Archive
Unneeded requirements implemented in Waterfall & Agile
Software does not wear out, but the world in which it runs evolves. Time and money is lost when, after implementing a feature in software, customer feedback is that the feature is not needed.
How do Waterfall and Agile implementation processes compare in the number of unneeded feature/requirements that they implement?
In a Waterfall process, a list of requirements is created and then implemented. The identity of ‘dead’ requirements is not known until customers start using the software, which is not until it is released at the end of development.
In an Agile process, a list of requirements is used to create a Minimal Viable Product, which is released to customers. An iterative development processes, driven by customer feedback, implements requirements, and makes frequent releases to customers, which reduces the likelihood of implementing known to be ‘dead’ requirements. Previously implemented requirements may be discovered to have become ‘dead’.
An analysis of the number of ‘dead’ requirements implemented by the two approaches appears at the end of this post.
The plot below shows the number of ‘dead’ requirements implemented in a project lasting a given number of working days (blue/red) and the difference between them (green), assuming that one requirement is implemented per working day, with the discovery after 100 working days that a given fraction of implemented requirements are not needed, and the number of requirements in the MVP is assumed to be small (fractions 0.5, 0.1, and 0.05 shown; code):
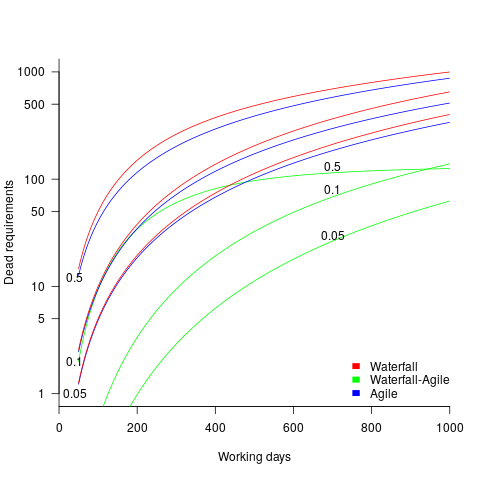
The values calculated using one requirement implemented per day scales linearly with requirements implemented per day.
By implementing fewer ‘dead’ requirements, an Agile project will finish earlier (assuming it only implements all the needed requirements of a Waterfall approach, and some subset of the ‘dead’ requirements). However, unless a project is long-running, or has a high requirements’ ‘death’ rate, the difference may not be compelling.
I’m not aware of any data on rate of discovery of ‘dead’ implemented requirements (there is some on rate of discovery of new requirements); as always, pointers to data most welcome.
The Waterfall projects I am familiar with, plus those where data is available, include some amount of requirement discovery during implementation. This has the potential to reduce the number of ‘dead’ implemented requirements, but who knows by how much.
As the size of Minimal Viable Product increases to become a significant fraction of the final software system, the number of fraction of ‘dead’ requirements will approach that of the Waterfall approach.
There are other factors that favor either Waterfall or Agile, which are left to be discussed in future posts.
The following is an analysis of Waterfall/Agile requirements’ implementation.
Define:
 is the fraction of requirements per day that remain relevant to customers. This value is likely to be very close to one, e.g.,
is the fraction of requirements per day that remain relevant to customers. This value is likely to be very close to one, e.g.,  .
.
 requirements implemented per working day.
requirements implemented per working day.
Waterfall
The implementation of  requirements takes
requirements takes  days, and the number of implemented ‘dead’ requirements is (assuming that the no ‘dead’ requirements were present at the end of the requirements gathering phase):
days, and the number of implemented ‘dead’ requirements is (assuming that the no ‘dead’ requirements were present at the end of the requirements gathering phase):
")
As  effectively all implemented requirements are ‘dead’.
effectively all implemented requirements are ‘dead’.
Agile
The number of implemented ‘live’ requirements on day  is given by:
is given by:

with the initial condition that the number of implemented requirements at the start of the first day of iterative development is the number of requirements implemented in the Minimum Viable Product, i.e.,  .
.
Solving this difference equation gives the number of ‘live’ requirements on day :
+F_{live}}")
as  ,
,  approaches to its maximum value of
approaches to its maximum value of 
Subtracting the number of ‘live’ requirements from the total number of requirements implemented gives:

or
+n*R_{done}(1-1/{n(1-F_{live})+F_{live}})")
or
+n*R_{done}{n-1}/{n+F_{live}/(1-F_{live})}")
as effectively all implemented requirements are ‘dead’, because the number of ‘live’ requirements cannot exceed a known maximum.
Update
The paper A software evolution experiment found that in a waterfall project, 40% of modules in the delivered system were not required.
Stochastic rounding reemerges
Just like integer types, floating-point types are capable of representing a finite number of numeric values. An important difference between integer and floating types is that the result of arithmetic and relational operations using integer types is exactly representable in an integer type (provided they don’t overflow), while the result of arithmetic operations using floating types may not be exactly representable in the corresponding floating type.
When the result of a floating-point operation cannot be exactly represented, it is rounded to a value that can be represented. Rounding modes include: round to nearest (the default for IEEE-754), round towards zero (i.e., truncated), round up (i.e., towards  ), round down (i.e., towards
), round down (i.e., towards  ), and round to even. The following is an example of round to nearest:
), and round to even. The following is an example of round to nearest:
123456.7 = 1.234567 × 10^5
101.7654 = 0.001017654 × 10^5
Adding
= 1.235584654 × 10^5
Round to nearest
= 1.235585 × 10^5 |
There is another round mode, one implemented in the 1950s, which faded away but could now be making a comeback: Stochastic rounding. As the name suggests, every round up/down decision is randomly chosen; a Google patent makes some claims about where the entropy needed for randomness can be obtained, and Nvidia also make some patent claims).
From the developer perspective, stochastic rounding has a very surprising behavior, which is not present in the other IEEE rounding modes; stochastic rounding is not monotonic. For instance: z < x+y does not imply that 0<(x+y)-z, because x+y may be close enough to z to have a 50% chance of being rounded to one of z or the next representable value greater than z, and in the comparison against zero the rounded value of (x+y) has an uncorrelated probability of being equal to z (rather than the next representable greater value).
For some problems, stochastic rounding avoids undesirable behaviors that can occur when round to nearest is used. For instance, round to nearest can produce correlated rounding errors that cause systematic error growth (by definition, stochastic rounding is uncorrelated); a behavior that has long been known to occur when numerically solving differential equations. The benefits of stochastic rounding are obtained for calculations involving long chains of calculations; the rounding error of the result of operations is guaranteed to be proportional to  , i.e., just like a 1-D random walk, which is not guaranteed for round to nearest.
, i.e., just like a 1-D random walk, which is not guaranteed for round to nearest.
While stochastic rounding has been supported by some software packages for a while, commercial hardware support is still rare, with Graphcore's Intelligence Processing Unit being one. There are some research chips supporting stochastic rounding, e.g., Intel's Loihi.
What applications, other than solving differential equations, involve many long chain calculations?
Training of machine learning models can consume many cpu hours/days; the calculation chains just go on and on.
Machine learning is considered to be a big enough market for hardware vendors to support half-precision floating-point. The performance advantages of half-precision floating-point are large enough to attract developers to reworking code to make use of them.
Is the accuracy advantage of stochastic rounding a big enough selling point that hardware vendors will provide the support needed to attract a critical mass of developers willing to rework their code to take advantage of improved accuracy?
It's possible that the intrinsically fuzzy nature of many machine learning applications swamps the accuracy advantage that stochastic rounding can have over round to nearest, out-weighing the costs of supporting it.
The ecosystem of machine learning based applications is still evolving rapidly, and we will have to wait and see whether stochastic rounding becomes widely used.
Some human biases in conditional reasoning
Tracking down coding mistakes is a common developer activity (for which training is rarely provided).
Debugging code involves reasoning about differences between the actual and expected output produced by particular program input. The goal is to figure out the coding mistake, or at least narrow down the portion of code likely to contain the mistake.
Interest in human reasoning dates back to at least ancient Greece, e.g., Aristotle and his syllogisms. The study of the psychology of reasoning is very recent; the field was essentially kick-started in 1966 by the surprising results of the Wason selection task.
Debugging involves a form of deductive reasoning known as conditional reasoning. The simplest form of conditional reasoning involves an input that can take one of two states, along with an output that can take one of two states. Using coding notation, this might be written as:
if (p) then q if (p) then !q if (!p) then q if (!p) then !q |
The notation used by the researchers who run these studies is a 2×2 contingency table (or conditional matrix):
OUTPUT
1 0
1 A B
INPUT
0 C D |
where: A, B, C, and D are the number of occurrences of each case; in code notation, p is the input and q the output.
The fertilizer-plant problem is an example of the kind of scenario subjects answer questions about in studies. Subjects are told that a horticultural laboratory is testing the effectiveness of 31 fertilizers on the flowering of plants; they are told the number of plants that flowered when given fertilizer (A), the number that did not flower when given fertilizer (B), the number that flowered when not given fertilizer (C), and the number that did not flower when not given any fertilizer (D). They are then asked to evaluate the effectiveness of the fertilizer on plant flowering. After the experiment, subjects are asked about any strategies they used to make judgments.
Needless to say, subjects do not make use of the available information in a way that researchers consider to be optimal, e.g., Allan’s  index
index -P(B vert D)=A/{A+B}-C/{C+D}") (sorry about the double,
(sorry about the double,  , rather than single, vertical lines).
, rather than single, vertical lines).
What do we know after 40+ years of active research into this basic form of conditional reasoning?
The results consistently find, for this and other problems, that the information A is given more weight than B, which is given by weight than C, which is given more weight than D.
That information provided by A and B is given more weight than C and D is an example of a positive test strategy, a well-known human characteristic.
Various models have been proposed to ‘explain’ the relative ordering of information weighting: gtw(B) gt w(C) gt w(D)") , e.g., that subjects have a bias towards sufficiency information compared to necessary information.
, e.g., that subjects have a bias towards sufficiency information compared to necessary information.
Subjects do not always analyse separate contingency tables in isolation. The term blocking is given to the situation where the predictive strength of one input is influenced by the predictive strength of another input (this process is sometimes known as the cue competition effect). Debugging is an evolutionary process, often involving multiple test inputs. I’m sure readers will be familiar with the situation where the output behavior from one input motivates a misinterpretation of the behaviour produced by a different input.
The use of logical inference is a commonly used approach to the debugging process (my suggestions that a statistical approach may at times be more effective tend to attract odd looks). Early studies of contingency reasoning were dominated by statistical models, with inferential models appearing later.
Debugging also involves causal reasoning, i.e., searching for the coding mistake that is causing the current output to be different from that expected. False beliefs about causal relationships can be a huge waste of developer time, and research on the illusion of causality investigates, among other things, how human interpretation of the information contained in contingency tables can be ‘de-biased’.
The apparently simple problem of human conditional reasoning over two variables, each having two states, has proven to be a surprisingly difficult to model. It is tempting to think that the performance of professional software developers would be closer to the ideal, compared to the typical experimental subject (e.g., psychology undergraduates or Mturk workers), but I’m not sure whether I would put money on it.
Evidence-based Software Engineering book: two years later
Two years ago, my book Evidence-based Software Engineering: based on the publicly available data was released. The first two weeks saw 0.25 million downloads, and 0.5 million after six months. The paperback version on Amazon has sold perhaps 20 copies.
How have the book contents fared, and how well has my claim to have discussed all the publicly available software engineering data stood up?
The contents have survived almost completely unscathed. This is primarily because reader feedback has been almost non-existent, and I have hardly spent any time rereading it.
In the last two years I have discovered maybe a dozen software engineering datasets that would have been included, had I known about them, and maybe another dozen non-software related datasets that could have been included in the Human behavior/Cognitive capitalism/Ecosystems/Reliability chapters. About half of these have been the subject of blog posts (links below), with the others waiting to be covered.
Each dataset provides a sliver of insight into the much larger picture that is software engineering; joining the appropriate dots, by analyzing multiple datasets, can provide a larger sliver of insight into the bigger picture. I have not spent much time attempting to join dots, but have joined a few tiny ones, and a few that are not so small, e.g., Estimating using a granular sequence of values and Task backlog waiting times are power laws.
I spent the first year, after the book came out, working through the backlog of tasks that had built up during the 10-years of writing. The second year was mostly dedicated to trying to find software project data (including joining Twitter), and reading papers at a much reduced rate.
The plot below shows the number of monthly downloads of the A4 and mobile friendly pdfs, along with the average kbytes per download (code+data):
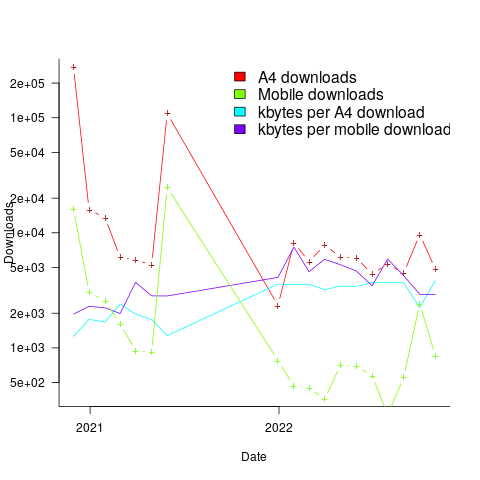
The monthly averages for 2022 are around 6K A4 and 700 mobile friendly pdfs.
I have been averaging one in-person meetup per week in London. Nearly everybody I tell about the book has not previously heard of it.
The following is a list of blog posts either analyzing existing data or discussing/analyzing new data.
Introduction
analysis: Software effort estimation is mostly fake research
analysis: Moore’s law was a socially constructed project
Human behavior
data (reasoning): The impact of believability on reasoning performance
data: The Approximate Number System and software estimating
data (social conformance): How large an impact does social conformity have on estimates?
data (anchoring): Estimating quantities from several hundred to several thousand
data: Cognitive effort, whatever it might be
Ecosystems
data: Growth in number of packages for widely used languages
data: Analysis of a subset of the Linux Counter data
data: Overview of broad US data on IT job hiring/firing and quitting
Projects
analysis: Delphi and group estimation
analysis: The CESAW dataset: a brief introduction
analysis: Parkinson’s law, striving to meet a deadline, or happenstance?
analysis: Evaluating estimation performance
analysis: Complex software makes economic sense
analysis: Cost-effectiveness decision for fixing a known coding mistake
analysis: Optimal sizing of a product backlog
analysis: Evolution of the DORA metrics
analysis: Two failed software development projects in the High Court
data: Pomodoros worked during a day: an analysis of Alex’s data
data: Multi-state survival modeling of a Jira issues snapshot
data: Over/under estimation factor for ‘most estimates’
data: Estimation accuracy in the (building|road) construction industry
data: Rounding and heaping in non-software estimates
data: Patterns in the LSST:DM Sprint/Story-point/Story ‘done’ issues
data: Shopper estimates of the total value of items in their basket
Reliability
analysis: Most percentages are more than half
Statistical techniques
Fitting discontinuous data from disparate sources
Testing rounded data for a circular uniform distribution
Post 2020 data
Pomodoros worked during a day: an analysis of Alex’s data
Impact of number of files on number of review comments
Finding patterns in construction project drawing creation dates
Recent Comments