Archive
My 2025 in software engineering
Unrelenting talk of LLMs now infests all the software ecosystems I frequent.
- Almost all the papers published (week) daily on the Software Engineering arXiv have an LLM themed title. Way back when I read these LLM papers, they seemed to be more concerned with doing interesting things with LLMs than doing software engineering research.
- Predictions of the arrival of AGI are shifting further into the future. Which is not difficult given that a few years ago, people were predicting it would arrive within 6-months. Small percentage improvements in benchmark scores are trumpeted by all and sundry.
- Towards the end of the year, articles explaining AI’s bubble economics, OpenAI’s high rate of loosing money, and the convoluted accounting used to fund some data centers, started appearing.
Coding assistants might be great for developer productivity, but for Cursor/Claude/etc to be profitable, a significant cost increase is needed.
Will coding assistant companies run out of money to lose before their customers become so dependent on them, that they have no choice but to pay much higher prices?
With predictions of AGI receding into the future, a new grandiose idea is needed to fill the void. Near the end of the year, we got to hear people who must know it’s nonsense claiming that data centers in space would be happening real soon now.
I attend one or two, occasionally three, evening meetups per week in London. Women used to be uncommon at technical meetups. This year, groups of 2–4 women have become common in meetings of 20+ people (perhaps 30% of attendees); men usually arrive individually. Almost all women I talked to were (ex) students looking for a job; this was also true of the younger (early 20s) men I spoke to. I don’t know if attending meetups been added to the list of things to do to try and find a job.
Tom Plum passed away at the start of the year. Tom was a softly spoken gentleman whose company, PlumHall, sold a C, and then C++, compiler validation suite. Tom lived on Hawaii, and the C/C++ Standard committees were always happy to accept his invitation to host an ISO meeting. The assets of PlumHall have been acquired by Solid Sands.
Perennial was the other major provider of C/C++ validation suites. It’s owner, Barry Headquist, is now enjoying his retirement in Florida.
The evidence-based software engineering Discord channel continues to tick over (invitation), with sporadic interesting exchanges.
What did I learn/discover about software engineering this year?
Software reliability research is a bigger mess than I had previously thought.
I now regularly use LLMs to find mathematical solutions to my experimental models of software engineering processes. Most go nowhere, but a few look like they have potential (here and here and here).
Analysis/data in the following blog posts, from the last 12-months, belongs in my book Evidence-Based Software Engineering, in some form or other (2025 was a bumper year):
Naming convergence in a network of pairwise interactions
Lifetime of coding mistakes in the Linux kernel
Decline in downloads of once popular packages
Distribution of method chains in Java and Python
Modeling the distribution of method sizes
Distribution of integer literals in text/speech and source code
Percentage of methods containing no reported faults
Half-life of Open source research software projects
Positive and negative descriptions of numeric data
Impact of developer uncertainty on estimating probabilities
After 55.5 years the Fortran Specialist Group has a new home
When task time measurements are not reported by developers
Evolution has selected humans to prefer adding new features
One code path dominates method execution
Software_Engineering_Practices = Morals+Theology
Long term growth of programming language use
Deciding whether a conclusion is possible or necessary
CPU power consumption and bit-similarity of input
Procedure nesting a once common idiom
Functions reduce the need to remember lots of variables
Remotivating data analysed for another purpose
Half-life of Microsoft products is 7 years
How has the price of a computer changed over time?
Deep dive looking for good enough reliability models
Apollo guidance computer software development process
Example of an initial analysis of some new NASA data
Extracting information from duplicate fault reports
I visited Foyles bookshop on Charing cross road during the week (if you’re ever in London, browsing books in Foyles is a great way to spend an afternoon).
Computer books once occupied almost half a floor, but is now down to five book cases (opposite is statistics occupying one book case, and the rest of mathematics in another bookcase):

Around the corner, Gender Studies and LGBTQ+ occupies seven bookcases (the same as last year, as I recall):

My 2024 in software engineering
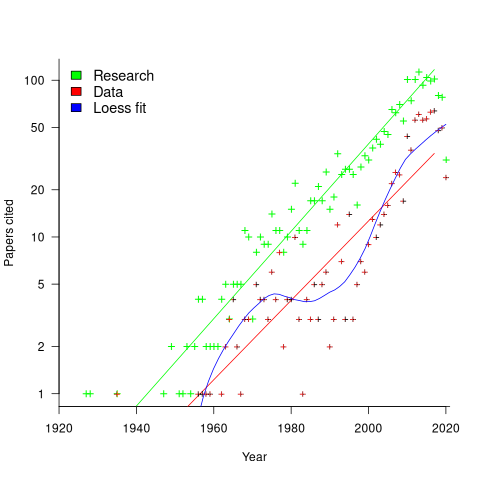
Readers are unlikely to have noticed something that has not been happening during the last few years. The plot below shows, by year of publication, the number of papers cited (green) and datasets used (red) in my 2020 book Evidence-Based Software Engineering. The fitted red regression lines suggest that the 20s were going to be a period of abundant software engineering data; this has not (yet?) happened (the blue line is a local regression fit, i.e., loess). In 2020 COVID struck, and towards the end of 2022 Large Language Models appeared and sucked up all the attention in the software research ecosystem, and there is lots of funding; data gathering now looks worse than boring (code+data):
LLMs are showing great potential as research tools, but researchers are still playing with them in the sandpit.
How many AI startups are there in London? I thought maybe one/two hundred. A recruiter specializing in AI staffing told me that he would estimate around four hundred; this was around the middle of the year.
What did I learn/discover about software engineering this year?
Regular readers may have noticed a more than usual number of posts discussing papers/reports from the 1960s, 1970s and early 1980s. There is a night and day difference between software engineering papers from this start-up period and post mid-1980s papers. The start-up period papers address industry problems using sophisticated mathematical techniques, while post mid-1980s papers pay lip service to industrial interests, decorating papers with marketing speak, such as maintainability, readability, etc. Mathematical orgasms via the study of algorithms could be said to be the focus of post mid-1980s researchers. So-called software engineering departments ought to be renamed as Algorithms department.
Greg Wilson thinks that the shift happened in the 1980s because this was the decade during which the first generation of ‘trained in software’ people (i.e., emphasis on mathematics and abstract ideas) became influential academics. Prior generations had received a practical training in physics/engineering, and been taught the skills and problem-solving skills that those disciplines had refined over centuries.
My research is a continuation of the search for answers to the same industrial problems addressed by the start-up researchers.
In the second half of the year I discovered the mathematical abilities of LLMs, and started using them to work through the equations for various models I had in mind. Sometimes the final model turned out to be trivial, but at least going through the process cleared away the complications in my mind. According to reports, OpenAI’s next, as yet unreleased, model has super-power maths abilities. It will still need a human to specify the equations to solve, so I am not expecting to have nothing to blog about.
Analysis/data in the following blog posts, from the last 12-months, belongs in my book Evidence-Based Software Engineering, in some form or other:
Small business programs: A dataset in the research void
Putnam’s software equation debunked (the book is non-committal).
if statement conditions, some basic measurements
Number of statement sequences possible using N if-statements; perhaps.
A new NASA software dataset from the 1970s
A surprising retrospective task estimation dataset
Average lines added/deleted by commits across languages
Census of general purpose computers installed in the 1960s
Some information on story point estimates for 16 projects
Agile and Waterfall as community norms
Median system cpu clock frequency over last 15 years
The evidence-based software engineering Discord channel continues to tick over (invitation), with sporadic interesting exchanges.
Recent Comments