Archive
Growth in number of packages for widely used languages
These days a language’s ecosystem of add-ons, such as packages, is often more important than the features provided by the language (which usually only vary in their syntactic sugar, and built-in support for some subset of commonly occurring features).
Use of a particular language grows and shrinks, sometimes over very many decades. Estimating the number of users of a language is difficult, but a possible proxy is ecosystem activity in the form of package growth/decline. However, it will take many several decades for the data needed to test how effective this proxy might be.
Where are we today?
The Module Counts website is the home for a project that counts the number of libraries/packages/modules contained in 26 language specific repositories. Daily data, in some cases going back to 2010, is available as a csv 🙂 The following are the most interesting items I discovered during a fishing expedition.
The csv file contains totals, and some values are missing (which means specifying an ‘ignore missing values’ argument to some functions). Some repos have been experiencing large average daily growth (e.g., 65 for PyPI, and 112 for Maven Central-Java), while others are more subdued (e.g., 0.7 for PERL and 3.9 for R’s CRAN). Apart from a few days, the daily change is positive.
Is the difference in the order of magnitude growth due to number of active users, number of packages that currently exist, a wide/narrow application domain (Python is wide, while R’s is narrow), the ease of getting a package accepted, or something else?
The plots below show how PyPI has been experiencing exponential growth of a kind (the regression model fitted to the daily total has the form  , where
, where  is the number of days since 2010-01-01; the red line is the daily diff of this equation), while Ruby has been experiencing a linear decline since late 2014 (all code+data):
is the number of days since 2010-01-01; the red line is the daily diff of this equation), while Ruby has been experiencing a linear decline since late 2014 (all code+data):
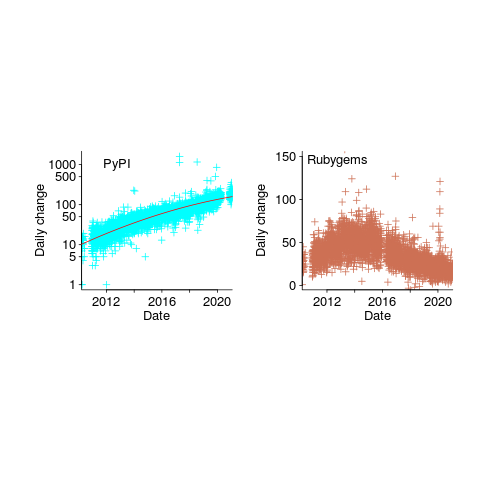
Will the five-year decline in new submissions to Rubygems continue, and does this point to an eventual demise of Ruby (a few decades from now)? Rubygems has years to go before it reaches PERL’s low growth rate (I think PERL is in terminal decline).
Are there any short term patterns, say at the weekly level? Autocorrelation is a technique for estimating the extent to which today’s value is affected by values from the immediate past (usually one or two measurement periods back, i.e., yesterday or the day before that). The two plots below show the autocorrelation for daily changes, with lag in days:
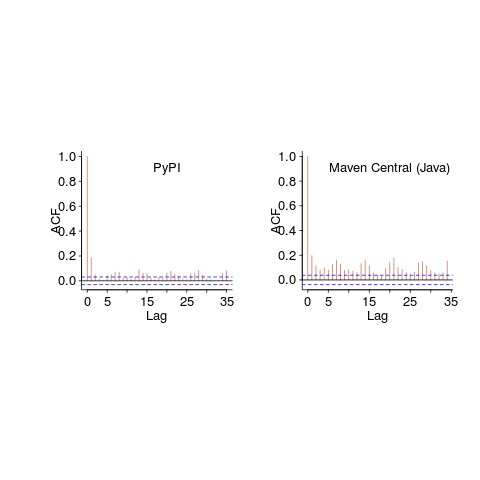
The recurring 7-day ‘peaks’ show the impact of weekends (I assume). Is the larger ”weekend-effect’ for Java, compared to PyPI, due to Java usage including a greater percentage of commercial developers (who tend not to work at the weekend)?
I did not manage to find any seasonal effect, e.g., more submissions during the winter than the summer. But I only checked a few of the languages, and only for a single peak (see code for details).
Another way of tracking package evolution is version numbering. For instance, how often do version numbers change, and which component, e.g., major/minor. There have been a couple of studies looking at particular repos over a few years, but nobody is yet recording broad coverage daily, over the long term 😉
Learning useful stuff from the Ecosystems chapter of my book
What useful, practical things might professional software developers learn from the Ecosystems chapter in my evidence-based software engineering book?
This week I checked the ecosystems chapter; what useful things did I learn (combined with everything I learned during all the other weeks spent working on this chapter)?
A casual reader would conclude that software engineering ecosystems involved lots of topics, with little or no theory connecting them. I had great plans for the connecting theories, but lack of detailed data, time and inspiration means the plans remain in my head (e.g., modelling the interaction between the growth of source code written in a particular language and the number of developers actively using that language).
For managers, the usefulness of this chapter is the strategic perspective it provides. How does what they and others are doing relate to everything else, and what patterns of evolution are to be expected?
Software people like to think that everything about software is unique. Software is unique, but the activities around it follow patterns that have been followed by other unique technologies, e.g., the automobile and jet engines. There is useful stuff to be learned from non-software ecosystems, and the chapter discusses some similarities I have learned about.
There is lots more evidence of the finite lifetime of software related items: lifetime of products, Linux distributions, packages, APIs and software careers.
Some readers might be surprised by the amount of discussion about what is now historical hardware. Software needs hardware to execute it, and the characteristics of the hardware of the day can have a significant impact on the characteristics of the software that gets written. I suspect that most of this discussion will not be that useful to most readers, but it provides some context around why things are the way they are today.
Readers with a wide knowledge of software ecosystems will notice that several major ecosystems barely get a mention. Embedded systems is a huge market, as is Microsoft Windows, and very many professional developers use C++. However, to date the focus of most research has been around Linux and Android (because its use of Java, a language often taught in academia), and languages that have a major package repository. So the ecosystems chapter presents a rather blinkered view of software engineering ecosystems.
What did I learn from this chapter?
Software ecosystems are bigger and more complicated that I had originally thought.
Readers might have a completely different learning experience from reading the ecosystems chapter. What useful things did you learn from the ecosystems chapter?
Happy 60th birthday: Algol 60
Report on the Algorithmic Language ALGOL 60 is the title of a 16-page paper appearing in the May 1960 issue of the Communication of the ACM. Probably one of the most influential programming languages, and a language that readers may never have heard of.
During the 1960s there were three well known, widely used, programming languages: Algol 60, Cobol, and Fortran.
When somebody created a new programming languages Algol 60 tended to be their role-model. A few of the authors of the Algol 60 report cited beauty as one of their aims, a romantic notion that captured some users imaginations. Also, the language was full of quirky, out-there, features; plenty of scope for pin-head discussions.
Cobol appears visually clunky, is used by business people and focuses on data formatting (a deadly dull, but very important issue).
Fortran spent 20 years catching up with features supported by Algol 60.
Cobol and Fortran are still with us because they never had any serious competition within their target markets.
Algol 60 had lots of competition and its successor language, Algol 68, was groundbreaking within its academic niche, i.e., not in a developer useful way.
Language family trees ought to have Algol 60 at, or close to their root. But the Algol 60 descendants have been so successful, that the creators of these family trees have rarely heard of it.
In the US the ‘military’ language was Jovial, and in the UK it was Coral 66, both derived from Algol 60 (Coral 66 was the first language I used in industry after graduating). I used to hear people saying that Jovial was derived from Fortran; another example of people citing the language the popular language know.
Algol compiler implementers documented their techniques (probably because they were often academics); ALGOL 60 Implementation is a real gem of a book, and still worth a read today (as an introduction to compiling).
Algol 60 was ahead of its time in supporting undefined behaviors 😉 Such as: “The effect, of a go to statement, outside a for statement, which refers to a label within the for statement, is undefined.”
One feature of Algol 60 rarely adopted by other languages is its parameter passing mechanism, call-by-name (now that lambda expressions are starting to appear in widely used languages, call-by-name has a kind-of comeback). Call-by-name essentially has the same effect as textual substitution. Given the following procedure (it’s not a function because it does not return a value):
procedure swap (a, b); integer a, b, temp; begin temp := a; a := b; b:= temp end; |
the effect of the call: swap(i, x[i]) is:
temp := i; i := x[i]; x[i] := temp |
which might come as a surprise to some.
Needless to say, programmers came up with ‘clever’ ways of exploiting this behavior; the most famous being Jensen’s device.
The follow example of go to usage appears in: International Standard 1538 Programming languages – ALGOL 60 (the first and only edition appeared in 1984, after most people had stopped using the language):
go to if Ab < c then L17 else g[if w < 0 then 2 else n] |
Orthogonality of language use won out over the goto FUD.
The Software Preservation Group is a great resource for Algol 60 books and papers.
Natural elimination, or the survival of the good enough
Thanks to Darwin, the world is full of people who think that evolution, in nature, works by: natural selection, or the survival of the fittest. I thought this until I read “Good Enough: The Tolerance for Mediocrity in Nature and Society” by Daniel Milo.
Milo makes a very convincing case that nature actually works by: natural elimination, or the survival of the good enough.
Why might Darwin have gone with natural selection in his book, On the Origin of Species? Milo makes the point that the only real evidence that Darwin had to work with was artificial selection, that is the breeding of farm animals and domestic pets to select for traits that humans found desirable. Darwin’s visit to the Galápagos islands triggered a way of thinking, it did not provide him with the evidence he needed; Darwin’s Finches have become a commonly cited example of natural selection at work, but while Darwin made the observations it was not until 80 years later that somebody else spotted their relevance.
The Origin of Species, or to use its full title: “On the Origin of Species by means of natural selection, or the preservation of favored races in the struggle for life.” is full of examples and terminology relating to artificial selection.
Natural selection, or natural elimination, isn’t the result the same?
Natural selection implies an optimization process, e.g., breeders selecting for a strain of cows that produce the most milk.
Natural elimination is a good enough process, i.e., a creature needs a collection of traits that are good enough for them to create the next generation.
A long-standing problem with natural selection is that it fails to explain the diversity present in a natural population of some breed of animal (there is very little diversity in each breed of farm animal, they have been optimized for consistency). Diversity is not a problem for natural elimination, which does not reduce differences in its search for fitness.
The diversity produced as a consequence of natural elimination creates a population containing many neutral traits (i.e., characteristics that have no positive or negative impact on continuing survival). When a significant change in the environment occurs, one or more of the neutral traits may suddenly have positive or negative survival consequences; the creatures with the positive traits have opportunity time to adapt to the changed environment. A population whose members possess a diverse range of neutral traits has a higher chance of long-term survival than a population where diversity has been squeezed in the quest for the fittest.
I think that natural elimination also applies within software ecosystems. Commercial products survive if enough customers buy them, software developers need good enough know-how to get the job done.
I’m sure customers would prefer software ecosystems to operate on the principle of survival of the fittest (it reduces their costs). Over the long term is society best served by diverse software ecosystems or softwaremonocultures? Diversity is a way of encouraging competition, but over time there is diminishing returns on the improvements.
Growth and survival of gcc options and processor support
Like any actively maintained software, compilers get more complicated over time. Languages are still evolving, and options are added to control the support for features. New code optimizations are added, which don’t always work perfectly, and options are added to enable/disable them. New ways of combining object code and libraries are invented, and new options are added to allow the desired combination to be selected.
The web pages summarizing the options for gcc, for the 96 versions between 2.95.2 and 9.1 have a consistent format; which means they are easily scrapped. The following plot shows the number of options relating to various components of the compiler, for these versions (code+data):
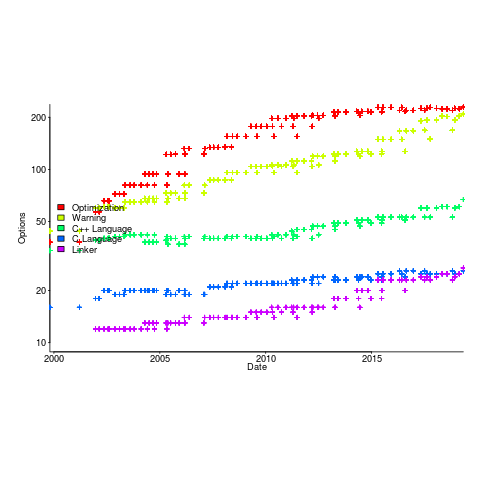
The total number of options grew from 632 to 2,477. The number of new optimizations, or at least the options supporting them, appears to be leveling off, but the number of new warnings continues to increase (ah, the good ol’ days, when -Wall covered everything).
The last phase of a compiler is code generation, and production compilers are generally structured to enable new processors to be supported by plugging in an appropriate code generator; since version 2.95.2, gcc has supported 80 code generators.
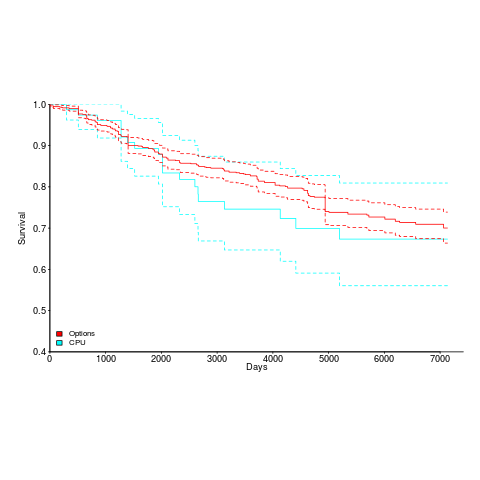
What can be added can be removed. The plot below shows the survival curve of gcc support for processors (80 supported cpus, with support for 20 removed up to release 9.1), and non-processor specific options (there have been 1,091 such options, with 214 removed up to release 9.1); the dotted lines are 95% confidence internals.
Lehman ‘laws’ of software evolution
The so called Lehman laws of software evolution originated in a 1968 study, and evolved during the 1970s; the book “Program Evolution: processes of software change” by Lehman and Belady was published in 1985.
The original work was based on measurements of OS/360, IBM’s flagship operating system for the computer industries flagship computer. IBM dominated the computer industry from the 1950s, through to the early 1980s; OS/360 was the Microsoft Windows, Android, and iOS of its day (in fact, it had more developer mind share than any of these operating systems).
In its day, the Lehman dataset not only bathed in reflected OS/360 developer mind-share, it was the only public dataset of its kind. But today, this dataset wouldn’t get a second look. Why? Because it contains just 19 measurement points, specifying: release date, number of modules, fraction of modules changed since the last release, number of statements, and number of components (I’m guessing these are high level programs or interfaces). Some of the OS/360 data is plotted in graphs appearing in early papers, and can be extracted; some of the graphs contain 18, rather than 19, points, and some of the values are not consistent between plots (extracted data); in later papers Lehman does point out that no statistical analysis of the data appears in his work (the purpose of the plots appears to be decorative, some papers don’t contain them).
One of Lehman’s early papers says that “… conclusions are based, comes from systems ranging in age from 3 to 10 years and having been made available to users in from ten to over fifty releases.“, but no other details are given. A 1997 paper lists module sizes for 21 releases of a financial transaction system.
Lehman’s ‘laws’ started out as a handful of observations about one very large software development project. Over time ‘laws’ have been added, deleted and modified; the Wikipedia page lists the ‘laws’ from the 1997 paper, Lehman retired from research in 2002.
The Lehman ‘laws’ of software evolution are still widely cited by academic researchers, almost 50-years later. Why is this? The two main reasons are: the ‘laws’ are sufficiently vague that it’s difficult to prove them wrong, and Lehman made a large investment in marketing these ‘laws’ (e.g., publishing lots of papers discussing these ‘laws’, and supervising PhD students who researched software evolution).
The Lehman ‘laws’ are not useful, in the sense that they cannot be used to make predictions; they apply to large systems that grow steadily (i.e., the kind of systems originally studied), and so don’t apply to some systems, that are completely rewritten. These ‘laws’ are really an indication that software engineering research has been in a state of limbo for many decades.
Update: Added numbers from appendix of “Software Engineering Metrics and Models” by Conte, Dunsmore, and Shen.
Ecosystems as major drivers of software development
During the age of the Algorithm, developers wrote most of the code in their programs. In the age of the Ecosystem, developers make extensive use of code supplied by third-parties.
Software ecosystems are one of the primary drivers of software development.
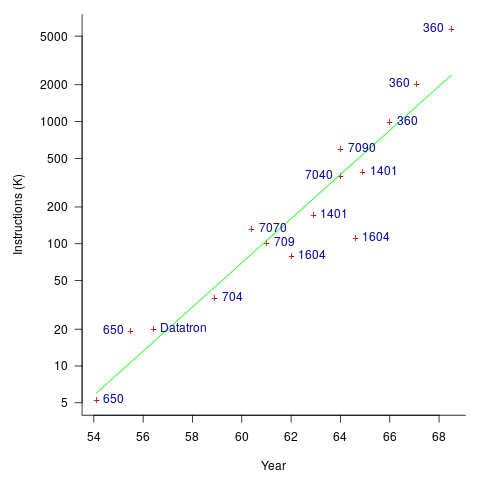
The early computers were essentially sold as bare metal, with the customer having to write all the software. Having to write all the software was expensive, time-consuming, and created a barrier to more companies using computers (i.e., it was limiting sales). The amount of software that came bundled with a new computer grew over time; the following plot (code+data) shows the amount of code (thousands of instructions) bundled with various IBM computers up to 1968 (an antitrust case eventually prevented IBM bundling software with its computers):
Some tasks performed using computers are common to many computer users, and users soon started to meet together, to share experiences and software. SHARE, founded in 1955, was the first computer user group.
SHARE was one of several nascent ecosystems that formed at the start of the software age, another is the Association for Computing Machinery; a great source of information about the ecosystems existing at the time is COMPUTERS and AUTOMATION.
Until the introduction of the IBM System/360, manufacturers introduced new ranges of computers that were incompatible with their previous range, i.e., existing software did not work.
Compatibility with existing code became a major issue. What had gone before started to have a strong influence on what was commercially viable to do next. Software cultures had come into being and distinct ecosystems were springing up.
A platform is an ecosystem which is primarily controlled by one vendor; Microsoft Windows is the poster child for software ecosystems. Over the years, Microsoft has added more and more functionality to Windows, and I don’t know enough to suggest the date when substantial Windows programs substantially depended on third-party code; certainly small apps may be mostly Windows code. The Windows GUI certainly ties developers very closely to a Windows way of doing things (I have had many people tell me that porting to a non-Windows GUI was a lot of work, but then this statement seems to be generally true of porting between different GUIs).
Does Facebook’s support for the writing of simple apps make it a platform? Bill Gates thought not: “A platform is when the economic value of everybody that uses it, exceeds the value of the company that creates it.”, which some have called the Gates line.
The rise of open source has made it viable for substantial language ecosystems to flower, or rather substantial package ecosystems, with each based around a particular language. For practical purposes, language choice is now about the quality and quantity of their ecosystem. The dedicated followers of fashion like to tell everybody about the wonders of Go or Rust (in fashion when I wrote this post), but without a substantial package ecosystem, no language stands a chance of being widely used over the long term.
Major new software ecosystems have been created on a regular basis (regular, as in several per decade), e.g., mainframes in the 1960s, minicomputers and workstation in the 1970s, microcomputers in the 1980s, the Internet in the 1990s, smartphones in the 2000s, the cloud in the 2010s.
Will a major new software ecosystem come into being in the future? Major software ecosystems tend to be hardware driven; is hardware development now basically done, or should we expect something major to come along? A major hardware change requires a major new market to conquer. The smartphone has conquered a large percentage of the world’s population; there is no larger market left to conquer. Now, it’s about filling in the gaps, i.e., lots of niche markets that are still waiting to be exploited.
Software ecosystems are created through lots of people working together, over many years, e.g., the huge number of quality Python packages. Perhaps somebody will emerge who has the skills and charisma needed to get many developers to build a new ecosystem.
Software ecosystems can disappear; I think this may be happening with Perl.
Can a date be put on the start of the age of the Ecosystem? Ideas for defining the start of the age of the Ecosystem include:
- requiring a huge effort to port programs from one ecosystem to another. It used to be very difficult to port between ecosystems because they were so different (it has always been in vendors’ interests to support unique functionality). Using this method gives an early start date,
- by the amount of code/functionality in a program derived from third-party packages. In 2018, it’s certainly possible to write a relatively short Python program containing a huge amount of functionality, all thanks to third-party packages. Was this true for any ecosystems in the 1980s, 1990s?
StatsModels: the first nail in R’s coffin
In 2012, when I decided to write a book on evidence-based software engineering, R was the obvious system to use for data analysis. At the time, lots of new books had “using R” or “with R” added at the end of their titles; I chose “using R”.
When developers tell me they need to do some statistical analysis, and ask whether they should use Python or R, I tell them to use Python if statistics is a small part of the program, otherwise use R.
If I started work on the book today, I would till choose R. If I were starting five-years from now, I could be choosing Python.
To understand why I think Python will eventually take over the niche currently occupied by R, we need to understand the unique selling points of both systems.
R’s strengths are that it supports a way of thinking that is a good fit for doing data analysis and has an extensive collection of packages that simplify the task of applying a wide variety of analysis techniques to data.
Python also has packages supporting the commonly used data analysis techniques. But nearly all the Python packages provide a developer-mentality interface (i.e., they provide an API like any other package), R provides data-analysis-mentality interfaces. R supports a way of thinking that data analysts can identify with.
Python’s strengths, over R, are a much larger base of developers and language support for writing large programs (R is really a scripting language). Yes, Python has a package ecosystem supporting the full spectrum of application domains, this is not relevant for analysing a successful invasion of R’s niche market (but it is relevant for enticing new developers who are still making up their mind).
StatsModels is a Python package based around R’s data-analysis-mentality interface. When I discovered this package a few months ago, I realised the first nail had been hammered into R’s coffin.
Yes, today R has nearly all the best statistical analysis packages and a large chunk of the leading edge stuff. But packages can be reimplemented (C code can be copy-pasted, the R code mapped to Python); there is no magic involved. Leading edge has a short shelf life, and what proves to be useful can be duplicated; the market for leading edge code in a mature market (e.g., data analysis) is tiny.
A bunch of bright young academics looking to make a name for themselves will see the major trees in the R forest have been felled. The trees in the Python data-analysis-mentality forest are still standing; all it takes is a few people wanting to be known as the person who implemented the Python package that everybody uses for XYZ analysis.
A collection of packages supporting the commonly (and eventually not so commonly) used data analysis techniques, with a data-analysis-mentality interface, removes a major selling point for using R. Python is a bigger developer market with support for many other application domains.
The flow of developers starting out with R will slow down, casual R users will have nothing to lose from trying out another language when the right project comes along (another language on the CV looks good and Python is a bigger market). There will be groups where everybody uses R and will continue to use R because that is what everybody else in the group uses. Ten-Twenty years from now R, developers could be working in a ghost town.
Evolutionary pressures on C++, Java and Python
The future evolution of C++, Java and Python is being driven by very different interested parties, and it’s going to be interesting watching events unfold over the next 5-10 years.
I have previously written about how the C++ Standard’s committee is past its sell-by date, has taken off its ball and chain and is now in the hands of bored consultants.
Bjarne Stroustrup was once effectively treated as C++’s Benevolent Dictator For Life (during the production of the first C++ Standard some people were labeled as Bjarne groupees); things have moved on since then, but the ‘old-guard’ are trying to make a comeback. Suggesting that people ought to base their thinking on a book published almost 25-years ago (Stroustrup’s “The Design and Evolution of C++”; a very interesting book that is well worth reading) creates a rather backward looking image. Bored consultants are looking to work on exciting new ideas. The old-guard need to appear modern to attract followers (even if the ideas are old ideas with a fresh coat of paint).
The threat to C++ is from bored consultants, each adding their own pet idea to the language standard; a situation that Stroustrup thinks is starting to happen.
Java, the language, is owned by Oracle, the company (let’s not get too involved in exactly what they own, have copyright on, etc). Oracle are not shy about asking people for licensing fees. Java is now on a 6-month release cycle (at least the Oracle version, there are Open Source implementations) and the free support only applies to the current release; paying a license fee buys support for versions older than 6-months. In the short term, the cheapest solution is for companies to pay for support.
Oracle are always happy to send in the lawyers and if too many customers switch to non-Oracle implementations, I’m sure something can be found to introduce enough uncertainty to discourage work/distribution involving Open Source Java implementations.
Will Java survive Oracle’s licensing? It is not in their interest for Java to die; Oracle will adjust their terms to keep the money flowing in, but over the longer term I think willing Java developers are going to be hard to find.
Guido van Rossum recently removed himself from the post of Python’s Benevolent Dictator For Life. One of the jobs of a benevolent dictator is maintaining some degree of language coherence, which involves preventing people’s pet ideas from being added to the language. Does this mean that Python is slowly going to be become more and more bloated? Perhaps, but I think a more likely problem is a language fork, multiple implementations of slightly different (at first) languages all claiming to be Python.
These days, the strength of Python is its large collection of very useful, commercial grade, packages, and future language details may turn out to be irrelevant. There is a lot to learn from the Python 2/3 transition, but true believers like to think that things will turn out differently for them.
The age of the Algorithm is long gone
I date the age of the Algorithm from roughly the 1960s to the late 1980s.
During the age of the Algorithms, developers spent a lot of time figuring out the best algorithm to use and writing code to implement algorithms.
Knuth’s The Art of Computer Programming (TAOCP) was the book that everybody consulted to find an algorithm to solve their current problem (wafer thin paper, containing tiny handwritten corrections and updates, was glued into the library copies of TAOCP held by my undergraduate university; updates to Knuth was news).
Two developments caused the decline of the age of the Algorithm (and the rise of the age of the Ecosystem and the age of the Platform; topics for future posts).
- The rise of Open Source (it was not called this for a while), meant it became less and less necessary to spend lots of time dealing with algorithms; an implementation of something that was good enough, was available. TAOCP is something that developers suggest other people read, while they search for a package that does something close enough to what they want.
- Software systems kept getting larger, driving down the percentage of time developers spent working on algorithms (the bulk of the code in commercially viable systems deals with error handling and the user interface). Algorithms are still essential (like the bolts holding a bridge together), but don’t take up a lot of developer time.
Algorithms are still being invented, and some developers spend most of their time working with algorithms, but peak Algorithm is long gone.
Perhaps academic researchers in software engineering would do more relevant work if they did not spend so much time studying algorithms. But, as several researchers have told me, algorithms is what people in their own and other departments think computing related research is all about. They remain shackled to the past.
Recent Comments