Archive
Distribution of small project completion times
Records of project estimates and actual task times show that round numbers are very common. Various possible reasons have been suggested for why actual times are often reported as a round number. This post analyses the impact of round number reports of actual times on the accuracy of estimates.
The plot below shows the number of tasks having a given reported completion time for 1,525 tasks estimated to take 1-hour (code+data):
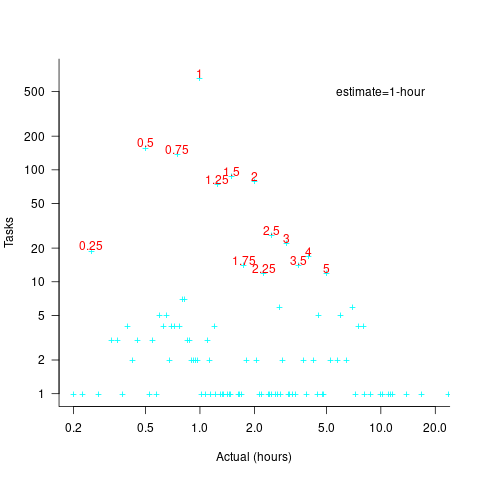
Of those 1,525 tasks estimated to take 1-hour, 44% had a reported completion time of 1-hour, 26% took less than 1-hour and 30% took more than 1-hour. The mean is 1.6 hours and the standard deviation 7.1. The spikiness of the distribution of actual times rules out analytical statistical analysis of the distribution.
If a large task is broken down into, say,  smaller tasks, all estimated to take the same amount of time
smaller tasks, all estimated to take the same amount of time  , what is the distribution of actual times for the large task?
, what is the distribution of actual times for the large task?
In the case of just two possible actual times to complete each smaller task, some percentage,  , of tasks are completed in actual time
, of tasks are completed in actual time  , and some percentage,
, and some percentage,  , completed in actual time
, completed in actual time  (with
(with  ). The probability distribution of the large task time,
). The probability distribution of the large task time, ") , for the two actual times case is:
, for the two actual times case is:
=(matrix{2}{1}{N k})(1-p_{t1})^k {p_{t1}}^{N-k}=(matrix{2}{1}{N k}){p_{t2}}^k (1-p_{t2})^{N-k}")
where:  , and
, and  .
.
The right-most equation is the probability distribution of the Binomial distribution, ") . The possible completion times for the large task start at
. The possible completion times for the large task start at  , followed by time increments of .
, followed by time increments of .
When there are three possible actual completion times for each smaller task, the calculation is complicated, and become more complicated with each new possible completion time.
A practical approach is to use Monte Carlo simulation. This involves simulating lots of large tasks containing smaller tasks. A sample of tasks is randomly drawn from the known 1,525 task actual times, and these actual times added to give one possible completion time. Running this process, say, 10,000 times produces what is known as the empirical distribution for the large task completion time.
The plot below shows the empirical distribution  smaller 1-hour tasks. The blue/green points show two peaks, the higher peak is a consequence of the use of round numbers, and the lower peak a consequence of the many non-round numbers. If the total times are rounded to 15 minute times, red points, a smoother distribution with a single peak emerges (code+data):
smaller 1-hour tasks. The blue/green points show two peaks, the higher peak is a consequence of the use of round numbers, and the lower peak a consequence of the many non-round numbers. If the total times are rounded to 15 minute times, red points, a smoother distribution with a single peak emerges (code+data):

When a large task involves smaller tasks estimated to take a variety of times, the empirical distribution of the actual time for each estimated time can be combined to give an empirical distribution of the large task (see sum_prob_distrib).
Provided enough information on task completion times is available, this technique works does what it says on the tin.
Superoptimizers are back in vogue
There has always been the need for a few developers with in-depth knowledge of a particular cpu architecture to sit down and think very hard about how best to implement a snippet of code performing some operation in assembly language, e.g., library implementors wanting the tightest code for a critical inner loop or compiler writers who need to map from intermediate code to machine code.
In 1987 Massalin published his now famous paper that introduced the term Superoptimizer; a program that enumerates all possible combinations of instruction sequences until the shortest/fastest one producing the desired output from the given input is found (various heuristics were used to prune the search space e.g., only considering 15 or so opcodes, and the longest sequence it ever generated contained 12 instructions).
While the idea was widely talked about, it never caught on in practice (a special purpose branch eliminator was produced for GCC; Hacker’s Delight also includes a stand-alone system). Perhaps the guild of mindbogglingly-obtuse-but-fast-instruction-sequences black-balled it (apprentices have to spend several years doing nothing but writing assembly code for their chosen architecture, thinking about how to make it go faster and/or be shorter and only talk to other apprentices/members and communicate with non-converts exclusively about their latest neat sequence), or perhaps it was just a case of not invented here (writing machine code used to be something that even run-of-the-mill developers got to do every now and again), or perhaps it was not considered cost-effective to build a superoptimizer for a given project (I don’t know of anyone offering a generic tool that could be tailored for specific cases) or perhaps developers were happy to just ride the wave of continually faster processors.
It was not until 2008 with Bansal’s thesis that superoptimizer research started to take off (as in paper publication rate increased from once every five years to more than one a year). Bansal found a new market, binary translation i.e., translating the binary of a program built to run on one kind of cpu to run on a different kind of cpu, for instance the Mac 68K emulator.
Bansal and other researchers’ work was oriented towards relatively short instruction sequences. To be really useful, some way of handling longer sequences was needed.
A few days ago Stochastic Superoptimization arrived on the scene (or rather a paper describing it became available for download). Schkufza, Sharma and Aiken use Markov chain Monte Carlo methods to sample the possible instruction sequences rather than generating all of them. The paper gives a 116 instruction example from which the author’s tool removed 16 lines to produce code that went 1.6 times faster (only 30 ‘core’ instructions were given in paper); what is also very interesting is that the tool operates on compiler generated output (gcc/llvm), suggesting the usage build program, profile it and then stochastic superoptimize the hot spots.
Markov chains and Monte Carlo methods are trendy topics that researchers like to write about, so we will certainly see more papers in this area.
These days few developers have had hands-on experience with machine code, so the depth of expertise that was once easy to find is now rare, processors have many more weird and wonderful instructions often interacting with older instructions in obscure ways, and the cpu architecture landscape continues to change regularly. The time may have arrived for superoptimizers to be widely used by industry.
Of course, superoptimizers can work at any level of abstraction, including expression trees built directly from some complicated floating-point calculation that needs to be optimized for accuracy or speed.
Recent Comments