Archive
Distribution of method chains in Java and Python
Some languages support three different ways of organizing a sequence of functions/methods, with calls taking as their first argument the value returned by the immediately prior call. For instance, Java supports the following possibilities:
r1=f1(val); r2=f2(r1); r3=f3(r2); // Sequential calls r3=f3(f2(f1(val))); // Nested calls, read right to left r3=val.f1().f2().f3(); // Method chain, read left to right |
Simula 67 was the first language to support the dot-call syntax used to code method chains. Ten years later Smalltalk-76 supported sending a message to the result of a prior send, which could be seen as a method chain rather than a nested call (because it is read left to right; Smalltalk makes minimal use of punctuator characters, so the syntax is not distinguishable).
How common are method chains in source code, and what is the distribution of chain length? Two studies have investigated this question: An Empirical Study of Method Chaining in Java by Nakamaru (PhD thesis), Matsunaga, Akiyama, Yamazaki, and Chiba, and Method Chaining Redux: An Empirical Study of Method Chaining in Java, Kotlin, and Python by Keshk, and Dyer.
The plot below shows the number of Java method chains having a given length, for code available in a given year. The red line is a fitted regression line for 2018, based on a model fitted to the complete dataset (code and data):
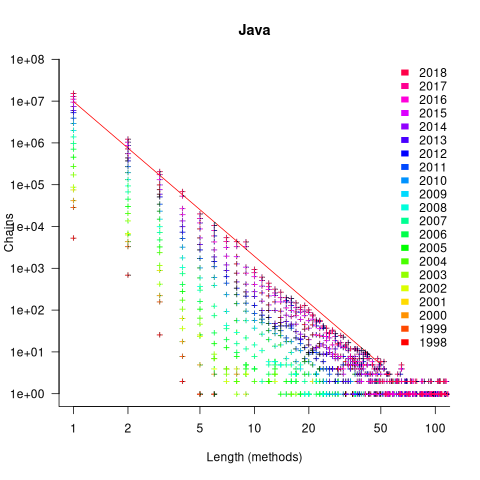
The fitted regression model is:

Why is the number of chains of all lengths growing by around 46% per year? I think this growth is driven by the growth in the amount of source measured. Measurements show that the percentage of source lines containing a method call is roughly constant. In the plot above, the number of unchained methods (i.e., chains of length one) increases in-step with the growth of chained methods. All chain lengths will grow at the same rate, if the source that contains them is growing.
What is responsible for the step change in the number of chains at around 10 methods? Nakamaru classified a random sample of 280 chains, and found that roughly 80% of chains longer than eight methods built an object, e.g., the following chain:
MoreObjects.toStringHelper(this) .add("iLine" , iLine) .add("lastK" , lastK) .add("spacesPending", spacesPending) .add("newlinesPending", newlinesPending) .add("blankLines", blankLines) .add("super", super.toString()) .toString() |
Are these chain usage patterns present in Python? The plot below shows the number of Python method chains having a given length, for code available in a given year. The red line is a fitted regression line for 2020, based on a model fitted to the complete dataset (code and data):

The fitted regression model is:

While this model is almost identical to the model fitted to the Java data (the annual growth rate is 39%), the above plot shows a large step change after chains of length two. Keshk’s paper focuses on replicating Nakamaru’s Java results, and then briefly discusses Python. I have an assortment of explanations, but nothing stands out.
Within code, how are method calls split between single calls and a chain of two or more calls?
The fractions in the plot below are calculated as the ratio of chains of length one (i.e., single method call) against chains containing two or more methods. The “j” shows Java ratios, and “p” Python ratios. The red lines show the fraction based on the total number of method calls, and the blue/green lines are based on occurrences of chains, i.e., chain of one vs chain of many (code and data):

The ratio of Java chains containing two or more methods vs one method, grew by around 6% a year between 2006 and 2018, which is only a small part of the overall 46% annual Java growth.
Method chaining is three times more common in Java than Python. In 2020 around a quarter of all method calls were in a chain of two or more, and single method calls were around ten times more common than multi-call chains.
In Python, the use of method chains has roughly remained unchanged over 15 years, with around 5% of all method calls appearing in a chain.
I don’t have a good idea for why method chains are three times more common in Java than Python. Are nested calls the more common usage in Python, or do developers use a sequence of calls communicating using temporary variables?
What of languages that don’t support method chaining, e.g., C. Is the distribution of the number of nested calls (or sequence of calls using temporaries) a power law with an exponent close to 3.7?
Suggestions and pointers to more data welcome.
Finding links between gcc source code and the C Standard
How close is the agreement between the behavior of a compiler and its corresponding language specification?
In the previous century, some Standards’ bodies offered a compiler validation service. However, even when the number of commercial compilers numbered in the hundreds, this service was not commercially viable. These days there are only a handful of industrial strength compilers.
The availability of huge quantities of Open source, for some languages, has created a new language specification. Being able to turn much of this source into executable programs has become an effective measure of compiler correctness.
Those working on C/C++ compilers (Open source or otherwise), often claim that they implement the requirements contained in the corresponding ISO Standard. Some are active in the ISO Standards’ process, and I believe that they do strive to implement the requirements contained in the language standard.
How confident can we be that all the requirements contained in a language standard are correctly implemented by a compiler?
There is a cottage industry of testing compiler runtime behavior, often using fuzzers, and sometimes a compiler is one of the programs chosen to test new fuzzing techniques. This research checks optimization and code generation.
This runtime testing is all well and good, but a large percentage of the text in a language specification contains requirements on the syntax and semantics. The quality of syntax/semantic testing depends on how well the people writing the tests understand the language semantics. It takes a year or two of detailed study to achieve an effective compiler-level of understanding of these ‘front-end’ requirements.
The approach taken by the Model Implementation C Checker to show syntax/semantic correctness was to cross-referenced every if-statement in the front-end to one or more lines in the C90 Standard (the 1990 edition of the ISO C Standard), or an internal house-keeping reference (the source contained 3K references to 1.3K requirements in the C Standard). This compiler/checker was formally validated by BSI. As far as I know, this is the only compiler source cross-referenced at the level of individual lines/if-statements; there are compilers whose source contains cross-references to the sections of a language specification.
The main benefit of this cross-referencing process is insuring that every requirement in the C Standard is addressed by the compiler (correctly or otherwise). Other benefits include providing packets of wording for targeted tests and the ability to generate a runtime trace of all language features involved in compiling a given translation unit.
Replicating this cross-referencing for the gcc or llvm C compiler front-ends would be a huge amount of work for somebody who already has a detailed knowledge of the C Standard, along with some knowledge of compilers. The number of pages in the Standard relating to the C language has grown from 101 pages in C90 to 190 pages in C23. At an average of 14 cross-referenceable lines per page, the expected number of cross-references is now likely to be around 2,700.
LLMs are great at extracting information from text, can generate impressive quality C conformance tests, and are much, much cheaper than C language experts. How good are LLMs at working out which section(s)/paragraph(s) in the C Standard are implemented by the source code of a function contained in, say, gcc?
The LLM prompt I used to test out the idea was:
List the section and paragraph number of the latest ISO C standard containing the requirements implemented in the following source code from a C compiler |
Links to all responses from: ChatGPT5 Thinking, Grok3 Fast and Gok3 Expert.
It is very likely that text from the various versions of the C Standard were in the training data of the larger LLMs, so I did not include this material in the prompt. ChatGPT5 Thinking listed the 2024 draft N3220 as its source document.
The source code was copied from the C front-end code of gcc (i.e., the directory: gcc-15.1.0/gcc/c), which contains 67KLOC, with 6.8K if-statements.
Starting small, the following code looked like an easy test (I removed the comment containing text from the C Standard and obscured the big clue in the original function name: null_pointer_constant_p):
bool check_is_n_ptr (const_tree expr) { /* This should really operate on c_expr structures, but they aren't yet available everywhere required. */ tree type = TREE_TYPE (expr); if (expr == nullptr_node) return true; return (TREE_CODE (expr) == INTEGER_CST && !TREE_OVERFLOW (expr) && integer_zerop (expr) && (INTEGRAL_TYPE_P (type) || (TREE_CODE (type) == POINTER_TYPE && VOID_TYPE_P (TREE_TYPE (type)) && TYPE_QUALS (TREE_TYPE (type)) == TYPE_UNQUALIFIED))); } |
Wow, ChatGPT5 Thinking’s response even included a note on why the code checks for an unqualified type:
Here are the exact C23 (ISO/IEC 9899:2024) clauses that your function is implementing:
6.3.2.3 Pointers, ¶3 — Definition of a null pointer constant: “An integer constant expression
with the value 0, such an expression cast to type void *, or the predefined constant nullptr
is called a null pointer constant.”
6.6 Constant expressions, ¶8 — What qualifies as an integer constant expression
(your INTEGER_CST / INTEGRAL_TYPE_P checks).
6.6 Constant expressions, ¶4 — Range requirement for constant expressions
(motivates the !TREE_OVERFLOW (expr) check).
6.4.4.6 Predefined constants, ¶¶1–3 — nullptr is a predefined constant (token classification;
ties to your expr == nullptr_node fast-path).
6.3.2.4 nullptr_t, ¶¶1–2 — Conversions of nullptr_t (confirms nullptr converts to any pointer
type yielding the null pointer value).
Notes
• The “cast to type void *” wording in 6.3.2.3 means unqualified void *,
which is why your code insists the pointed-to void is unqualified.
Grok3 Fast’s response was even more expansive (and almost instantaneous), listing examples of section/paragraphs containing uses of null pointers, and pointing out that the wording was unchanged until C23 (when the nullptr keyword was introduced, along with its type nullptr_t). It also pointed out gcc specific features of the implementation (the prompt did not identify the compiler).
That’s enough of the easy questions. The following code (comments removed, function name unchanged) is essentially asking a question: What is the promoted type of the argument?
tree c_type_promotes_to (tree type) { tree ret = NULL_TREE; if (TYPE_MAIN_VARIANT (type) == float_type_node) ret = double_type_node; else if (c_promoting_integer_type_p (type)) { if (TYPE_UNSIGNED (type) && (TYPE_PRECISION (type) == TYPE_PRECISION (integer_type_node))) ret = unsigned_type_node; else ret = integer_type_node; } if (ret != NULL_TREE) return (TYPE_ATOMIC (type) ? c_build_qualified_type (ret, TYPE_QUAL_ATOMIC) : ret); return type; } |
ChatGPT5 listed six references. Three were good, and the other three were closely related, but I would not have cited them. The seven Grok3 references came from several documents using slightly different section numbers. Updating the prompt to explicitly name N3220 as the document to use did not change Grok3’s cited references (for this question).
All the code in the previous questions was there because of text in the C Standard. How do ChatGPT5/Grok3 handle the presence of code that does not have standard associated text?
The following function contains code to handle named address spaces (defined in a 2005 Technical Report: TR 18037 Extensions to support embedded processors).
static tree qualify_type (tree type, tree like) { addr_space_t as_type = TYPE_ADDR_SPACE (type); addr_space_t as_like = TYPE_ADDR_SPACE (like); addr_space_t as_common; /* If the two named address spaces are different, determine the common superset address space. If there isn't one, raise an error. */ if (!addr_space_superset (as_type, as_like, &as_common)) { as_common = as_type; error ("%qT and %qT are in disjoint named address spaces", type, like); } return c_build_qualified_type (type, TYPE_QUALS_NO_ADDR_SPACE (type) | TYPE_QUALS_NO_ADDR_SPACE_NO_ATOMIC (like) | ENCODE_QUAL_ADDR_SPACE (as_common)); } |
ChatGPT5 listed six good references and pointed out the association between the named address space code and TR 18037. Grok3 Fast hallucinated extensive quoted text/references from TR 18037 related to named address spaces. Grok3 Expert pointed out that the Standard does not contain any requirements related to named address spaces and listed two reasonable references.
Finding appropriate cross-references is the time-consuming first step. Next, I want the LLM to add them as comments next to the corresponding code.
I picked a 312 line function, and updated the prompt to add comments to the attached file:
Find the section and paragraph numbers in the ISO C standard, specified in document N3220, containing the requirements implemented in the source code contained in the attached file, and add these section and paragraph numbers at the corresponding places in the code as comment |
ChatGPT5 Thinking thought for 5 min 46 secs (output), and Grok3 Expert thought for 3 mins 4 secs (output).
Both ChatGPT5 and Grok3 modified the existing code, either by joining adjacent lines, changing variable names, or deleting lines. ChatGPT made far fewer changes, while the Grok3 output was 65 lines shorter than the original (including the added comments).
Both LLMs added comments to blocks of if-statements (my fault for not explicitly specifying that every if should be cross-referenced), with ChatGPT5 adding the most cross-references.
One way to stop the LLMs making unasked for changes to the source is to have them focus on the added comments, i.e., ask for a diff that can be fed into patch. The updated prompt is:
Find the section and paragraph numbers in the ISO C standard, specified in document N3220, containing the requirements implemented by each if statement in the source code contained in the attached file. Create a diff file that patch can use to add these section and paragraph numbers as comments at the corresponding lines in the original code |
ChatGPT5 Thinking thought for around 4 min (it reported inconsistent values (output), and Grok3 Expert thought for 5 min 1 sec (output).
The ChatGPT5 patch contained many more cross-references than its earlier output, with comments on more if-statements. The Grok3 patch was a third the size of the ChatGPT5 patch.
How well did the LLMs perform?
ChatGPT5 did very well, and its patch output would be a good starting point for a detailed human expert edit. Perhaps an improved prompt, or some form of fine-tuning would useful improve performance.
Grok3 Fast does not appear to be usable, but Grok3 Expert could be used as an independent check against ChatGPT5 output.
Working at the section/paragraph level it is not always possible to give the necessary detailed cross-reference because some paragraphs contain multiple requirements. It might be easier to split the C Standard text into smaller chunks, rather than trying to get LLMs to give line offsets within a paragraph.
Modeling the distribution of method sizes
The number of lines of code in a method/function follows the same pattern in the three languages for which I have measurements: C, Java, Pharo (derived from Smalltalk-80).
The number of methods containing a given number of lines is a power law, with an exponent of 2.8 for C, 2.7 for Java and 2.6 for Pharo.
This behavior does not appear to be consistent with a simplistic model of method growth, in lines of code, based on the following three kinds of steps over a 2-D lattice: moving right with probability  , moving up and to the right with probability
, moving up and to the right with probability  , and moving down and to the right with probability
, and moving down and to the right with probability  . The start of an
. The start of an if or for statement are examples of coding constructs that produce a step followed by a step at the end of the statement; steps are any non-compound statement. The image below shows the distinct paths for a method containing four statements:

For this model, if  the probability of returning to the origin after taking
the probability of returning to the origin after taking  is a complicated expression with an exponentially decaying tail, and the case
is a complicated expression with an exponentially decaying tail, and the case  is a well studied problem in 1-D random walks (the probability of returning to the origin after taking steps is
is a well studied problem in 1-D random walks (the probability of returning to the origin after taking steps is  approx n^{-1.5}") ).
).
Possible changes to this model to more closely align its behavior with source statement production include:
- include terms for the correlation between statements, e.g., assigning to a local variable implies a later statement that reads from that variable,
- include context terms in the up/down probabilities, e.g., nesting level.
Measuring statement correlation requires handling lots of special cases, while measurements of up/down steps is easily obtained.
How can / probabilities be written such that step length has a power law with an exponent greater than two?
ChatGPT 5 told me that the Langevin equation and Fokker–Planck equation could be used to derive probabilities that produced a power law exponent greater than two. I had no idea had they might be used, so I asked ChatGPT, Grok, Deepseek and Kimi to suggest possible equations for the / probabilities.
The physics model corresponding to this code related problem involves the trajectories of particles at the bottom of a well, with the steepness of the wall varying with height. This model is widely studied in physics, where it is known as a potential well.
Reaching a possible solution involved refining the questions I asked, following suggestions that turned out to be hallucinations, and trying to work out what a realistic solution might look like.
One ChatGPT suggestion that initially looked promising used a Metropolis–Hastings approach, and a logarithmic potential well. However, it eventually dawned on me that ^a") , where
, where  is nesting level, and
is nesting level, and  some constant, is unlikely to be realistic (I expect the probability of stepping up to decrease with nesting level).
some constant, is unlikely to be realistic (I expect the probability of stepping up to decrease with nesting level).
Kimi proposed a model based on what it called algebraic divergence:
=r/{z(y)},U(y)={u_0y^{1-2/{alpha}}}/{z(y)}, D(y)={d_0y^{1-2/{alpha}}}/{z(y)}")
where: ") normalises the probabilities to equal one,
normalises the probabilities to equal one, =r+u_0y^{1-2/alpha}+d_0y^{1-2/alpha}") ,
,  is the up probability at nesting 0,
is the up probability at nesting 0,  is the down probability at nesting 0, and
is the down probability at nesting 0, and  is the desired power law exponent (e.g., 2.8).
is the desired power law exponent (e.g., 2.8).
For C,  , giving
, giving =r/{z(y)},U(y)={u_0y^{0.29}}/{z(y)}, D(y)={d_0y^{0.29}}/{z(y)}")
The average length of a method, in LOC, is given by:
![E[LOC]={alpha r}/{2(d_0-u_0)}+O(e^{lambda}-1)](https://shape-of-code.com/wp-content/plugins/wpmathpub/phpmathpublisher/img/math_969.5_ffcacf0bb8190096d4d17fb475c0a290.png "E[LOC]={alpha r}/{2(d_0-u_0)}+O(e^{lambda}-1)") , where:
, where: }/{d_0+u_0}")
For C, the mean function length is 26.4 lines, and the values of  , , and need to be chosen subject to the constraint
, , and need to be chosen subject to the constraint  .
.
Combining the normalization factor with the requirement  , shows that as increases,
, shows that as increases, ") slowly decreases and
slowly decreases and ") slowly increases.
slowly increases.
One way to judge how closely a model matches reality is to use it to make predictions about behavior patterns that were not used to create the model. The behavior patterns used to build this model were: function/method length is a power law with exponent greater than 2. The mean length, ![E[LOC]](https://shape-of-code.com/wp-content/plugins/wpmathpub/phpmathpublisher/img/math_981.5_0ac27fa76bd7c6e393f3497c9f30db7e.png "E[LOC]") , is a tuneable parameter.
, is a tuneable parameter.
Ideally a model works across many languages, but to start, given the ease of measuring C source (using Coccinelle), this one language will be the focus.
I need to think of measurable source code patterns that are not an immediate consequence of the power law pattern used to create the model. Suggestions welcome.
It’s possible that the impact of factors not included in this model (e.g., statement correlation) is large enough to hide any nesting related patterns that are there. While different kinds of compound statements (e.g., if vs. for) may have different step probabilities, in C, and I suspect other languages, if-statement use dominates (Table 1713.1: if 16%, for 4.6% while 2.1%, non-compound statements 66%).
Early research on economies of scale for computer systems
Before microprocessor cost/performance wiped out (in the early 1990s) other cpu platforms (e.g., mainframes and minis), people argued that computer hardware benefited from economies of scale.
The claimed benefit was more bang for the buck, i.e., more compute for less money.
Checking this claim requires treating pre-microprocessor computer systems and the later microprocessor-based systems as two separate cases, because many of the factors driving costs and performance are very different.
Today’s large microprocessor-based computer systems achieve economies of scale through discounts from bulk purchases and spreading fixed costs across multiple systems. The data is available, and the economic analysis is straight forward.
A lack of reliable data on the costs of designing/building pre-microprocessor computer systems rules out an economic analysis of cost/performance from first principles. The data that was/is available is the cost of computer systems and some indicators of performance (such as instruction timings or benchmarks).
Now, the observed fact that the cost of compute was decreasing over time is unrelated to the claim that the cost of compute decreases as the size of the computer increases.
Assuming a power law relationship between computer cost,  , and size,
, and size,  , at a point in time, we have:
, at a point in time, we have:  , where is some constant. Economies of scale occur when:
, where is some constant. Economies of scale occur when: 
In his detailed cost/performance analysis of computers between 1944-1967, Kenneth Knight treated computers launched in the same year as effectively occurring at the same time. He also built a single model, with year included as an explanatory variable, which means the fitted rate of decrease is the same over all years (rather than varying between years).
The plot below uses Knight’s 1953-1961 data, and shows operations per second against seconds per dollar (a confusing combination, but what Knight used), with fitted regression lines for three years using Knight’s model (code and data)
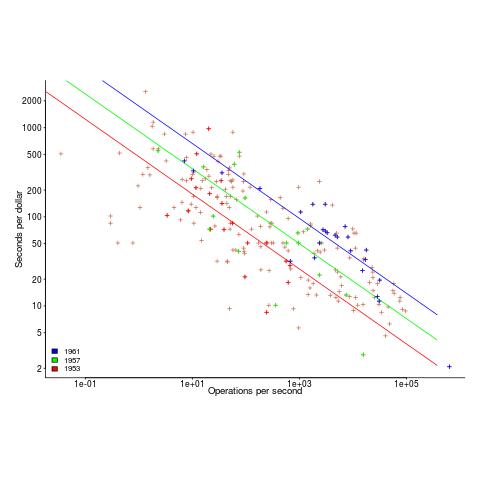
The fitted exponent for this form of x/y axis maps to a value which has , i.e., there are economies of scale.
It so happens that the value of the Knight’s fitted exponent is close to that proposed in a 1953 paper (“High speed arithmetic: The digital computer as a research tool”, no online copy):
It used to cost one cent to do a multiplication on a desk calculator; now it is more like four cents; but with these big machines we can do a million in an hour for $400, and that means twenty-five multiplications for a cent! I believe that there is a fundamental rule, which I modestly call Grosch's law, giving added economy only as the square root of the increase in speed-that is, to do a calculation ten times as cheaply you must do it one hundred times as fast. |
which did indeed become widely known as Grosch’s law.
Having been given a lucky kick-start by Knight (fitted individually, years are not close to Grosch’s law), checking for agreement with Grosch’s law became a focus for later studies. While various papers highlighted problems with the later data analysis (e.g., the regression techniques and sample noise producing mathematical artifacts), Grosch’s law ceased being a thing because mainframes/minicomputers ceased being a thing.
Did mainframe/mincomputers have economies of scale in the years after Knight’s data? It’s difficult to tell, the publicly available data is too sparse to support reliable analysis.
Recent Comments