Archive
Agile and Waterfall as community norms
While rapidly evolving computer hardware has been a topic of frequent public discussion since the first electronic computer, it has taken over 40 years for the issue of rapidly evolving customer requirements to become a frequent topic of public discussion (thanks to the Internet).
The following quote is from the Opening Address, by Andrew Booth, of the 1959 Working Conference on Automatic Programming of Digital Computers (published as the first “Annual Review in Automatic Programming”):
'Users do not know what they wish to do.' This is a profound truth. Anyone who has had the running of a computing machine, and, especially, the running of such a machine when machines were rare and computing time was of extreme value, will know, with exasperation, of the user who presents a likely problem and who, after a considerable time both of machine and of programmer, is presented with an answer. He then either has lost interest in the problem altogether, or alternatively has decided that he wants something else. |
Why did the issue of evolving customer requirements lurk in the shadows for so long?
Some of the reasons include:
- established production techniques were applied to the process of building software systems. What is now known in software circles as the Waterfall model was/is an established technique. The figure below is from the 1956 paper Production of Large Computer Programs by Herbert Benington (Winston Royce’s 1970 paper has become known as the paper that introduced Waterfall, but the contents actually propose adding iterations to what Royce treats as an established process):
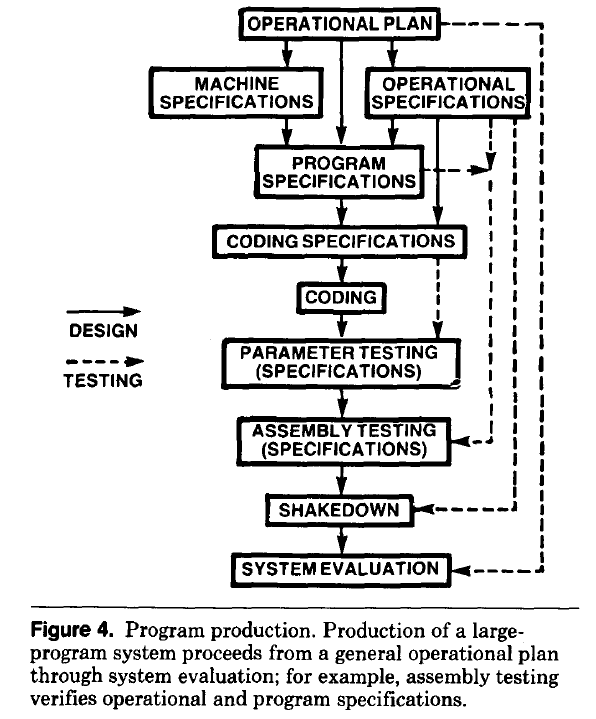
- management do not appreciate how quickly requirements can change (at least until they have experience of application development). In the 1980s, when microcomputers were first being adopted by businesses, I had many conversations with domain experts who were novice programmers building their first application for their business/customers. They were invariably surprised by the rate at which requirements changed, as development progressed.
While in public the issue lurked in the shadows, my experience is that projects claiming to be using Waterfall invariably had back-channel iterations, and requirements were traded, i.e., drop those and add these. Pre-Internet, any schedule involving more than two releases a year could be claimed to be making frequent releases.
Managers claimed to be using Waterfall because it was what everybody else did (yes, some used it because it was the most effective technique for their situation, and on some new projects it may still be the most effective technique).
Now that the issue of rapidly evolving requirements is out of the closet, what’s to stop Agile, in some form, being widely used when ‘rapidly evolving’ needs to be handled?
Discussion around Agile focuses on customers and developers, with middle management not getting much of a look-in. Companies using Agile don’t have many layers of management. Switching to Agile results in a lot of power shifting from middle management to development teams, in fact, these middle managers now look surplus to requirements. No manager is going to support switching to a development approach that makes them redundant.
Adam Yuret has another theory for why Agile won’t spread within enterprises. Making developers the arbiters of maximizing customer value prevents executives mandating new product features that further their own agenda, e.g., adding features that their boss likes, but have little customer demand.
The management incentives against using Agile in practice does not prevent claims being made about using Agile.
Now that Agile is what everybody claims to be using, managers who don’t want to stand out from the crowd find a way of being part of the community.
Is the code reuse problem now solved?
Writing a program to solve a problem involves breaking the problem down into subcomponents that have a known coding solution, and connecting the input/output of these subcomponents into sequences that produced the desired behavior.
When computers first became available, developers had to write every subcomponent. It was soon noticed that new programs contained some functionality that was identical to functionality present in previously written programs, and software libraries were created to reduce development cost/time through reuse of existing code. Developers have being sharing code since the very start of computing.
To be commercially viable, computer manufacturers discovered that they not only had to provide vendor specific libraries, they also had to support general purpose functionality, e.g., sorting and maths libraries.
The Internet significantly reduced the cost of finding and distributing software, enabling an explosion in the quality and quantity of publicly available source code. It became possible to write major subcomponents by gluing together third-party libraries and packages (subject to licensing issues).
Diversity of the ecosystems in which libraries/packages have to function means that developers working in different environments have to apply different glue. Computing diversity increases costs.
A lot of effort was invested in trying to increase software reuse in a very diverse world.
In the 1990 there was a dramatic reduction in diversity, caused by a dramatic reduction in the number of distinct cpus, operating systems and compilers. However, commercial and personal interests continue to drive the creation of new cpus, operating systems, languages and frameworks.
The reduction in diversity has made it cheaper to make libraries/packages more widely available, and reduced the variety of glue coding patterns. However, while glue code contains many common usage patterns, they tend not to be sufficiently substantial or distinct enough for a cost-effective reuse solution to be readily apparent.
The information available on developer question/answer sites, such as Stackoverflow, provides one form of reuse sharing for glue code.
The huge amounts of source code containing shared usage patterns are great training input for large languages models, and widespread developer interest in these patterns means that the responses from these trained models is of immediate practical use for many developers.
LLMs appear to be the long sought cost-effective solution to the technical problem of code reuse; it’s too early to say what impact licensing issues will have on widespread adoption.
One consequence of widespread LLM usage is a slowing of the adoption of new packages, because LLMs will not know anything about them. LLMs are also the death knell for fashionable new languages, which is a very good thing.
Studying the lifetime of Open source
A software system can be said to be dead when the information needed to run it ceases to be available.
Provided the necessary information is available, plus time/money, no software ever has to remain dead, hardware emulators can be created, support libraries can be created, and other necessary files cobbled together.
In the case of software as a service, the vendor may simply stop supplying the service; after which, in my experience, critical components of the internal service ecosystem soon disperse and are forgotten about.
Users like the software they use to be actively maintained (i.e., there are one or more developers currently working on the code). This preference is culturally driven, in that we are living through a period in which most in-use software systems are actively maintained.
Active maintenance is perceived as a signal that the software has some amount of popularity (i.e., used by other people), and is up-to-date (whatever that means, but might include supporting the latest features, or problem reports are being processed; neither of which need be true). Commercial users like actively maintained software because it enables the option of paying for any modifications they need to be made.
Software can be a zombie, i.e., neither dead or alive. Zombie software will continue to work for as long as the behavior of its external dependencies (e.g., libraries) remains sufficiently the same.
Active maintenance requires time/money. If active maintenance is required, then invest the time/money.
Open source software has become widely used. Is Open source software frequently maintained, or do projects inhabit some form of zombie state?
Researchers have investigated various aspects of the life cycle of open source projects, including: maintenance activity, pull acceptance/merging or abandoned, and turnover of core developers; also, projects in niche ecosystems have been investigated.
The commits/pull requests/issues, of circa 1K project repos with lots of stars, is data that can be automatically extracted and analysed in bulk. What is missing from the analysis is the context around the creation, development and apparent abandonment of these projects.
Application areas and development tools (e.g., editor, database, gui framework, communications, scientific, engineering) tend to have a few widely used programs, which continue to be actively worked on. Some people enjoy creating programs/apps, and will start development in an area where there are existing widely used programs, purely for the enjoyment or to scratch an itch; rarely with the intent of long term maintenance, even when their project attracts many other developers.
I suspect that much of the existing research is simply measuring the background fizz of look-alike programs coming and going.
A more realistic model of the lifecycle of Open source projects requires human information; the intent of the core developers, e.g., whether the project is intended to be long-term, primarily supported by commercial interests, abandoned for a successor project, or whether events got in the way of the great things planned.
Printing press+widespread religious behavior: A theory
The book The Weirdest People in the World: How the West Became Psychologically Peculiar and Particularly Prosperous provides an explanation of the processes which weakened the existing social ties of family and tribe; however, the emergence of WEIRD people (Western, Educated, Industrialized, Rich and Democratic) required new social norms to spread and be accepted throughout society. A major technical innovation, in the form of the printing press, provided the means for mass communication of ideas and practices.
David High-Jones’ book Wyclif’s Dust: Western Cultures from the Printing Press to the Present describes the social consequences of what he calls book religion; a combination of deeply religious western societies and the ability of individuals to write and sell affordable books (made possible by the printing press). Religion+printing press created the conditions for what High-Jones calls a hothouse culture, a period from the 1600s to the end of the 1800s.
Around 1440 the printing press is invented and quickly spreads; around 5 million books were handwritten in the 1400s, about 80 million books were produced in the first 50 years of printing, and around a billion in the 1700s. During the 1500s the Protestant reformation happens; Protestant encouraged its followers to read the Bible, which creates a demand for printed Bibles and the need to be able to read (which increases literacy rates). In England, between 1480-1640, 40% of published books were religious.
The changes to society’s existing norms are wrought by cultural transmission, initially via middle class parents making use of edifying books to teach their children moral values and social skills, later Sunday schools took on this role, but also had to offer reading lessons to attract members. In the adult world, accepted norms were maintained by social enforcement. The impact on western societies was widespread because observant religious behavior was widespread.
The original intent, of those writing the religious books, was the creation of a god fearing society. In practice, a trust based society was created, where workers might be relied upon not to shirk their duties and businessmen to not renege on agreements.
In the beginning science, in the form of printed technical books, rarely made an appearance. In the 1700s the Enlightenment happens, and scientific books are discussed by small collections of disparate individuals. The industrial revolution happens, but the bulk of the demand is for trustworthy workers; technical and scientific know how remains a minority interest.
In Part I of the book, High-Jones weaves a reading and convincing narrative. Part II, 1900 to today, is a tale of the crumbling and breakdown of the social forces and incentives that creates the trust based society; while example are enumerated, no overarching theory is proposed (I skimmed this part).
Moore’s law was a socially constructed project
Moore’s law was a socially constructed project that depended on the coordinated actions of many independent companies and groups of individuals to last for as long it did.
All products evolve, but what was it about Moore’s law that enabled microelectronics to evolve so much faster and for longer than most other products?
Moore’s observation, made in 1965 based on four data points, was that the number of components contained in a fabricated silicon device doubles every year. The paper didn’t make this claim in words, but a line fitted to four yearly data points (starting in 1962) suggested this behavior continuing into the mid-1970s. The introduction of IBM’s Personal Computer, in 1981 containing Intel’s 8088 processor, led to interested parties coming together to create a hugely profitable ecosystem that depended on the continuance of Moore’s law.
The plot below shows Moore’s four points (red) and fitted regression model (green line). In practice, since 1970, fitting a regression model (purple line) to the number of transistors in various microprocessors (blue/green, data from Wikipedia), finds that the number of transistors doubled every two years (code+data):
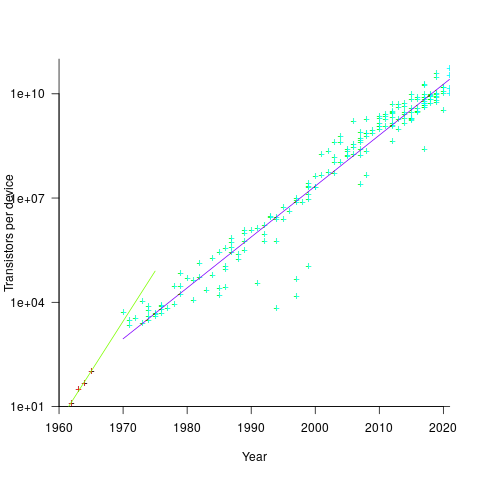
In the early days, designing a device was mostly a manual operation; that is, the circuit design and logic design down to the transistor level were hand-drawn. This meant that creating a device containing twice as many transistors required twice as many engineers. At some point the doubling process either becomes uneconomic or it takes forever to get anything done because of the coordination effort.
The problem of needing an exponentially-growing number of engineers was solved by creating electronic design automation tools (EDA), starting in the 1980s, with successive generations of tools handling ever higher levels of abstraction, and human designers focusing on the upper levels.
The use of EDA provides a benefit to manufacturers (who can design differentiated products) and to customers (e.g., products containing more functionality).
If EDA had not solved the problem of exponential growth in engineers, Moore’s law would have maxed-out in the early 1980s, with around 150K transistors per device. However, this would not have stopped the ongoing shrinking of transistors; two economic factors independently incentivize the creation of ever smaller transistors.
When wafer fabrication technology improvements make it possible to double the number of transistors on a silicon wafer, then around twice as many devices can be produced (assuming unchanged number of transistors per device, and other technical details). The wafer fabrication cost is greater (second row in table below), but a lot less than twice as much, so the manufacturing cost per device is much lower (third row in table).
The doubling of transistors primarily provides a manufacturer benefit.
The following table gives estimates for various chip foundry economic factors, in dollars (taken from the report: AI Chips: What They Are and Why They Matter). Node, expressed in nanometers, used to directly correspond to the length of a particular feature created during the fabrication process; these days it does not correspond to the size of any specific feature and is essentially just a name applied to a particular generation of chips.
Node (nm) 90 65 40 28 20 16/12 10 7 5 Foundry sale price per wafer 1,650 1,937 2,274 2,891 3,677 3,984 5,992 9,346 16,988 Foundry sale price per chip 2,433 1,428 713 453 399 331 274 233 238 Mass production year 2004 2006 2009 2011 2014 2015 2017 2018 2020 Quarter Q4 Q4 Q1 Q4 Q3 Q3 Q2 Q3 Q1 Capital investment per wafer 4,649 5,456 6,404 8,144 10,356 11,220 13,169 14,267 16,746 processed per year Capital consumed per wafer 411 483 567 721 917 993 1,494 2,330 4,235 processed in 2020 Other costs and markup 1,293 1,454 1,707 2,171 2,760 2,990 4,498 7,016 12,753 per wafer |
The second economic factor incentivizing the creation of smaller transistors is Dennard scaling, a rarely heard technical term named after the first author of a 1974 paper showing that transistor power consumption scaled with area (for very small transistors). Halving the area occupied by a transistor, halves the power consumed, at the same frequency.
The maximum clock-frequency of a microprocessor is limited by the amount of heat it can dissipate; the heat produced is proportional to the power consumed, which is approximately proportional to the clock-frequency. Instead of a device having smaller transistors consume less power, they could consume the same power at double the frequency.
Dennard scaling primarily provides a customer benefit.
Figuring out how to further shrink the size of transistors requires an investment in research, followed by designing/(building or purchasing) new equipment. Why would a company, who had invested in researching and building their current manufacturing capability, be willing to invest in making it obsolete?
The fear of losing market share is a commercial imperative experienced by all leading companies. In the microprocessor market, the first company to halve the size of a transistor would be able to produce twice as many microprocessors (at a lower cost) running twice as fast as the existing products. They could (and did) charge more for the latest, faster product, even though it cost them less than the previous version to manufacture.
Building cheaper, faster products is a means to an end; that end is receiving a decent return on the investment made. How large is the market for new microprocessors and how large an investment is required to build the next generation of products?
Rock’s law says that the cost of a chip fabrication plant doubles every four years (the per wafer price in the table above is increasing at a slower rate). Gambling hundreds of millions of dollars, later billions of dollars, on a next generation fabrication plant has always been a high risk/high reward investment.
The sales of microprocessors are dependent on the sale of computers that contain them, and people buy computers to enable them to use software. Microprocessor manufacturers thus have to both convince computer manufacturers to use their chip (without breaking antitrust laws) and convince software companies to create products that run on a particular processor.
The introduction of the IBM PC kick-started the personal computer market, with Wintel (the partnership between Microsoft and Intel) dominating software developer and end-user mindshare of the PC compatible market (in no small part due to the billions these two companies spent on advertising).
An effective technique for increasing the volume of microprocessors sold is to shorten the usable lifetime of the computer potential customers currently own. Customers buy computers to run software, and when new versions of software can only effectively be used in a computer containing more memory or on a new microprocessor which supports functionality not supported by earlier processors, then a new computer is needed. By obsoleting older products soon after newer products become available, companies are able to evolve an existing customer base to one where the new product is looked upon as the norm. Customers are force marched into the future.
The plot below shows sales volume, in gigabytes, of various sized DRAM chips over time. The simple story of exponential growth in sales volume (plus signs) hides the more complicated story of the rise and fall of succeeding generations of memory chips (code+data):
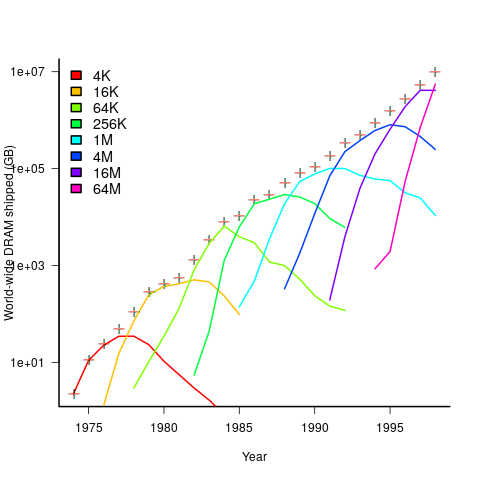
The Red Queens had a simple task, keep buying the latest products. The activities of the companies supplying the specialist equipment needed to build a chip fabrication plant has to be coordinated, a role filled by the International Technology Roadmap for Semiconductors (ITRS). The annual ITRS reports contain detailed specifications of the expected performance of the subsystems involved in the fabrication process.
Moore’s law is now dead, in that transistor doubling now takes longer than two years. Would transistor doubling time have taken longer than two years, or slowed down earlier, if:
- the ecosystem had not been dominated by two symbiotic companies, or did network effects make it inevitable that there would be two symbiotic companies,
- the Internet had happened at a different time,
- if software applications had quickly reached a good enough state,
- if cloud computing had gone mainstream much earlier.
Tracking software evolution via its Changelog
Software that is used evolves. How fast does software evolve, e.g., much new functionality is added and how much existing functionality is updated?
A new software release is often accompanied by a changelog which lists new, changed and deleted functionality. When software is developed using a continuous release process, the changelog can be very fine-grained.
The changelog for the Beeminder app contains 3,829 entries, almost one per day since February 2011 (around 180 entries are not present in the log I downloaded, whose last entry is numbered 4012).
Is it possible to use the information contained in the Beeminder changelog to estimate the rate of growth of functionality of Beeminder over time?
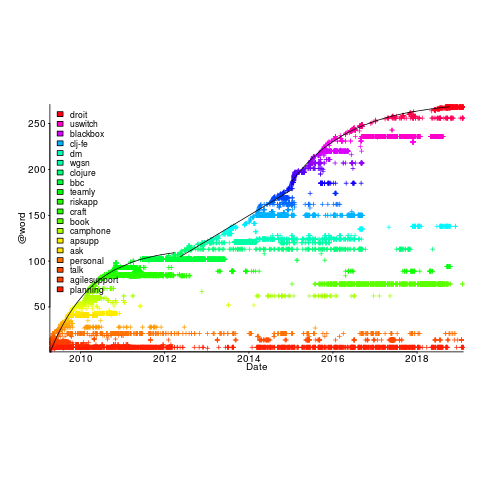
My thinking is driven by patterns in a plot of the Renzo Pomodoro dataset. Renzo assigned a tag-name (sometimes two) to each task, which classified the work involved, e.g., @planning. The following plot shows the date of use of each tag-name, over time (ordered vertically by first use). The first and third black lines are fitted regression models of the form  , where:
, where:  is a constant and
is a constant and  is the number of days since the start of the interval fitted; the second (middle) black line is a fitted straight line.
is the number of days since the start of the interval fitted; the second (middle) black line is a fitted straight line.
How might a changelog line describing a day’s change be distilled to a much shorter description (effectively a tag-name), with very similar changes mapping to the same description?
Named-entity recognition seemed like a good place to start my search, and my natural language text processing tool of choice is still spaCy (which continues to get better and better).
spaCy is Python based and the processing pipeline could have all been written in Python. However, I’m much more fluent in awk for data processing, and R for plotting, so Python was just used for the language processing.
The following shows some Beeminder changelog lines after stripping out urls and formatting characters:
Cheapo bug fix for erroneous quoting of number of safety buffer days for weight loss graphs. Bugfix: Response emails were accidentally off the past couple days; fixed now. Thanks to user bmndr.com/laur for alerting us! More useful subject lines in the response emails, like "wrong lane!" or whatnot. Clearer/conciser stats at bottom of graph pages. (Will take effect when you enter your next datapoint.) Progress, rate, lane, delta. Better handling of significant digits when displaying numbers. Cf stackoverflow.com/q/5208663 |
The code to extract and print the named-entities in each changelog line could not be simpler.
import spacy import sys nlp = spacy.load("en_core_web_sm") # load trained English pipelines count=0 for line in sys.stdin: count += 1 print(f'> {count}: {line}') # doc=nlp(line) # do the heavy lifting # for ent in doc.ents: # iterate over detected named-entities print(ent.lemma_, ent.label_) |
To maximize the similarity between named-entities appearing on different lines the lemmas are printed, rather than original text (i.e., words appear in their base form).
The label_ specifies the kind of named-entity, e.g., person, organization, location, etc.
This code produced 2,225 unique named-entities (5,302 in total) from the Beeminder changelog (around 0.6 per day), and failed to return a named-entity for 33% of lines. I was somewhat optimistically hoping for a few hundred unique named-entities.
There are several problems with this simple implementation:
- each line is considered in isolation,
- the change log sometimes contains different names for the same entity, e.g., a person’s full name, Christian name, or twitter name,
- what appear to be uninteresting named-entities, e.g., numbers and dates,
- the language does not know much about software, having been training on a corpus of general English.
Handling multiple names for the same entity would a lot of work (i.e., I did nothing), ‘uninteresting’ named-entities can be handled by post-processing the output.
A language processing pipeline that is not software-concept aware is of limited value. spaCy supports adding new training models, all I need is a named-entity model trained on manually annotated software engineering text.
The only decent NER training data I could find (trained on StackOverflow) was for BERT (another language processing tool), and the data format is very different. Existing add-on spaCy models included fashion, food and drugs, but no software engineering.
Time to roll up my sleeves and create a software engineering model. Luckily, I found a webpage that provided a good user interface to tagging sentences and generated the json file used for training. I was patient enough to tag 200 lines with what I considered to be software specific named-entities. … and now I have broken the NER model I built…
The following plot shows the growth in the total number of named-entities appearing in the changelog, and the number of unique named-entities (with the 1,996 numbers and dates removed; code+data);
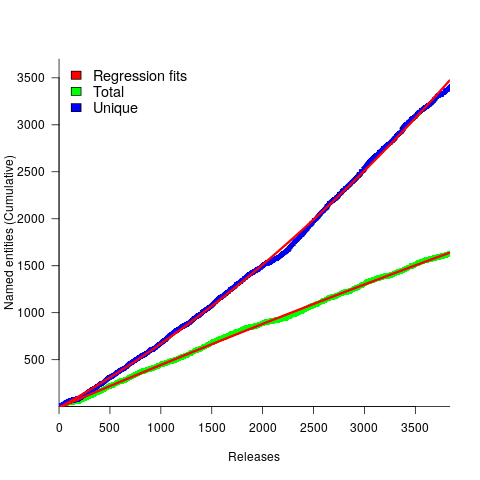
The regression fits (red lines) are quadratics, slightly curving up (total) and down (unique); the linear growth components are: 0.6 per release for total, and 0.46 for unique.
Including software named-entities is likely to increase the total by at least 15%, but would have little impact on the number of unique entries.
This extraction pipeline processes one release line at a time. Building a set of Beeminder tag-names requires analysing the changelog as a whole, which would take a lot longer than the day spent on this analysis.
The Beeminder developers have consistently added new named-entities to the changelog over more than eleven years, but does this mean that more features have been consistently added to the software (or are they just inventing different names for similar functionality)?
It is not possible to answer this question without access to the code, or experience of using the product over these eleven years.
However, staying in business for eleven years is a good indicator that the developers are doing something right.
The software heritage of K&R C
The mission statement of the Software Heritage is “… to collect, preserve, and share all software that is publicly available in source code form.”
What are the uses of the preserved source code that is collected? Lots of people visit preserved buildings, but very few people are interested in looking at source code.
One use-case is tracking the evolution of changes in developer usage of various programming language constructs. It is possible to use Github to track the adoption of language features introduced after 2008, when the company was founded, e.g., new language constructs in Java. Over longer time-scales, the Software Heritage, which has source code going back to the 1960s, is the only option.
One question that keeps cropping up when discussing the C Standard, is whether K&R C continues to be used. Technically, K&R C is the language defined by the book that introduced C to the world. Over time, differences between K&R C and the C Standard have fallen away, as compilers cease supporting particular K&R ways of doing things (as an option or otherwise).
These days, saying that code uses K&R C is taken to mean that it contains functions defined using the K&R style (see sentence 1818), e.g.,
writing:
int f(a, b) int a; float b; { /* declarations and statements */ } |
rather than:
int f(int a, float b) { /* declarations and statements */ } |
As well as the syntactic differences, there are semantic differences between the two styles of function definition, but these are not relevant here.
How much longer should the C Standard continue to support the K&R style of function definition?
The WG14 committee prides itself on not breaking existing code, or at least not lots of it. How much code is out there, being actively maintained, and containing K&R function definitions?
Members of the committee agree that they rarely encounter this K&R usage, and it would be useful to have some idea of the decline in use over time (with the intent of removing support in some future revision of the standard).
One way to estimate the evolution in the use/non-use of K&R style function definitions is to analyse the C source created in each year since the late 1970s.
The question is then: How representative is the Software Heritage C source, compared to all the C source currently being actively maintained?
The Software Heritage preserves publicly available source, plus the non-public, proprietary source forming the totality of the C currently being maintained. Does the public and non-public C source have similar characteristics, or are there application domains which are poorly represented in the publicly available source?
Embedded systems is a very large and broad application domain that is poorly represented in the publicly available C source. Embedded source tends to be heavily tied to the hardware on which it runs, and vendors tend to be paranoid about releasing internal details about their products.
The various embedded systems domains (e.g., 8, 16, 32, 64-bit processor) tend to be a world unto themselves, and I would not be surprised to find out that there are enclaves of K&R usage (perhaps because there is no pressure to change, or because the available tools are ancient).
At the moment, the Software Heritage don’t offer code search functionality. But then, the next opportunity for major changes to the C Standard is probably 5-years away (the deadline for new proposals on the current revision has passed); plenty of time to get to a position where usage data can be obtained 🙂
Production of software may continue to be craft based
Andrew Carnegie made his fortune in the steel industry, and his autobiography is a fascinating insight into the scientific vs. craft/folklore approach to smelting iron ore. Carnegie measured the processes involved in smelting; he tracked the input and outputs involved in the smelting process, and applied the newly available scientific knowledge (e.g., chemistry) to minimize the resources needed to extract iron from ore. Other companies continued to treat Iron smelting as a suck-it-and-see activity, driven by personal opinion and the application of techniques that had worked in the past.
The technique of using what-worked-last-time can be a successful strategy when the variability of the inputs is low. In the case of smelting Iron there was a lot of variability in the Iron ore, Limestone and Coke fed into the furnaces. The smelting companies in Carnegie’s day ‘solved’ this input variability problem by restricting their purchase of raw materials to mines that delivered material that worked last time.
Hiring an experienced chemist (the only smelting company to do so), Carnegie found out that the quality of ore (i.e., percentage Iron content) in some mines with a high reputation was much lower than the ore quality of some mines with a low reputation; Carnegie was able to obtain a low price for high quality ore because other companies did not appreciate its characteristics (and shunned using it). Other companies were unable to extract Iron from high quality ore because they stuck to using a process that worked for lower quality ore (the amount of Limestone and Coke added to the smelting process has to be adjusted based on the Iron content of the ore, otherwise the process may deliver poor results, or even fail to produce Iron; see chapter 13).
When Carnegie’s application of scientific knowledge, and his competitors’ opinion driven production, is combined with being a good businessman, it’s no surprise that Carnegie made a fortune from his Iron smelting business.
What are the parallels between iron smelting in Carnegie’s day and the software industry?
An obvious parallel is the industry dominance of opinion driven processes. But then, the lack of any scientific basis for the processes involved in building software systems would seem to make drawing parallels a pointless exercise.
Let’s assume that there was a scientific basis for some of the major processes involved in software engineering. Would any of these science-based processes be adopted?
The reason for using science based knowledge and mechanization is to reduce costs, which may lead to increased profits or just staying in business (in a Red Queen’s race).
Agriculture is an example of a business where science and mechanization dominate, and building construction is a domain where this has not happened. Perhaps building construction will become more mechanized when unknown missing components become available (mechanization was available for agricultural processes in the 1700s, but they did not spread for a century or two, e.g., threshing machines).
It’s possible to find parallels between software engineering and the smelting process, agriculture, and building construction. In fact, it parallels can probably be found between software engineering and any other major business domain.
Drawing parallels between software engineering and other major business domains creates a sense of familiarity. In practice, software is unlike most existing business domains in that software products are one-off creations of an intangible good, which has (virtually) zero cost of reproduction, while the economics of creating tangible goods (e.g., by smelting, sowing and reaping, or building houses) is all about reducing the far from zero cost of reproduction.
Perhaps the main take-away from the history of the production of tangible goods is that the scientific method has not always supplanted the craft approach to production.
Widely used programming languages: past, present, and future
Programming languages are like pop groups in that they have followers, fans and supporters; new ones are constantly being created and some eventually become widely popular, while those that were once popular slowly fade away or mutate into something else.
Creating a language is a relatively popular activity. Science fiction and fantasy authors have been doing it since before computers existed, e.g., the Elf language Quenya devised by Tolkien, and in the computer age Star Trek’s Klingon. Some very good how-to books have been written on the subject.
As soon as computers became available, people started inventing programming languages.
What have been the major factors influencing the growth to widespread use of a new programming languages (I’m ignoring languages that become widespread within application niches)?
Cobol and Fortran became widely used because there was widespread implementation support for them across computer manufacturers, and they did not have to compete with any existing widely used languages. Various niches had one or more languages that were widely used in that niche, e.g., Algol 60 in academia.
To become widely used during the mainframe/minicomputer age, a new language first had to be ported to the major computers of the day, whose products sometimes supported multiple, incompatible operating systems. No new languages became widely used, in the sense of across computer vendors. Some new languages were widely used by developers, because they were available on IBM computers; for several decades a large percentage of developers used IBM computers. Based on job adverts, RPG was widely used, but PL/1 not so. The use of RPG declined with the decline of IBM.
The introduction of microcomputers (originally 8-bit, then 16, then 32, and finally 64-bit) opened up an opportunity for new languages to become widely used in that niche (which would eventually grow to be the primary computing platform of its day). This opportunity occurred because compiler vendors for the major languages of the day did not want to cannibalize their existing market (i.e., selling compilers for a lot more than the price of a microcomputer) by selling a much lower priced product on microcomputers.
BASIC became available on practically all microcomputers, or rather some dialect of BASIC that was incompatible with all the other dialects. The availability of BASIC on a vendor’s computer promoted sales of the hardware, and it was not worthwhile for the major vendors to create a version of BASIC that reduced portability costs; the profit was in games.
The dominance of the Microsoft/Intel partnership removed the high cost of porting to lots of platforms (by driving them out of business), but created a major new obstacle to the wide adoption of new languages: Developer choice. There had always been lots of new languages floating around, but people only got to see the subset that were available on the particular hardware they targeted. Once the cpu/OS (essentially) became a monoculture most new languages had to compete for developer attention in one ecosystem.
Pascal was in widespread use for a few years on micros (in the form of Turbo Pascal) and university computers (the source of Wirth’s ETH compiler was freely available for porting), but eventually C won developer mindshare and became the most widely used language. In the early 1990s C++ compiler sales took off, but many developers were writing C with a few C++ constructs scattered about the code (e.g., use of new, rather than malloc/free).
Next, the Internet took off, and opened up an opportunity for new languages to become dominant. This opportunity occurred because Internet related software was being made freely available, and established compiler vendors were not interested in making their products freely available.
There were people willing to invest in creating a good-enough implementation of the language they had invented, and giving it away for free. Luck, plus being in the right place at the right time resulted in PHP and Javascript becoming widely used. Network effects prevent any other language becoming widely used. Compatible dialects of PHP and Javascript may migrate widespread usage to quite different languages over time, e.g., Facebook’s Hack.
Java rode to popularity on the coat-tails of the Internet, and when it looked like security issues would reduce it to niche status, it became the vendor supported language for one of the major smart-phone OSs.
Next, smart-phones took off, but the availability of Open Source compilers closed the opportunity window for new languages to become dominant through lack of interest from existing compiler vendors. Smart-phone vendors wanted to quickly attract developers, which meant throwing their weight behind a language that many developers were already familiar with; Apple went with Objective-C (which evolved to Swift), Google with Java (which evolved to Kotlin, because of the Oracle lawsuit).
Where does Python fit in this grand scheme? I don’t yet have an answer, or is my world-view wrong to treat Python usage as being as widespread as C/C++/Java?
New programming languages continue to be implemented; I don’t see this ever stopping. Most don’t attract more users than their implementer, but a few become fashionable amongst the young, who are always looking to attach themselves to something new and shiny.
Will a new programming language ever again become widely used?
Like human languages, programming languages experience strong networking effects. Widely used languages continue to be widely used because many companies depend on code written in it, and many developers who can use it can obtain jobs; what company wants to risk using a new language only to find they cannot hire staff who know it, and there are not many people willing to invest in becoming fluent in a language with no immediate job prospects.
Today’s widely used programmings languages succeeded in a niche that eventually grew larger than all the other computing ecosystems. The Internet and smart-phones are used by everybody on the planet, there are no bigger ecosystems to provide new languages with a possible route to widespread use. To be widely used a language first has to become fashionable, but from now on, new programming languages that don’t evolve from (i.e., be compatible with) current widely used languages are very unlikely to migrate from fashionable to widely used.
It has always been possible for a proficient developer to dedicate a year+ of effort to create a new language implementation. Adding the polish need to make it production ready used to take much longer, but these days tool chains such as LLVM supply a lot of the heavy lifting. The problem for almost all language creators/implementers is community building; they are terrible at dealing with other developers.
It’s no surprise that nearly all the new languages that become fashionable originate with language creators who work for a company that happens to feel a need for a new language. Examples include:
- Go created by Google for internal use, and attracted an outside fan base. Company languages are not new, with IBM’s PL/1 being the poster child (or is there a more modern poster child). At the moment Go is a trendy language, and this feeds a supply of young developers willing to invest in learning it. Once the trendiness wears off, Google will start to have problems recruiting developers, the reason: Being labelled as a Go developer limits job prospects when few other companies use the language. Talk to a manager who has tried to recruit developers to work on applications written in Fortran, Pascal and other once-widely used languages (and even wannabe widely used languages, such as Ada),
- Rust a vanity project from Mozilla, which they have now
abandonedcast adrift. Did Rust become fashionable because it arrived at the right time to become the not-Google language? I await a PhD thesis on the topic of the rise and fall of Rust, - Microsoft’s C# ceased being trendy some years ago. These days I don’t have much contact with developers working in the Microsoft ecosystem, so I don’t know anything about the state of the C# job market.
Every now and again a language creator has the social skills needed to start an active community. Zig caught my attention when I read that its creator, Andrew Kelley, had quit his job to work full-time on Zig. Two and a-half years later Zig has its own track at FOSEM’21.
Will Zig become the next fashionable language, as Rust/Go popularity fades? I’m rooting for Zig because of its name, there are relatively few languages whose name starts with Z; the start of the alphabet is over-represented with language names. It would be foolish to root for a language because of a belief that it has magical properties (e.g., powerful, readable, maintainable), but the young are foolish.
Growth in number of packages for widely used languages
These days a language’s ecosystem of add-ons, such as packages, is often more important than the features provided by the language (which usually only vary in their syntactic sugar, and built-in support for some subset of commonly occurring features).
Use of a particular language grows and shrinks, sometimes over very many decades. Estimating the number of users of a language is difficult, but a possible proxy is ecosystem activity in the form of package growth/decline. However, it will take many several decades for the data needed to test how effective this proxy might be.
Where are we today?
The Module Counts website is the home for a project that counts the number of libraries/packages/modules contained in 26 language specific repositories. Daily data, in some cases going back to 2010, is available as a csv 🙂 The following are the most interesting items I discovered during a fishing expedition.
The csv file contains totals, and some values are missing (which means specifying an ‘ignore missing values’ argument to some functions). Some repos have been experiencing large average daily growth (e.g., 65 for PyPI, and 112 for Maven Central-Java), while others are more subdued (e.g., 0.7 for PERL and 3.9 for R’s CRAN). Apart from a few days, the daily change is positive.
Is the difference in the order of magnitude growth due to number of active users, number of packages that currently exist, a wide/narrow application domain (Python is wide, while R’s is narrow), the ease of getting a package accepted, or something else?
The plots below show how PyPI has been experiencing exponential growth of a kind (the regression model fitted to the daily total has the form  , where is the number of days since 2010-01-01; the red line is the daily diff of this equation), while Ruby has been experiencing a linear decline since late 2014 (all code+data):
, where is the number of days since 2010-01-01; the red line is the daily diff of this equation), while Ruby has been experiencing a linear decline since late 2014 (all code+data):
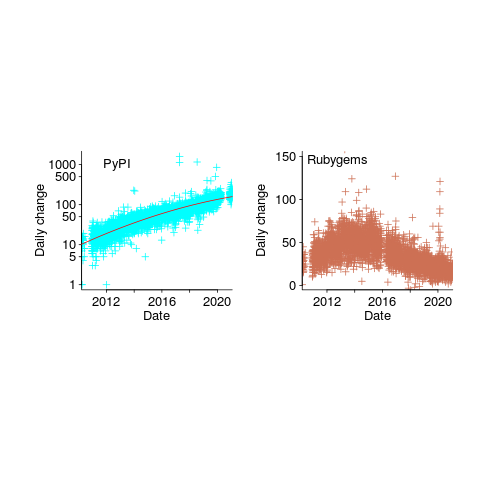
Will the five-year decline in new submissions to Rubygems continue, and does this point to an eventual demise of Ruby (a few decades from now)? Rubygems has years to go before it reaches PERL’s low growth rate (I think PERL is in terminal decline).
Are there any short term patterns, say at the weekly level? Autocorrelation is a technique for estimating the extent to which today’s value is affected by values from the immediate past (usually one or two measurement periods back, i.e., yesterday or the day before that). The two plots below show the autocorrelation for daily changes, with lag in days:
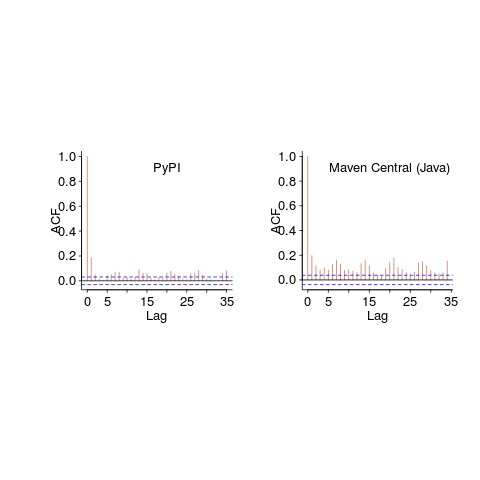
The recurring 7-day ‘peaks’ show the impact of weekends (I assume). Is the larger ”weekend-effect’ for Java, compared to PyPI, due to Java usage including a greater percentage of commercial developers (who tend not to work at the weekend)?
I did not manage to find any seasonal effect, e.g., more submissions during the winter than the summer. But I only checked a few of the languages, and only for a single peak (see code for details).
Another way of tracking package evolution is version numbering. For instance, how often do version numbers change, and which component, e.g., major/minor. There have been a couple of studies looking at particular repos over a few years, but nobody is yet recording broad coverage daily, over the long term 😉
Recent Comments