Archive
Predicted impact of LLM use on developer ecosystems
LLMs are not going to replace developers. Next token prediction is not the path to human intelligence. LLMs provide a convenient excuse for companies not hiring or laying off developers to say that the decision is driven by LLMs, rather than admit that their business is not doing so well
Once the hype has evaporated, what impact will LLMs have on software ecosystems?
The size and complexity of software systems is limited by the human cognitive resources available for its production. LLMs provide a means to reduce the human cognitive effort needed to produce a given amount of software.
Using LLMs enables more software to be created within a given budget, or the same amount of software created with a smaller budget (either through the use of cheaper, and presumably less capable, developers, or consuming less time of more capable developers).
Given the extent to which companies compete by adding more features to their applications, I expect the common case to be that applications contain more software and budgets remain unchanged. In a Red Queen market, companies want to be perceived as supporting the latest thing, and the marketing department needs something to talk about.
Reducing the effort needed to create new features means a reduction in the delay between a company introducing a new feature that becomes popular, and the competition copying it.
LLMs will enable software systems to be created that would not have been created without them, because of timescales, funding, or lack of developer expertise.
I think that LLMs will have a large impact on the use of programming languages.
The quantity of training data (e.g., source code) has an impact on the quality of LLM output. The less widely used languages will have less training data. The table below lists the gigabytes of source code in 30 languages contained in various LLM training datasets (for details see The Stack: 3 TB of permissively licensed source code by Kocetkov et al.):
Language TheStack CodeParrot AlphaCode CodeGen PolyCoder HTML 746.33 118.12 JavaScript 486.2 87.82 88 24.7 22 Java 271.43 107.7 113.8 120.3 41 C 222.88 183.83 48.9 55 C++ 192.84 87.73 290.5 69.9 52 Python 190.73 52.03 54.3 55.9 16 PHP 183.19 61.41 64 13 Markdown 164.61 23.09 CSS 145.33 22.67 TypeScript 131.46 24.59 24.9 9.2 C# 128.37 36.83 38.4 21 GO 118.37 19.28 19.8 21.4 15 Rust 40.35 2.68 2.8 3.5 Ruby 23.82 10.95 11.6 4.1 SQL 18.15 5.67 Scala 14.87 3.87 4.1 1.8 Shell 8.69 3.01 Haskell 6.95 1.85 Lua 6.58 2.81 2.9 Perl 5.5 4.7 Makefile 5.09 2.92 TeX 4.65 2.15 PowerShell 3.37 0.69 FORTRAN 3.1 1.62 Julia 3.09 0.29 VisualBasic 2.73 1.91 Assembly 2.36 0.78 CMake 1.96 0.54 Dockerfile 1.95 0.71 Batchfile 1 0.7 Total 3135.95 872.95 715.1 314.1 253.6 |
The major companies building LLMs probably have a lot more source code (as of July 2023, the Software Heritage had over  unique source code files); this table gives some idea of the relative quantities available for different languages, subject to recency bias. At the moment, companies appear to be training using everything they can get their hands on. Would LLM performance on the widely used languages improve if source code for most of the 682 languages listed on Wikipedia was not included in their training data?
unique source code files); this table gives some idea of the relative quantities available for different languages, subject to recency bias. At the moment, companies appear to be training using everything they can get their hands on. Would LLM performance on the widely used languages improve if source code for most of the 682 languages listed on Wikipedia was not included in their training data?
Traditionally, developers have had to spend a lot of time learning the technical details about how language constructs interact. For the first few languages, acquiring fluency usually takes several years.
It’s possible that LLMs will remove the need for developers to know much about the details of the language they are using, e.g., they will define variables to have the appropriate type and suggest possible options when type mismatches occur.
Removing the fluff of software development (i.e., writing the code) means that developers can invest more cognitive resources in understanding what functionality is required, and making sure that all the details are handled.
Removing a lot of the sunk cost of language learning removes the only moat that some developers have. Job adverts could stop requiring skills with particular programming languages.
Little is currently known about developer career progression, which means it’s not possible to say anything about how it might change.
Since they were first created, programming languages have fascinated developers. They are the fashion icon of software development, with youngsters wanting to program in the latest language, or at least not use the languages used by their parents. If developers don’t invest in learning language details, they have nothing language related to discuss with other developers. Programming languages will cease to be a fashion icon (cpus used to be a fashion icon, until developers did not need to know details about them, such as available registers and unique instructions). Zig could be the last language to become fashionable.
I don’t expect the usage of existing language features to change. LLMs mimic the characteristics of the code they were trained on.
When new constructs are added to a popular language, it can take years before they start to be widely used by developers. LLMs will not use language constructs that don’t appear in their training data, and if developers are relying on LLMs to select the appropriate language construct, then new language constructs will never get used.
By 2035 things should have had time to settle down and for the new patterns of developer behavior to be apparent.
Impact of developer uncertainty on estimating probabilities
For over 50 years, it has been known that people tend to overestimate the likelihood of uncommon events/items occurring, and underestimate the likelihood of common events/items. This behavior has replicated in many experiments and is sometimes listed as a so-called cognitive bias.
Cognitive bias has become the term used to describe the situation where the human response to a problem (in an experiment) fails to match the response produced by the mathematical model that researchers believe produces the best output for this kind of problem. The possibility that the mathematical models do not reflect the reality of the contexts in which people have to solve the problems (outside of psychology experiments), goes against the grain of the idealised world in which many researchers work.
When models take into account the messiness of the real world, the responses are a closer match to the patterns seen in human responses, without requiring any biases.
The 2014 paper Surprisingly Rational: Probability theory plus noise explains biases in judgment by F. Costello and P. Watts (shorter paper), showed that including noise in a probability estimation model produces behavior that follows the human behavior patterns seen in practice.
If a developer is asked to estimate the probability that a particular event,  , occurs, they may not have all the information needed to make an accurate estimate. They may fail to take into account some s, and incorrectly include other kinds of events as being s. This noise,
, occurs, they may not have all the information needed to make an accurate estimate. They may fail to take into account some s, and incorrectly include other kinds of events as being s. This noise,  , introduces a pattern into the developer estimate:
, introduces a pattern into the developer estimate:
*P_E + N*(1-P_E)=(1-2N)*P_E+N")
where:  is the developer’s estimated probability of event occurring,
is the developer’s estimated probability of event occurring,  is the actual probability of the event, and is the probability that noise produces an incorrect classification of an event as
is the actual probability of the event, and is the probability that noise produces an incorrect classification of an event as  or (for simplicity, the impact of noise is assumed to be the same for both cases).
or (for simplicity, the impact of noise is assumed to be the same for both cases).
The plot below shows actual event probability against developer estimated probability for various values of , with a red line showing that at  , the developer estimate matches reality (code):
, the developer estimate matches reality (code):

The effect of noise is to increase probability estimates for events whose actually probability is less than 0.5, and to decrease the probability when the actual is greater than 0.5. All estimates move towards 0.5.
What other estimation behaviors does this noise model predict?
If there are two events, say  and
and  , then the noise model (and probability theory) specifies that the following relationship holds:
, then the noise model (and probability theory) specifies that the following relationship holds:
+P(B) == P(A & B)+P(A delim{|}{B}{})")
where: ") denotes the probability of its argument.
denotes the probability of its argument.
The experimental results show that this relationship does hold, i.e., the noise model is consistent with the experiment results.
This noise model can be used to explain the conjunction fallacy, i.e., Tversky & Kahneman’s famous 1970s “Lindy is a bank teller” experiment.
What predictions does the noise model make about the estimated probability of experiencing  (
( ) occurrences of the event in a sequence of
) occurrences of the event in a sequence of  assorted events (the previous analysis deals with the case
assorted events (the previous analysis deals with the case  )?
)?
An estimation model that takes account of noise gives the equation:

where:  is the developer’s estimated probability of experiencing s in a sequence of length , and
is the developer’s estimated probability of experiencing s in a sequence of length , and  is the actual probability of there being .
is the actual probability of there being .
The plot below shows actual event probability against developer estimated probability for various values of , with a red line showing that at , the developer estimate matches reality (code):

This predicted behavior, which is the opposite of the case where , follows the same pattern seen in experiments, i.e., actual probabilities less than 0.5 are decreased (towards zero), while actual probabilities greater than 0.5 are increased (towards one).
There have been replications and further analysis of the predictions made by this model, along with alternative models that incorporate noise.
To summarise:
When estimating the probability of a single event/item occurring, noise/uncertainty will cause the estimated probability to be closer to 50/50 than the actual probability.
When estimating the probability of multiple events/items occurring, noise/uncertainty will cause the estimated probability to move towards the extremes, i.e., zero and one.
A process to find and extract data-points from graphs in pdf files
Ever since I discovered that it’s sometimes possible to extract the x/y values of the points/circles/diamonds appearing in a graph, within a pdf, I have been trying to automate the process.
Within a pdf there are two ways of encoding an image, such as the one below. The information can be specified using a graphics image format (e.g., jpeg, png, or svg), or it can be specified using a sequence of pdf’s internal virtual machine instructions.

After spotting an interesting graph containing data points, when reading a paper, the quickest way to find out whether the image is embedded in the pdf as an image file (the most common case) is to run pdfcpu (using the options extract -m image). If the graph is not contained in the image files extracted by pdfcpu, it may have been created using internal pdf commands (or be a format not yet support by pdfcpu).
Until recently, finding the sequence of internal pdf instructions used to visualise a particular graph was a tedious process. A few months ago, I discovered the tool pdfsyntax, which has an option to convert the pdf internals into a html page containing links between the various components (making it easy to go to a particular page and view the contents). However, pdfsyntax is still new, i.e., it regularly fails to convert a pdf file.
As distributed, pdf files are compressed. They can be converted to readable form using the command qpdf –stream-data=uncompress (images remain in their respective binary format). To locate the instructions that generate a graph, I search for a sequence of 3-4 characters appearing close to the graph in the displayed text (it is difficult to predict how words will be split for layout purposes, within a pdf). The instructions that generate the graph may appear later in the uncompressed file, with a named reference to these instructions appearing around this text (i.e., a pdf function call). LLM’s are great at describing the behavior of sequences of pdf instructions.
Why not grep uncompressed pdf files to find those containing the instructions used to generate graphs?
Surprisingly, apps that produce pdf files use a myriad of different instruction sequences to draw circles, diamonds, pluses, etc. While there is a pdf instruction to draw a circle, the most common technique uses four Bézier curves to draw each quadrant of a circle; a colored circle might be drawn by filling a specified area with a chosen color. The plus (+) symbol is sometimes drawn as a vertical line followed by a horizontal line (or the other order), and sometimes all the vertical lines are drawn followed by all the horizontal lines. Diamonds are created using four angled lines.
Fewer combinations of instructions are used to draw the values associated with the axis ticks, e.g., 10, 20, 30, etc.
The output from my script that searches pdf files for possible extractable data lists the line numbers of possible data points and possible tick labels, along with the totals for each. A graph will usually contain many points and 10+ labels. Lower totals usually suggest incidental matches.
If an appropriate instruction sequence is found, it is copied to a file, and a bespoke awk script (usually an edited version of a previous script) extracts the numeric values within the reference frame of the graph axis bounds. This extraction process first calculates the x/y coordinates of the center of the circle/diamond/plus, in the pdf frame, then calculates the x/y coordinates of the axis tick marks, in the pdf frame, then maps the x/y data points to the axis frame.
I’m not expecting the extraction of numeric values to have any degree of automation anytime soon. But then, this problem would make a great challenge for LLM coding apps…
When a graph is specified using an image format, WebPlotDigitizer is the extraction tool of choice.
After 55.5 years the Fortran Specialist Group has a new home
In the 1960s and 1970s, new developments in Cobol and Fortran language standards and implementations regularly appeared on the front page of the weekly computer papers (Algol 60 news sometimes appeared). Various language user groups were created, which produced newsletters and held meetups (this term did not become common until a decade or two ago).
In January 1970 the British Computer Society‘s Fortran Specialist Group (FSG) held its first meeting and 55.5 years later (this month) this group has moved to a new parent organization the Society of Research Software Engineering. The FSG is distinct from BSI‘s Fortran Standards panel and the ISO Fortran working group, although they share a few members.
I believe that the FSG is the oldest continuously running language user group. Second place probably goes to the ACCU (Association on C and C++ Users) which was started in the late 1980s. Like me, both of these groups are based in the UK (the ACCU has offshoots in other countries). I welcome corrections from readers familiar with the language groups in other countries (there were many Pascal user groups created in the 1980s, but I don’t know of any that are still active). COBOL is a business language, and I have never seen a non-vendor meetup group that got involved with language issues.
The plot below shows estimated FSG membership numbers for various years, averaging 180 (thanks to David Muxworthy for the data; code+data):

My experience of national user groups is that membership tends to hover around a thousand. Perhaps the more serious, professional approach of the BCS deters the more casual members that haunt other user groups (whose membership fees help keep things afloat).
What are the characteristics of this Fortran group that have given it such a long and continuous life?
- It was started early. Fortran was one of the first, of two (perhaps three), widely used programming languages,
- Fortran continued to evolve in response to customer demand, which made it very difficult for new languages to acquire a share of Fortran’s scientific/engineering market. Compiler vendors have kept up, or at least those selling to high-end power customers have (the Open source Fortran compilers have lagged well behind).
Most developers don’t get involved with calculations using floating-point values, and so are unfamiliar with the multitude of issues that can have a significant impact on program output, e.g., noticeably inaccurate results. The Fortran Standard’s committee has spent many years making it possible to write accurate, portable floating-point code.
A major aim of the 1999 revision of the C Standard was to make its support for floating-point programming comparable to Fortran, to entice Fortran developers to switch to C,
- people being willing to dedicate their time, over a long period, to support the activities of this group.
The minutes of all the meetings are available. The group met four times a year until 1993, and then once or twice a year. Extracting (imperfectly) the attendance from the minutes finds around 525540 unique names, with 322350 attending once and one person attending 8155 meetings. The plot below shows the number of people who attended a given number of meetings (code+data):

The survival of any group depends on those members who turn up regularly and help out. The plot below shows a sorted list of FSG member tenure, in years, excluding single attendance members (code+data):

Will the FSG live on for another 55 years at the Society of Research Software Engineering?
Fortran continues to be used in a wide range of scientific/engineering applications. There is a lot of Fortran source out there, but it’s not a fashionable language and so rarely a topic of developer conversation. A group only lives because some members invest their time to make things happen. We will have to wait and see if this transplanted groups attracts a few people willing to invest in it.
Update the next day. Added attendance from pdf minutes, and removed any middle initials to improve person matching.
Why is actual implementation time often reported in whole hours?
Estimates of the time needed to implement a software task are often given in whole hours (i.e., no minutes), with round numbers being preferred. Surprisingly, reported actual implementation times also share this ‘preference’ for whole hours and round numbers (around a third of short task estimates are accurate, so it is to be expected that around a third of actual implementation times will be some number of whole hours, at least for the small percentage of projects that record task implementation time).
Even for accurate estimates, some variation in minutes around the hour boundary is to be expected for the actual implementation time. Why are developers reporting integer hour values for actual time?
The following are some of the possible reasons, two at opposite ends of the spectrum, for developers to log actual time as an integer number of hours:
- Parkinson’s law, i.e., the task was completed earlier and the minutes before the whole hour were filled with other activities,
- striving to complete a task by the end of the hour, much like a marathon runner strives to complete a race on a preselected time boundary,
- performing short housekeeping tasks once the primary task is complete, where management is aware of this overhead accounting.
Is it possible to distinguish between these developer behaviors by analysing many task durations?
My thinking is that all three of these practices occur, with some developers having a preference for following Parkinson’s law, and a few developers always striving to get things done.
Given that Parkinson’s law is 70 years old and well known, there ought to be a trail of research papers analysing a variety of models.
Parkinson specified two ‘laws’. The less well known second law, specifies that the number of bureaucrats in an organization tends to grow, regardless of the amount of work to be done. Governments and large organizations publish employee statistics, and these have been used to check Parkinson’s second law.
With regard to Parkinson’s first law, there are papers whose titles suggest that something more than arm waving is to be found within. Sadly, I have yet to find a non-arm waving paper. Given the extreme difficulty of obtaining data on task durations, this lack of papers is not surprising.
Perhaps our LLM overlords, having been trained on the contents of the Internet, will succeed where traditional search engines have failed. The usual suspects (Grok, ChatGPT, Perplexity and Deepseek) suggested various techniques for fitting models to data, rather than listing existing models.
A new company, Kimi, launched their highly-rated model yesterday, and to try it out I asked: “Discuss mathematical models that analyse the impact of project staff following Parkinson’s law”. The quality of the reply was impressive (my registration has not yet been accepted, so I cannot obtain a link to Kimi’s response). A link to Grok 3’s evaluation of Kimi’s five suggested modelling techniques.
Having spent a some time studying the issues of integer hour actual times, I have not found a way to distinguish between the three possibilities listed above, using estimate/actual time data. Software development involves too many possible changeable activities to be amenable to Taylor’s scientific management approach.
Good luck trying to constrain what developers can do and when they can do it, or requiring excessive logging of activities, just to make it possible to model the development process.
When task time measurements are not reported by developers
Measurements of the time taken to complete a software development task usually rely on the values reported by the person doing the work. People often give round number answers to numeric questions. This rounding has the effect of shifting start/stop/duration times to 5/10/15/20/30/45/60 minute boundaries.
To what extent do developers actually start/stop tasks on round number time boundaries, or aim to work for a particular duration?
The ABB Dev Interaction Data contains 7,812,872 interactions (e.g., clicking an icon) with Visual Studio by 144 professional developers performing an estimated 27,000 tasks over about 28,000 hours. The interaction start/stop times were obtained from the IDE to a 1-second resolution.
Completing a task in Visual Studio involves multiple interactions, and the task start/end times need to be extracted from each developer’s sequence of interactions. Looking at the data, rows containing the File.Exit message look like they are a reliable task-end delimiter (subsequent interactions usually happen many minutes after this message), with the next task for the corresponding developer starting with the next row of data.
Unfortunately, the time between two successive interactions is sometimes so long that it looks as if a task has ended without a File.Exit message being recorded. Plotting the number of occurrences of time-gaps between interactions (in minutes) suggests that it’s probably reasonable to treat anything longer than a 10-minute gap as the end of a task.
The plot below shows the number of tasks having a given duration, based on File.Exit, or using an 11-minute gap between interactions (blue/green) to indicate end-of-task, or a 20-minute gap (red; code+data):

The very prominent spikes in task counts at round numbers, seen in human reported times, are not present. The pattern of behavior is the same for both 11/20-minute gaps. I have no idea why there is a discontinuity at 10 minutes.
A development task is likely to involve multiple VS tasks. Is the duration of multiple VS tasks more likely to sum to a round number than a nonround number? There is no obvious reason why they should.
Is work on a VS task more likely to start/end at a round number time than a nonround number time?
Brief tasks are likely to be performed in the moment, i.e., without regard to clock time. Perhaps developers pay attention to clock time when tasks are expected to take some time.
The plot below shows the number of tasks taking at least 10-minutes that are started at a given number of minutes past the hour (blue/green), with red pluses showing 5-minute intervals (code+data):

No spikes in the count of tasks at round number start times (no spikes in the end times either; code+data).
Why spend time looking for round numbers where they are not expected to occur? Publishing negative results is extremely difficult, and so academics are unlikely to be interested in doing this analysis (not that software engineering researchers have shown any interest in round number usage).
An attempt to shroud text from LLMs
Describe the items discussed in the following sentences: “phashyon es cycklyq. chuyldren donth wanth tew weywr chloths vat there pairent weywr. pwroggwrammyng languij phashyon hash phricksionz vat inycially inqloob impleementaision suppoort, lybrareyz (whych sloa doun adopsion, ant wunsh establysht jobz ol avaylable too suppourt ecksysting kowd (slowyng doun va demighz ov a langguij).”
I was at the {Tech: Europe} hackathon yesterday, and my ‘inspired’ idea was to transform sentences such that while people could (eventually) still understand them, LLMs would fail miserably.
My team-mates from the last hackathon applied too late to be accepted, pitching the idea to people without a team failed to convince anyone to join me, and the idea pitches I heard did not convince me to join someone else.
Many years ago, I implemented a sounds like tool, which generates character sequences that an English reader would recognise (perhaps slowly) as sounding like the input word (also used in a previous hack). Surely, replacing every word in a sentence with a randomly chosen sounds-like character sequence would seriously confuse LLMs (wrapper code around sounds like tool).
My ‘inspired’ idea failed hard with: Grok, ChatGPT, Deepseek (no sharable link), and Perplexity.
Grok’s response yesterday (this recent response does not begin by giving the corrected sentence):
The sentences provided contain numerous typographical errors, making them challenging to interpret. However, by correcting the likely typos, the intended meaning can be inferred as follows: Corrected Sentences: "Fashion is cyclical. Children don’t want to wear clothes that their parents wore. Programming language fashion has frictions that initially include implementation support, libraries (which slow down adoption), and once established, jobs are available to support existing code (slowing down the demise of a language)." |
Time to do some pivoting, with options including:
- Update source-like tool. LLMs operate on tokens, which are short common character sequences, which may or may not be complete words. The sounds-like tool could be enhanced to be token aware, and attempt to change all tokens within a word. While the tokenization sequence list varies between LLMs, I assume that most, say, 10,000 common character sequences are always treated as tokens. The list of GPT2 tokens is available.
- Narrow the use case. Anybody monitoring text messages will want to keep costs down by using as small a model as possible, and will likely want to keep the text in-house. Check the ability of small models to handle sounds-like sentences.
- Add non-sounds-like changes. For instance, adding underscores, changing some letters to upper case, and changing ‘l’ to the number ‘1’.
With only a few hours available (this was essentially an afternoon hack), I opted to investigate the performance of small models.
Below is the edited output (‘…’ indicates further text was generated) of models containing 14.8, 8.29, 4.02, 2.03 billion parameters. These Open weights models ran under LM Studio on my local machine (which does not have a GPU, so the response is sluuuugish).
I was surprised at how well the models performed, particularly the 4.02B parameter reasoning model. The responses did not start to go wrong until the model size was reduced to 2 billion parameters. We will have to wait and see if tiny models continue to improve, such that a model containing under a billion parameters can reliably interpret sounds-like sentences.
I’m still clinging to the possibility that sentences can be modified such that humans can understand them, but LLMs cannot (AGI, which LLMs are not close to achieving, will by definition have human level ability).
deepseek-r1-distil-qwen-14b has 14.8B parameters and is currently a leading model at this size. Its response was:
The sentences discuss several items:
Fashion Cycles: The first sentence appears to suggest that fashion (phashyon)
is cyclic (cycklyq), meaning it follows repeating trends or cycles.
Children's Preferences for Clothing: The second sentence discusses children
not wanting to wear the same clothes as their parents, implying a
generational difference in fashion preferences.
Programming Language Trends and Challenges:
o The third sentence talks about programming languages (pwroggwrammyng languij)
having fads or trends (phashyon hash phricksionz), which are initially
implemented but can slow down adoption due to libraries taking time to develop.
o It also mentions that these fads may eventually lead to the decline of
existing codebases (ecksysting kowd) because they become outdated or unsupported.
Overall, the sentences touch on fashion trends, generational differences in
clothing preferences, and challenges related to programming language adoption
and maintenance.
2.68 tok/sec • 826 tokens • 29.94s to first token |
Perhaps vision models will not be as proficient with this kind of text. Qwen2.5-VL-7B-Instruct is an 8.29B parameter vision model.
The sentences you've provided appear to be a mix of misspelled and jumbled words, making it challenging to understand the intended meaning. However, I'll attempt to interpret them based on common themes in technology and programming. 1. "phashyon es cycklyq." - This seems to be an incomplete or corrupted phrase that might refer to something related to fashion being cyclical. 2. "chuyldren donth wanth tew weywr chloths vat there pairent weywr." - This appears to be a misspelled and jumbled sentence, possibly referring to children not wanting to wear clothes their parents wore when they were young. 3. "pwroggwrammyng languij phashyon hash phricksionz vat inycially inqloob impleementaision suppoort." - This phrase seems to be discussing programming languages and the friction or challenges associated with implementing initial support for new features or functionalities within these languages. 4. "lybrareyz (whych sloa doun adopsion, ant wunsh establysht jobz ol avaylable too suppourt ecksysting kowd (slowyng doun va demighz ov a langguij)" - This part appears to be discussing libraries that slow down adoption and the desire for established jobs or roles available to support existing code, which in turn slows down development of languages. In summary: ... 4.06 tok/sec • 392 tokens • 13.46s to first token |
Qwen3-4b is a 4.02B parameter model with reasoning abilities:
Thought for 2 minutes 47 seconds The sentences discuss two main topics: 1. A Metaphorical Observation: "Children don’t want to wear clothes their parents wear." This is a metaphorical statement suggesting that individuals (e.g., developers) may resist adopting technologies or practices that are inherited from older generations (e.g., legacy code, outdated programming languages). It highlights a generational or cultural resistance to following established norms. 2. Technical Discussion on Programming Languages and Libraries: "Programming languages have features initially included in implementation support, libraries that slow down adoption and establish jobs for existing code, slowing the decline of a language." This refers to: o Programming Language Features: Some programming languages include built-in support for specific functionalities (e.g., syntax, tools) that are essential for development. o Libraries and Ecosystems: Libraries or frameworks in a programming language can influence adoption by providing tools that simplify tasks. However, if these libraries become outdated or complex, they may slow down the adoption of newer versions of the language. o Maintenance and Decline: The text suggests that maintaining compatibility with existing code (e.g., legacy systems) can help sustain a programming language, even as newer technologies emerge. This creates a tension between innovation and backward compatibility. Key Concepts: o Metaphor vs. Technicality: The first part uses a metaphor to illustrate resistance to inherited practices, while the second part delves into technical aspects of software development. o Language Evolution: The discussion highlights how programming languages balance innovation (new features) with preservation (supporting existing code), which can affect their longevity and adoption. This interplay between metaphor and technical detail underscores themes of generational change, technological inertia, and the challenges of maintaining compatibility in software ecosystems. 5.59 tok/sec • 1290 tokens • 7.67s to first token |
Qwen3-1.7B is a 2.03B parameter model, i.e., a smaller version of Qwen3-4b used above.
Thought for 1 minutes 8 seconds The sentences discuss several interconnected themes, blending technical and metaphorical elements: 1. Phishing (Cyclic Behavior): The first sentence references "phashyon" (likely a misspelling of "phishing") as cyclic or recurring, suggesting phishing attacks that repeat or evolve over time. 2. Children's Clothing and Parental Influence: A metaphorical statement about children not wanting to wear clothes their parents wear, implying a generational or cultural disconnect in preferences or values. 3. Programming Languages and Technical Concepts: The text introduces complex technical terms: o Phishing Zones (possibly a misinterpretation of "phishing zones" as areas where phishing attacks occur). o Implementation Support and Libraries (e.g., libraries that slow down adoption or require stable ecosystems). o Ecosystems (referring to software or technical environments) and Job Creation in these systems. 4. Adoption and Slowdown: Libraries are described as "slowing down adoption" and "slowly reducing values over a language," suggesting challenges in integrating new technologies or standards. 5. Confusion and Mixed Language Elements: The text contains mixed syntax (e.g., "pwroggwrammyng" → "programming"), mistranslations, and unclear phrasing, likely due to linguistic errors or intentional ambiguity. Key Items Discussed:... 10.32 tok/sec • 1081 tokens • 2.93s to first token |
Thanks to our {Tech: Europe} hosts who kept us fed and watered.
Evolution has selected humans to prefer adding new features
Assume that clicking within any of the cells in the image below flips its color (white/green). Which cells would you click on to create an image that is symmetrical along the horizontal/vertical axis?

In one study, 80% of subjects added a block of four green cells in each of the three white corners. The other 20% (18 of 91 subjects) made a ‘subtractive’ change, that is, they clicked the four upper left cells to turn them white (code+data).
The 12 experiments discussed in the paper People systematically overlook subtractive changes by Adams, Converse, Hales, and Klotz (a replication) provide evidence for the observation that when asked to improve an object or idea, people usually propose adding something rather than removing something.
The human preference for adding, rather than removing, has presumably evolved because it often provides benefits that out weigh the costs.
There are benefits/costs to both adding and removing.
Creating an object:
- may produce a direct benefit and/or has the potential to increase the creator’s social status, e.g., ‘I made that’,
- incurs the cost of time and materials needed for the implementation.
Removing an object may:
- produce savings, but these are not always directly obvious, e.g., simplifying an object to reduce the cost of adding to it later. Removing (aka sacking) staff is an unpopular direct saving,
- generate costs by taking away any direct benefits it provides and/or reducing the social status enjoyed by the person who created it (who may take action to prevent the removal).
For low effort tasks, adding probably requires less cognitive effort than removing; assuming that removal is not a thoughtless activity. Chesterton’s fence is a metaphor for prudence decision-making, illustrating the benefit of investigating to find out if any useful service provided by what appears to be a useless item.
There is lots of evidence that while functionality is added to software systems, it is rarely removed. The measurable proxy for functionality is lines of code. Lots of source code is removed from programs, but a lot more is added.
Some companies have job promotion requirements that incentivize the creation of new software systems, but not their subsequent maintenance.
Open source is a mechanism that supports the continual adding of features to software, because it does not require funding. The C++ committee supply of bored consultants proposing new language features, as an outlet for their creative urges, will not dry up until the demand for developers falls below the supply of developers.
Update
The analysis in the paper More is Better: English Language Statistics are Biased Toward Addition by Winter, Fischer, Scheepers, and Myachykov, finds that English words (based on the Corpus of Contemporary American English) associated with an increase in quantity or number are much more common than words associated with a decrease. The following table is from the paper:
Word Occurrences
add 361,246
subtract 1,802
addition 78,032
subtraction 313
plus 110,178
minus 14,078
more 1,051,783
less 435,504
most 596,854
least 139,502
many 388,983
few 230,946
increase 35,247
decrease 4,791 |
ClearRoute x Le Mans 24h Hackathon 2025
This weekend, Team Awesome (Sam, Frank and yours truly) took part in the [London] ClearRoute x Le Mans 24h Hackathon 2025 (ClearRoute is an engineering consultancy and Le Mans is an endurance-focused sports car race).
London hackathons have been thin on the ground during the last four years. I suspect that the chilling of the economic climate, with the end of the zero interest-rate policy, caused companies to cut back funding for projects whose benefits were rather indirect. Things do seem to be picking up. This is my second hackathon this year, there are two hacks next weekend and one the following weekend.
Based on the title, the theme of the hackathon was obviously the Le Mans 24 hour car race, and we were asked to use ClearRoute’s LLM-based tools to find ways to improve race team performance.
I was expecting the organisers to provide us with interesting race data. After asking about data and hearing the dreaded suggestion, “find some on the internet”, I was almost ready to leave. However, the weekend was rescued by a sudden inspired idea.
My limited knowledge of motorsport racing comes from watching Formula 1 on TV (until the ever-increasing number of regulations created a boring precession), and I remembered seeing teams penalized because they broke an important rule. The rule infringement may have been spotted by a race marshal, or a member of another team, who then reported it to the marshals.
Le Mans attracts 60+ racecars each year, in three categories (each with their own rules document). The numbers for 2025 were 21 Hypercars, 17 LMP2 prototypes, and 24 LMGT3 cars (the 2025 race ran this weekend).
Manually checking the behavior of 60+ cars against a large collection of ever-changing rules is not practical. Having an LLM-based Agent check text descriptions of racing events for rule violations would not only be very cost-effective, but it would also reduce the randomness of somebody happening to be in the right place and time to see an infringement.
This idea now seems obvious, given my past use of LLMs to check software conformance and test generation.
Calling an idea inspired is all well and good, if it works. This being a hackathon, suck-it-and-see is the default response to will it work questions.
One of the LLMs made available was Gemini Flash, which has a 1 million token input context window. The 161 page pdf of the Le Mans base technical rules document probably contains a lot less than 1 million tokens. The fact that the documents were written in French (left column of page) and English (right column) was initially more of a concern.
Each team was given a $100 budget to spend on LLMs, and after spending a few percent of our budget we had something that looked like it worked, i.e., it detected all 14 instances of race-time checkable rule violations listed by Grok.
My fellow team-mates knew as much about motor racing as I did, and we leaned heavily on what our favourite LLMs told us. I was surprised at how smoothly and quickly the app was up and running; perhaps because so much of the code was LLM generated. Given how flawed human written hackathon code can be, I cannot criticize LLM generated hackathon code.
Based on our LLM usage costs during application creation and testing, checking the events associated with one car over 24 hours is estimated to be around $36.00, and with a field of 60 cars the total estimated cost is $2,160.
Five teams presented on Sunday afternoon, and Team Awesome won! The source code is available on GitHub.
Motorcar racing is a Red Queen activity. If they are not already doing so, I expect that teams will soon be using LLMs to check what other teams are doing.
Thanks to our ClearRoute hosts who kept us fed and watered, and were very responsive to requests for help.
One code path dominates method execution
A recurring claim is that most reported faults are the result of coding mistakes in a small percentage of a program’s source code, with the 80/20 ‘rule’ being cited for social confirmation. I think there is something to this claim, but that the percentages are not so extreme.
A previous post pointed out that reported faults are caused by users. The 80/20 observation can be explained by users only exercising a small percentage of a program’s functionality (a tiny amount of data supports this observation). Surprisingly, there are researchers who believe that a small percentage of the code has some set of characteristics which causes it to contain most of a program’s coding mistakes (this belief has the advantage that a lot of source code is easily accessible and can be analysed to produce papers).
To what extent does user input direct program execution towards a small’ish subset of the code available to be executed?
The recent paper: Monitoring the Execution of 14K Tests: Methods Tend to Have One Path That Is Significantly More Executed by Andre Hora counted the number of times each path through a method’s source code was executed, when the method was called, for the 5,405 methods in 25 Python programs. These programs were driven by their 14,177 tests, rather than user input. The paper is focused on testing, in particular developer that developers tend to focus on positive tests.
Test suites are supposed to exercise all of a program’s source, so it is to be expected that these measurements will show a wider dispersion of code coverage than might be expected of typical user input.
The measurements also include a count of the lines executed/not executed along each executed method path. No information is provided on the number of unexecuted paths.
Within a method, there is always going to one path through the code that is executed more often than any other path. What this study found is that the most common path is often executed many more times than the other paths. The plot below shows, for each method (each +), the percentage of all calls to a method where the most common path was executed, against the total number of executed paths for that method; red/blue lines are fitted power law/exponential regression models, and the grey line shows the case where percentage executed is the fraction for a given number of paths (code+data):
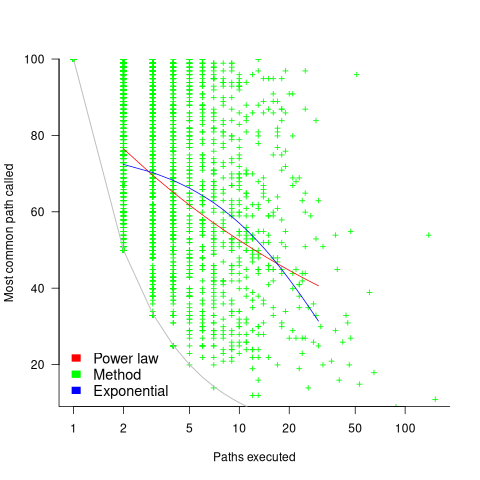
On average, the most common path is executed around four times more often than the second most commonly executed path.
While statistically significant, the fitted models do not explain much of the variance in the data. An argument can be made for either a power law and exponential distribution, and not having a feel for what to expect, I fitted both.
Non-error paths through a method have been found to be longer than the error paths. These measurements do not contain the information needed to attempt to replicate this finding.
New paths through a method are created by conditional statements, and the percentage of such statements in a method tends to be relatively constant across methods. The plot below shows the percentage of all calls to a method where the most common path was executed, where the method (each +) contains a given LOC; red/blue lines are fitted power law/exponential regression models (code+data):
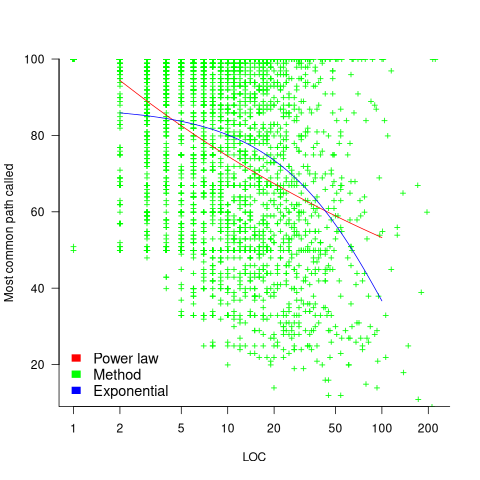
The models fitted to against LOC are better than those fitted against paths executed, but still not very good. A possible reason is that some methods will have unexecuted paths, LOC is a good proxy for total paths, and most common path percentage depends on total paths.
On average, 56% of a method’s LOC are executed along the most frequently executed path. When weighted by the number of method calls, the percentage is 48%.
The results of this study show that a call to most methods is likely to be dominated by the execution of one sequence of code. Another way that in which a small amount of code can dominate program execution is when most calls are to a small subset of the available methods. The plot below shows a density plot for the total number of calls to each method (code+data):

Around 62% of methods are called less than 100 times, while 2.6% are called over 10,000 times.
Recent Comments