Archive
Join a crowdsourced search for software engineering data
Software engineering data, that can be made publicly available, is very rare; most people don’t attempt to collect data, and when data is collected, people rarely make any attempt to hang onto the data they do collect.
Having just one person actively searching for software engineering data (i.e., me) restricts potential sources of data to be English speaking and to a subset of development ecosystems.
This post is my attempt to start a crowdsourced campaign to search for software engineering data.
Finding data is about finding the people who have the data and have the authority to make it available (no hacking into websites).
Who might have software engineering data?
In the past, I have emailed chief technology officers at companies with less than 100 employees (larger companies have lawyers who introduce serious amounts of friction into releasing company data), and this last week I have been targeting Agile coaches. For my evidence-based software engineering book I mostly emailed the authors of data driven papers.
A lot of software is developed in India, China, South America, Russia, and Europe; unless these developers are active in the English-speaking world, I don’t see them.
If you work in one of these regions, you can help locate data by finding people who might have software engineering data.
If you want to be actively involved, you can email possible sources directly, alternatively I can email them.
If you want to be actively involved in the data analysis, you can work on the analysis yourself, or we can do it together, or I am happy to do it.
In the English-speaking development ecosystems, my connection to the various embedded ecosystems is limited. The embedded ecosystems are huge, there must be software data waiting to be found. If you are active within an embedded ecosystem, you can help locate data by finding people who might have software engineering data.
The email template I use for emailing people is below. The introduction is intended to create a connection with their interests, followed by a brief summary of my interest, examples of previous analysis, and the link to my book to show the depth of my interest.
By all means cut and paste this template, or create one that you feel is likely to work better in your environment. If you have a blog or Twitter feed, then tell them about it and why you think that evidence-based software engineering is important.
Be responsible and only email people who appear to have an interest in applying data analysis to software engineering. Don’t spam entire development groups, but pick the person most likely to be in a position to give a positive response.
This is a search for gold nuggets, and the response rate will be very low; a 10% rate of reply, saying sorry not data, would be better than what I get. I don’t have enough data to be able to calculate a percentage, but a ballpark figure is that 1% of emails might result in data.
My experience is that people are very unsure that anything useful will be found in their data. My response has been that I am always willing to have a look.
I always promise to anonymize their data, and not release it until they have agreed; but working on the assumption that the intent is to make a public release.
I treat the search as a background task, taking months to locate and email, say, 100-people considered worth sending a targeted email. My experience is that I come up with a search idea or encounter a blog post that suggests a line of enquiry, that may result in sending half-a-dozen emails. The following week, if I’m lucky, the same thing might happen again (perhaps with fewer emails). It’s a slow process.
If people want to keep a record of ideas tried, the evidence-based software engineering Slack channel could do with some activity.
Hello, A personalized introduction, such as: I have been reading your blog posts on XXX, your tweets about YYY, your youtube video on ZZZ. My interest is in trying to figure out the human issues driving the software process. Here are two detailed analysis of Agile estimation data: https://arxiv.org/abs/1901.01621 and https://arxiv.org/abs/2106.03679 My book Evidence-based Software Engineering discusses what is currently known about software engineering, based on an analysis of all the publicly available data. pdf+code+all data freely available here: http://knosof.co.uk/ESEUR/ and I'm always on the lookout for more software data. This email is a fishing request for software engineering data. I offer a free analysis of software data, provided an anonymised version of the data can be made public.
Creating and evolving a programming language: funding
The funding for artists and designers/implementors of programming languages shares some similarities.
Rich patrons used to sponsor a few talented painters/sculptors/etc, although many artists had no sponsors and worked for little or no money. Designers of programming languages sometimes have a rich patron, in the form of a company looking to gain some commercial advantage, with most language designers have a day job and work on their side project that might have a connection to their job (e.g., researchers).
Why would a rich patron sponsor the creation of an art work/language?
Possible reasons include: Enhancing the patron’s reputation within the culture in which they move (attracting followers, social or commercial), and influencing people’s thinking (to have views that are more in line with those of the patron).
The during 2009-2012 it suddenly became fashionable for major tech companies to have their own home-grown corporate language: Go, Rust, Dart and Typescript are some of the languages that achieved a notable level of brand recognition. Microsoft, with its long-standing focus on developers, was ahead of the game, with the introduction of F# in 2005 (and other languages in earlier and later years). The introduction of Swift and Hack in 2014 were driven by solid commercial motives (i.e., control of developers and reduced maintenance costs respectively); Google’s adoption of Kotlin, introduced by a minor patron in 2011, was driven by their losing of the Oracle Java lawsuit.
Less rich patrons also sponsor languages, with the idiosyncratic Ivor Tiefenbrun even sponsoring the creation of a bespoke cpu to speed up the execution of programs written in the company language.
The benefits of having a rich sponsor is the opportunity it provides to continue working on what has been created, evolving it into something new.
Self sponsored individuals and groups also create new languages, with recent more well known examples including Clojure and Julia.
What opportunities are available for initially self sponsored individuals to support themselves, while they continue to work on what has been created?
The growth of the middle class, and its interest in art, provided a means for artists to fund their work by attracting smaller sums from a wider audience.
In the last 10-15 years, some language creators have fostered a community driven approach to evolving and promoting their work. As well as being directly involved in working on the language and its infrastructure, members of a community may also contribute or help raise funds. There has been a tiny trickle of developers leaving their day job to work full time on ‘their’ language.
The term Hedonism driven development is a good description of this kind of community development.
People have been creating new languages since computers were invented, and I don’t expect this desire to create new languages to stop anytime soon. How long might a language community be expected to last?
Having lots of commercially important code implemented in a language creates an incentive for that language’s continual existence, e.g., companies paying for support. When little or co commercial important code is available to create an external incentive, a language community will continue to be active for as long as its members invest in it. The plot below shows the lifetime of 32 secular and 19 religious 19th century American utopian communities, based on their size at foundation; lines are fitted loess regression (code+data):
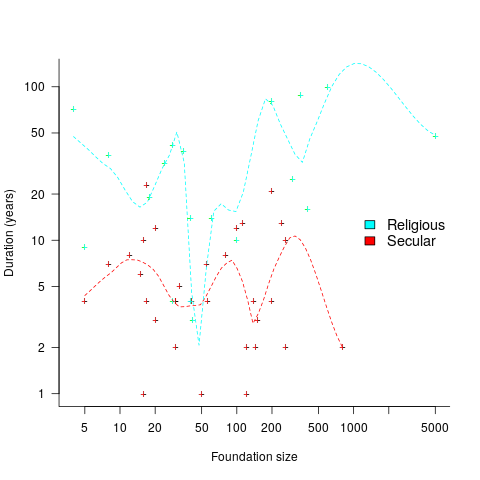
How many self-sustaining language communities are there, and how many might the world’s population support?
My tracking of new language communities is a side effect of the blogs I follow and the few community sites a visit regularly; so a tiny subset of the possibilities. I know of a handful of ‘new’ language communities; with ‘new’ as in not having a Wikipedia page (yet).
One list contains, up until 2005, 7,446 languages. I would not be surprised if this was off by almost an order of magnitude. Wikipedia has a very idiosyncratic and brief timeline of programming languages, and a very incomplete list of programming languages.
I await a future social science PhD thesis for a more thorough analysis of current numbers.
Fishing for software data
During 2021 I sent around 100 emails whose first line started something like: “I have been reading your interesting blog post…”, followed by some background information, and then a request for software engineering data. Sometimes the request for data was specific (e.g., the data associated with the blog post), and sometimes it was a general request for any data they might have.
So far, these 100 email requests have produced one two datasets. Around 80% failed to elicit a reply, compared to a 32% no reply for authors of published papers. Perhaps they don’t have any data, and don’t think a reply is worth the trouble. Perhaps they have some data, but it would be a hassle to get into a shippable state (I like this idea because it means that at least some people have data). Or perhaps they don’t understand why anybody would be interested in data and must be an odd-ball, and not somebody they want to engage with (I may well be odd, but I don’t bite :-).
Some of those who reply, that they don’t have any data, tell me that they don’t understand why I might be interested in data. Over my entire professional career, in many other contexts, I have often encountered surprise that data driven problem-solving increases the likelihood of reaching a workable solution. The seat of the pants approach to problem-solving is endemic within software engineering.
Others ask what kind of data I am interested in. My reply is that I am interested in human software engineering data, pointing out that lots of Open source is readily available, but that data relating to the human factors underpinning software development is much harder to find. I point them at my evidence-based book for examples of human centric software data.
In business, my experience is that people sometimes get in touch years after hearing me speak, or reading something I wrote, to talk about possible work. I am optimistic that the same will happen through my requests for data, i.e., somebody I emailed will encounter some data and think of me 🙂
What is different about 2021 is that I have been more willing to fail, and not just asking for data when I encounter somebody who obviously has data. That is to say, my expectation threshold for asking is lower than previous years, i.e., I am more willing to spend a few minutes crafting a targeted email on what appear to be tenuous cases (based on past experience).
In 2022 I plan to be even more active, in particular, by giving talks and attending lots of meetups (London based). If your company is looking for somebody to give an in-person lunchtime talk, feel free to contact me about possible topics (I’m always after feedback on my analysis of existing data, and will take a 10-second appeal for more data).
Software data is not commonly available because most people don’t collect data, and when data is collected, no thought is given to hanging onto it. At the moment, I don’t think it is possible to incentivize people to collect data (i.e., no saleable benefit to offset the cost of collecting it), but once collected the cost of hanging onto data is peanuts. So as well as asking for data, I also plan to sell the idea of hanging onto any data that is collected.
Fishing tips for software data welcome.
Christmas books for 2021
This year, my list of Christmas books is very late because there is only one entry (first published in 1950), and I was not sure whether a 2021 Christmas book post was worthwhile.
The book is “Planning in Practice: Essays in Aircraft planning in war-time” by Ely Devons. A very readable, practical discussion, with data, on the issues involved in large scale planning; the discussion is timeless. Check out second-hand book sites for low costs editions.
Why isn’t my list longer?
Part of the reason is me. I have not been motivated to find new topics to explore, via books rather than blog posts. Things are starting to change, and perhaps the list will be longer in 2022.
Another reason is the changing nature of book publishing. There is rarely much money to be made from the sale of non-fiction books, and the desire to write down their thoughts and ideas seems to be the force that drives people to write a book. Sites like substack appear to be doing a good job of diverting those with a desire to write something (perhaps some authors will feel the need to create a book length tomb).
Why does an author need a publisher? The nitty-gritty technical details of putting together a book to self-publish are slowly being simplified by automation, e.g., document formatting and proofreading. It’s a win-win situation to make newly written books freely available, at least if they are any good. The author reaches the largest readership (which helps maximize the impact of their ideas), and readers get a free electronic book. Authors of not very good books want to limit the number of people who find this out for themselves, and so charge money for the electronic copy.
Another reason for the small number of good new, non-introductory, books, is having something new to say. Scientific revolutions, or even minor resets, are rare (i.e., measured in multi-decades). Once several good books are available, and nothing much new has happened, why write a new book on the subject?
The market for introductory books is much larger than that for books covering advanced material. While publishers obviously want to target the largest market, these are not the kind of books I tend to read.
Parkinson’s law, striving to meet a deadline, or happenstance?
How many minutes past the hour was it, when you stopped working on some software related task?
There are sixty minutes in an hour, so if stop times are random, the probability of finishing at any given minute is 1-in-60. If practice (based on the 200k+ time records in the CESAW dataset) the probability of stopping on the hour is 1-in-40, and for stopping on the half-hour is 1-in-48.
Why are developers more likely to stop working on a task, on the hour or half-hour?
Is this a case of Parkinson’s law, or are developers striving to complete a task within a specified time, or are they stopping because a scheduled activity takes priority?
The plot below shows the number of times (y-axis) work on a task stopped on a given minute past the hour (x-axis), for 16 different software projects (project number in blue, with top 10 numbers in red, code+data):

Some projects have peaks at 50, 55, or thereabouts. Perhaps people are stopping because they have a meeting to attend, and a peak is visible because the project had lots of meetings, or no peak was visible because the project had few meetings. Some projects have a peak at 28 or 29, which might be some kind of time synchronization issue.
Is it possible to analyze the distribution of end minutes to reasonably infer developer project behavior, e.g., Parkinson’s law, striving to finish by a given time, or just not watching the clock?
An expected distribution pattern for both Parkinson’s law, and striving to complete, is a sharp decline of work stops after a reference time, e.g., end of an hour (this pattern is present in around ten of the projects plotted). A sharp increase in work stops prior to a reference time could also apply for both behaviors; stopping to switch to other work adds ‘noise’ to the distribution.
The CESAW data is organized by project, not developer, i.e., it does not list everything a developer did during the day. It is possible that end-of-hour work stops are driven by the need to synchronize with non-project activities, i.e., no Parkinson’s law or striving to complete.
In practice, some developers may sometimes follow Parkinson’s law, other times strive to complete, and other times not watch the clock. If models capable of separating out the behaviors were available, they might only be viable at the individual level.
Stop time equals start time plus work duration. If people choose a round number for the amount of work time, there is likely to be some correlation between start/end minutes past the hour. The plot below shows heat maps for start fraction of hour (y-axis) against end fraction of hour (x-axis) for four projects (code+data):
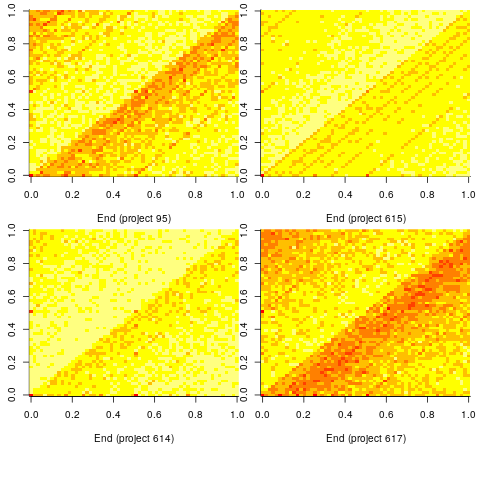
Work durations that are exact multiples of an hour appear along the main diagonal, with zero/zero being the most common start/end pair (at 4% over all projects, with 0.02% expected for random start/end times). Other diagonal lines come from work durations that include a fraction of an hour, e.g., 30-minutes and 20-minutes.
For most work periods, the start minute occurs before the end minute, i.e., the work period does not cross an hour boundary.
What can be learned from this analysis?
The main takeaway is that there is a small bias for work start/end times to occur on the hour or half-hour, and other activities (e.g., meetings) cause ongoing work to be interrupted. Not exactly news.
More interesting ideas and suggestions welcome.
First understand the structure of a standard, then read it
Extracting useful information from the text in an ISO programming language standard first requires an understanding of the stylized English in which it is written.
I regularly encounter people who cite wording from the C Standard to back up their interpretation of a particular language construct. My first thought when this happens is: Do I want to spend the time explaining how the standard ‘works’ to get to the point of dealing with the topic being discussed?
I am not aware of any “How to read the C Standard” guide, or such a guide for any language.
Explaining enough detail to have a sensible conversation about the text takes, maybe, 10-30 minutes. The interpretation of text in any standard can depend on the section in which it occurs, and particular phrases can be specified to have different interpretations in different contexts. For instance, in the C Standard, a source code construct that violates a “shall” requirement specified in a “Constraints” section is about as serious as things get (i.e., it’s a mandatory compile time error), while violating a “shall” requirement specified outside a “Constraints” is undefined behavior (i.e., the compiler can do what it likes, including nothing).
New readers also get hung up on footnotes, which are a great source of confusion. Footnotes have no normative meaning; technically, they are classified as informative (their real use is providing the committee a means to include wording in the document to satisfy some interested party, without the risk of breaking the standard {because this text has no normative status}).
Sometimes a person familiar with the C++ Standard applies the interpretation rules they have learned to the C Standard. This can work in limited cases, but the fundamental differences between how the two documents are structured requires a reorientation of thinking. For instance, the C Standard specifies the behavior of source code (from which the behavior of implementations has to be inferred), while the C++ Standard specifies the behavior of implementations (from which the behavior of source code constructs has to be inferred), and the C++ Standard does not contain “Constraints” sections.
The general committee response, at least in WG14, to complaints that the language standard requires effort to understand, is that the standard is not intended as a tutorial. At least there is a prose document to read, there are forms of language specification that don’t provide this luxury. At a minimum, a language standard first needs to be read two or three times before trying to answer detailed questions.
In general, once somebody has learned to interpret one ISO Standard, the know-how does not transfer to other ISO language standards, but they have an appreciation of the need for such an understanding.
In theory, know-how is supposed to be transferable; part 2 of the ISO directives, Principles and rules for the structure and drafting of ISO and IEC documents, “… stipulates certain rules to be applied in order to ensure that they are clear, precise and unambiguous.” There are also the technical reports: Guidelines for the Preparation of Conformity Clauses in Programming Language Standards (published in 1990), which I suspect few people have read, even within the standards’ programming language community, and Guidelines for the preparation of programming language standards (unchanged since the fourth edition in 2003).
In practice: The Fortran and Cobol standards were written before people had any idea which rules might be appropriate; I think the Pascal standard appeared just before the rules were formalised. Also, all three standards were created by National bodies (US, US, and UK respectively) as National standards, and then ‘promoted’ as-is to be ISO standards. ADA was a DoD standard that got ‘promoted’, and very much did its own thing with regard to stylized English.
The post-1990 language standards visually look as if they follow the ISO rules in force at the time they were first written (Directives, part 2 is on its ninth edition), i.e., the titles of clauses match the clause numbering scheme specified by ISO rules, e.g., clause 3 specifies “Terms and definitions”. However, readers are going to need some cultural background on the use of the language by its community, to figure out the intent of the text. For instance, the 1990 revision of the Pascal Standard contains extensive use of “shall”, but it is not clear how this is to be interpreted; I used Pascal extensively for 10-years, but never studied its ISO standard, and reading it now with my C Standard expertise is a strange experience, e.g., familiar language “constraints” do not appear to be specified in the text, and the compiler does not appear to be required to flag anything.
Two of the pre-1990 language standards, Fortran and Cobol, were initially written in the 1960s, and read like they are from another age (probably because of the way they are laid out, and the fonts used). The differences are so obvious that any readers with prior experience are likely to understand that they are going to have to figure out the structure from scratch. The formatting of post-1990 Fortran Standards lacks the 1960s vibe.
The software heritage of K&R C
The mission statement of the Software Heritage is “… to collect, preserve, and share all software that is publicly available in source code form.”
What are the uses of the preserved source code that is collected? Lots of people visit preserved buildings, but very few people are interested in looking at source code.
One use-case is tracking the evolution of changes in developer usage of various programming language constructs. It is possible to use Github to track the adoption of language features introduced after 2008, when the company was founded, e.g., new language constructs in Java. Over longer time-scales, the Software Heritage, which has source code going back to the 1960s, is the only option.
One question that keeps cropping up when discussing the C Standard, is whether K&R C continues to be used. Technically, K&R C is the language defined by the book that introduced C to the world. Over time, differences between K&R C and the C Standard have fallen away, as compilers cease supporting particular K&R ways of doing things (as an option or otherwise).
These days, saying that code uses K&R C is taken to mean that it contains functions defined using the K&R style (see sentence 1818), e.g.,
writing:
int f(a, b) int a; float b; { /* declarations and statements */ } |
rather than:
int f(int a, float b) { /* declarations and statements */ } |
As well as the syntactic differences, there are semantic differences between the two styles of function definition, but these are not relevant here.
How much longer should the C Standard continue to support the K&R style of function definition?
The WG14 committee prides itself on not breaking existing code, or at least not lots of it. How much code is out there, being actively maintained, and containing K&R function definitions?
Members of the committee agree that they rarely encounter this K&R usage, and it would be useful to have some idea of the decline in use over time (with the intent of removing support in some future revision of the standard).
One way to estimate the evolution in the use/non-use of K&R style function definitions is to analyse the C source created in each year since the late 1970s.
The question is then: How representative is the Software Heritage C source, compared to all the C source currently being actively maintained?
The Software Heritage preserves publicly available source, plus the non-public, proprietary source forming the totality of the C currently being maintained. Does the public and non-public C source have similar characteristics, or are there application domains which are poorly represented in the publicly available source?
Embedded systems is a very large and broad application domain that is poorly represented in the publicly available C source. Embedded source tends to be heavily tied to the hardware on which it runs, and vendors tend to be paranoid about releasing internal details about their products.
The various embedded systems domains (e.g., 8, 16, 32, 64-bit processor) tend to be a world unto themselves, and I would not be surprised to find out that there are enclaves of K&R usage (perhaps because there is no pressure to change, or because the available tools are ancient).
At the moment, the Software Heritage don’t offer code search functionality. But then, the next opportunity for major changes to the C Standard is probably 5-years away (the deadline for new proposals on the current revision has passed); plenty of time to get to a position where usage data can be obtained 🙂
Open source: the goody bag for software infrastructure
For 70 years there has been a continuing discovery of larger new ecosystems for new software to grow into, as well as many small ones. Before Open source became widely available, the software infrastructure (e.g., compilers, editors and libraries of algorithms) for these ecosystems had to be written by the pioneer developers who happened to find themselves in an unoccupied land.
Ecosystems may be hardware platforms (e.g., mainframes, minicomputers, microcomputers and mobile phones), software platforms (e.g., Microsoft Windows, and Android), or application domains (e.g., accounting and astronomy)
There are always a few developers building some infrastructure project out of interest, e.g., writing a compiler for their own or another language, or implementing an editor that suites them. When these projects are released, they have to compete against the established inhabitants of an ecosystem, along with other newly released software clamouring for attention.
New ecosystems have limited established software infrastructure, and may not yet have attracted many developers to work within them. In such ‘virgin’ ecosystems, something new and different faces less competition, giving it a higher probability of thriving and becoming established.
Building from scratch is time-consuming and expensive. Adapting existing software systems speeds things up and reduces costs; adaptation also has the benefit of significantly reducing the startup costs when recruiting developers, i.e., making it possible for experienced people to use the skills acquired while working in other ecosystems. By its general availability, Open source creates competition capable of reducing the likelihood that some newly created infrastructure software will become established in a ‘virgin’ ecosystem.
Open source not only reduces startup costs for those needing infrastructure for a new ecosystem, it also reduces ongoing maintenance costs (by spreading them over multiple ecosystems), and developer costs (by reducing the need to learn something different, which happened to be created by developers who built from scratch).
Some people will complain that Open source is reducing diversity (where diversity is viewed as unconditionally providing benefits). I would claim that reducing diversity in this case is a benefit. Inventing new ways of doing things based on the whims of those doing the invention is a vanity project. I have nothing against people investing their own resources on their own vanity projects, but let’s not pretend that the diversity generated by such projects is likely to provide benefits to others.
By providing the components needed to plug together a functioning infrastructure, Open source reduces the cost of ecosystem ‘invasion’ by software. The resources which might have been invested building infrastructure components can be directed to building higher level functionality.
Where are we with models of human learning?
Learning is an integral part of writing software. What have psychologists figured out about the characteristics of human learning?
A study of memory, published in 1885, kicked off the start of modern psychology research. At the start of the 1900s, learning research was still closely tied to the study of the characteristics of what we now call working memory, e.g., measuring the time taken for subjects to correctly recall sequences of digits, nonsense syllables, words and prose. By the 1930s, learning was a distinct subject in its own right.
What is now known as the power law of learning was first proposed in 1926. Wikipedia is right to use the phrase power law of practice, since it is some measure of practice that appears in the power law of learning equation:  , where:
, where:  is the time taken to do the task,
is the time taken to do the task, is some measure of practice (such as the number of times the subject has performed the task), and
is some measure of practice (such as the number of times the subject has performed the task), and  ,
,  , and
, and  are constants fitted to the data.
are constants fitted to the data.
For the next 70 years some form of power law did a good job of fitting the learning data produced by researchers. Then in 1997 a paper pointed out that researchers were fitting aggregate data (i.e., one equation fitted to all subject data), and that an exponential equation was a better fit to individual subject response times:  . The power law appeared to be the result of aggregating the exponential response performance of multiple subjects; oops.
. The power law appeared to be the result of aggregating the exponential response performance of multiple subjects; oops.
What is the situation today, 25 years later? Do the subsystems of our brains produce a power law or exponential improvement in performance, with practice?
The problem with answering this question is that both equations can fit the available data quite well, with one being a technically better fit than the other for different datasets. The big difference between the two equations is in their tails, however, it is costly and time-consuming to obtain enough data to distinguish between them in this region.
When discussing learning in my evidence-based software engineering book, I saw no compelling reason to run counter to the widely cited power law, but I did tell readers about the exponential fit issue.
Studies of learnings have tended to use simple tasks; subjects are usually only available for a short time, and many task repetitions are needed to model the impact of learning. Simple tasks tend to be dominated by one primary activity, which means that subjects can focus their learning on this one activity.
Complicated tasks involve many activities, each potentially providing distinct learning opportunities. Which activities will a subject focus on improving, will the performance on one activity improve faster than others, will the approach chosen for one activity limit the performance on a second activity?
For a complicated task, the change in performance with amount of practice could be a lot more complicated than a single power law/exponential equation, e.g., there may be multiple equations with each associated with one or more activities.
In the previous paragraph, I was careful to say “could be a lot more complicated”. This is because the few datasets of organizational learning show a power law performance improvement, e.g., from 1936 we have the most cited study Factors Affecting the Cost of Airplanes, and the less well known but more interesting Liberty shipbuilding from the 1940s.
If the performance of something involving multiple people performing many distinct activities follows a power law improvement with practice, then the performance of an individual carrying out a complicated task might follow a simple equation; perhaps the combined form of many distinct simple learning activities is a simple equation.
Researchers are now proposing more complicated models of learning, along with fitting them to existing learning datasets.
Which equation should software developers use to model the learning process?
I continue to use a power law. The mathematics tend to be straight-forward, and it often gives an answer that is good enough (because the data fitted contains lots of variance). If it turned out that an exponential would be easier to work with, I would be happy to switch. Unless there is a lot of data in the tail, the difference between power law/exponent is usually not worth worrying about.
There are situations where I have failed to successfully add a learning (power law) component to a model. Was this because there was no learning present, or was the learning not well-fitted by a power law? I don’t know, and I cannot think of an alternative equation that might work, for these cases.
How large an impact does social conformity have on estimates?
People experience social pressure to conform to group norms. How big an impact might social pressure have on a developer’s estimate of the effort needed to implement some functionality?
If a manager suggests that the effort likely to be required is large/small, I would expect a developer to respond accordingly (even if the manager is thought to be incompetent; people like to keep their boss happy). Of course, customer opinions are also likely to have an impact, but what about fellow team members, or even the receptionist. Until somebody runs the experiments, we are going to have to do with non-software related tasks.
A study by Molleman, Kurversa, and van den Bos asked subjects (102 workers on Mechanical Turk) to estimate the number of animals in an image (which contained between 50 and 100 ants, flamingos, bees, cranes or crickets). Subjects were given 30 seconds to respond, and after typing their answer they were told that “another participant had estimated X“, and given 45 seconds to give a second estimate. The ‘social pressure’ estimate, X, was chosen to be around 15-25% larger/smaller than the estimate given (values from a previous experiment were randomly selected).
The plot below shows the number of second estimates where there was a given percentage change between the first and second estimates, red line is a loess fit; the formula used is  (code+data):
(code+data):
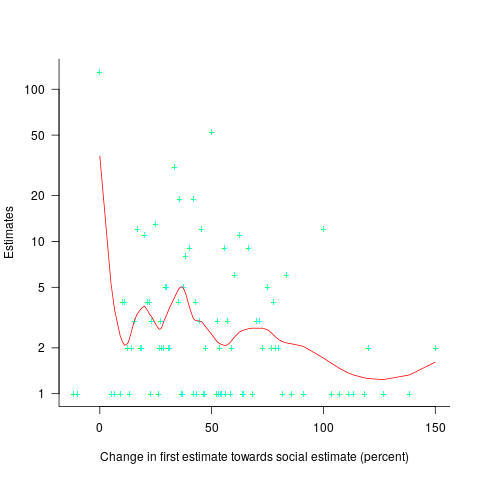
Around 25% of second estimates were unchanged, and 2% were changed to equal the social estimate. In two cases the second estimate was less than the first, and in eleven cases it was larger than the social estimate. Both the mean and median for shift towards the social estimate were just over 30% of the difference between the first estimate and the social estimate.
As with previous estimating studies, a few round numbers were often chosen. I was interested in finding out what impact the use of a round number value for the first estimate, or the social estimate, might have on the change in estimated value. The best regression model I could find showed that if the first estimate was exactly divisible by 5 (or 10), then the second estimate was likely to be around 5% larger. In fact divisible-by-5 was the only variable that had any predictive power.
My initial hypothesis was that the act of choosing a round number is an expression of uncertainty, and that this uncertainty increases the impact of the social estimate (when making the second estimate). An analysis of later experiments suggested that this pattern was illusionary (see below).
Modelling estimate values, rather than their differences, the equation:  explains nearly all the variance present in the data.
explains nearly all the variance present in the data.
Two weeks after the first experiment, all 102 subjects were asked to repeat the experiment (they each saw the same images, in the same order, and social estimates as in the first study); 69 subjects participated. Nine months after the first experiment, subjects were asked to repeat the experiment again; 47 subjects participated, again with each subject seeing the same images in the same order, and social estimates. Thirty-five subjects participated in all three experiments.
To what extent were subjects consistently influenced by the social estimate, across three identical sessions? The Pearson correlation coefficient between both the first/second experiment, and the first/third experiment, was around 0.6.
The impact of round numbers was completely different, i.e., no impact on the second, and a -7% impact on the third (i.e., a reduced change). So much for my initial hypothesis.
The exponents in the above equation did not change much for the data from the second and third reruns of the experiment.
The variability in the social estimates used in these experiments, involving image contents, differs from software estimates in that they were only 12-25% different from the first estimate. Software estimates often differ by significantly larger amounts (in fact, a 12% difference would probably be taken as agreement).
With some teams, people meet to thrash out a team estimate. Data is sometimes available on the final estimate, but data on the starting values is very hard to come by. Pointers to experiments where social estimates are significantly different (i.e., greater than 50%) from the ones given by subjects welcome.
Recent Comments