee is currently being very conservative and insists that any proposed new constructs already be implemented in at least one compiler.
Recent Comments