Archive
C compiler conformance testing: with ChatGPT assistance
How can developers check that a compiler correctly implements all the behavior requirements contained in the corresponding language specification?
An obvious approach is to write lots of test cases for each distinct behavior; such a collection of tests is known as a validation suite, when used by a standard’s organization to test compilers/OS interfaces/etc. The extent to which a compiler’s behavior, when fed these tests, matches that listed in the language specification is a measure of its conformance.
In a world of many compilers with significant differences in behavior (i.e., pre-Open source), it makes economic sense for governments to sponsor the creation of validation suites, and/or companies to offer such suites commercially (mainly for C and C++). The spread of Open source compilers decimated compiler diversity, and compiler validation is fading into history.
New features continue to be added to Cobol, Fortran, C, and C++ by their respective ISO Standard’s committee. If governments are no longer funding updates to validation suites and the cost of commercial suites is too high for non-vendors (my experience is that compiler vendors find them to be cost-effective), how can developers check that a compiler conforms to the behavior specified by the Standard?
How much effort is required to create some minimal set of compiler conformance tests?
C is the language whose requirements I am most familiar with. The C Standard specifies that a conforming compiler issue a diagnostic for a violation of a requirement appearing in a Constraint clause, e.g., “For addition, either both operands shall have arithmetic type, or …”
There are 80 such clauses, containing around 530 non-blank lines, in N3301, the June 2024 draft. Let’s say 300+ distinct requirements, requiring a minimum of one test each. Somebody very familiar with the C Standard might take, say, 10 minutes per test, which is 3,000 minutes, or 50 hours, or 6.7 days; somebody slightly less familiar might take, say, at least an hour, which is 300+ hours, or 40+ days.
Lots of developers are using LLMs to generate source code from a description of what is needed. Given Constraint requirements in the C Standard, can an LLM generate tests that do a good enough job checking a compiler’s conformance to the C Standard?
Simply feeding the 157 pages from the Language chapter of the C Standard into an LLM, and asking it to generate tests for each Constraint requirement does not seem practical with the current state of the art; I’m happy to be proved wrong. A more focused approach might produce the desired tests.
Negative tests are likely to be the most challenging for an LLM to generate, because most publicly available source deals with positive cases, i.e., it is syntactically/semantically correct. The wording of Constraints sometimes specifies what usage is not permitted (e.g., clause 6.4.5.3 “A floating suffix df, dd, dl, DF, DD, or DL shall not be used in a hexadecimal floating literal.”), other times specifies what usage is permitted (e.g., clause 6.5.3.4 “The first operand of the . operator shall have an atomic, qualified, or unqualified structure or union type, and the second operand shall name a member of that type.”), or simply specifies a requirement (e.g., clause 6.7.3.2 “A member declaration that does not declare an anonymous structure or anonymous union shall contain a member declarator list.”).
I took the text from the 80 Constraint clauses, removed footnote numbers and rejoined words split at line-breaks. The plan was to prefix the text of each Constraint with instructions on the code requires. After some experimentation, the instructions I settled on were:
Write a sequence of very short programs which tests that a C compiler correctly flags each violation of the requirements contained in the following excerpt from the latest draft of the C Standard: |
Initially, excerpt was incorrectly spelled as except, but this did not seem to have any effect. Perhaps this misspelling is sufficiently common in the training data, that LLM weights support the intended association.
Experiments using Grok and ChatGPT 4o showed that both generated technically correct tests, but Grok generated code that was intended to be run (and was verbose), while the ChatGPT 4o output was brief and to the point; it did such a good job that I did not try any other LLMs. For this extended test, use of the web interface proved to be an effective approach. Interfacing via the API is probably more practical for larger numbers of requirements.
After some experimentation, I submitted the text from 31 Constraint clauses (I picked the non-trivial ones). The complete text of the questions and ChatGPT 4o responses (text files).
ChatGPT sometimes did not generate tests for all the requirements, when these were presented as they appeared in the Constraint, but did generate tests when the containing sentence was presented in isolation from other requirement sentences. For instance, the following sentence from clause 6.5.5 Cast Operators:
Conversions that involve pointers, other than where permitted by the constraints of 6.5.17.2, shall be specified by means of an explicit cast. |
was ignored when included as part of the complete Constraint, but when presented in isolation, reasonable tests were generated.
The responses never contained more than 10 test cases. I am guessing that this is the result of limits on response cpu time/length. Dividing the text of longer Constraints should solve this issue.
Some assumptions made by ChatGPT 4o about the implementation can be deduced from its responses, e.g., it appears to treat the type short as containing fewer than 32-bits (it assumes that a bit-field defined as a short containing 32-bits will be treated as a Constraint violation). This is not surprising, given the volume of public C source targeting the Intel x86.
I was impressed by the quality of the 242 test cases generated by ChatGPT 4o, which often included multiple tests for the same requirement (text files).
While it sometimes failed to produce a test for a requirement, I did not spot any incorrect tests (as in, not correctly testing for a violation of a listed requirement); the subset of tests feed through behaved as claimed), and I eventually found a prompt that appears to be creating a downloadable zip file of all the tests (most prompts resulted in a zip file containing some collection of 10 tests); the creation process is currently waiting for available cpu time. I now know that downloading a zip file containing one file per test, after each user prompt, is the more reliable option.
Modelling estimate/actual including uncertainty in the estimate
What is an effective technique for modelling the relationship between the time estimated to implement a task and the actual time taken to implement that task?
A regression model is the obvious approach. However, an important assumption made by the commonly used regression techniques is not met by estimate/actual project data
The commonly used regression techniques involve two kinds of variables: the explanatory variable and the response variable (also known as the independent and dependent variables). For instance, in the equation  ,
,  is the explanatory variable and
is the explanatory variable and  is the response variable.
is the response variable.
When fitting a regression model to measurement data, the fitted equation is assumed to have the form such as:  , where
, where  is uncertainty in the value of , with the valued assumed to have no uncertainty;
is uncertainty in the value of , with the valued assumed to have no uncertainty;  and
and  are constants fitted by the modelling process. The values returned by the model fitting process include an estimate for , as well as estimates for and .
are constants fitted by the modelling process. The values returned by the model fitting process include an estimate for , as well as estimates for and .
When running an experiment, the values of the explanatory variables(e.g., ) are chosen by the experimenter, with the subject providing the value of the response variable, e.g., .
What does this technical detail have to do with estimation data?
The task estimate/actual values are both provide by the subject (i.e., the developer), there is no experimenter providing one of the values; in fact there is no experiment, these are measurements of things that happened. Both the estimate and actual are response variables, and both contain some amount of uncertainty, and the fitting process needs to take this into account. The appropriate regression technique to use for this case is an errors-in-variables model, which fits the equation +epsilon") , with
, with  being the uncertainty in .
being the uncertainty in .
A previous post discussed the surprising behavior that can occur when failing to use errors-in-variables regression for where the data does not contain any explanatory variables, i.e., all the variables contain uncertainty.
The process of fitting an errors-in-variables regression model requires additional input, a value for has to be specified. Taking the example of task estimation, possible uncertainties in the estimate include: misunderstanding of the requirement(s), faded memory of the actual time previously taken by very similar tasks, an inaccurate model of developer skills, and a preference for using round numbers.
What data is available on the uncertainty of individual task estimates? I know of one study where, unknown to them, the individuals estimated the same task twice (in fact, seven people each estimated the same six distinct tasks twice, over a period of three-months). The plot below shows the first/second estimate made by each person for each of the six tasks, with the grey line showing where first==second estimate (code+data):
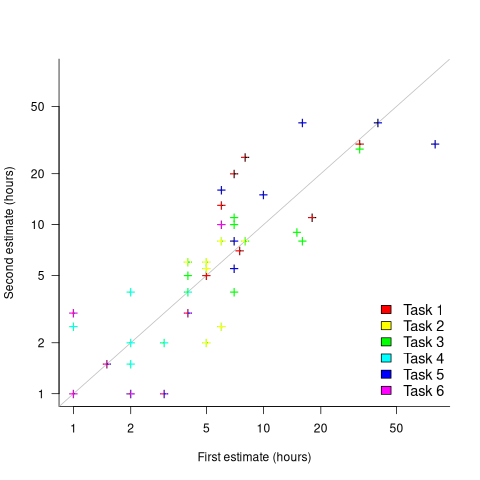
Assuming the estimation uncertainty in this experiment’s data is roughly equal to the estimation uncertainty in other estimation datasets, of tasks taking up to 20 hours, how might it be used to calculate a value for the uncertainty in estimated values?
Two possibilities include:
- Assuming that the uncertainty in both the first and second estimates is equal, a model can be fitted using Deming regression (which treats both variables as having the same uncertainty), and the residual standard error of this model used as the value of . This value for a fitted multiplicative model is 0.6 (code+data),
- using the mean of the relative errors,
}/Est_1") ; its value is 0.55.
; its value is 0.55.
How different are the models built using linear regression and errors-in-variables regression, for small task estimates?
A basic linear regression model fitted to the SiP estimation dataset is:  .
.
Updating this model, using SIMEX, to take into uncertainty in the value of  gives, for an uncertainty error of 0.55:
gives, for an uncertainty error of 0.55:  , and for an uncertainty error of 0.60:
, and for an uncertainty error of 0.60:  . The coefficients for the two models are essentially the same (code+data).
. The coefficients for the two models are essentially the same (code+data).
The exponent value is the noticeable difference between the linear regression and errors-in-variables regression models. Adding the assumed amount of uncertainty (based on data from one experiment) to the estimated value leads to a model where estimate/actual are very close to having a linear relationship.
Is this errors-in-variables model any closer to reality than the linear regression model? The model shows that the estimate/actual relationship is closer to linear than was previously thought. Until more data becomes available, we won’t know how close this relationship actually is.
The people who made the estimates in the SiP data also performed the work that took the recorded actual time. Assigning a task to a different person could produce both a different estimate and a different actual, but these possible values are unknown. On a larger scale, different companies bidding on the same contract specify different amounts and have different implementations times; data showing these differences.
if statement conditions, some basic measurements
The conditions contained in if-statements control all the decisions a program makes, yet relatively little is known about their characteristics.
A condition contains one or more clauses, for instance, the condition (a && b) contains two clauses that both need to be true, for the condition to be true. An earlier post modelled the number of clauses in Java conditions, and found an exponential decline (around 90% of conditions contained a single clause, for C this is around 85%).
The condition in a nested if-statement contains implicit decisions, because its evaluation depends on the conditions evaluated by its outer if-statements. I have long predicted that, on average, the number of clauses in a condition will decrease as if-statement nesting increases, because some decisions are subsumed by outer conditions. I have not seen any measurements on conditionals vs nesting, and this week this question reached the top of my to-do list.
I used Coccinelle to extract the text contained in each condition, along with the start/end line numbers of the associated if/else compound statement(s). After almost 20 years, Coccinelle is still the most flexible C source analysis tool available that does not require delving into compiler internals. The following is an example of the output (code and data):
file;stmt;if_line;if_col;cmpd_end;cmpd_line_end;expr sqlite-src-3460100/src/fkey.c;if;240;10;240;243;aiCol sqlite-src-3460100/src/fkey.c;if;217;6;217;217;! zKey sqlite-src-3460100/src/fkey.c;if;275;8;275;275;i == nCol sqlite-src-3460100/src/fkey.c;if;1428;6;1428;1433;aChange == 0 || fkParentIsModified ( pTab , pFKey , aChange , bChngRowid ) sqlite-src-3460100/src/fkey.c;if;808;4;808;808;iChildKey == pTab -> iPKey && bChngRowid sqlite-src-3460100/src/fkey.c;if;452;4;452;454;nIncr > 0 && pFKey -> isDeferred == 0 |
The conditional expressions (last column above) were reduced to a basic form involving simple variables and logical operators, along with operator counts. Some example output below (code and data):
simp_expr,land,lor,ternary v1,0,0,0 v1 && v2,1,0,0 v1 || v2,0,1,0 v1 && v2 && v3,2,0,0 v1 || ( v2 && v3 ),1,1,0 ( v1 && v2 ) || ( v3 && v4 ),2,1,0 ( v1 ? dm1 : dm2 ),0,0,1 |
The C source code projects measured were the latest stable versions of Vim (44,205 if-statements), SQLite (27,556 if-statements), and the Linux kernel (version 6.11.1; 1,446,872 if-statements).
A side note: I was surprised to see the ternary operator appearing in some conditions; in effect, an if within an if (see last line of the previous example). The ternary operator usually appears as a component of a large conditional expression (e.g., x + ( v1 ? dm1 : dm2 ) > y), rather than itself containing clauses, e.g., ( v1 ? dm1 : dm2 ) && v2. I have not seen the requirements for this operator discussed in any analysis of MC/DC.
The plot below shows the number of if-statements occurring at a given nesting level, along with regression fits, of the form  , to the Vim and SQLite data; the Linux data was better fit by a power law (code+data):
, to the Vim and SQLite data; the Linux data was better fit by a power law (code+data):
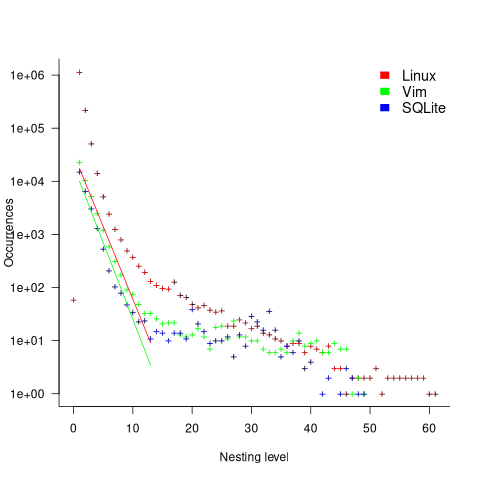
I suspect that most of the deeply nested levels in Vim and SQLite are the results of long else if chains, which, while technically highly nested, could all have been written having the same nesting level, such as the following:
if (strcmp(x, "abc")) ; // code else if (strcmp(x, "xyz")) ; // code else if (strcmp(x, "123")) ; // code |
This if else pattern does not appear to be common in Linux. Perhaps ‘regularizing’ the if else sequences in Vim and SQLite will move the distribution towards a power law (i.e., like Linux).
Average nesting depth will also be affected by the average number of lines per function, with functions containing more statements providing the opportunity for more deeply nested if-statements (rather than calling a function containing nested if-statements).
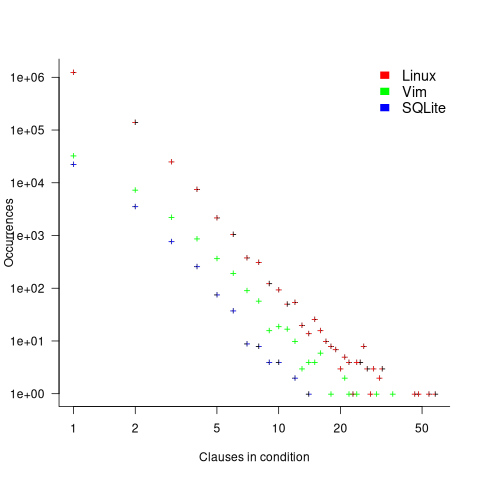
The plot below shows the number of occurrences of conditions containing a given number of clauses. Neither the exponential and power law are good fits, and log-log axis are used because it shows the points are closer to forming a straight line (code+data):
The plot below shows the nesting level and number of clauses in the condition for each of the 1,446,872 if-statements in the Linux kernel. Each value was ‘jittered’ to distribute points about their actual value, creating a more informative visualization (code+data):
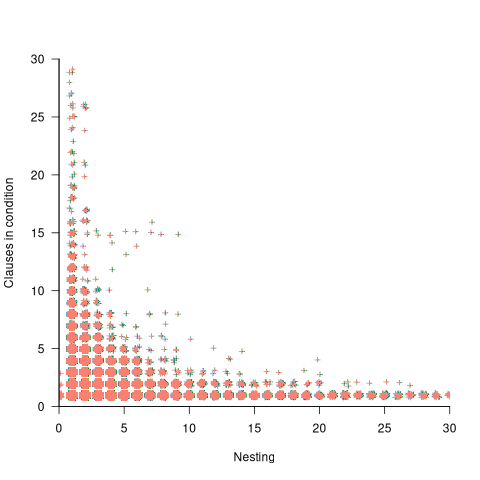
As expected, the likelihood of a condition containing multiple clauses does decrease with nesting level. However, with around 85% of conditions containing a single clause, the fitted regression models essential predict one clause for all nesting levels.
MC/DC a step towards safety critical Open source software
Open source projects and safety critical software are at opposite ends of the development process spectrum. From the user perspective, when an Open source project becomes very widely used within its application domain, there is a huge incentive to run it within safety critical domains.
How might software that was not originally developed using a safety critical process be certified for use in a safety critical domain?
A mass of process bureaucracy has sprung up around building software systems whose correct operation is depended on in safety critical situations. There is no evidence that any process bureaucracy produces more reliable software than any other process bureaucracy, and organizations adapt processes to fit within the rules and deliver a system given the available funding.
Some processes specify measurable output requirements, and being able to show that a program developed using an Open source process meets the desired measurable requirements is a step on the path to possible certification. One of the requirements specified in DO-178C (“Software Considerations in Airborne Systems and Equipment Certification”, a non-free publication) for level A: Anomalous behavior produces a catastrophic failure condition, is 100% Modified condition/decision coverage (MC/DC) of the source code. In the automotive world, the same coverage requirement is specified for Automotive Safety Integrity Level D of ISO 26262. As far as I know, the only DO-178C certified Open source program, at this level (which does not imply being safety critical), is SQLite.
The two main hurdles to the adoption of MC/DC by Open source projects are the huge amount of work involved in creating the necessary tests and, until recently, the lack of industrial strength Open source tools for measuring MC/DC (there are many commercial tools).
While compiler support for statement coverage has long been available in both GCC and clang, support for MC/DC only became available in an official release of clang this year (the initial functionality was pushed in 2021). The official releases of GCC do not yet support MC/DC, but a patch has been available since 2022 (talk by author).
Making available an industrial strength Open source compiler that supports MC/DC testing removes one barrier on the path to DO-178C certification of Open source programs. The certification process itself requires that support tools meet certain minimum requirements, which are specified in DO-330. A tool used as part of the verification process of a program at Level A needed not itself have 100% MC/DC, or even 100% statement coverage. The LLVM project tracks statement coverage, which is not even close to 100%.
Are there any coding constructs that get in the way of achieving 100% MC/DC?
It’s possible to write a condition that cannot be tested in a way that meets the MC/DC requirement: Each condition in a decision is shown to independently affect the outcome of the decision. For instance, in the following condition:
if ((A && B) || (!A && C)) |
the value of the variable A affects the outcome of both operands of ||, and the complete expression cannot be rewritten, using just A, B, C, to change this situation. The complete boolean expression is said to be strongly coupled. An expression involving the same variable in multiple relational or equality tests (e.g., (x > 0) && (x < 10)) is said to be weakly coupled.
An analysis of the Ada source code (appendix C) contained in five aircraft flight recorders finds examples of strongly and weakly coupled conditions. This suggests that occurrences of these construct in source code does not prevent a program becoming DO-178C certified.
Linux must be the prime candidate for an Open source program being considered for some kind of safety critical certification. A kernel patch to support MC/DC profiling is in the works (with a kernel MC/DC of around 2.33%, lots of new tests are going to have to be written). Lots of other significant certification requirements also need to be met.
In C, around 90% of if-statements contain a single conditional test (statement 1739), while in Java around 90% of if-statements contain a single conditional test, with around 0.1% containing five or more.
A kind of coverage that is not so often discussed is object code structural coverage, i.e., coverage based on the conditions contained in generated machine code, such as from a compiler. Object code coverage is designed to handle the possibility of compilers generating code containing conditions that are not present in the original source.
Some compilers generate the same machine code for both top level if-statements in the following code:
int g; void square(int a, int b, int c) { if (a && b && c) g++; if (a) if (b) if (c) g++; } |
Recent Comments