Archive
Distribution of method chains in Java and Python
Some languages support three different ways of organizing a sequence of functions/methods, with calls taking as their first argument the value returned by the immediately prior call. For instance, Java supports the following possibilities:
r1=f1(val); r2=f2(r1); r3=f3(r2); // Sequential calls r3=f3(f2(f1(val))); // Nested calls, read right to left r3=val.f1().f2().f3(); // Method chain, read left to right |
Simula 67 was the first language to support the dot-call syntax used to code method chains. Ten years later Smalltalk-76 supported sending a message to the result of a prior send, which could be seen as a method chain rather than a nested call (because it is read left to right; Smalltalk makes minimal use of punctuator characters, so the syntax is not distinguishable).
How common are method chains in source code, and what is the distribution of chain length? Two studies have investigated this question: An Empirical Study of Method Chaining in Java by Nakamaru (PhD thesis), Matsunaga, Akiyama, Yamazaki, and Chiba, and Method Chaining Redux: An Empirical Study of Method Chaining in Java, Kotlin, and Python by Keshk, and Dyer.
The plot below shows the number of Java method chains having a given length, for code available in a given year. The red line is a fitted regression line for 2018, based on a model fitted to the complete dataset (code and data):
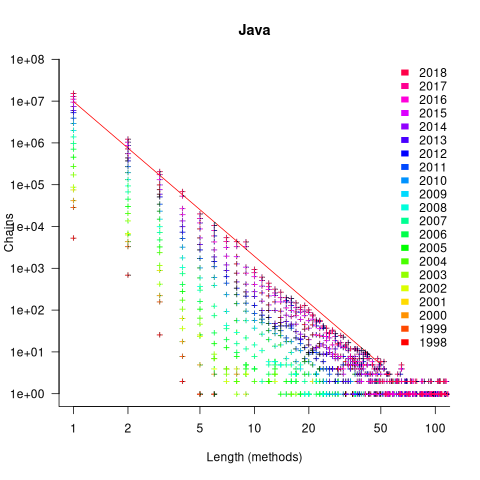
The fitted regression model is:

Why is the number of chains of all lengths growing by around 46% per year? I think this growth is driven by the growth in the amount of source measured. Measurements show that the percentage of source lines containing a method call is roughly constant. In the plot above, the number of unchained methods (i.e., chains of length one) increases in-step with the growth of chained methods. All chain lengths will grow at the same rate, if the source that contains them is growing.
What is responsible for the step change in the number of chains at around 10 methods? Nakamaru classified a random sample of 280 chains, and found that roughly 80% of chains longer than eight methods built an object, e.g., the following chain:
MoreObjects.toStringHelper(this) .add("iLine" , iLine) .add("lastK" , lastK) .add("spacesPending", spacesPending) .add("newlinesPending", newlinesPending) .add("blankLines", blankLines) .add("super", super.toString()) .toString() |
Are these chain usage patterns present in Python? The plot below shows the number of Python method chains having a given length, for code available in a given year. The red line is a fitted regression line for 2020, based on a model fitted to the complete dataset (code and data):

The fitted regression model is:

While this model is almost identical to the model fitted to the Java data (the annual growth rate is 39%), the above plot shows a large step change after chains of length two. Keshk’s paper focuses on replicating Nakamaru’s Java results, and then briefly discusses Python. I have an assortment of explanations, but nothing stands out.
Within code, how are method calls split between single calls and a chain of two or more calls?
The fractions in the plot below are calculated as the ratio of chains of length one (i.e., single method call) against chains containing two or more methods. The “j” shows Java ratios, and “p” Python ratios. The red lines show the fraction based on the total number of method calls, and the blue/green lines are based on occurrences of chains, i.e., chain of one vs chain of many (code and data):

The ratio of Java chains containing two or more methods vs one method, grew by around 6% a year between 2006 and 2018, which is only a small part of the overall 46% annual Java growth.
Method chaining is three times more common in Java than Python. In 2020 around a quarter of all method calls were in a chain of two or more, and single method calls were around ten times more common than multi-call chains.
In Python, the use of method chains has roughly remained unchanged over 15 years, with around 5% of all method calls appearing in a chain.
I don’t have a good idea for why method chains are three times more common in Java than Python. Are nested calls the more common usage in Python, or do developers use a sequence of calls communicating using temporary variables?
What of languages that don’t support method chaining, e.g., C. Is the distribution of the number of nested calls (or sequence of calls using temporaries) a power law with an exponent close to 3.7?
Suggestions and pointers to more data welcome.
Modeling the distribution of method sizes
The number of lines of code in a method/function follows the same pattern in the three languages for which I have measurements: C, Java, Pharo (derived from Smalltalk-80).
The number of methods containing a given number of lines is a power law, with an exponent of 2.8 for C, 2.7 for Java and 2.6 for Pharo.
This behavior does not appear to be consistent with a simplistic model of method growth, in lines of code, based on the following three kinds of steps over a 2-D lattice: moving right with probability  , moving up and to the right with probability
, moving up and to the right with probability  , and moving down and to the right with probability
, and moving down and to the right with probability  . The start of an
. The start of an if or for statement are examples of coding constructs that produce a step followed by a step at the end of the statement; steps are any non-compound statement. The image below shows the distinct paths for a method containing four statements:

For this model, if  the probability of returning to the origin after taking
the probability of returning to the origin after taking  is a complicated expression with an exponentially decaying tail, and the case
is a complicated expression with an exponentially decaying tail, and the case  is a well studied problem in 1-D random walks (the probability of returning to the origin after taking steps is
is a well studied problem in 1-D random walks (the probability of returning to the origin after taking steps is  approx n^{-1.5}") ).
).
Possible changes to this model to more closely align its behavior with source statement production include:
- include terms for the correlation between statements, e.g., assigning to a local variable implies a later statement that reads from that variable,
- include context terms in the up/down probabilities, e.g., nesting level.
Measuring statement correlation requires handling lots of special cases, while measurements of up/down steps is easily obtained.
How can / probabilities be written such that step length has a power law with an exponent greater than two?
ChatGPT 5 told me that the Langevin equation and Fokker–Planck equation could be used to derive probabilities that produced a power law exponent greater than two. I had no idea had they might be used, so I asked ChatGPT, Grok, Deepseek and Kimi to suggest possible equations for the / probabilities.
The physics model corresponding to this code related problem involves the trajectories of particles at the bottom of a well, with the steepness of the wall varying with height. This model is widely studied in physics, where it is known as a potential well.
Reaching a possible solution involved refining the questions I asked, following suggestions that turned out to be hallucinations, and trying to work out what a realistic solution might look like.
One ChatGPT suggestion that initially looked promising used a Metropolis–Hastings approach, and a logarithmic potential well. However, it eventually dawned on me that ^a") , where
, where  is nesting level, and
is nesting level, and  some constant, is unlikely to be realistic (I expect the probability of stepping up to decrease with nesting level).
some constant, is unlikely to be realistic (I expect the probability of stepping up to decrease with nesting level).
Kimi proposed a model based on what it called algebraic divergence:
=r/{z(y)},U(y)={u_0y^{1-2/{alpha}}}/{z(y)}, D(y)={d_0y^{1-2/{alpha}}}/{z(y)}")
where: ") normalises the probabilities to equal one,
normalises the probabilities to equal one, =r+u_0y^{1-2/alpha}+d_0y^{1-2/alpha}") ,
,  is the up probability at nesting 0,
is the up probability at nesting 0,  is the down probability at nesting 0, and
is the down probability at nesting 0, and  is the desired power law exponent (e.g., 2.8).
is the desired power law exponent (e.g., 2.8).
For C,  , giving
, giving =r/{z(y)},U(y)={u_0y^{0.29}}/{z(y)}, D(y)={d_0y^{0.29}}/{z(y)}")
The average length of a method, in LOC, is given by:
![E[LOC]={alpha r}/{2(d_0-u_0)}+O(e^{lambda}-1)](https://shape-of-code.com/wp-content/plugins/wpmathpub/phpmathpublisher/img/math_969.5_ffcacf0bb8190096d4d17fb475c0a290.png "E[LOC]={alpha r}/{2(d_0-u_0)}+O(e^{lambda}-1)") , where:
, where: }/{d_0+u_0}")
For C, the mean function length is 26.4 lines, and the values of  , , and need to be chosen subject to the constraint
, , and need to be chosen subject to the constraint  .
.
Combining the normalization factor with the requirement  , shows that as increases,
, shows that as increases, ") slowly decreases and
slowly decreases and ") slowly increases.
slowly increases.
One way to judge how closely a model matches reality is to use it to make predictions about behavior patterns that were not used to create the model. The behavior patterns used to build this model were: function/method length is a power law with exponent greater than 2. The mean length, ![E[LOC]](https://shape-of-code.com/wp-content/plugins/wpmathpub/phpmathpublisher/img/math_981.5_0ac27fa76bd7c6e393f3497c9f30db7e.png "E[LOC]") , is a tuneable parameter.
, is a tuneable parameter.
Ideally a model works across many languages, but to start, given the ease of measuring C source (using Coccinelle), this one language will be the focus.
I need to think of measurable source code patterns that are not an immediate consequence of the power law pattern used to create the model. Suggestions welcome.
It’s possible that the impact of factors not included in this model (e.g., statement correlation) is large enough to hide any nesting related patterns that are there. While different kinds of compound statements (e.g., if vs. for) may have different step probabilities, in C, and I suspect other languages, if-statement use dominates (Table 1713.1: if 16%, for 4.6% while 2.1%, non-compound statements 66%).
Percentage of methods containing no reported faults
It is often said, with some evidence, that 80% of reported faults, for a program, occur in 20% of its code. I think this pattern is a consequence of 20% of the code being executed 80% of the time, while many researchers believe that 20% of the source code has characteristics that result in it containing 80% of the coding mistakes.
The 20% figure is commonly measured as a percentage of methods/functions, rather than a percentage of lines of code.
This post investigates the expected fraction of a program’s methods that remain fault report free, based on two probability models.
Both models assume that coding mistakes are uniformly scattered throughout the code (i.e., every statement has the same probability of containing a mistake) and that the corresponding coding mistake is contained within a single method (the evidence suggests that this is true for 50% of faults).
A simple model is to assume that when a new fault is reported, the probability that the corresponding coding mistake appears in a particular method is proportional to the method’s length,  in lines of code, of the method. The evidence shows that the distribution of methods containing a given number of lines, , is well-fitted by a power law (for Java:
in lines of code, of the method. The evidence shows that the distribution of methods containing a given number of lines, , is well-fitted by a power law (for Java:  ).
).
If  reported faults have been fixed in a program containing
reported faults have been fixed in a program containing  methods/functions, what is the expected number of methods that have not been modified by the fixing process?
methods/functions, what is the expected number of methods that have not been modified by the fixing process?
The answer (with help from: mostly Kimi, with occasional help from Deepseek (who don’t have a share chat options), ChatGPT 5, Grok, and some approximations; chat logs) is:
}Li_b(e^{-{F/M}{{zeta(b)}/{zeta(b-1)}}})")
where:  is the Riemann zeta function,
is the Riemann zeta function,  is the polylogarithm function and
is the polylogarithm function and  for Java.
for Java.
The plot below shows the predicted fraction of unmodified methods against number of faults, for programs of various sizes; the grey lines show the rough approximation:  (code+data):
(code+data):
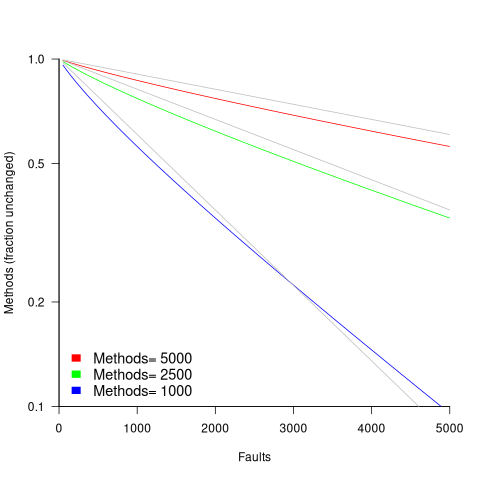
The observed behavior of most reported faults involving a subset of a program’s methods can be modelled using some form of preferential attachment.
One preferential attachment model specifies that the likelihood of a coding mistake appearing in a method is proportional to ") , where is the number of previously detected coding mistakes in the method.
, where is the number of previously detected coding mistakes in the method.
The estimated number of unmodified methods is now:
}Li_b(({M zeta(b-1)}/{M zeta(b-1)+a*(F+1) zeta(b)})^{1/a})")
where: is the average value of  over all faults (if
over all faults (if  , then
, then  for a power law with exponent 2.35).
for a power law with exponent 2.35).
The plot below shows the predicted fraction of unmodified methods against number of faults for a program containing 1,000 methods, for various values of , with the black line showing the fraction of unmodified methods predicted by the simple model above (code+data):
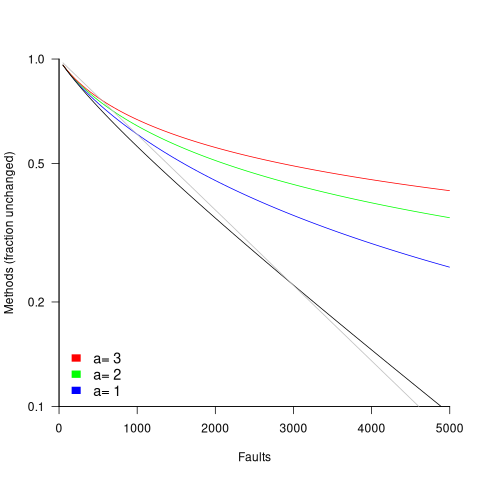
In practice, random selection of the method containing a coding mistake will introduce some fuzziness in the predicted fraction of unmodified methods.
As the number of reported faults grows, the attraction of methods involved in previous reported faults slows the rate at which methods experience their first detected coding mistake.
How realistic are these models?
By focusing on the number of unmodified methods, many complications are avoided.
Both models assume that an unchanging number of methods in a program and that the length of each method is fixed. This assumption holds between each release of a program.
For actively maintained programs, the number of methods in a program changes over time, and the length of some existing methods also changes (if a program were not actively maintained, reported faults would not get fixed).
These models are unlikely to be applicable to programs with short release cycles, where there are few reported faults between releases.
How well do the models’ predictions agree with the data?
At the moment, I am not aware of a dataset containing the appropriate data. Number of faults vs unmodified methods has been added to my list of interesting patterns to notice.
Summary of the derivation of the solutions for the two models.
Simple model
The expected number of unmodified methods, ") , is:
, is:
=sum{L=1}{T}{m_L{P(U_LF)}}") , where
, where  is the length of the longest method,
is the length of the longest method,  is the number of methods of length , and
is the number of methods of length , and ") is the probability that a method of length will be unmodified after fault reports.
is the probability that a method of length will be unmodified after fault reports.
The evidence shows that the distribution of methods containing a given number of lines, , is well-fitted by a power law (for Java: ).
Given a program containing methods, the number of methods of length is:
 , where for Java.
, where for Java.
If is large and  , then the sum can be approximated by the Riemann zeta function, , giving:
, then the sum can be approximated by the Riemann zeta function, , giving:
}}")
The probability that a method containing lines will not be modified by a fault report (assuming that fixing the mistake only involves one method) is:  , where
, where  is the total lines of code in the program, and the probability of this method not being modified after fault reports is approximately:
is the total lines of code in the program, and the probability of this method not being modified after fault reports is approximately:
^F approx e^{{-F*L}/{P_t}}")
The expected number of empty boxes is:
}}*e^{{-F*L}/{P_t}}}=M/{zeta(b)}Li_b(e^{-F/{P_t}})")
The number of lines of code in a program containing methods is:
}}}=M/{zeta(b)}sum{L=1}{T}{L^{1-b}}=M{{zeta(b-1)}/{zeta(b)}}")
Finally giving:
}Li_b(e^{-{F/M}{{zeta(b)}/{zeta(b-1)}}})")
where is the polylogarithm function.
This equation is roughly, for the purposes of understanding the effect of each variable:

Preferential attachment model
When a mistake is corrected in a method, the attraction weight of that method increases (alternatively, the attraction weight of the other methods decreases). The probability that a method is not modified after fault reports is now:
}=prod{k=0}{F}{{P_t+a*k-L}/{P_t+a*k}}={Gamma({P_t}/a)Gamma({P_t-L}/a+F+1)}/{Gamma({P_t-L}/a)Gamma(P_t/a+F+1)}")
where:  the average value of over all faults, and
the average value of over all faults, and  is the gamma function.
is the gamma function.
applying the Stirling/Gamma–ratio rule, i.e., }/{Gamma(z+b)} approx z^{a-b}") we get:
we get:
})^{F/a} = ((P_t/{P_t+a*(F+1)})^{1/a})^F")
where the expression ^{1/a})^F") is the preferential attachment version of the expression
is the preferential attachment version of the expression ^F") appearing in the simple model derivation. Using this preferential attachment expression in the analysis of the simple model, we get:
appearing in the simple model derivation. Using this preferential attachment expression in the analysis of the simple model, we get:
I don’t have a rough approximation for this expression.
Distribution of program sizes
Program size, in lines of code (LOC), used to be a topic of conversation among developers and managers. Program size is an issue when computer memory is measured in kilobytes. Large programs would be organized into overlays such that only small subsets needed to be held in memory at any time, i.e., programmer defined memory management.
Management used program size as a proxy for implementation effort/cost. Because size was a topic of conversation, it was possible to ask around to obtain a selection of values for the size of programs with similar functionality (accurate actual implementation costs were/are rarely available via the grapevine, but developers were/are always happy to talk about how small/large their programs were/are). These days, estimating LOC prior to implementation may appear more scientific, but I doubt it’s more accurate.
Once computers containing megabytes of memory became widespread, and the use of third-party libraries continued to grow, program size became a niche topic of conversation.
The size of some operating systems has become an occasional topic of conversation; it wasn’t previously because mainframe/mini computer manufacturers didn’t want customers talking about how much of their expensive memory was taken up by the OS. The size of Microsoft Windows leaked out and the Linux kernel is a topic of research.
Discussions around size have moved on from individual programs to the amount of space taken up by an installed application suite. Today, program size can be a rounding error compared to data files, extensions and add-ons.
Researchers have also moved on; repository size, in LOC/packages, is what now gets reported.
For those who are interested in program size; what is the distribution of program sizes? How many LOC are needed for a program to be above 50%, or in the top 95%?
Recent data on the size of individual programs is surprisingly hard to find, given how often LOC values appear in print. The one dataset I found is from the paper Empirical analysis of the relationship between CC and SLOC in a large corpus of Java methods and C functions, which is derived from the 2010’ish Sourcerer corpus of 13,103 Java projects (each of which I assume contains one program). The plot below shows the LOC (red) and methods (blue/green) for each program, in ascending order, along with values at various percentage points (code+data):
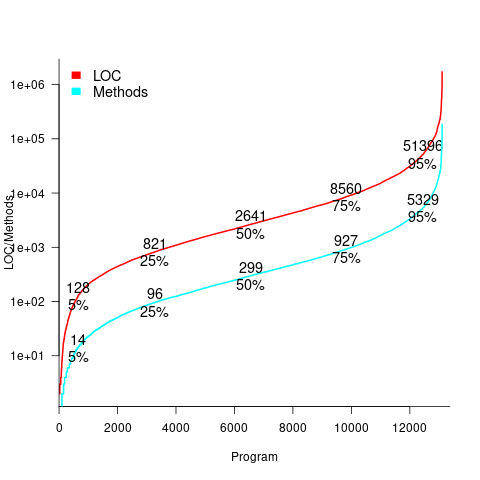
The size of Java programs is very likely to have increased since 2010. How much have grown? I don’t know.
What about the size of programs written in other languages?
I expect Python program size to be smaller, because the huge number of available package removes the need to implement a myriad of boilerplate functionality.
I expect C program size to be larger, both because of the smaller library ecosystem and because C programs tend to be older (programs rarely shrink with age).
Readability of anonymous inner classes and lambda expressions
The available evidence on readability is virtually non-existent, mostly consisting of a handful of meaningless experiments.
Every now and again somebody runs an experiment comparing the readability of X and Y. All being well, this produces a concrete result that can be published. I think that it would be a much more effective use of resources to run eye tracking experiments to build models of how people read code, but then I’m not on the publish or perish treadmill.
One such experimental comparison of X and Y is the paper Two N-of-1 self-trials on readability differences between anonymous inner classes (AICs) and lambda expressions (LEs) on Java code snippets by Stefan Hanenberg (who ran some experiments on the benefits of strong typing) and Nils Mehlhorn.
How might the readability of X and Y be compared (e.g., Java anonymous inner classes and lambda expressions)?
If the experimenter has the luxury of lots of subjects, then half of the subjects can be assigned to use X and half to use Y. When only a few subjects are available, perhaps as few as one, an N-of-1 experimental design can be used.
This particular study is worth discussing because it appears to be thought out and well run, as well as illustrating the issues involved in running such experiments, not because the readability of the two constructs is of particular interest. I think that developer choice of anonymous inner classes or lambda expressions is based on fashion and/or habit, and developers will claim the construct they use is the most readable one for them.
The Hanenberg and Mehlhorn study involved two experiments, using a N-of-1 design. In the first experiment task, subjects saw a snippet of code and had to count the number of parameters in either the anonymous inner class or the lambda expression (whose parameters were either untyped or typed); in the second experiment task subjects had to count the number of defined parameters that were used in the body of the anonymous inner class or lambda expression. English words were used for parameter names.
Each of the eight subjects saw the same set of randomly shuffled distinct 600 code snippets. The time taken to answer and correct/incorrect answer status were recorded. The snippets varied in the number of parameters and kind of construct; for task 1: 0-4 parameters, 3-kinds of construct, repeated 40 times, giving  distinct snippets; for task 2: 0-3 parameters used out of 3 parameters, 3-kinds of construct, repeated 50 times, giving
distinct snippets; for task 2: 0-3 parameters used out of 3 parameters, 3-kinds of construct, repeated 50 times, giving  distinct snippets.
distinct snippets.
The first task requires subjects to locate the definition of the construct, count the number of parameters, and report the count. The obvious model is different constructs require different amounts of time to locate, and that each parameter adds a fixed amount to the response time; there may be a small learning component.
Fitting a simple regression model shows (depending on choice of outlier bounds) that averaged over all subjects each parameter increased response time by around 80 msec, and that response was faster for lambda expressions (around 200 msec without parameter types, 90 msec if types are present); code+data. However, the variation across subjects had a standard deviation that was similar to these means.
The second task required subjects to read the body of the code, to find out which parameters were used. The mean response time increased from 1.5 to 3.7 seconds.
I was not sure whether to expect response time to increase or decrease as the number of parameters used in the body of the code increased (when the actual number of parameters is always three).
A simple fitted regression model finds that increase/decrease behavior varies between subjects (around 50 msec per parameter used); code+data. I am guessing that performance behavior depends on the mental model used to hold the used/not yet used information.
The magnitude of the performance differences found in this study mimics that seen in most human based software engineering experiments, that is, the impact of the studied construct is very small.
Widely used programming languages: past, present, and future
Programming languages are like pop groups in that they have followers, fans and supporters; new ones are constantly being created and some eventually become widely popular, while those that were once popular slowly fade away or mutate into something else.
Creating a language is a relatively popular activity. Science fiction and fantasy authors have been doing it since before computers existed, e.g., the Elf language Quenya devised by Tolkien, and in the computer age Star Trek’s Klingon. Some very good how-to books have been written on the subject.
As soon as computers became available, people started inventing programming languages.
What have been the major factors influencing the growth to widespread use of a new programming languages (I’m ignoring languages that become widespread within application niches)?
Cobol and Fortran became widely used because there was widespread implementation support for them across computer manufacturers, and they did not have to compete with any existing widely used languages. Various niches had one or more languages that were widely used in that niche, e.g., Algol 60 in academia.
To become widely used during the mainframe/minicomputer age, a new language first had to be ported to the major computers of the day, whose products sometimes supported multiple, incompatible operating systems. No new languages became widely used, in the sense of across computer vendors. Some new languages were widely used by developers, because they were available on IBM computers; for several decades a large percentage of developers used IBM computers. Based on job adverts, RPG was widely used, but PL/1 not so. The use of RPG declined with the decline of IBM.
The introduction of microcomputers (originally 8-bit, then 16, then 32, and finally 64-bit) opened up an opportunity for new languages to become widely used in that niche (which would eventually grow to be the primary computing platform of its day). This opportunity occurred because compiler vendors for the major languages of the day did not want to cannibalize their existing market (i.e., selling compilers for a lot more than the price of a microcomputer) by selling a much lower priced product on microcomputers.
BASIC became available on practically all microcomputers, or rather some dialect of BASIC that was incompatible with all the other dialects. The availability of BASIC on a vendor’s computer promoted sales of the hardware, and it was not worthwhile for the major vendors to create a version of BASIC that reduced portability costs; the profit was in games.
The dominance of the Microsoft/Intel partnership removed the high cost of porting to lots of platforms (by driving them out of business), but created a major new obstacle to the wide adoption of new languages: Developer choice. There had always been lots of new languages floating around, but people only got to see the subset that were available on the particular hardware they targeted. Once the cpu/OS (essentially) became a monoculture most new languages had to compete for developer attention in one ecosystem.
Pascal was in widespread use for a few years on micros (in the form of Turbo Pascal) and university computers (the source of Wirth’s ETH compiler was freely available for porting), but eventually C won developer mindshare and became the most widely used language. In the early 1990s C++ compiler sales took off, but many developers were writing C with a few C++ constructs scattered about the code (e.g., use of new, rather than malloc/free).
Next, the Internet took off, and opened up an opportunity for new languages to become dominant. This opportunity occurred because Internet related software was being made freely available, and established compiler vendors were not interested in making their products freely available.
There were people willing to invest in creating a good-enough implementation of the language they had invented, and giving it away for free. Luck, plus being in the right place at the right time resulted in PHP and Javascript becoming widely used. Network effects prevent any other language becoming widely used. Compatible dialects of PHP and Javascript may migrate widespread usage to quite different languages over time, e.g., Facebook’s Hack.
Java rode to popularity on the coat-tails of the Internet, and when it looked like security issues would reduce it to niche status, it became the vendor supported language for one of the major smart-phone OSs.
Next, smart-phones took off, but the availability of Open Source compilers closed the opportunity window for new languages to become dominant through lack of interest from existing compiler vendors. Smart-phone vendors wanted to quickly attract developers, which meant throwing their weight behind a language that many developers were already familiar with; Apple went with Objective-C (which evolved to Swift), Google with Java (which evolved to Kotlin, because of the Oracle lawsuit).
Where does Python fit in this grand scheme? I don’t yet have an answer, or is my world-view wrong to treat Python usage as being as widespread as C/C++/Java?
New programming languages continue to be implemented; I don’t see this ever stopping. Most don’t attract more users than their implementer, but a few become fashionable amongst the young, who are always looking to attach themselves to something new and shiny.
Will a new programming language ever again become widely used?
Like human languages, programming languages experience strong networking effects. Widely used languages continue to be widely used because many companies depend on code written in it, and many developers who can use it can obtain jobs; what company wants to risk using a new language only to find they cannot hire staff who know it, and there are not many people willing to invest in becoming fluent in a language with no immediate job prospects.
Today’s widely used programmings languages succeeded in a niche that eventually grew larger than all the other computing ecosystems. The Internet and smart-phones are used by everybody on the planet, there are no bigger ecosystems to provide new languages with a possible route to widespread use. To be widely used a language first has to become fashionable, but from now on, new programming languages that don’t evolve from (i.e., be compatible with) current widely used languages are very unlikely to migrate from fashionable to widely used.
It has always been possible for a proficient developer to dedicate a year+ of effort to create a new language implementation. Adding the polish need to make it production ready used to take much longer, but these days tool chains such as LLVM supply a lot of the heavy lifting. The problem for almost all language creators/implementers is community building; they are terrible at dealing with other developers.
It’s no surprise that nearly all the new languages that become fashionable originate with language creators who work for a company that happens to feel a need for a new language. Examples include:
- Go created by Google for internal use, and attracted an outside fan base. Company languages are not new, with IBM’s PL/1 being the poster child (or is there a more modern poster child). At the moment Go is a trendy language, and this feeds a supply of young developers willing to invest in learning it. Once the trendiness wears off, Google will start to have problems recruiting developers, the reason: Being labelled as a Go developer limits job prospects when few other companies use the language. Talk to a manager who has tried to recruit developers to work on applications written in Fortran, Pascal and other once-widely used languages (and even wannabe widely used languages, such as Ada),
- Rust a vanity project from Mozilla, which they have now
abandonedcast adrift. Did Rust become fashionable because it arrived at the right time to become the not-Google language? I await a PhD thesis on the topic of the rise and fall of Rust, - Microsoft’s C# ceased being trendy some years ago. These days I don’t have much contact with developers working in the Microsoft ecosystem, so I don’t know anything about the state of the C# job market.
Every now and again a language creator has the social skills needed to start an active community. Zig caught my attention when I read that its creator, Andrew Kelley, had quit his job to work full-time on Zig. Two and a-half years later Zig has its own track at FOSEM’21.
Will Zig become the next fashionable language, as Rust/Go popularity fades? I’m rooting for Zig because of its name, there are relatively few languages whose name starts with Z; the start of the alphabet is over-represented with language names. It would be foolish to root for a language because of a belief that it has magical properties (e.g., powerful, readable, maintainable), but the young are foolish.
Growth in number of packages for widely used languages
These days a language’s ecosystem of add-ons, such as packages, is often more important than the features provided by the language (which usually only vary in their syntactic sugar, and built-in support for some subset of commonly occurring features).
Use of a particular language grows and shrinks, sometimes over very many decades. Estimating the number of users of a language is difficult, but a possible proxy is ecosystem activity in the form of package growth/decline. However, it will take many several decades for the data needed to test how effective this proxy might be.
Where are we today?
The Module Counts website is the home for a project that counts the number of libraries/packages/modules contained in 26 language specific repositories. Daily data, in some cases going back to 2010, is available as a csv 🙂 The following are the most interesting items I discovered during a fishing expedition.
The csv file contains totals, and some values are missing (which means specifying an ‘ignore missing values’ argument to some functions). Some repos have been experiencing large average daily growth (e.g., 65 for PyPI, and 112 for Maven Central-Java), while others are more subdued (e.g., 0.7 for PERL and 3.9 for R’s CRAN). Apart from a few days, the daily change is positive.
Is the difference in the order of magnitude growth due to number of active users, number of packages that currently exist, a wide/narrow application domain (Python is wide, while R’s is narrow), the ease of getting a package accepted, or something else?
The plots below show how PyPI has been experiencing exponential growth of a kind (the regression model fitted to the daily total has the form  , where
, where  is the number of days since 2010-01-01; the red line is the daily diff of this equation), while Ruby has been experiencing a linear decline since late 2014 (all code+data):
is the number of days since 2010-01-01; the red line is the daily diff of this equation), while Ruby has been experiencing a linear decline since late 2014 (all code+data):
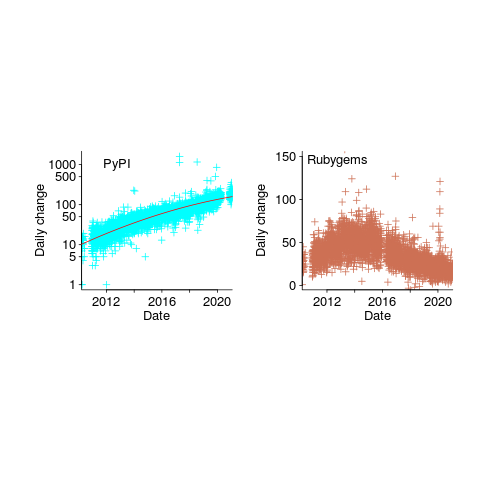
Will the five-year decline in new submissions to Rubygems continue, and does this point to an eventual demise of Ruby (a few decades from now)? Rubygems has years to go before it reaches PERL’s low growth rate (I think PERL is in terminal decline).
Are there any short term patterns, say at the weekly level? Autocorrelation is a technique for estimating the extent to which today’s value is affected by values from the immediate past (usually one or two measurement periods back, i.e., yesterday or the day before that). The two plots below show the autocorrelation for daily changes, with lag in days:
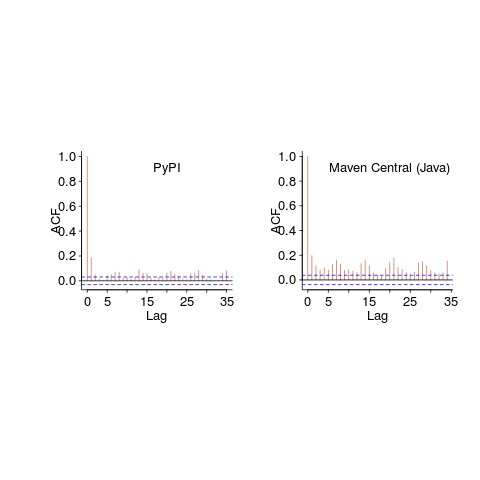
The recurring 7-day ‘peaks’ show the impact of weekends (I assume). Is the larger ”weekend-effect’ for Java, compared to PyPI, due to Java usage including a greater percentage of commercial developers (who tend not to work at the weekend)?
I did not manage to find any seasonal effect, e.g., more submissions during the winter than the summer. But I only checked a few of the languages, and only for a single peak (see code for details).
Another way of tracking package evolution is version numbering. For instance, how often do version numbers change, and which component, e.g., major/minor. There have been a couple of studies looking at particular repos over a few years, but nobody is yet recording broad coverage daily, over the long term 😉
Impact of function size on number of reported faults
Are longer functions more likely to contain more coding mistakes than shorter functions?
Well, yes. Longer functions contain more code, and the more code developers write the more mistakes they are likely to make.
But wait, the evidence shows that most reported faults occur in short functions.
This is true, at least in Java. It is also true that most of a Java program’s code appears in short methods (in C 50% of the code is contained in functions containing 114 or fewer lines, while in Java 50% of code is contained in methods containing 4 or fewer lines). It is to be expected that most reported faults appear in short functions. The plot below shows, left: the percentage of code contained in functions/methods containing a given number of lines, and right: the cumulative percentage of lines contained in functions/methods containing less than a given number of lines (code+data):
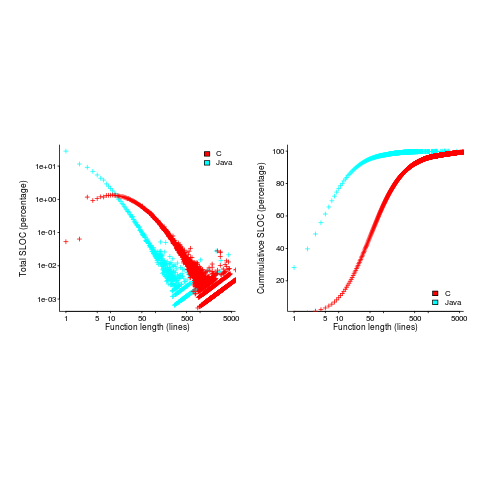
Does percentage of program source really explain all those reported faults in short methods/functions? Or are shorter functions more likely to contain more coding mistakes per line of code, than longer functions?
Reported faults per line of code is often referred to as: defect density.
If defect density was independent of function length, the plot of reported faults against function length (in lines of code) would be horizontal; red line below. If every function contained the same number of reported faults, the plotted line would have the form of the blue line below.
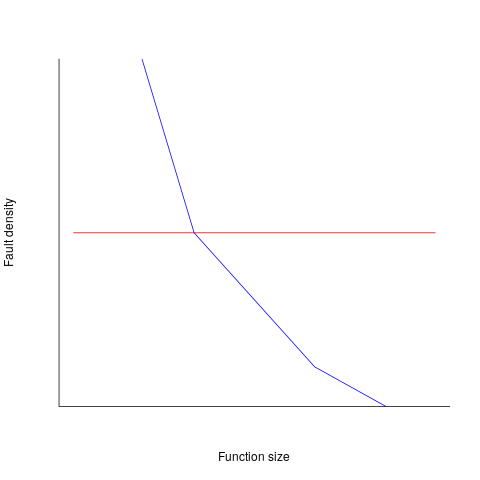
Two things need to occur for a fault to be experienced. A mistake has to appear in the code, and the code has to be executed with the ‘right’ input values.
Code that is never executed will never result in any fault reports.
In a function containing 100 lines of executable source code, say, 30 lines are rarely executed, they will not contribute as much to the final total number of reported faults as the other 70 lines.
How does the average percentage of executed LOC, in a function, vary with its length? I have been rummaging around looking for data to help answer this question, but so far without any luck (the llvm code coverage report is over all tests, rather than per test case). Pointers to such data very welcome.
Statement execution is controlled by if-statements, and around 17% of C source statements are if-statements. For functions containing between 1 and 10 executable statements, the percentage that don’t contain an if-statement is expected to be, respectively: 83, 69, 57, 47, 39, 33, 27, 23, 19, 16. Statements contained in shorter functions are more likely to be executed, providing more opportunities for any mistakes they contain to be triggered, generating a fault experience.
Longer functions contain more dependencies between the statements within the body, than shorter functions (I don’t have any data showing how much more). Dependencies create opportunities for making mistakes (there is data showing dependencies between files and classes is a source of mistakes).
The previous analysis makes a large assumption, that the mistake generating a fault experience is contained in one function. This is true for 70% of reported faults (in AspectJ).
What is the distribution of reported faults against function/method size? I don’t have this data (pointers to such data very welcome).
The plot below shows number of reported faults in C++ classes (not methods) containing a given number of lines (from a paper by Koru, Eman and Mathew; code+data):
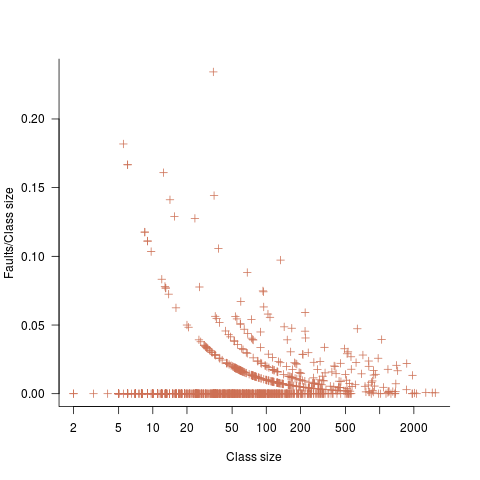
It’s tempting to think that those three curved lines are each classes containing the same number of methods.
What is the conclusion? There is one good reason why shorter functions should have more reported faults, and another good’ish reason why longer functions should have more reported faults. Perhaps length is not important. We need more data before an answer is possible.
How are C functions different from Java methods?
According to the right plot below, most of the code in a C program resides in functions containing between 5-25 lines, while most of the code in Java programs resides in methods containing one line (code+data; data kindly supplied by Davy Landman):
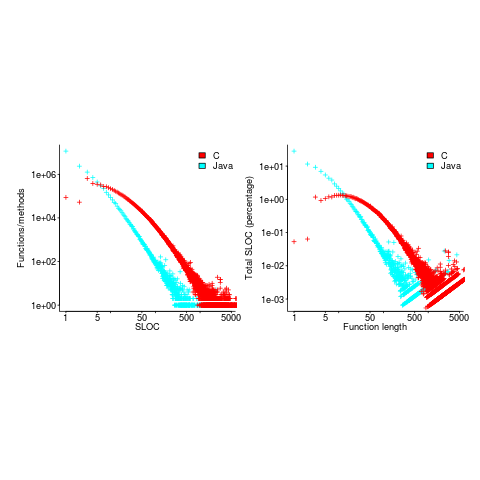
The left plot shows the number of functions/methods containing a given number of lines, the right plot shows the total number of lines (as a percentage of all lines measured) contained in functions/methods of a given length (6.3 million functions and 17.6 million methods).
Perhaps all those 1-line Java methods are really complicated. In C, most lines contain a few tokens, as seen below (code+data):
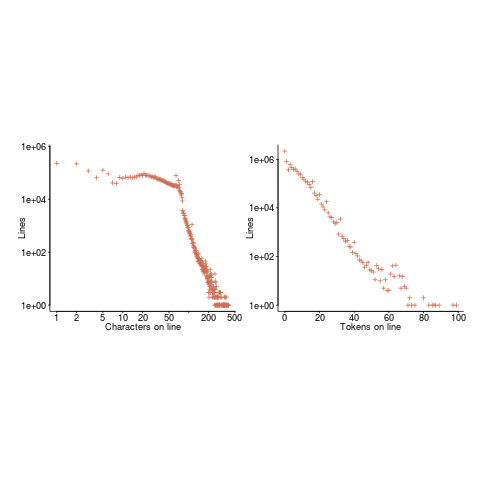
I don’t have any characters/tokens per line data for Java.
Is Java code mostly getters and setters?
I wonder what pattern C++ will follow, i.e., C-like, Java-like, or something else? If you have data for other languages, please send me a copy.
Evolutionary pressures on C++, Java and Python
The future evolution of C++, Java and Python is being driven by very different interested parties, and it’s going to be interesting watching events unfold over the next 5-10 years.
I have previously written about how the C++ Standard’s committee is past its sell-by date, has taken off its ball and chain and is now in the hands of bored consultants.
Bjarne Stroustrup was once effectively treated as C++’s Benevolent Dictator For Life (during the production of the first C++ Standard some people were labeled as Bjarne groupees); things have moved on since then, but the ‘old-guard’ are trying to make a comeback. Suggesting that people ought to base their thinking on a book published almost 25-years ago (Stroustrup’s “The Design and Evolution of C++”; a very interesting book that is well worth reading) creates a rather backward looking image. Bored consultants are looking to work on exciting new ideas. The old-guard need to appear modern to attract followers (even if the ideas are old ideas with a fresh coat of paint).
The threat to C++ is from bored consultants, each adding their own pet idea to the language standard; a situation that Stroustrup thinks is starting to happen.
Java, the language, is owned by Oracle, the company (let’s not get too involved in exactly what they own, have copyright on, etc). Oracle are not shy about asking people for licensing fees. Java is now on a 6-month release cycle (at least the Oracle version, there are Open Source implementations) and the free support only applies to the current release; paying a license fee buys support for versions older than 6-months. In the short term, the cheapest solution is for companies to pay for support.
Oracle are always happy to send in the lawyers and if too many customers switch to non-Oracle implementations, I’m sure something can be found to introduce enough uncertainty to discourage work/distribution involving Open Source Java implementations.
Will Java survive Oracle’s licensing? It is not in their interest for Java to die; Oracle will adjust their terms to keep the money flowing in, but over the longer term I think willing Java developers are going to be hard to find.
Guido van Rossum recently removed himself from the post of Python’s Benevolent Dictator For Life. One of the jobs of a benevolent dictator is maintaining some degree of language coherence, which involves preventing people’s pet ideas from being added to the language. Does this mean that Python is slowly going to be become more and more bloated? Perhaps, but I think a more likely problem is a language fork, multiple implementations of slightly different (at first) languages all claiming to be Python.
These days, the strength of Python is its large collection of very useful, commercial grade, packages, and future language details may turn out to be irrelevant. There is a lot to learn from the Python 2/3 transition, but true believers like to think that things will turn out differently for them.
Recent Comments