Archive
The Approximate Number System and software estimating
The ability to perform simple numeric operations can improve the fitness of a creature (e.g., being able to select which branch contains the most fruit), increasing the likelihood of it having offspring. Studies have found that a wide variety of creatures have a brain subsystem known as the Approximate Number System (ANS).
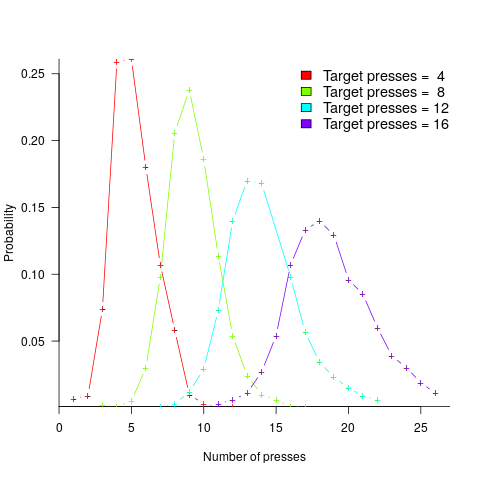
A study by Mechner rewarded rats with food, if they pressed a lever N times (with N taking one of the values 4, 8, 12 or 16), followed by pressing a second lever. The plot below shows the number of lever presses made before pressing the second lever, for a given required N; it suggests that the subject rat is making use of an approximate number system (code+data):
Humans have a second system for representing numbers, which is capable of exact representation, it is language. The Number Sense by Stanislas Dehaene was on my list of Christmas books for 2011.
One method used to study the interface between the two number systems, available to humans, involves subjects estimating the number of dots in a briefly presented image. While reading about one such study, I noticed that some of the plots showed patterns similar to the patterns seen in plots of software estimate/actual data. I emailed the lead author, Véronique Izard, who kindly sent me a copy of the experimental data.
The patterns I was hoping to see are those invariably seen in software effort estimation data, e.g., a power law relationship between actual/estimate, consistent over/under estimation by individuals, and frequent use of round numbers.
Psychologists reading this post may be under the impression that estimating the time taken to implement some functionality, in software, is a relatively accurate process. In practice, for short tasks (i.e., under a day or two) the time needed to form a more accurate estimate makes a good-enough estimate a cost-effective option.
This Izard and Dehaene study involved two experiments. In the first experiment, an image containing between 1 and 100 dots was flashed on the screen for 100ms, and subjects then had to type the estimated number of dots. Each of the six subjects participated in five sessions of 600 trials, with each session lasting about one hour; every number of dots between 1 and 100 was seen 30 times by each subject (for one subject the data contains 1,783 responses, other subjects gave 3,000 responses). Subjects were free to type any value as their estimate.
These kinds of studies have consistently found that subject accuracy is very poor (hardly surprising, given that subjects are not provided with any feedback to help calibrate their estimates). But since researchers are interested in patterns that might be present in the errors, very low accuracy is not an issue.
The plot below shows stimulus (number of dots shown) against subject response, with green line showing  , and red line a fitted regression model having the form
, and red line a fitted regression model having the form  (which explains just over 70% of the variance; code+data):
(which explains just over 70% of the variance; code+data):
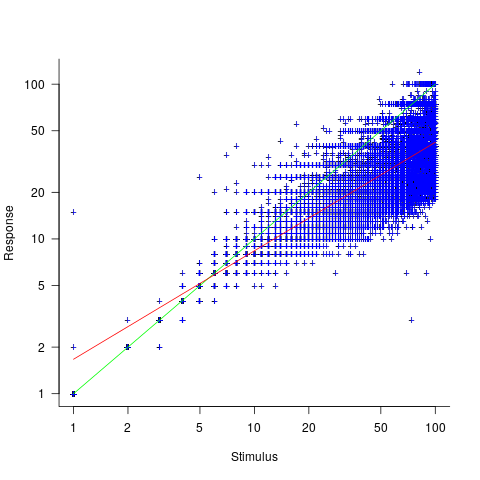
Just like software estimates, there is a good fit to a power law, and the only difference in accuracy performance is that software estimates tend not to be so skewed towards underestimating (i.e., there are a lot more low accuracy overestimates).
Adding subjectID to the model gives:  , with
, with  varying between 0.65 and 1.57; more than a factor of two difference between subjects (this model explains just under 90% of the variance). This is a smaller range than the software estimation data, but with only six subjects there was less chance of a wider variation (code+data).
varying between 0.65 and 1.57; more than a factor of two difference between subjects (this model explains just under 90% of the variance). This is a smaller range than the software estimation data, but with only six subjects there was less chance of a wider variation (code+data).
The software estimation data finds shows that accuracy does not improve with practice. The experimental subjects were not given any feedback, and would not be expected to improve, but does the strain of answering so many questions cause them to get worse? Adding trial number to the model suggests a 12% increase in underestimation, over 600 trials. However, adding an interaction with SubjectID shows that the performance of two subjects remains unchanged, while two subjects experience a 23% increase in underestimation.
The plot below shows the number of times each response was given, combining all subjects, with commonly given responses in red (code+data):
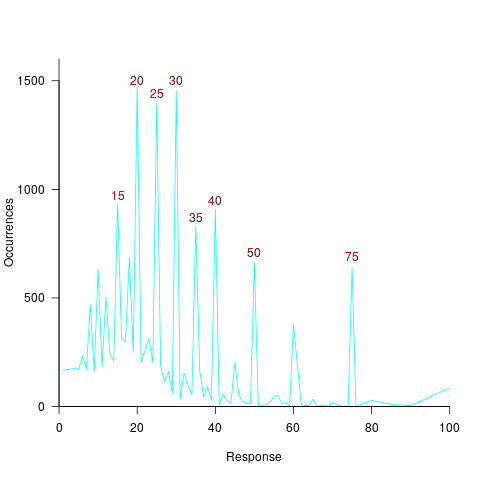
The commonly occurring values that appear in software estimation data are structured as fractions of units of time, e.g., 0.5 hours, or 1 hour or 1 day (appearing in the data as 7 hours). The only structure available to experimental subjects was subdivisions of powers of 10 (i.e., 10 and 100).
Analysing the responses by subject shows that each subject had their own set of preferred round numbers.
To summarize: The results from an experiment investigating the interface between the two human number systems contains three patterns seen in software estimation data, i.e., power law relationship between actual and estimate, individual differences in over/underestimating, and extensive use of round numbers.
Izard’s second experiment limited response values to prespecified values (i.e., one to 10 and multiples of 10), and gave a calibration example after each block of 46 trials. The calibration example improved performance, and the use of round numbers as prespecified response values had the effect of removing spikes from the response counts (which were relatively smooth; code+data)).
We now have circumstantial evidence that software developers are using the Approximate Number System when making software estimates. We will have to wait for brain images from a developer in an MRI scanner, while estimating a software task, to obtain more concrete proof that the ANS is involved in the process. That is, are the areas of the brain thought to be involved in the ANS (e.g., the intraparietal sulcus) active during software estimation?
Readability: a scientific approach
Readability, as applied to software development today, is a meaningless marketing term. Readability is promoted as a desirable attribute, and is commonly claimed for favored programming languages, particular styles of programming, or ways of laying out source code.
Whenever somebody I’m talking to, or listening to in a talk, makes a readability claim, I ask what they mean by readability, and how they measured it. The speaker invariably fumbles around for something to say, with some dodging and weaving before admitting that they have not measured readability. There have been a few studies that asked students to rate the readability of source code (no guidance was given about what readability might be).
If somebody wanted to investigate readability from a scientific perspective, how might they go about it?
The best way to make immediate progress is to build on what is already known. There has been over a century of research on eye movement during reading, and two model of eye movement now dominate, i.e., the E-Z Reader model and SWIFT model. Using eye-tracking to study developers is slowly starting to be adopted by researchers.
Our eyes don’t smoothly scan the world in front of us, rather they jump from point to point (these jumps are known as a saccade), remaining fixed long enough to acquire information and calculate where to jump next. The image below is an example from an eye tracking study, where subjects were asking to read a sentence (see figure 770.11). Each red dot appears below the center of each saccade, and the numbers show the fixation time (in milliseconds) for that point (code):

Models of reading are judged by the accuracy of their predictions of saccade landing points (within a given line of text), and fixation time between saccades. Simulators implementing the E-Z Reader and SWIFT models have found that these models have comparable performance, and the robustness of these models are compared by looking at the predictions they make about saccade behavior when reading what might be called unconventional material, e.g., mirrored or scarmbeld text.
What is the connection between the saccades made by readers and their understanding of what they are reading?
Studies have found that fixation duration increases with text difficulty (it is also affected by decreases with word frequency and word predictability).
It has been said that attention is the window through which we perceive the world, and our attention directs what we look at.
A recent study of the SWIFT model found that its predictions of saccade behavior, when reading mirrored or inverted text, agreed well with subject behavior.
I wonder what behavior SWIFT would predict for developers reading a line of code where the identifiers were written in camelCase or using underscores (sometimes known as snake_case)?
If the SWIFT predictions agreed with developer saccade behavior, a raft of further ‘readability’ tests spring to mind. If the SWIFT predictions did not agree with developer behavior, how might the model be updated to support the reading of lines of code?
Until recently, the few researchers using eye tracking to investigate software engineering behavior seemed to be having fun playing with their new toys. Things are starting to settle down, with some researchers starting to pay attention to existing models of reading.
What do I predict will be discovered?
Lots of studies have found that given enough practice, people can become proficient at handling some apparently incomprehensible text layouts. I predict that given enough practice, developers can become equally proficient at most of the code layout schemes that have been proposed.
The important question concerning text layout, is: which one enables an acceptable performance from a wide variety of developers who have had little exposure to it? I suspect the answer will be the one that is closest to the layout they have had the most experience,i.e., prose text.
Cognitive bias or not paying enough attention?
Assume you are responsible for two teams who independently work on projects, say Team A and Team B. The teams have different work completion rates, with Team A completing work at the rate of 70 widgets per week, while Team B completes 30 widgets per week. Both teams always work on projects that require the completion of the same number of widgets.
You have the resources to send just one of the teams on a course. It is predicted that sending Team A on the course would improve their performance to 110 widgets per week, while attending the course would improve the performance of Team B to 40 widgets per week.
Senior management have decreed that time to market is the metric by which project managers are judged.
You want to impress senior management by significantly improving time to market for your projects; which team do you send on the course (i.e., the one that is likely to experience the largest reduction in time to market)?
This question is a restatement of a one involving cars travelling at different speeds, that has grown into a niche research area. Studies have found that a large percentage of subjects give the wrong answer, and they are said to have a time-saving bias, or time-loss bias.
The inability to correctly process “inverse variables” has been given as the reason people tend to give the wrong answer. The term “inverse variables” comes from the formula for calculating completion time, where the velocity appears as the denominator. Another way of looking at this problem is that when going slowly, there is more scope for improvement, compared to when going much faster.
A speed increase from 30 to 40 is only 10, or a 33% improvement; while an increase from 70 to 110 is an increase of 40, or 57%. Based on these numbers, Team A should be sent on the course.
However, we are interested in time to market. Let’s assume that both teams have to complete a project requiring 100 widgets. Before attending the course, Team A completes 100 widgets in 100/70=1.4 weeks, and Team B completes 100 widgets in 100/30=3.3 weeks. After attending the course, Team A would complete 100 widgets in 100/110=0.91 weeks, and Team B would complete 100 widgets in 100/40=2.5 weeks. Time to market for Team A has been reduced by (1.4-0.9)=0.5 weeks, while the reduction for Team B is (3.3-2.5)=0.8 weeks. So sending Team B on the course makes you look better, on the time to market metric.
If somebody ran an experiment with project managers, would the subjects tend to incorrectly process “inverse variables”. Well, somebody has done the experiment, and yes, many subjects exhibited the time-saving bias (the experimental scenario described in the appendix is a lot easier to understand than the one in the main body of the paper, which is a mess; Magne Jørgensen continues to be the only person doing interesting experiments in software estimation).
It has become common practice that, when a large percentage of subjects in a psychology experiment respond in ways that are inconsistent with a mathematical approach, the behavior is labelled as being a bias. I think the use of this terminology makes the behavior sound more interesting than it actually is; what’s wrong with saying that people make mistakes. Perhaps labelling experimental responses as being a bias makes it easier to get papers published.
Whether people are biased, or don’t pay enough attention, when solving non-trivial equations, what might be done about it?
This is not about whether any particular metric is a useful one, rather it is about calculating the right answer for whatever metric happens to be chosen.
Would an awareness campaign highlighting the problems people have with “inverse variables” be worthwhile? I don’t think so. Many people have problems with equations, and I don’t see why this case is more worthy of being highlighted than any other.
Am I missing something?
Psychology researchers are interested in figuring out the functioning of the brain/mind, so they are looking for patterns in the responses subjects give. Once someone has published a few papers on a research topic, they become invested in it. If they continue to get funding, the papers keep on coming. Sometimes a niche topic acquires a major following, and the work contributes to a major change of thinking about the mind, e.g., the Wason selection task helped increase the evidence that culture has an impact on cognitive behavior.
I think that software engineering researchers need to carefully evaluate the likely importance of behaviors that psychology researchers have labelled as a bias.
Impact of native language on variable naming
When creating a variable name, to what extent are developers influenced by their native human language?
There is lots of evidence that variable names are either English words, abbreviations of English words, or some combination of these two. Source code containing a large percentage of identifiers using words from other languages does exist, but it requires effort to find; there is a widely expressed view that source should be English based (based on my experience of talking to non-native English speakers, and even the odd paper discussing the issue, e.g., Language matters).
Given that variable names can prove information that reduces the effort needed to understand code, and that most code is only ever read by the person who wrote it, developers should make the most of their expertise in using their native language.
To what extent do non-native English-speaking developers make use of their non-English native language?
I have found it very difficult to even have a discussion around this question. When I broach the subject with non-native English speakers, the response is often along the lines of “our develo0pers speak good English.” I am careful to set the scene by telling them of my interest in naming, and that I think there are benefits for developers to make use of their native language. The use of non-English languages in software development is not yet a subject that is open for discussion.
I knew that sooner or later somebody would run an experiment…
How Developers Choose Names is another interesting experiment involving Dror Feitelson (the paper rather confusingly refers to it as a survey, a post on an earlier experiment).
What makes this experiment interesting is that bilingual subjects (English and Hebrew) were used, and the questions were in English or Hebrew. The 230 subjects (some professional, some student) were given a short description and asked to provide an appropriate variable/function/data-structure name; English was used for 26 of the question, and Hebrew for the other 21 questions, and subjects answered a random subset.
What patterns of Hebrew usage are present in the variable names?
Out of 2017 answers, 14 contained Hebrew characters, i.e., not enough for statistical analysis. This does not mean that all the other variable names were only derived from English words, in some cases Hebrew words appeared via transcription using the 26 English letters. For instance, using “pinuk” for the Hebrew word that means “benefit” in English. Some variables were created from a mixture of Hebrew and English words, e.g., deservedPinuks and pinuksUsed.
Analysing this data requires someone who is fluent in Hebrew and English. I am not a fluent, or even non-fluent, Hebrew speaker. My role in this debate is encouraging others, and at last I have some interesting data to show people.
The paper spends time showing how for personal preferences result in a wide selection of names being chosen by different people for the same quantity. I cannot think of any software engineering papers that have addressed this issue for variable names, but there is lots of evidence from other fields; also see figure 7.33.
Those interested in searching source code for the impact of native-language might like to look at the names of variables appearing as operands of the bitwise and logical operators. Some English words occur much more frequently in the names of these variable, compared to variables that are operands of arithmetic operators, e.g., flag, status, and signal. I predict that non-native English-speaking developers will make use of corresponding non-English words.
Estimate variability for the same task
If 100 people estimate the time needed to implement a feature, in software, what is the expected variability in the estimates?
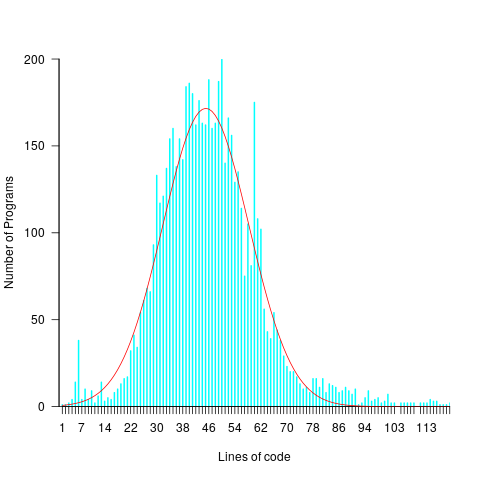
Studies of multiple implementations of the same specification suggest that standard deviation of the mean number of lines across implementations is 25% of the mean (based on data from 10 sets of multiple implementations, of various sizes).
The plot below shows lines of code against the number of programs (implementing the 3n+1 problem) containing that many lines (red line is a Normal distribution fitted by eye, code and data):
Might any variability in the estimates for task implementation be the result of individuals estimating their own performance (which is variable)?
To the extent that an estimate is based on a person’s implementation experience, a developer’s past performance will have some impact on their estimate. However, studies have found a great deal of variability between individual estimates and their corresponding performance.
One study asked 14 companies to bid on implementing a system (four were eventually chosen to implement it; see figure 5.2 in my book). The estimated elapsed time varied by a factor of ten. Until the last week this was the only study of this question for which the data was available (and may have been the only such study).
A study by Alhamed and Storer investigated crowd-sourcing of effort estimates, structured by use of planning poker. The crowd were workers on Amazon’s Mechanical Turk, and the tasks estimated came from the issue trackers of JBoss, Apache and Spring Integration (using issues that had been annotated with an estimate and actual time, along with what was considered sufficient detail to make an estimate). An initial set of 419 issues were whittled down to 30, which were made available, one at a time, as a Mechanical Turk task (i.e., only one issue was available to be estimated at any time).
Worker estimates were given using a time-based category (i.e., the values 1, 4, 8, 20, 40, 80), with each value representing a unit of actual time (i.e., one hour, half-day, day, half-week, week and two weeks, respectively).
Analysis of the results from a pilot study were used to build a model that detected estimates considered to be low quality, e.g., providing a poor justification for the estimate. These were excluded from any subsequent iterations.
Of the 506 estimates made, 321 passed the quality check.
Planning poker is an iterative process, with those making estimates in later rounds seeing estimates made in earlier rounds. So estimates made in later rounds are expected to have some correlation with earlier estimates.
Of the 321 quality check passing estimates, 153 were made in the first-round. Most of the 30 issues have 5 first-round estimates each, one has 4 and two have 6.
Workers have to pick one of five possible value as their estimate, with these values being roughly linear on a logarithmic scale, i.e., it is not possible to select an estimate from many possible large values, small values, or intermediate values. Unless most workers pick the same value, the standard deviation is likely to be large. Taking the logarithm of the estimate maps it to a linear scale, and the plot below shows the mean and standard deviation of the log of the estimates for each issue made during the first-round (code+data):

The wide spread in the standard deviations across a spread of mean values may be due to small sample size, or it may be real. The only way to find out is to rerun with larger sample sizes per issue.
Now it has been done once, this study needs to be run lots of times to measure the factors involved in the variability of developer estimates. What would be the impact of asking workers to make hourly estimates (they would not be anchored by experimenter specified values), or shifting the numeric values used for the categories (which probably have an anchoring effect)? Asking for an estimate to fix an issue in a large software system introduces the unknown of all kinds of dependencies, would estimates provided by workers who are already familiar with a project be consistently shifted up/down (compared to estimates made by those not familiar with the project)? The problem of unknown dependencies could be reduced by giving workers self-contained problems to estimate, e.g., the 3n+1 problem.
The crowdsourcing idea is interesting, but I don’t think it will scale, and I don’t see many companies making task specifications publicly available.
To mimic actual usage, research on planning poker (which appears to have non-trivial usage) needs to ensure that the people making the estimates are involved during all iterations. What is needed is a dataset of lots of planning poker estimates. Please let me know if you know of one.
Software engineering experiments: sell the idea, not the results
A new paper investigates “… the feasibility of stealthily introducing vulnerabilities in OSS via hypocrite commits (i.e., seemingly beneficial commits that in fact introduce other critical issues).” Their chosen Open source project was the Linux kernel, and they submitted three patches to the kernel review process.
This interesting idea blew up in their faces, when the kernel developers deduced that they were being experimented on (they obviously don’t have a friend on the inside). The authors have come out dodging and weaving.
What can be learned by reading the paper?
Firstly, three ‘hypocrite commits’ is not enough submissions to do any meaningful statistical analysis. I suspect it’s a convenience sample, a common occurrence in software engineering research. The authors sell three as a proof-of-concept.
How many of the submitted patches passed the kernel review process?
The paper does not say. The first eight pages provide an introduction to the Open source development model, the threat model for introducing vulnerabilities, and the characteristics of vulnerabilities that have been introduced (presumably by accident). This is followed by 2.5 pages of background and setup of the experiment (labelled as a proof-of-concept).
The paper then switches (section VII) to discussing a different, but related, topic: the lifetime of (unintended) vulnerabilities in patches that had been accepted (which I think should have been the topic of the paper. This interesting discussion is 1.5 pages; also see The life and death of statically detected vulnerabilities: An empirical study, covered in figure 6.9 in my book.
The last two pages discuss mitigation, related work, and conclusion (“…a proof-of-concept to safely demonstrate the practicality of hypocrite commits, and measured and quantified the risks.”; three submissions is not hard to measure and quantify, but the results are not to be found in the paper).
Having the paper provide the results (i.e., all three commits spotted, and a very negative response by those being experimented on) would have increased the chances of negative reviewer comments.
Over the past few years I have started noticing this kind of structure in software engineering papers, i.e., extended discussion of an interesting idea, setup of experiment, and cursory or no discussion of results. Many researchers are willing to spend lots of time discussing their ideas, but are unwilling to invest much time in the practicalities of testing them. Some reviewers (who decide whether a paper is accepted to publication) don’t see anything wrong with this approach, e.g., they accept these kinds of papers.
Software engineering research remains a culture of interesting ideas, with evidence being an optional add-on.
The impact of believability on reasoning performance
What are the processes involved in reasoning? While philosophers have been thinking about this question for several thousand years, psychologists have been running human reasoning experiments for less than a hundred years (things took off in the late 1960s with the Wason selection task).
Reasoning is a crucial ability for software developers, and I thought that there would be lots to learn from the cognitive psychologists research into reasoning. After buying all the books, and reading lots of papers, I realised that the subject was mostly convoluted rabbit holes individually constructed by tiny groups of researchers. The field of decision-making is where those psychologists interested in reasoning, and a connection to reality, hang-out.
Is there anything that can be learned from research into human reasoning (other than that different people appear to use different techniques, and some problems are more likely to involve particular techniques)?
A consistent result from experiments involving syllogistic reasoning is that subjects are more likely to agree that a conclusion they find believable follows from the premise (and are more likely to disagree with a conclusion they find unbelievable). The following is perhaps the most famous syllogism (the first two lines are known as the premise, and the last line is the conclusion):
All men are mortal.
Socrates is a man.
Therefore, Socrates is mortal. |
Would anybody other than a classically trained scholar consider that a form of logic invented by Aristotle provides a reasonable basis for evaluating reasoning performance?
Given the importance of reasoning ability in software development, there ought to be some selection pressure on those who regularly write software, e.g., software developers ought to give a higher percentage of correct answers to reasoning problems than the general population. If the selection pressure for reasoning ability is not that great, at least software developers have had a lot more experience solving this kind of problem, and practice should improve performance.
The subjects in most psychology experiments are psychology undergraduates studying in the department of the researcher running the experiment, i.e., not the general population. Psychology is a numerate discipline, or at least the components I have read up on have a numeric orientation, and I have met a fair few psychology researchers who are decent programmers. Psychology undergraduates must have an above general-population performance on syllogism problems, but better than professional developers? I don’t think so, but then I may be biased.
A study by Winiger, Singmann, and Kellen asked subjects to specify whether the conclusion of a syllogism was valid/invalid/don’t know. The syllogisms used were some combination of valid/invalid and believable/unbelievable; examples below:
Believable Unbelievable
Valid
No oaks are jubs. No trees are punds.
Some trees are jubs. Some Oaks are punds.
Therefore, some trees Therefore, some oaks
are not oaks. are not trees.
Invalid
No tree are brops. No oaks are foins.
Some oaks are brops. Some trees are foins.
Therefore, some trees Therefore, some oaks
are not oaks. are not trees. |
The experiment was run using an online crowdsource site, and 354 data sets were obtained.
The plot below shows the impact of conclusion believability (red)/unbelievability (blue/green) on subject performance, when deciding whether a syllogism was valid (left) or invalid (right), (code+data):
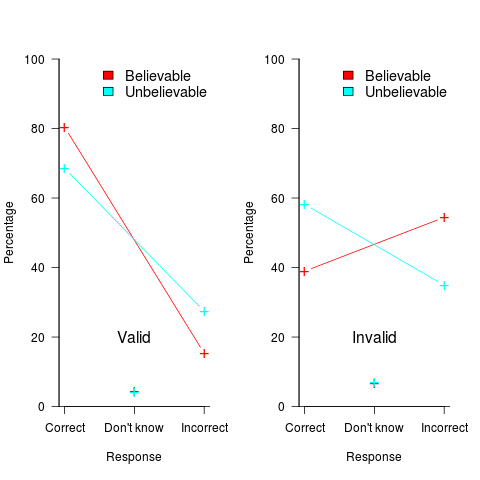
The believability of the conclusion biases the responses away/towards the correct answer (the error bars are tiny, and have not been plotted). Building a regression model puts numbers to the difference, and information on the kind of premise can also be included in the model.
Do professional developers exhibit such a large response bias (I would expect their average performance to be better)?
People tend to write fewer negative tests, than positive tests. Is this behavior related to the believability that certain negative events can occur?
Believability is an underappreciated coding issue.
Hopefully people will start doing experiments to investigate this issue 🙂
Payback time-frame for research in software engineering
What are the major questions in software engineering that researchers should be trying to answer?
A high level question whose answer is likely to involve life, the universe, and everything is: What is the most cost-effective way to build software systems?
Viewing software engineering research as an attempt to find the answer to a big question mirrors physicists quest for a Grand Unified Theory of how the Universe works.
Physicists have the luxury of studying the Universe at their own convenience, the Universe does not need their input to do a better job.
Software engineering is not like physics. Once a software system has been built, the resources have been invested, and there is no reason to recreate it using a more cost-effective approach (the zero cost of software duplication means that manufacturing cost is the cost of the first version).
Designing and researching new ways of building software systems may be great fun, but the time and money needed to run the realistic experiments needed to evaluate their effectiveness is such that they are unlikely to be run. Searching for more cost-effective software development techniques by paying to run the realistic experiments needed to evaluate them, and waiting for the results to become available, is going to be expensive and time-consuming. A theory is proposed, experiments are run, results are analysed; rinse and repeat until a good-enough cost-effective technique is found. One iteration will take many years, and this iterative process is likely to take many decades.
Very many software systems are being built and maintained, and each of these is an experiment. Data from these ‘experiments’ provides a cost-effective approach to improving existing software engineering practices by studying the existing practices to figure out how they work (or don’t work).
Given the volume of ongoing software development, most of the payback from any research investment is likely to occur in the near future, not decades from now; the evidence shows that source code has a short and lonely existence. Investing for a payback that might occur 30-years from now makes no sense; researchers I talk to often use this time-frame when I ask them about the benefits of their research, i.e., just before they are about to retire. Investing in software engineering research only makes economic sense when it is focused on questions that are expected to start providing payback in, say, 3-5 years.
Who is going to base their research on existing industry practices?
Researching existing practices often involves dealing with people issues, and many researchers in computing departments are not that interested in the people side of software engineering, or rather they are more interested in the computer side.
Algorithm oriented is how I would describe researchers who claim to be studying software engineering. I am frequently told about the potential for huge benefits from the discovery of more efficient algorithms. For many applications, algorithms are now commodities, i.e., they are good enough. Those with a career commitment to studying algorithms have a blinkered view of the likely benefits of their work (most of those I have seen are doing studying incremental improvements, and are very unlikely to make a major break through).
The number of researchers studying what professional developers do, with an aim to improving it, is very small (I am excluding the growing number of fake researchers doing surveys). While I hope there will be a significant growth in numbers, I’m not holding my breadth (at least in the short term; as for the long term, Planck’s experience with quantum mechanics was: “Science advances one funeral at a time”).
How should involved if-statement conditionals be structured?
Which of the following two if-statements do you think will be processed by readers in less time, and with fewer errors, when given the value of x, and asked to specify the output?
// First - sequence of subexpressions if (x > 0 && x < 10 || x > 20 && x < 30) print("a"); else print "b"); // Second - nested ifs if (x > 0 && x < 10) print("c"); else if (x > 20 && x < 30) print("d"); else print("e"); |
Ok, the behavior is not identical, in that the else if-arm produces different output than the preceding if-arm.
The paper Syntax, Predicates, Idioms — What Really Affects Code Complexity? analyses the results of an experiment that asked this question, including more deeply nested if-statements, the use of negation, and some for-statement questions (this post only considers the number of conditions/depth of nesting components). A total of 1,583 questions were answered by 220 professional developers, with 415 incorrect answers.
Based on the coefficients of regression models fitted to the results, subjects processed the nested form both faster and with fewer incorrect answers (code+data). As expected performance got slower, and more incorrect answers given, as the number of intervals in the if-condition increased (up to four in this experiment).
I think short-term memory is involved in this difference in performance; or at least I can concoct a theory that involves a capacity limited memory. Comprehending an expression (such as the conditional in an if-statement) requires maintaining information about the various components of the expression in working memory. When the first subexpression of x > 0 && x < 10 || x > 20 && x < 30 is false, and the subexpression after the || is processed, there is no now forget-what-went-before point like there is for the nested if-statements. I think that the single expression form is consuming more working memory than the nested form.
Does the result of this experiment (assuming it is replicated) mean that developers should be recommended to write sequences of conditions (e.g., the first if-statement example) about as:
if (x > 0 && x < 10) print("a"); else if (x > 20 && x < 30) print("a"); else print("b"); |
Duplicating code is not good, because both arms have to be kept in sync; ok, a function could be created, but this is extra effort. As other factors are taken into account, the costs of the nested form start to build up, is the benefit really worth the cost?
Answering this question is likely to need a lot of work, and it would be a more efficient use of resources to address questions about more commonly occurring conditions first.
A commonly occurring use is testing a single range; some of the ways of writing the range test include:
if (x > 0 && x < 10) ... if (0 < x && x < 10) ... if (10 > x && x > 0) ... if (x > 0 && 10 > x) ... |
Does one way of testing the range require less effort for readers to comprehend, and be more likely to be interpreted correctly?
There have been some experiments showing that people are more likely to give correct answers to questions involving information expressed as linear syllogisms, if the extremes are at the start/end of the sequence, such as in the following:
A is better than B
B is better than C |
and not the following (which got the lowest percentage of correct answers):
B is better than C
B is worse than A |
Your author ran an experiment to find out whether developers were more likely to give correct answers for particular forms of range tests in if-conditions.
Out of a total of 844 answers, 40 were answered incorrectly (roughly one per subject; it was a paper and pencil experiment, so no timings). It's good to see that the subjects were so competent, but with so few mistakes made the error bars are very wide, i.e., too few mistakes were made to be able to say that one representation was less mistake-prone than another.
I hope this post has got other researchers interested in understanding developer performance, when processing if-statements, and that they will be running more experiments help shed light on the processes involved.
Performance impact of comments on tasks taking a few minutes
How cost-effective is an investment in commenting code?
Answering this question requires knowing the time needed to write the comment and the time they save for later readers of the code.
A recent study investigated the impact of comments in small programming tasks on developer performance, and Sebastian Nielebock, the first author, kindly sent me a copy of the data.
How might the performance impact of comments be measured?
The obvious answer is to ask subjects to solve a coding problem, with half the subjects working with code containing comments and the other half the same code without the comments. This study used three kinds of commenting: No comments, Implementation comments and Documentation comments; the source was in Java.
Were the comments in the experiment useful, in the sense of providing information that was likely to save readers some time? A preliminary run was used to check that the comments provided some benefit.
The experiment was designed to be short enough that most subjects could complete it in less than an hour (average time to complete all tasks was 31 minutes). My own experience with running experiments is that it is possible to get professional developers to donate an hour of their time.
What is a realistic and experimentally useful amount of work to ask developers to in an hour?
The authors asked subjects to complete 9-tasks; three each of applying the code (i.e., use the code’s API), fix a bug in the code, and extend the code. Would a longer version of one of each, rather than a shorter three of each been better? I think the only way to find out is to try it both ways (I hope the authors plan to do another version).
What were the results (code+data)?
Regular readers will know, from other posts discussing experiments, that the biggest factor is likely to be subject (professional developers+students) differences, and this is true here.
Based on a fitted regression model, Documentation comments slowed performance on a task by 30 seconds, compared to No comments and Implementation comments (which both had the same performance impact). Given that average task completion time was 205 seconds, this is a 15% slowdown for Documentation comments.
This study set out to measure the performance impact of comments on small programming tasks. The answer, at least for tasks designed to take a few minutes, is that No comments, or if comments are required, then write Implementation comments.
This experiment measured the performance impact of comments on developers who did not write the code containing them. These developers have to first read and understand the comments (which takes time). However, the evidence suggests that code is mostly modified by the developer who wrote it (just reading the code does not leave a record that can be analysed). In this case, the reading a comment (that the developer previously wrote) can trigger existing memories, i.e., it has a greater information content for the original author.
Will comments have a bigger impact when read by the person who wrote them (and the code), or on tasks taking more than a few minutes? I await the results of more experiments…
Update: I have updated the script based on feedback about the data from Sebastian Nielebock.